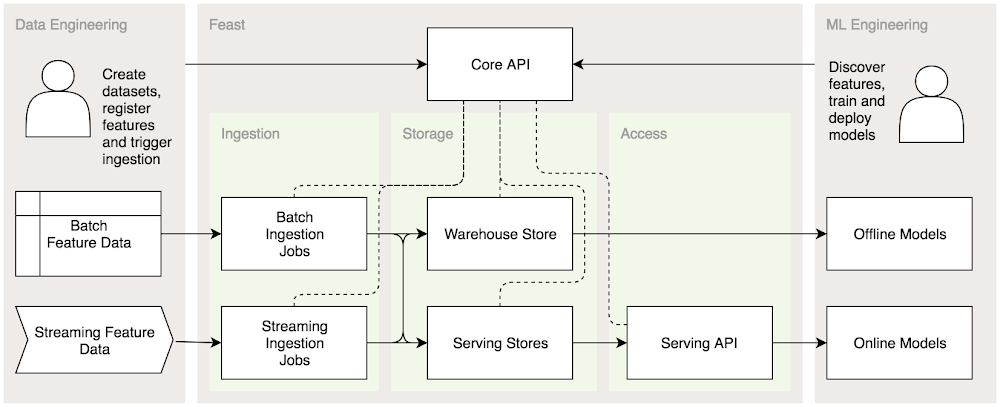
GO-JEK and Google Cloud are pleased to announce the release of Feast, an open source feature store that allows teams to manage, store, and discover features for use in machine learning projects.Feast solves the problem of making features accessible for machine learning across multiple teams. To operate machine learning systems at scale, teams need to have access to a wealth of feature data. Data which is crucial in being able to both train accurate models and serve them in production.Developed jointly by GO-JEK and Google Cloud, Feast aims to solve a set of common challenges facing data science teams by becoming an open, extensible, unified platform for feature storage. It gives teams the ability to define and publish features to this unified store, which in turn facilitates discovery and feature reuse across machine learning projects.“Feast is an essential component in building end-to-end machine learning systems at GO-JEK,” says Peter Richens, Senior Data Scientist at GO-JEK, “so we are very excited to release it to the open source community. We worked closely with Google Cloud in the design and development of the product, and this has yielded a robust system for the management of machine learning features, all the way from idea to production. Feast not only abstracts away the data management challenges we had, but also greatly increases discovery and reuse of features in our ML projects. It allows us to build a foundation of features for our models to leverage, making models more accurate, and greatly reducing time to market.”Feast solves an important part of the machine learning lifecycle. Feast’s near term strategic goal is to integrate with and be installable within Kubeflow, completing an end-to-end machine learning process.MotivationFeatures are properties of an observed phenomenon that are at the root of what makes machine learning algorithms effective. Typically they come in the form of numeric values based on an organization’s users or systems. The more relevant the features are to the business problem, the more accurately a model will be able to optimize for a specific business outcome.Typically a team will create, store, and manage features based on the requirements of a specific machine learning project. These requirements drive the development of new pipelines for the creation of features, and for the deployment of new data stores used in model training and serving. However, managing features and infrastructure on a per project basis can present its own set of challenges:Engineering overhead: New projects may require different infrastructure to be provisioned to source, transform, and serve features. This is particularly true for real-time streaming data use cases. The engineering work involved in implementing these systems leads teams to limit the amount and complexity of features that they develop. This also leads to teams having to manage more infrastructure as they take on new projects.Keeping features up to date: Often features are engineered from batch data sources in order to avoid the complexities of creating features from event streams. The consequence is that models only have access to features as new as the most recently run feature creation pipeline.Inconsistency between training and serving: Machine learning models are generally first trained and evaluated on offline feature data. The feature transformations that produce these data sets are typically written in programming languages that make data manipulation easy, but do not meet the requirements of production serving systems. This leads to feature transformations being redeveloped for production use which can introduce data inconsistencies, leading to unpredictable model scores.Lack of visibility: The development of features often does not include documenting the intent of the feature creator, nor the steps involved in the creation of a feature. When this information does exist, the structure and focus typically is not consistent across teams or projects.Duplication of features and lack of reusability: Project teams are often faced with a difficult decision when engineering features for a new system. Given the lack of visibility into what other teams have done, when can they reuse existing features? Often the decision is made to redevelop features from scratch to ensure a project has no unstable dependencies.SolutionFeast solves these challenges by providing a platform on which to standardize the definition, storage and access of serving features for training and serving. It encourages sharing, discovery, and reuse of features amongst ML practitioners, acting as a bridge between data and machine learning engineering.Feast abstracts away the engineering overhead associated with managing data infrastructure. It handles the ingestion, storage, and serving of feature data in a scalable way, unifying batch and streaming feature data. The system updates storage backend schemas according to registered feature specifications, and ensures that there is a consistent view of features in both your historical and real-time data stores. End users can then access these features from their development environment, or from production systems at scale.The key attributes of Feast are that it is:Standardized: Feast presents a centralized platform on which teams can register features in a standardized way. The platform provides structure to the way features are defined and allows teams to reference features in discussions with a singly understood way.Accessible: By providing a unified serving API for feature stores, ML applications are able to easily access batch and real-time features opaquely. This greatly reduces the complexity of deploying applications that would often need to deploy and manage their own real-time stores or batch files. There is clear separation of responsibilities and new ML projects can easily leverage features that have been created by prior teams.Open source: The software is designed from the ground up to be open source and vendor agnostic. The design is modular and extensible, meaning new types of data stores and input sources can easily be added and combined. It can run locally or on Kubernetes. It leverages open source technology like Apache Beam, Redis and PostgreSQL, or managed services like BigQuery, Dataflow and BigTable.Developer focused: Feast does not just aim to be used for training and serving in production environments, but also as part of model prototyping and evaluation. A Python SDK will allow users to easily interact with Feast in interactive development environments like Jupyter notebooks.KubeflowThere is a growing ecosystem of tools trying to help productionize machine learning. A key open source ML platform in this space is Kubeflow, which has focussed on improving packaging, serving, training, evaluation and orchestration.Companies that have built successful internal ML platforms have identified that standardized feature definition, storage and access was critical to successful adoption and utility of their platforms.For this reason, Feast aims to be deployable on Kubeflow and integrate as seamlessly as possible with other Kubeflow components in the future, including a python SDK for use with Kubeflow’s Jupyter notebooks, and ML Pipelines.There is a Kubeflow GitHub issue here for discussion of future Feast integration.How you can contributeFeast provides a consistent way to access features that can be passed into serving models, and to access features in batch for training. We hope that Feast can act as a bridge between your data engineering and machine learning teams and would love to hear feedback via our GitHub project.Find the Feast project on GitHub repository hereJoin the Kubeflow community and find us on Slack
Quelle: Google Cloud Platform
Published by