Guest post: Multi-Cloud continuous delivery using Spinnaker at Waze
By Tom Feiner, Systems Operations Engineer, Katriel Traum, Systems Operations Engineer, Nir Tarcic, Site Reliability Engineer, Waze and Matt Duftler, Software Engineer, Spinnaker
At Waze, our mission of outsmarting traffic, together forces us to be mindful of our users most precious possession — their time. Our cloud-based service saves users time by helping them find the optimal route based on crowdsourced data.
But a cloud service is only as good as it is available. At Waze, we use multiple cloud providers to improve the resiliency of our production systems. By running an active-active architecture across Google Cloud Platform (GCP) and AWS, we’re in a better position to survive a DNS DDOS attack, a regional failure — even a global failure of an entire cloud provider.
Sometimes, though, a bug in routing or ETA calculations makes it to production undetected, and we need the ability to roll that code back or fix it as fast as possible — velocity is key. That’s easier said than done in a multi-cloud environment. For example, our realtime routing service spans over 80 autoscaling groups/managed instance groups across two cloud providers and over multiple regions.
This is where continuous delivery helps out. Specifically, we use Spinnaker, an open source, continuous delivery platform for releasing software changes with high velocity and confidence. Spinnaker has handled 100% of our production deployments for the past year, regardless of target platform.
Spinnaker and continuous delivery FTW
Large-scale cloud deployments can be complex. Fortunately, Spinnaker abstracts many of the particulars of each cloud provider, allowing our developers to focus on making Waze even better for our users instead of concerning themselves with the low-level details of multiple cloud providers. All the while, we’re able to maintain important continuous delivery concepts like canaries, immutable infrastructure and fast rollbacks.
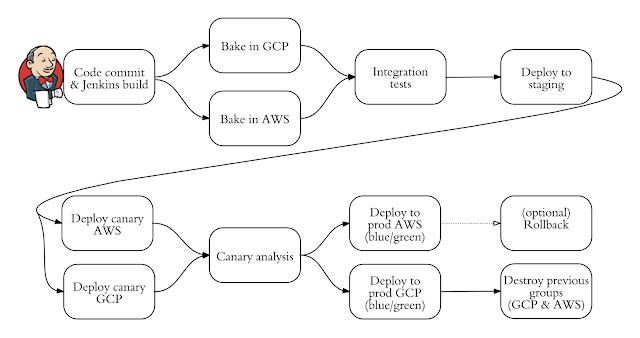
Jenkins is a first-class citizen in Spinnaker, so once code is committed to git and Jenkins builds a package, that same package triggers the main deployment pipeline for that particular microservice. That pipeline bakes the package into an immutable machine image on multiple cloud providers in parallel and continues to run any automated testing stages. The deployment proceeds to staging using blue/green deployment strategy, and finally to production without having to get deep into the details of each platform. Note that Spinnaker automatically resolves the correct image IDs per cloud provider, so that each cloud’s deployment processes happen automatically and correctly without the need for any configuration.
Example of a multi-cloud pipeline
*Jenkins Icon from the Jenkins project
Multi-Cloud blue/green deployment using Spinnaker
Thanks to Spinnaker, developers can focus on developing business logic, rather than becoming experts on each cloud platform. Teams can track the lifecycle of a deployment using several notification mechanisms including email, Slack and SMS, allowing them to coordinate handoffs between developer and QA teams. Support for tools like canary analysis and fast rollbacks allows developers to make informed decisions about the state of their deployment. Since Spinnaker is designed from the ground up to be a self-service tool, developers can do all of this with minimal involvement from the Ops team.
At Waze, we strive to release new features & bug fixes to our users as quickly as possible . Spinnaker allows us to do just that while also helping keep multi-cloud deployments and rollbacks simple, easy and reliable.
If this sounds like something your organization would benefit from, check out Spinnaker. And don’t miss our talks at GCP Next 2017:
Waze: migrating a multi million user app to Google Cloud Platform
Best practices for Continuous Delivery on Google Cloud Platform
Quelle: Google Cloud Platform








