Spiegelreflex: Canon EOS R5 nimmt 8K mit 30 Bildern pro Sekunde auf
Canon hat einige technische Spezifikationen seines neuen Spitzen-DSLR-Modells freigegeben. (Canon, DSLR)
Quelle: Golem

Canon hat einige technische Spezifikationen seines neuen Spitzen-DSLR-Modells freigegeben. (Canon, DSLR)
Quelle: Golem

Netflix führt eine Neuerung ein, die es bei Disney+, Amazon Prime Video und Apple TV+ bisher nicht gibt. (Netflix, Disney)
Quelle: Golem

Tesla verlangt jetzt Geld für seine Konnektivitätsdienste. Das gilt aber nur für Elektroautos ab einem bestimmten Verkaufsdatum. (Tesla, Technologie)
Quelle: Golem

Die Regierung will “rechtzeitig” über die Neuvergabe der 450-MHz-Frequenzen entscheiden. Die Wirtschaft will damit sicheres Laden garantieren. (Bundesregierung, Handy)
Quelle: Golem
Whether they’re caring for patients or advancing research towards a cure, healthcare and life sciences organizations are on the front lines in the fight against COVID-19. We know that the pandemic is impacting every aspect of the healthcare industry differently, and that the needs of organizations are rapidly evolving. Our goal is to bring our technology expertise to bear in helping your experts—so that healthcare organizations can focus on providing the best care to as many people as possible. To help tackle this challenge, we’re announcing today the general availability of our Cloud Healthcare API, and we’re also sharing a number of other industry-tailored solutions to support our customers and partners during this time.Announcing the general availability of the Google Cloud Healthcare APIHealthcare providers’ access to real-time, unified healthcare data is critical—and every second matters. As the industry is pushed to its limits in light of COVID-19, the need for increased data interoperability is more important than ever. In the last few months, the industry has laid the foundation for progress with final rules issued by CMS and ONC, implementing key provisions of the 21st Century Cures Act. Today, healthcare organizations are in dire need of easy-to-use technology that supports health information exchange. To address this gap, we’ve made our Cloud Healthcare API generally available today to the industry at-large. The API allows healthcare organizations to ingest and manage key data from a range of inputs and systems—and then better understand that data through the application of analytics and machine learning in real time, at scale. It also enables providers to easily interact with that data using Web-friendly, REST-based endpoints and health plans to rapidly get up and running with a cloud based FHIR server providing the capabilities needed to implement, scale and support interoperability and patient access. Since launching our partnership last year, the Mayo Clinic has been relying on our Healthcare API to enable the storage and interoperability of its clinical data. “We’re in a time where technology needs to work fast, securely, and most importantly in a way that furthers our dedication to our patients,” said John Halamka, M.D., president of Mayo Clinic Platform. “Google Cloud’s Healthcare API accelerates data liquidity among stakeholders, and in-return, will help us better serve our patients.”For healthcare and life science organizations, gathering a unified view of FHIR, HL7v2 and DICOM data is often a herculean effort, due to complicated and siloed systems within their care environments. With the Cloud Healthcare API and our partner ecosystem, our goal is to make it as simple as possible for the industry to make informed, data-driven decisions, so that caregivers can focus on what matters most: saving lives. Additional solutions to support healthcare providers in the fight against COVID-19 In addition to the Cloud Healthcare API, we are highlighting a number of solutions this week to help healthcare organizations, researchers, and patients navigate the COVID-19 pandemic. Working in partnership with Google Search, YouTube, Google Maps Platform, and other groups across Alphabet, these solutions include:Virtual care and telehealth services—Healthcare providers can offer patients video appointments through Google Meet and leverage G Suite to keep patient information in Google Docs, Sheets or other files stored in Google Drive that can be accessed and updated from anywhere using laptops, tablets or smartphones, all while maintaining data security and HIPAA compliance. Collaboration capabilities for remote work—With G Suite and Google Meet, healthcare and life science organizations are able to virtually connect with colleagues to drive conversations and projects forward while dealing with the new norm of remote working mandates. And with Chrome Enterprise, healthcare providers, like Hackensack Meridian Health, are freed from fixed workstations with mobile access to the files and information they need on the go.24/7 conversational self-service support—Our new Rapid Response Virtual Agent, which launched last week, helps organizations like the University of Pennsylvania provide immediate responses to patients and disseminate accurate information quickly during this critical time—taking the burden off overworked health hotlines and call centers.High-demand public health datasets—We’re helping healthcare organizations study COVID-19 with a pre-hosted repository of public healthcare datasets. And local providers and emergency planners can also apply Looker’s pre-built analyses and dashboards to these datasets.Visualization of essential services—Using Google Maps Platform in conjunction with COVID-19 datasets, healthcare organizations can locate critical equipment, provide testing site locations, give patients directions, and route medical deliveries to recipients. Earlier this month, we announced a new initiative with HCA Healthcare and SADA, called the National Response Portal, to help U.S. hospital systems better track important data on ventilator utilization, ICU bed capacity, COVID-19 testing results and more.Google Cloud research credits—We’re also enabling researchers, educational institutions, non-profits, and pharma companies to advance their COVID-19 research by accessing scalable computing power. Eligible organizations can apply for research credits to receive funding for projects related to potential treatments, techniques, and datasets. See Eligibility and FAQs.Although we’re still in the early days of this fight, the stronger we work together as businesses, organizations, and communities, the better we’re able to secure positive outcomes. We’re here to help, and we have teams working closely with healthcare organizations across the country to support the unique needs that are emerging in response to COVID-19. We’re amazed by the global response we’ve seen to date, and are humbled by the opportunity to continue to play a key part in helping healthcare organizations deliver care during the pandemic. To learn more about what we are doing, and how we might be able to help, please visit: cloud.google.com/covid19-healthcare.
Quelle: Google Cloud Platform

One of the greatest benefits of running in the cloud is being able to scale up and down to meet demand and reduce operational expenditures. And that’s especially true when you’re experiencing unexpected changes in customer demand.Here at Google Cloud, we have an entire team of Solutions Architects dedicated to helping customers manage their cloud operating expenses. Over the years working with our largest customers, we’ve identified some common things people tend to miss when looking for ways to optimize costs, and compiled them here for you. We think that following these best practices will help you rightsize your cloud costs to the needs of your business, so you can get through these challenging, unpredictable times. 1. Get to know billing and cost management toolsDue to the on-demand, variable nature of cloud, costs have a way of creeping up on you if you’re not monitoring them closely. Once you understand your costs, you can start to put controls in place and optimize your spending. To help with this, Google Cloud provides a robust set of no-cost billing and cost management tools that can give you the visibility and insights you need to keep up with your cloud deployment.At a high level, learn to look for things like “which projects cost the most, and why?” To start, organize and structure your costs in relation to your business needs. Then, drill down into the services using Billing reports to get an at-a-glance view of your costs. You should also learn how to attribute costs back to departments or teams using labels and build your own custom dashboards for more granular cost views. You can also use quotas, budgets, and alerts to closely monitor your current cost trends and forecast them over time, to reduce the risk of overspending. If you aren’t familiar with our billing and cost management tools, we are offering free training for a limited time to help you learn the fundamentals of understanding and optimizing your Google Cloud costs. For a comprehensive step by step guide, see our Guide to Cloud Billing and watch our Beyond Your Bill video series. Be sure to also check out these hands-on training courses: Understanding your Google Cloud Costs and Optimizing your GCP Costs.2. Only pay for the compute you needNow that you have better visibility in your cloud spend, it’s time to set your sights on your most expensive project(s) to identify compute resources that aren’t providing enough business value.Identify idle VMs (and disks): The easiest way to reduce your Google Cloud Platform (GCP) bill is to get rid of resources that are no longer being used. Think about those proof-of-concept projects that have since been deprioritized, or zombie instances that nobody bothered to delete. Google Cloud offers several Recommenders that can help you optimize these resources, including an idle VM recommender that identifies inactive virtual machines (VMs) and persistent disks based on usage metrics. Always tread carefully when deleting a VM, though. Before deleting a resource, ask yourself, “what potential impact will deleting this resource have and how can I recreate it, if necessary?” Deleting instances gets rid of the underlying disk(s) and all of its data. One best practice is to take a snapshot of the instance before deleting it. Alternatively, you can choose to simply stop the VM, which terminates the instance, but keeps resources like disks or IP addresses until you detach or delete them. For more info, read therecommender documentation. And stay tuned as we add more usage-based recommenders to the portfolio. Schedule VMs to auto start and stop: The benefit of a platform like Compute Engineis that you only pay for the compute resources that you use. Production systems tend to run 24/7; however, VMs in development, test or personal environments tend to only be used during business hours, and turning them off can save you a lot of money! For example, a VM that runs for 10 hours per day, Monday through Friday costs 75% less to run per month compared to leaving it running. To get started, here’s a serverless solution that we developed to help you automate and manage automated VM shutdown at scale.Rightsize VMs: On Google Cloud, you can already realize significant savings by creating custom machine type with the right amount of CPU and RAM to meet your needs. But workload requirements can change over time. Instances that were once optimized may now be servicing fewer users and traffic. To help, our rightsizing recommendations can show you how to effectively downsize your machine type based on changes in vCPU and RAM usage. These rightsizing recommendations for your instance’s machine type (or managed instance group) are generated using system metrics gathered by Cloud Monitoring over the previous eight days.For organizations that use infrastructure as code to manage their environments, check out this guide, which will show you how to deploy VM rightsizing recommendations at scale. Leverage preemptible VMs: Preemptible VMs are highly affordable compute instances that live up to 24 hours and that are up to 80% cheaper than regular instances. Preemptible VMs are a great fit for fault tolerant workloads such as big data, genomics, media transcoding, financial modelling and simulation. You can also use a mix of regular and preemptible instances to finish compute-intensive workloads faster and cost-effectively, by setting up a specialized managed instance group. But why limit preemptible VMs to a Compute Engine environment? Did you know GPUs, GKE clusters and secondary instances in Dataproc can also use preemptible VMs? And now, you can also reduce your Cloud Dataflow streaming (and batch) analytics costs by using Flexible Resource Scheduling to supplement regular instances with preemptible VMs.3. Optimize Cloud Storage costs and performanceWhen you run in your own data center, storage tends to get lost in your overall infrastructure costs, making it harder to do proper cost management. But in the cloud, where storage is billed as a separate line item, paying attention to storage utilization and configuration can result in substantial cost savings. And storage needs, like compute, are always changing. It’s possible that the storage class you picked when you first set up your environment may no longer be appropriate for a given workload. Also, Cloud Storage has come a long way—it offers a lot of new features that weren’t there just a year ago.If you’re looking to save on storage, here are some good places to look. Storage classes: Cloud Storage offers a variety of storage classes—standard, nearline, coldline and archival, all with varying costs and their own best-fit use cases. If you only use the standard class, it might be time to take a look at your workloads and reevaluate how frequently your data is being accessed. In our experience, many companies use standard class storage for archival purposes, and could reduce their spend by taking advantage of nearline or coldline class storage. And in some cases, if you are holding onto objects for cold-storage use cases like legal discovery, the new archival class storage might offer even more savings.Lifecycle policies: Not only can you save money by using different storage classes, but you can make it happen automatically with object lifecycle management. By configuring a lifecycle policy, you can programmatically set an object to adjust its storage class based on a set of conditions—or even delete it entirely if it’s no longer needed. For example, imagine you and your team analyze data within the first month it’s created; beyond that, you only need it for regulatory purposes. In that case, simply set a policy that adjusts your storage to coldline or archive after your object reaches 31 days.Deduplication: Another common source of waste in storage environments is duplicate data. Of course, there are times when it’s necessary. For instance, you may want to duplicate a dataset across multiple geographic regions so that local teams can access it quickly. However, in our experience working with customers, a lot of duplicate data is the result of lax version control, and the resulting duplicates can be cumbersome and expensive to manage. Luckily, there are lots of ways to prevent duplicate data, as well as tools to prevent data from being deleted in error. Here are a few things to consider:If you’re trying to maintain resiliency with a single source of truth, it may make more sense to use a multi-region bucket rather than creating multiple copies in various buckets. With this feature, you will have geo redundancy enabled for objects stored. This will ensure your data is replicated asynchronously across two or more locations. This protects against regional failures in the event of a natural disaster.A lot of duplicate data comes from not properly using the Cloud Storage object versioning feature. Object versioning prevents data from being overwritten or accidentally deleted, but the duplicates it creates can really add up. Do you really need five copies of your data? One might be enough as long as it’s protected. Worried you won’t be able to roll back? You can set up object versioning policies to ensure you have an appropriate number of copies. Still worried about losing something accidentally? Consider using the bucket lock feature, which helps ensure that items aren’t deleted before a specific date or time. This is really useful for demonstrating compliance with several important regulations. In short, if you use object versioning, there are several features you can use to keep your data safe without wasting space unnecessarily. 4. Tune your data warehouseOrganizations of all sizes look to BigQuery for a modern approach to data analytics. However, some configurations are more expensive than others. Let’s do a quick check of your BigQuery environment and set up some guardrails to help you keep costs down. Enforce controls: The last thing you need is a long query to run forever and rack up costs. To limit query costs, use the maximum bytes billed setting. Going above the limit will cause the query to fail, but you also won’t get charged for it, as shown below.Along with enabling cost control on a query level, you can apply similar logic to users and projects as well.Use partitioning and clustering: Partitioning and clustering your tables, whenever possible, can help greatly reduce the cost of processing queries, as well as improve performance. Today, you can partition a table based on ingestion time, date, timestamp or integer range column. To make sure your queries and jobs are taking advantage of partitioned tables, we also recommend you enable the Require partition filter, which forces users to include the partition column in the WHERE clause. Another benefit of partitioning is that BigQuery automatically drops the price of data stored by 50% for each partition or table that hasn’t been edited in 90 days, by moving it into long-term storage. It is more cost-effective and convenient to keep your data in BigQuery rather than going through hassles of migrating it to lower tiered storage. There is no degradation of performance, durability, availability or any other functionality when a table or partition is moved to long-term storage.Check for streaming inserts: You can load data into BigQuery in two ways: as a batch load job, or with real-time streaming, using streaming inserts. When optimizing your BigQuery costs, the first thing to do is check your bill and see if you are being charged for streaming inserts. And if you are, ask yourself, “Do I need data to be immediately available (seconds instead of hours) in BigQuery?” and “Am I using this data for any real-time use case once the data is available in BigQuery?” If the answer to either of these questions is no, then we recommend you to switch to batch loading data, which is free.Use Flex Slots: By default, BigQuery charges you variable on-demand pricing based on bytes processed by your queries. If you are a high-volume customer with stable workloads, you may find it more cost effective to switch from on-demand to flat rate pricing, which gives you an ability to process unlimited bytes for a fixed predictable cost. Given rapidly changing business requirements, we recently introduced Flex Slots, a new way to purchase BigQuery slots for duration as short as 60 seconds, on top of monthly and annual flat-rate commitments. With this combination of on-demand and flat-rate pricing, you can respond quickly and cost-effectively to changing demand for analytics.5. Filter that network packetLogging and monitoring are the cornerstones of network and security operations. But with environments that span clouds and on-premises environments, getting clear and comprehensive visibility into your network usage can be as hard as identifying how much electricity your microwave used last month. In fact, Google Cloud comes with several tools that can give you visibility into your network traffic (and therefore costs). There are also some quick and dirty configuration changes you can make to bring your network costs down, fast. Let’s take a look.Identify your “top talkers”: Ever wonder which services are taking up your bandwidth? Cloud Platform SKUs is a quick way to identify how much you are spending on a given Google Cloud service. It’s also important to know your network layout and how traffic flows between your applications and users. Network Topology, a module of Network Intelligence Center, provides you comprehensive visibility into your global GCP deployment and its interaction with the public internet, including an organization-wide view of the topology, and associated network performance metrics. This allows you to identify inefficient deployments and take necessary actions to optimize your regional and intercontinental network egress cost. Checkout this brief video for an overview of Network Intelligence Center and Network Topology. Network Service Tiers: Google Cloud lets you choose between two network service tiers: premium and standard. For excellent performance around the globe, you can choose premium tier, which continues to be our tier of choice. Standard tier offers a lower performance, but may be a suitable alternative for some cost-sensitive workloads. Cloud Logging: You may not know it, but you do have control over network traffic visibility by filtering out logs that you no longer need. Check out some common examples of logs that you can safely exclude.The same applies to Data Access audit logs, which can be quite large and incur additional costs. For example you probably don’t need to log them for development projects. For VPC Flow Logs and Cloud Load Balancing, you can also enable sampling, which can dramatically reduce the volume of log traffic being written into the database. You can set this from 1.0 (100% log entries are kept) to 0.0 (0%, no logs are kept). For troubleshooting or custom use cases, you can always choose to collect telemetry for a particular VPC network or subnet or drill down further to monitor a specific VM Instance or virtual interface.Want more?Whether you’re an early-stage startup or a large enterprise with a global footprint, everyone wants to be smart with their money right now. Following the tips in this blog post will get you on your way. For more on optimizing your Google Cloud costs, check out our Cost Management video playlist, as well as deeper dives into other Cloud Storage, BigQuery, Networking, Compute Engine, and Cloud Logging and Monitoring cost optimization strategies.
Quelle: Google Cloud Platform
As the world fights to bring the COVID-19 pandemic under control, another crisis looms.
In late 2018, the UN Intergovernmental Panel on Climate Change (IPCC) warned that if we want to avoid the worst impacts of climate change, we need to cut global carbon emissions almost in half by 2030. This decade will be critical.
As we’ve stated in the past, the time to act is now — we simply cannot continue business as usual, and this proves resoundingly true this year. We are in a time of maximum uncertainty and urgency.
Earth Day Live: April 22-24
Earth Day Live is a three-day livestream and an epic community mobilization to show support for our planet, through which millions of people can tune in online alongside activists, celebrities, musicians, and more. The massive live event — which starts on April 22 and concludes on April 24 — is organized by climate, environmental, and Indigenous groups within the US Climate Strike Coalition and Stop The Money Pipeline Coalition.
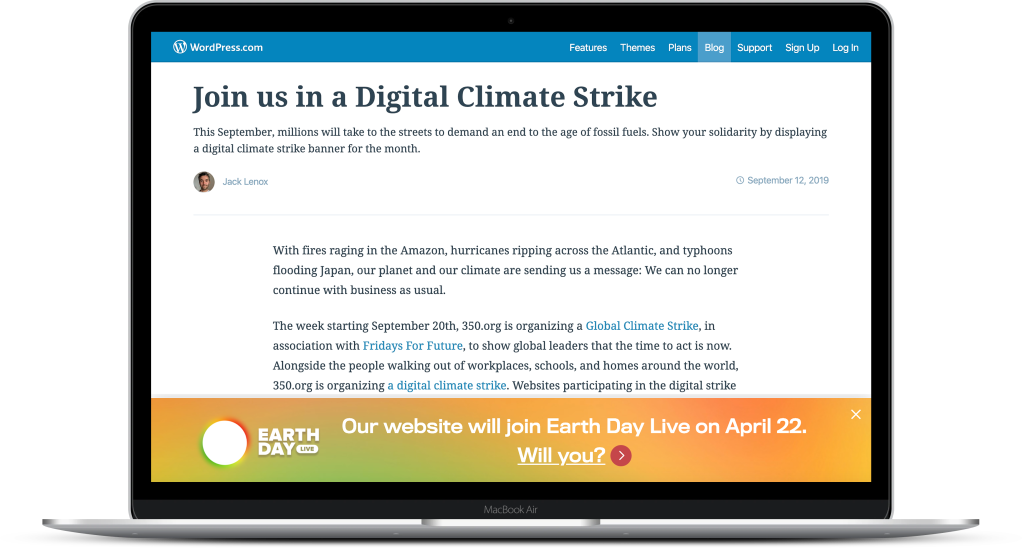
Starting today, you can opt into displaying a banner that promotes Earth Day Live on your WordPress.com site, showing your commitment to this critical topic and spreading the word about the digital event and livestream. On April 22, sites with this feature enabled will automatically display a full-screen overlay message. Your site visitors will be able to dismiss the banner once viewed.
Promote this global movement on your site
To activate the banner, go to My Site → Manage → Settings. At the top of the Settings menu, you will see a toggle switch — flip it on to join this digital climate strike.
Self-hosted WordPress sites can also join the movement by installing the Earth Day Live WP plugin from the WordPress.org plugin repository.
After the livestream ends, the banner will disappear on its own — no further action is required on your end. (If you’ve installed the plugin, it will automatically disable.)
Together we can make a difference. We hope you’ll join us in supporting this movement.
Visit Earth Day Live for event details, and explore more digital Earth Day initiatives and resources on WordPress so you can take action on April 22 — or any day.
Quelle: RedHat Stack

The COVID-19 pandemic is affecting organizations in different ways, whether it’s hospitals or governments directly impacted by the coronavirus or businesses that need to rapidly evolve to support new work-from-home scenarios. Over the last few weeks, we’ve had numerous conversations with customers about how we can help them adapt to new ways of working, while keeping their data protected. As the number of remote workers increases drastically in a short period of time, one thing we’ve heard repeatedly is that organizations need an easier way to provide access to key internal applications. Workers can’t get to customer service systems, call center applications, software bug trackers, project management dashboards, employee portals, and many other web apps that they can normally get to through a browser when they’re on the corporate network in an office.To help customers solve this problem and get their workers the access they need, today, we’re introducing BeyondCorp Remote Access. This cloud solution—based on the zero-trust approach we’ve used internally for almost a decade—lets your employees and extended workforce access internal web apps from virtually any device, anywhere, without a traditional remote-access VPN. Over time, we plan to offer the same capability, control, and additional protections for virtually any application or resource a user needs to access.BeyondCorp Remote Access’s high-level architecture.Let’s take a deeper look at today’s pressing remote access challenge and our solution.The VPN issueThe root problem lies with the remote-access VPNs organizations normally use. Traditional VPN infrastructure can be difficult for IT teams to deploy and manage for so many new users in a short period of time, and they’re struggling under the load. From the user perspective, VPNs can be complex, especially for those who haven’t used one before. These problems are exacerbated when organizations try to roll out VPN access to their extended workforce of contractors, temporary employees, and partners. VPNs can also increase risk since they extend the organization’s network perimeter, and many organizations assume that every user inside the perimeter is trusted.Our approach to remote accessWe believe there’s a better way. Recently, as we’ve asked most of our employees and extended workforce to work from home due to COVID-19, their ability to access apps and get work done has not been significantly affected. We didn’t just roll this new capability out. In 2011, we started our journey to implement a zero-trust access approach we called BeyondCorp. Our mission was to enable Google employees and our extended workforce to work successfully from untrusted networks on a variety of devices without using a client-side VPN.BeyondCorp’s high-level architecture.But BeyondCorp offers much more than a simpler, more modern VPN replacement. It helps ensure that only the right users access the right information in the right context. For example, you can enforce a policy that says: “My contract HR recruiters working from home on their own laptops can access our web-based document management system (and nothing else), but only if they are using the latest version of the OS, and are using phishing-resistant authentication like security keys.” Or: “My timecard application should be safely available to all hourly employees on any device, anywhere.”Defining access policies in BeyondCorp Remote Access.BeyondCorp delivers the familiar user experience that helps make our employees and extended workforce productive inside the office, along with the heightened security and control we require outside.Get started with a proven solutionWhile we’ve been big supporters of this zero-trust access approach for many years, we know it’s not something that most organizations will deploy overnight. However, you can get started today solving the pressing problem of remote access to internal web apps for a specific set of users. With BeyondCorp Remote Access, we can help you do this in days rather than the months that it might take to roll out a traditional VPN solution, whether your applications are hosted in the cloud or deployed in your datacenter. We are partnering with Deloitte’s industry-leading cyber practice to deliver end-to-end architecture, design, and deployment services to support your zero-trust journey. The components of the solution are based on Google’s own decade of experience implementing the BeyondCorp model and have been “battle-tested” in production by thousands of Google Cloud customers, including New York City Cyber Command:”We are responsible for leading the cyber defense of America’s largest city,” said Colin Ahern, Deputy CISO atNew York City Cyber Command. “It is vital that our Agency personnel are able to access critical applications no matter the situation or location. Google’s BeyondCorp has allowed us to build a zero-trust environment where our team can quickly and securely access essential resources from untrusted networks.”We’re committed to helping you meet the immediate need for rapid rollout of remote access today, while enabling you to build a more secure foundation for a modern, zero-trust access model tomorrow. If this is something that might be useful for your organization, get in touch, we’re eager to help.
Quelle: Google Cloud Platform

This blog post was co-authored by Chad Raynor, Principal Program Manager, Azure Maps.
Updates to Azure Maps services include new and recently added features, including the general availability of Azure Maps services on Microsoft Azure Government cloud. Here is a rundown of the new and recently added features for Azure Maps services:
Azure Maps is now generally available on Azure Government cloud
The general availability of Azure Maps for Azure Government cloud allows you to easily include geospatial and location intelligence capabilities in solutions deployed on Azure Government cloud with the quality, performance, and reliability required for enterprise grade applications. Microsoft Azure Government delivers a cloud platform built upon the foundational principles of security, privacy and control, compliance, and transparency. Public sector entities receive a physically isolated instance of Microsoft Azure that employs world-class security and compliance services critical to the US government for all systems and applications built on its architecture.
Azure Maps Batch services are generally available
Azure Maps Batch capabilities available through Search and Route services are now generally available. Batch services allows customers to send batches of queries using just a single API request.
Batch capabilities are supported by the following APIs:
Post Search Address Batch
Post Search Address Reverse Batch
Post Search Fuzzy Batch
Post Route Directions Batch
What’s new for the Azure Maps Batch services?
Users have now an option to submit synchronous (sync) request, which is designed for lightweight batch requests. When the service receives a request, it will respond as soon as the batch items are calculated instead of returning a 202 along with a redirect URL. With sync API there will be no possibility to retrieve the results later. When Azure Maps receives sync request, it responds as soon as the batch items are calculated. For large batches, we recommend continuing to use the Asynchronous API that is appropriate for processing big volumes of relatively complex route requests.
For Search APIs, the Asynchronous API allows developers to batch up to 10,000 queries and sync API up to 100 queries. For Route APIs, the Asynchronous API allows developers to batch up to 700 queries and sync API up to 100 queries.
Azure Maps Matrix Routing service is generally available
The Matrix Routing API is now generally available. The service allows calculation of a matrix of route summaries for a set of routes defined by origin and destination locations. For every given origin, the service calculates the travel time and distance of routing from that origin to every given destination.
For example, let's say a food delivery company has 20 drivers and they need to find the closest driver to pick up the delivery from the restaurant. To solve this use case, they can call Matrix Route API.
What’s new in the Azure Maps Matrix Routing service?
The team worked to improve the Matrix Routing performance and added support to submit synchronous request like for the batch services described above. The maximum size of a matrix for asynchronous request is 700 and for synchronous request it's 100 (the number of origins multiplied by the number of destinations).
For Asynchronous API calls we introduced new waitForResults parameter. If this parameter is set to be true, user will get a 200 response if the request is finished under 120 seconds. Otherwise, user will get a 202 response right away and async API will return users an URL to check the progress of async request in the location header of the response.
Updates for Render services
Introducing Get Map tile v2 API in preview
Like Azure Maps Get Map Tiles API v1, our new Get Map Tile version 2 API, in preview, allows users to request map tiles in vector or raster format typically to be integrated into a map control or SDK. The service allows to request various map tiles, such as Azure Maps road tiles or real-time Weather Radar tiles. By default, Azure Maps uses vector map tiles for its SDKs.
The new version will offer users more consistent way to request data. The new version introduces a concept of tileset, a collection of raster or vector data that are further broken up into a uniform grid of square tiles at preset zoom levels. Every tileset has a tilesetId to request a specific tileset. For example, microsoft.base.
Also, Get Map Tile v2now supports the option to call imagery data that was earlier only available through Get Map Imagery Tile API. In addition, Azure Maps Weather Service radar and infrared map tiles are only available through the version 2.
Dark grey map style available through Get Map Tile and Get Map Image APIs
In addition to serve the Azure Maps dark grey map style through our SDKs, customers can now also access it through Get Map Tile APIs (version 1 and version 2) and Get Map Image API in vector and raster format. This empowers customers to create rich map visualizations, such as embedding a map image into a web page.
Azure Maps dark grey map style.
Route service: Avoid border crossings, pass in custom areas to avoid
The Azure Maps team has continued to make improvements to the Routing APIs. We have added new parameter value avoid=borderCrossings to support routing scenarios where vehicles are required to avoid country/region border crossings, and keep the route within one country.
To offer more advanced vehicle routing capabilities, customers can now include areas to avoid in their POST Route Directions API request. For example, a customer might want to avoid sending their vehicles to a specific area because they are not allowed to operate in the area without a permission form the local authority. As a solution, users can now pass in the route request POST body polygons in GeoJSON format as a list of areas to avoid.
Cartographic and styling updates
Display building models
Through Azure Maps map control, users have now option to render 2.5D building models on the map. By default, all buildings are rendered as just their footprints. By setting showBuildingModels to true, buildings will be rendered with their 2.5D models. Try the feature now.
Display building models.
Islands, borders, and country/region polygons
To improve the user experience and give more detailed views, we reduced the boundary data simplification reduction to offer better visual experience at higher zoom levels. User can now see more detailed polygon boundary data.
Left: Before boundary data simplification reduction. Right: After boundary data simplification reduction.
National Park labeling and data rendering
Based on feedback from our users, we simplified labels for scatters polygons by reducing the number of labels. Also, National park and National Forest labels are displayed already on zoom level 6.
National Park and National Forest labels displayed on zoom level 6.
Send us your feedback
We always appreciate feedback from the community. Feel free to comment below, post questions to Stack Overflow, or submit feature requests to the Azure Maps Feedback UserVoice.
Quelle: Azure
Multistage builds feature in Dockerfiles enables you to create smaller container images with better caching and smaller security footprint. In this blog post, I’ll show some more advanced patterns that go beyond copying files between a build and a runtime stage, allowing to get most out of the feature. If you are new to multistage builds you probably want to start by reading the usage guide first.
Note on BuildKit
The latest Docker versions come with new opt-in builder backend BuildKit. While all the patterns here work with the older builder as well, many of them run much more efficiently when BuildKit backend is enabled. For example, BuildKit efficiently skips unused stages and builds stages concurrently when possible. I’ve marked these cases under the individual examples. If you use these patterns, enabling BuildKit is strongly recommended. All other BuildKit based builders support these patterns as well.
• • •
Inheriting from a stage
Multistage builds added a couple of new syntax concepts. First of all, you can name a stage that starts with a FROM command with AS stagename and use –from=stagename option in a COPY command to copy files from that stage. In fact, FROM command and –from flag have much more in common and it is not accidental that they are named the same. They both take the same argument, resolve it and then either start a new stage from that point or use it as a source for file copy.
That means that same way as you can use –from=stagename you can also use FROM stagename to use a previous stage as a source image for your current stage. This is useful when multiple commands in the Dockerfile share the same common parts. It makes the shared code smaller and easier to maintain while keeping the child stages separate so that when one is rebuilt it doesn’t invalidate the build cache for the others. Each stage can also be built individually using the –target flag while invoking docker build.
FROM ubuntu AS baseRUN apt-get update && apt-get install gitFROM base AS src1RUN git clone …FROM base AS src2RUN git clone …
In BuildKit, the second and third stage in this example would be built concurrently.
Using images directly
Similarly to using build stage names in FROM commands that previously only supported image references, we can turn this around and directly use images with –fromflag. This allows copying files directly from other images. For example, in the following code, we can use linuxkit/ca-certificates image to directly copy the TLS CA roots into our current stage.
FROM alpineCOPY –from=linuxkit/ca-certificates / /
Alias for a common image
A build stage doesn’t need to contain any commands — it may just be a single FROM line. When you are using an image in multiple places this can be useful to improve readability and making sure that when a shared image needs to be updated, only a single line needs to be changed.
FROM alpine:3.6 AS alpineFROM alpineRUN …FROM alpineRUN …
In this example, any place that uses image alpine is actually fixed to alpine:3.6 not alpine:latest. When it comes time to update to alpine:3.7, only a single line needs to be changed and we can be sure that all parts of the build are now using the updated version.
This is even more powerful when a build argument is used in the alias. The following example is equal to the previous one but lets the user override all the instances the alpine image is being used in this build with setting the –build-arg ALPINE_VERSION=value option. Remember that any arguments used in FROM commands need to be defined before the first build stage.
ARG ALPINE_VERSION=3.6FROM alpine:${ALPINE_VERSION} AS alpineFROM alpineRUN …
Using build arguments in ` — from`
The value specified in –from flag of the COPY command may not contain build arguments. For example, the following example is not valid:
// THIS EXAMPLE IS INTENTIONALLY INVALIDFROM alpine AS build-stage0RUN …FROM alpineARG src=stage0COPY –from=build-${src} . .
This is because the dependencies between the stages need to be determined before the build can start, so that we don’t need to evaluate all commands every time. For example, an environment variable defined in alpine image could have an effect on the evaluation of the –from value. The reason we can evaluate the arguments for the FROM command is that these arguments are defined globally before any stage begins. Luckily, as we learned before, we can just define an alias stage with a single FROM command and refer that instead.
ARG src=stage0FROM alpine AS build-stage0RUN …FROM build-${src} AS copy-srcFROM alpineCOPY –from=copy-src . .
Overriding a build argument src would now cause the source stage for the final COPY element to switch. Note that if this causes some stages to become unused, only BuildKit based builders have the capability to efficiently skip these stages so they never run.
Conditions using build arguments
There have been requests to add IF/ELSE style conditions support in Dockerfiles. It is unclear yet if something like this will be added in the future — with the help of custom frontends support in BuildKit we may try that in the future. Meanwhile, with some planning, there is a possibility to use current multistage concepts to get a similar behavior.
// THIS EXAMPLE IS INTENTIONALLY INVALIDFROM alpineRUN …ARG BUILD_VERSION=1IF $BUILD_VERSION==1RUN touch version1ELSE IF $BUILD_VERSION==2RUN touch version2DONERUN …
The previous example shows pseudocode how conditions could be written with IF/ELSE. To have the same behavior with current multistage builds you would need to define different branch conditions as separate stages and use an argument to pick the correct dependency path.
ARG BUILD_VERSION=1FROM alpine AS baseRUN …FROM base AS branch-version-1RUN touch version1FROM base AS branch-version-2RUN touch version2FROM branch-version-${BUILD_VERSION} AS after-conditionFROM after-condition RUN …
The last stage in this Dockerfile is based on after-condition stage that is an alias to an image that is resolved by BUILD_VERSION build argument. Depending on the value of BUILD_VERSION, a different middle section stage is picked.
Note that only BuildKit based builders can skip the unused branches. In previous builders all stages would be still built, but their results would be discarded before creating the final image.
Development/test helper for minimal production stage
Let’s finish up with an example of combining the previous patterns to show how to create a Dockerfile that creates a minimal production image and then can use the contents of it for running tests or for creating a development image. Start with a basic example Dockerfile:
FROM golang:alpine AS stage0…FROM golang:alpine AS stage1…FROM scratchCOPY –from=stage0 /binary0 /binCOPY –from=stage1 /binary1 /bin
This is quite a common when creating a minimal production image. But what if you wanted to also get an alternative developer image or run tests with these binaries in the final stage? An obvious way would be just to copy the same binaries to the test and developer stages as well. A problem with that is that there isn’t a guarantee that you will test all the production binaries in the same combination. Something may change in the final stage and you may forget to make identical changes to the other stages or make a mistake to the path where the binaries are copied. After all, we want to test the final image not an individual binary.
An alternative pattern would be to define a developer and test stage after production stage and copy the whole production stage contents. A single FROM command with the production stage can be then used to make the production stage default again as the last step.
FROM golang:alpine AS stage0…FROM scratch AS releaseCOPY –from=stage0 /binary0 /binCOPY –from=stage1 /binary1 /binFROM golang:alpine AS dev-envCOPY –from=release / /ENTRYPOINT [“ash”]FROM golang:alpine AS testCOPY –from=release / /RUN go test …FROM release
By default, this Dockerfile will continue building the default minimal image, while building for example with –target=dev-env option will now build an image with a shell that always contains the full release binaries.
• • •
I hope this was helpful and gave you some ideas for creating more efficient multistage Dockerfiles. You can use the BuildKit repository to track the new developments for more efficient builds and new Dockerfile features. If you need help, you can join the #buildkit channel in Docker Community Slack.
The post Advanced Dockerfiles: Faster Builds and Smaller Images Using BuildKit and Multistage Builds appeared first on Docker Blog.
Quelle: https://blog.docker.com/feed/