Coronakrise: Netflix stellt Dokus kostenlos auf Youtube
Tierfilme und mehr: Wegen geschlossener Schulen in den USA hat Netflix viele Dokus kostenlos im Netz veröffentlicht. (Netflix, Video-Community)
Quelle: Golem

Tierfilme und mehr: Wegen geschlossener Schulen in den USA hat Netflix viele Dokus kostenlos im Netz veröffentlicht. (Netflix, Video-Community)
Quelle: Golem

An der Supermarktkasse könnte man seine Tiefkühlpizza irgendwann mit einer Karte von Google bezahlen – es gibt sogar schon erste Bilder. (Google, Apple)
Quelle: Golem

Die EU ist bei den Bewilligungen für den Ausbau des Glasfasernetzes zu langsam, so der Vorwurf von Bundestagsabgeordneten aus CDU und CSU. (Glasfaser, Telekom)
Quelle: Golem

Da wird jeder Abteilungsleiter zum Jedi: Disney hat Hintergrundbilder mit Star-Wars-Motiven für Videokonferenzen veröffentlicht. (Videotelefonie, Microsoft)
Quelle: Golem
Starting a new website can be a bit overwhelming but we’re here to help! Beginning Monday, April 20th, WordPress.com will host free, 30-minute live webinars to cover those initial questions that come up as you start to build your website. Each day will cover a different topic, all designed to give actionable advice on how to create the type of website you want.
Date: Starts April 20, 2020 and repeats daily Monday thru Friday
Weekly Schedule:
Mondays – Getting Started: Website Building 101Tuesdays – Quick Start: Payments (Simple and Recurring)Wednesdays – Quick Start: BloggingThursdays – Quick Start: WooCommerce 101Fridays – Empezando: Construcción de Sitios Web 101
Time: 09:00 am PDT | 10:00 am CDT | 12:00 pm EDT | 16:00 UTC
Who’s Invited: New WordPress.com users and anyone interested in learning more about WordPress.com’s website capabilities.
Register Here: https://wordpress.com/webinars/
Our WordPress.com customer service team, we call them Happiness Engineers, are experts in helping new users get up and running on their new websites. Across each week of webinars we’ll cover questions about the basics of setting up your website, handling simple and recurring payments, blogging best practices, and adding in eCommerce capabilities. Come with questions as you’ll be able to submit them beforehand—in the registration form—and during the live webinar.
Everyone is welcome, even if you already have a site set up. We know you’re busy, so if you can’t make the live event, you’ll be able to watch a recording of the webinar on our YouTube channel.
Live attendance is limited, so be sure to register early. We look forward to seeing you on the webinar!
Quelle: RedHat Stack
The post Securing Your Containers Isn’t Enough — Webinar Q&A appeared first on Mirantis | Pure Play Open Cloud.
Last week we presented a webinar with our partner Zettaset about containerized data encryption and why it’s important. Here are the answers to your questions, provided by Bryan Langston and Uday Shetty of Mirantis and Tim Reilly and Maksim Yankovskiy of Zettaset.
View webinar slides and recording
Why is encryption so important if we wrap our existing security around all workloads?
It goes back to why encrypting a containerized environment is different than with a legacy environment. The single word answer would be multi-tenancy. Multi-tenant datacenters usually depend on the segmentation of the hardware. Multi-tenant containerized environments are entirely in the software stack. So we cannot just take an existing, legacy encryption technology or security technology and apply it to the entire software stack of containers and just call it a day. We have to do something that’s specific to containers. We have to do something that integrates directly with containers and works seamlessly in the containerized environment.
What is the performance impact of encrypting data in containers? How do you ensure that encryption does not introduce latency when dealing with very large buckets? How can we reduce processing time?
With the Zettaset solution, we’re running in containers, but we’re running within the kernel and working at the block level using AES_NI instructions for fast cryptographic performance. We measure about a 3% performance hit for read and write using file system benchmark tests on the underlying encryption scheme. It performs just as well on large file systems as it does on small ones. You can reduce that performance hit by splitting your application across more containers on more CPUs.
Performance is critical because you don’t want your encryption solution to slow down your analytics system, bringing it down to its knees. It happened before, that’s why people are rightfully concerned. Minimizing performance overhead is one of the fundamentals of our solution.
What is the most common security incident reported for containers?
Bryan: Like Tim and Maksim have been talking about, the data breaches, storming the castle. Storming the castle is made possible by not locking down your environment in terms of network access policies, the RBAC, lack of implementation of least privilege. Think of a top secret security clearance in the government: information is granted on a need-to-know basis. Explicitly defining that will avoid a lot of problems. The most common security incident is access to data by someone who shouldn’t have it.
Maksim: The most common security incidents stem from improperly configured containerized environments that allow attackers to install malicious software on a single container and then from that single container distribute that malicious software to all other containers within the infrastructure. Malicious software then takes over the entire container infrastructure and has unrestricted access to containers and data. While tools such as intrusion detection and container image integrity scanners would help alert the admins of the breach, these tools would not protect the data from compromise. This emphasizes the need for data at rest encryption.
How big of a component of DevSecOps is encryption? If you take advantage of a solution like Zettaset, what else remains to say we have a “DevSecOps Practice?”
Bryan: Good question, it’s kind of like, “How do I know if I’m doing DevSecOps right?” I would phrase that as: Encryption needs to be as big as needed to satisfy your company’s risk management policy. Every company has a different level of risk. Every company has different subsets of controls within a security framework, like PCI for example, to which they have to comply. Just because you sell stuff over the Internet doesn’t mean you’re handling payment, for example. Your subset of controls for PCI might look different from other players in the same online reselling space. So it’s as big as needed to satisfy your company’s risk management policy. What your DevSecOps team has to enforce will vary.
One other thing to keep in mind is that the implementation of DevSecOps is a combination of both industry best practices and the layer of security that pertains to your company’s business model, like how I was just talking about risk management. There are very well defined industry best practices for many components — I’m talking about CIS benchmarks, stuff you can easily download and run and give a quick assessment to how you are doing compared to those benchmarks — but then you also have to define the layer that pertains to you.
In order to say “I have a DevSecOps practice,” we’re talking about having a team that focuses on understanding the attack vectors, and then identifying the controls that are relevant to your workload and your business, and then having the means to implement those controls from a technology perspective, whether that’s encryption, like we’re talking about here, or RBAC, or network policies or some of the other things that we discussed earlier, or all of them.
Nick: Is it fair to say that you’re better off with too much security than not enough security?
Bryan: Yeah, you want to stay off the front page of the headlines. I’m sure Marriott, in light of the current environment we’re in with coronavirus, did not need to exacerbate their problem with a security breach. So definitely, err on the side of caution.
Maksim: By the way, I don’t think there’s such a thing as too much security. There are things that you may choose not to implement, but there’s no such thing as too much security.
My containers are running on SEDs (Self Encrypting Drives). Do I still need Zettaset Container Encryption?
SEDs offer a simple approach to encrypting data. SEDs, however, are not suitable for properly securing container environments.
SEDs do not offer key granularity to address the fluid topology of container environments – containers will share SED partitions and data from different containers will be encrypted with the same key. In the event of a compromise, one bad actor container compromises all other containers that share the same SED.
Also, SEDs do not offer enterprise grade key management; some store keys on the drive, some rely on the OS to store the master key. Both of these approaches are not scalable and not secure.
Zettaset Container Encryption ensures that:
Each container is allocated its own storage volume mapped to a unique storage volume group that is encrypted with unique encryption key.
The container volume is only available when a container mounts it; the volume is automatically unmounted when the container exits.
The KMIP-compatible enterprise key manager running natively in a container provides secure key management infrastructure.
I am curious, I should be able to encrypt the disks before I make it an image, so before I run “docker build”, shouldn’t I be able to run the application when I run “docker run”?
The Docker build command builds the container image, which includes unmodifiable layers of OS, software, and data. This is not the data that Zettaset encrypts. Zettaset encrypts data that containers use and generate at runtime, the data that persists, essentially – production data.
How do you handle encryption when containers move from one host to another host?
When containers move between hosts, the data doesn’t necessarily move between the hosts, because the storage should not be associated with the hosts. In a typical distributed environment, when you have processes running on different hosts, this is addressed by having shared storage, but shared storage is still managed by Docker daemons, which are on hosts. So we are able to handle the storage allocation to the container on the shared volumes just like we are able to handle storage allocation to the containers on the volumes that are hardwired to the hosts.
So, we can use storage that is tied to the host, or we can use the storage that is shared between the Docker hosts. in addition, with centralized virtual key manager, we are able to provide access to container data regardless of which host container runs on. This goes hand-in-hand with the shared storage approach.
Does Docker Enterprise integrate with any Key Manager/ HSM?
Docker Enterprise doesn’t have any specific integrations with any HSM currently. UCP provides a certificate authority (for TLS, client bundles, node joining, API certs, etc) and DTR provides the notary (for image content trust). The cert authority can be a 3rd party.
Can you clarify the ephemeral nature of the key manager container, and how it securely accesses the keys (and how those are stored securely?) Can the system leverage key storage like KMS in AWS?
That question speaks to several important things. Yes, a key manager in a containerized environment should run in a container. There has been a lot of work on key managers over the last 20 years. We started with proprietary key managers, then we started moving to key managers supporting what is known as KMIP (Key Manager Interoperability Protocol), which is essentially a common language that every key manager out there speaks. The key manager running in a container is part of our solution. It is fully KMIP compatible, and integration has been tested with other encryption solutions, and of course ours.
Understanding that enterprise security requirements may be different, we provide you with a software-based key manager, but we also understand that you may already have investments in existing Gemalto/Safenet or Thales/Vormetric security key management infrastructure. We allow you to connect very simply and very easily to any existing key management infrastructure that you may have. We have a KMIP compatible key manager that stores the keys in a key database. The key database is secured with a hierarchy of master keys and hashed with appropriate hash keys. Those keys are stored in the software security module, which is essentially a software implementation of your typical Hardware Security Module (HSM). We’re also (as any solution should be) PKCS11 compliant, which means it can talk to HSM’s if required, which are essentially hardware devices that store master keys securely.
AWS KMS does not support the industry-standard Key Management Interoperability Protocol (KMIP) and because KMS is owned by the cloud provider, Zettaset recommends using a third-party key manager that allows the customer to own their keys. AWS’s policy is that “security is a shared responsibility” and this is the optimal way to implement it.
The reason why I’m saying all this and giving such a detailed and somewhat technical answer is that when you look at an encryption solution, you should make sure that it does a good job with housekeeping. If encryption is an afterthought, then believe me when I tell you, key management is not even on the map, but it should be.
How does your “driver” know what size storage to create if the developer isn’t doing anything different in docker. It seems that the developer would have to specify that size.
We talk about transparency, and now we’re saying, when you specify a volume, we need to know the size of the volume you allocate. So it’s an additional burden of the development to ask for a certain amount of storage.
There are three options that our solution is providing. One option is: Storage volumes can be preallocated by administrators, and that’s very well integrated with the Docker Create Volume command. So an administrator can specify a volume for, let’s say, a MySQL database and specify size there.
The second option is that an administrator, at the time of installation of our software, can specify the default size of the volume that the container will get, and then a developer simply runs the Docker Run command and doesn’t have to specify the size of the volume and the volume gets allocated.
The third options is that nothing gets specified, and we just specify a default value of the volume size, which is specified within the installation of the software.
So between the three, transparency should be addressed.
In a cloud-based Kubernetes offering such as AKS/EKS, most operational deployments provision separate block storage disks (EBS/Azure Disk) per container. Since there is a logical separation here, and containers aren’t sharing a disk, what does a product like Zettaset bring to the table?
While storage provisioning can provision separate AWS EBS devices per container, Zettaset allows for partitioning one (or small number) of storage devices for use by multiple containers, therefore dramatically reducing the number of EBS volumes required. In addition, Zettaset provides automated encryption and key management of those storage devices without the need to deploy encrypted EBS volumes.
How is RBAC here different than in K8s?
Zettaset XCrypt relies on K8s RBAC for access and permission management. In addition, XCrypt provides ability to securely decommission a K8s worker node completely, if a node is compromised. This is done with a single admin command without the need to have access to the node.
Can we use Azure key vault with this to store encryption keys for containers, and if yes, then how will it be communicating ?
We don’t support Azure key vaults at this time. Only KMIP compatible key managers.
As a Docker Enterprise Partner, can we offer Zettaset as an OEM product?
Mirantis values our partners and will consider what’s best for our customers and mutual business benefits. Please contact us with specific questions.
How is Zettaset integrated with Docker containers? Is it a layer above Docker Enterprise or something which is integrated within every Docker container? Can it be used with Docker Enterprise orchestration tools ?
Zettaset XCrypt integrates with Docker Enterprise by providing “XCrypt Volume Driver”, a Docker Volume Driver API-compatible driver that transparently integrates into the Docker storage management stack. It is fully usable with Docker Enterprise orchestration tools.
The post Securing Your Containers Isn’t Enough — Webinar Q&A appeared first on Mirantis | Pure Play Open Cloud.
Quelle: Mirantis

Nur in zwei Bundesländern dauert es etwas länger. Telefónica O2 kündigt zudem Sonderangebote an. (Telefónica, Mobilfunk)
Quelle: Golem

Diejenigen, die am anfälligsten für Covid-19 sind, haben immer noch keinen Internetzugang. (Internet, Studie)
Quelle: Golem
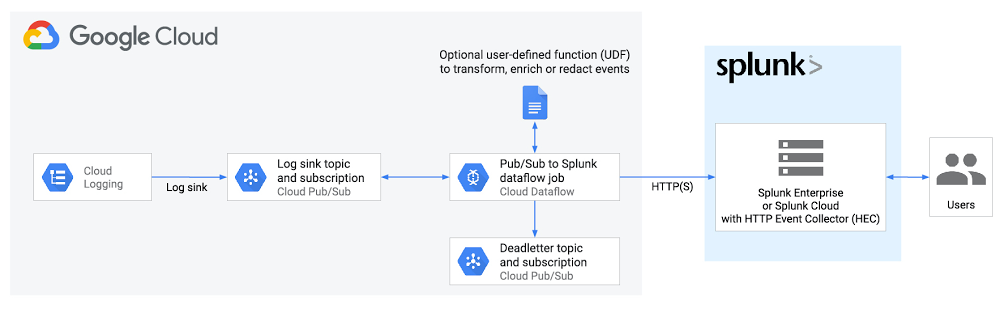
At Google Cloud, we’re focused on solving customer problems and meeting them where they are. Many of you use third-party monitoring solutions from Splunk to keep a tab on both on-prem and cloud environments. These use cases include IT ops, security, application development, and business analytics. In this blog post, we’ll show you how to set up a streaming pipeline to natively push your Google Cloud data to your Splunk Cloud or Splunk Enterprise instance using the recently released Pub/Sub to Splunk Dataflow template. Using this Dataflow template, you can export data from Pub/Sub to Splunk. So, any message that can be delivered to a Pub/Sub topic can now be forwarded to Splunk. That includes logs from Cloud Logging (formerly Stackdriver Logging), messages from IoT devices, or events such as security findings from Cloud Security Command Center. We hear that customers are using this template to meet the variety, velocity and volume of valuable data coming out of Google Cloud. “Google Cloud’s Pub/Sub to Splunk Dataflow template has been helpful for enabling Spotify Security to ingest highly variable log types into Splunk,” says Andy Gu, Security Engineer at Spotify. “Thanks to their efforts, we can leverage both Google’s Pub/Sub model and Splunk’s query capabilities to simplify the management of our detection and response infrastructure and process over eight million daily events.”The step-by-step walkthrough covers the entire setup, from configuring the originating log sinks in Cloud Logging to the final Splunk destination—the Splunk HTTP Event Collector (HEC) endpoint.Streaming vs. polling dataTraditionally, Splunk users have the option to pull logs from Google Cloud using Splunk Add-on for Google Cloud Platform as a data collector. Specifically, this add-on runs a Splunk modular input that periodically pulls logs from a Pub/Sub topic that’s configured as a log sink export. This documented solution works well, but it does include tradeoffs that need to be taken into account:Requires managing one or more data collectors (a.k.a., Splunk-heavy forwarders) with added operational complexity for high availability and scale-out with increased log volumeRequires external resource access to Google Cloud by giving permissions to aforementioned data collectors to establish subscription and pull data from Pub/Sub topic(s)We’ve heard from you that you need a more cloud-native approach that streams logs directly to a Splunk HTTP(S) endpoint, or Splunk HEC, without the need to manage an intermediary fleet of data collectors. This is where the managed Cloud Dataflow service comes into play: A Dataflow job can automatically pull logs from a Pub/Sub topic, parse and convert payloads into the Splunk HEC event format, apply an optional user-defined function (UDF) to transform or redact the logs, then finally forward to Splunk HEC. To facilitate this setup, Google released the Pub/Sub to Splunk Dataflow template with built-in capabilities like retry with exponential backoff (for resiliency to network failures or in case Splunk is down) and batch events and/or parallelize requests (for higher throughput) as detailed below. Set up logging export to SplunkThis is how the end-to-end logging export looks:Click to enlargeBelow are the steps that we’ll walk through:Set up Pub/Sub topics and subscriptionsSet up a log sinkSet IAM policy for Pub/Sub topicSet up Splunk HEC endpointSet up and deploy Pub/Sub to the Splunk Dataflow templateSet up Pub/Sub topics and subscriptionsFirst, set up a Pub/Sub topic that will receive your exported logs, and a Pub/Sub subscription that the Dataflow job can later pull logs from. You can do so via the Cloud Console or via CLI using gcloud. For example, using gcloud looks like this:Note: It is important to create the subscription before setting up the Cloud Logging sink to avoid losing any data added to the topic prior to the subscription getting created.Repeat the same steps for the Pub/Sub deadletter topic that holds any undeliverable message to Splunk HEC, due to misconfigurations such as an incorrect HEC token or any processing errors during execution of the optional UDF function (see more below) by Dataflow:Set up a Cloud Logging sinkCreate a log sink with the previously created Pub/Sub topic as destination. Again, you can do so via the Logs Viewer, or via CLI using gcloud logging. For example, to capture all logs in your current Google Cloud project (replace [MY_PROJECT]), use this code:Note: The Dataflow pipeline that we’ll be deploying will itself generate logs in Cloud Monitoring that will get pushed into Splunk, further generating logs and creating an exponential cycle. That’s why the log filter above explicitly excludes logs from a job named “pubsub2splunk” which is the arbitrary name of the Dataflow job we’ll use later on. Another way to avoid that cycle is to set up the logging export in a separate dedicated “logging” project—generally a best practice.Refer to sample queries for resource or service-specific logs to be used as the log-filter parameter value above. Similarly, refer to aggregated exports for examples of “gcloud logging sink” commands to export logs from all projects or folders in your Google Cloud organization, provided you have permissions. For example, you may choose to export the Cloud Audit Logs from all projects into one Pub/Sub topic to be later forwarded to Splunk.The output of this last command is similar to this:Take note of the service account [LOG_SINK_SERVICE_ACCOUNT] returned. It typically ends with @gcp-sa-logging.iam.gserviceaccount.com.Set IAM policy for Pub/Sub topicFor the sink export to work, you need to grant the returned sink service account a Cloud IAM role so it has permission to publish logs to the Pub/Sub topic:If you created the log sink using the Cloud Console, it will automatically grant the new service account permission to write to its export destinations, provided you own the destination. In this case, it’s Pub/Sub topic my-logs.Set up the Splunk HEC endpointIf you don’t already have an Splunk HEC endpoint, refer to the Splunk docs on how to configure Splunk HEC, whether it’s on your managed Splunk Cloud service or your own Splunk Enterprise instance. Take note of the newly created HEC token, which will be used below.Note: For high availability and to scale with high-volume traffic, refer to Splunk docs on how to scale by distributing load to multiple HEC nodes fronted by an HTTP(S) load balancer. Executing Pub/Sub to Splunk Dataflow templateThe Pub/Sub to Splunk pipeline can be executed from the UI, gcloud, or via a REST API call (more detail here). Below is an example form, populated in the Console after selecting “Cloud Pub/Sub to Splunk” template. Note the job name “pubsub2splunk” matches the name used in the log filter above, which excludes logs from this specific Dataflow job. Clicking on “Optional parameters” expands the form with more parameters to customize the pipeline, such as adding a user-defined function (UDF) to transform events (described in the next section), or configure the number of parallel requests or number of batched events per request. Refer to best practices below for more details on parameters related to scaling and sizing. Once parameters are set, click on “Run job” to deploy the continuous streaming pipeline.Add a UDF function to transform events (optional)As mentioned above, you can optionally specify a JavaScript UDF function to transform events before sending to Splunk. This is particularly helpful to enrich event data with additional fields, normalize or anonymize field values, or dynamically set event metadata like index, source, or sourcetype on an event basis.Here’s a JavaScript UDF function example that sets an additional new field inputSubscription to track the originating Pub/Sub subscription (in our case pubsub2splunk) and sets the event’s source to the value of logName from incoming log entry, and event sourcetype to payload or resource type programmatically, depending on incoming log entry:In order to use a UDF, you need to upload it to a Cloud Storage bucket and specify it in the template parameters before you click “Run job” in the previous step. Copy the above sample code into a new file called my-udf.js, then upload to a Cloud Storage bucket (replace [MY_BUCKET]) using this code:Go back to the template form in the Dataflow console, click and expand “Optional parameters,” and specify the two UDF parameters as follows:Once you click “Run job,” the pipeline starts streaming events to Splunk within minutes. You can visually check proper operation by clicking on the Dataflow job and selecting the “Job Graph” tab, which should look as below. In our test project, the Dataflow step WriteToSplunk is sending a little less than 1,000 elements/s to Splunk HEC, after applying the UDF function (via ApplyUDFTransformation step) and converting elements to Splunk HEC event format (via ConvertToSplunkEvent step). To make sure you are aware of any issues with the pipeline, we recommend setting up a Cloud Monitoring alert that will fire if the age of the oldest “unacknowledged”—or unprocessed—message in the input Pub/Sub subscription exceeds 10 minutes. An easy way to access graphs for this metric is in the Pub/Sub subscription details page in Pub/Sub’s Cloud Console UI.Click to enlargeView logs in SplunkYou can now search all Google Cloud logs and events from your Splunk Enterprise or Splunk Cloud search interface. Make sure to use the index you set when configuring your Splunk HEC token (we used index “test”). Here’s an example basic search to visualize the number of events per type of monitored resource:Tips and tricks for using the Splunk Dataflow templatePopulating Splunk event metadataSplunk HEC allows event data to be enhanced with a number of metadata fields that can be used for filtering and visualizing the data in Splunk. As mentioned above, the Pub/Sub to Splunk Dataflow pipeline allows you to set these metadata fields using an optional UDF function written in JavaScript. In order to enhance the event data with the additional metadata, the user-provided UDF can nest a JSON object tagged with the “_metadata” key in the event payload. This _metadata object can contain the supported fields (see table below) for Splunk metadata that will be automatically extracted and populated by the pipeline:The pipeline will also remove the “_metadata” field from the event data sent to Splunk. This is done to avoid duplication of data between the event payload and the event metadata.The following metadata fields are supported for extraction at this time:(see Splunk HEC metadata for more details)Note: For the “time” row, the pipeline will also attempt to extract time metadata from the event data in case there is a field named “timestamp” in the data payload. This is done to simplify extracting the time value from Cloud Logging’s LogEntry payload format. Note that any time value present in the “_metadata” object will always override the value extracted from the “timestamp” field.Batching writes to Splunk HECThe Pub/Sub to Splunk pipeline lets you combine multiple events into a single request. This allows for increased throughput and reduces the number of write requests made to the Splunk HEC endpoint. The default setting for batch is 1 (no batching). This can be changed by specifying a batchCount value greater than 1. Note about balancing throughput and latency: The cost of batching is a slight latency for individual messages, which are queued in memory before being forwarded to Splunk in batches. The pipeline attempts to enforce an upper limit (two seconds) to the amount of time an event remains in the pipeline before it gets pushed to Splunk. This is done to minimize that latency and avoid having events waiting in the pipeline for too long, in case the user provides a very high batchCount. For use cases that do not tolerate any added latency to individual events, batching should be turned off (default setting).Increasing write parallelismThe Pub/Sub to Splunk pipeline allows you to increase the number of parallel requests that are made to Splunk HEC endpoint. The default setting is 1 (no parallelism). This can be changed by specifying a parallelism value greater than 1. Note that increased parallelism will lead to an increase in the number of requests sent to the Splunk HEC endpoint and might require scaling HEC downstream.SSL certificate validationIf the Splunk HEC endpoint is SSL-enabled (recommended!) but is using self-signed certificates, you may want to disable the certificate validation. The default setting is to validate the SSL certificate. This can be changed by setting disableCertificateValidation to true.Autoscaling and parallelismIn addition to setting parallelism, the Pub/Sub to Splunk pipeline is autoscaling enabled with a maximum of 20 workers (default). The user can override this via the UI or via the –max-workers flag when executing the pipeline via gcloud CLI. It is recommended that the number of parallel requests (parallelism) should not exceed the number of max workers.What’s next?Refer to our user docs for the latest reference material, and to get started with the Pub/Sub to Splunk Dataflow template. We’d like to hear your feedback and feature requests. You can create an issue directly in the corresponding GitHub repo, or create a support case directly from your Cloud Console, or ask questions in our Stack Overflow forum.To get started with Splunk Enterprise on Google Cloud, check out the open-sourced Terraform scripts to deploy a cluster on Google Cloud within minutes. By default, the newly deployed Splunk Enterprise indexer cluster is distributed across multiple zones; it is pre-configured and ready to ingest data via both Splunk TCP and HEC inputs. The Terraform output returns an HEC token that you can readily use when creating your Dataflow job. Check out deploying Splunk Enterprise on GCP for general deployment guidelines.
Quelle: Google Cloud Platform

Das sind die Kosten, die ursprünglich für das gesamte Projekt angesetzt waren. (BMI, Security)
Quelle: Golem