Videostreaming: Disney+ hat 50 Millionen Abonnenten weltweit
Es ist ungewiss, wie viele der Abonnenten für Disney+ bereits etwas dafür bezahlen. (Disney+, Disney)
Quelle: Golem

Es ist ungewiss, wie viele der Abonnenten für Disney+ bereits etwas dafür bezahlen. (Disney+, Disney)
Quelle: Golem

Wer sich in schweren Zeiten von wirklich schlimmen Filmen und Serien trösten lassen will, findet bei Amazon Prime, was er braucht. Wir haben die grottigsten ausgegraben. Von Peter Osteried (Streaming, Amazon)
Quelle: Golem
The post Mirantis Partners with Kong for Destination: Decentralization Virtual Event appeared first on Mirantis | Pure Play Open Cloud.
Mirantis will discuss the road to cloud-native and ways to secure decentralized applications
April 8, 2020, Campbell, CA — Mirantis, the open cloud company, today announced that it is partnering with Kong for the company’s Destination: Decentralization virtual event. Other partners for the event include Cloud Native Computing Foundation (CNCF), AWS, and DataDog. Mirantis will give two talks at the event about the road to cloud-native applications and ways platforms can help secure decentralized applications.
Destination: Decentralization, to be held on April 16th, is a free digital event about decentralizing software architectures in light of the rapid adoption of containers and microservices. The event will host virtual lectures and hands-on labs where attendees will learn how to adapt to this new technological landscape. Mirantis is also geared up to give two presentations at the event:
Two ways platforms can help decentralize applications (and cloud) while still controlling what matters most
Bryan Langston, Director of Architecture, will talk about trusted container registry best practices and Docker Enterprise’s experimental implementation of the NIST OSCAL security standard.
The long road to cloud-native applications: Inter-service communications, application architectures, and platform deployment patterns
Bruce Mathews, Sr. Solutions Architect, will cover the fundamentals of microservices architecture, inter-service communications from the Ops and Developer perspectives, and key design patterns for making service-mesh coordinated apps more operations-friendly.
Register now for Destination: Decentralization: https://konghq.com/events/destination-decentralization/#register
The post Mirantis Partners with Kong for Destination: Decentralization Virtual Event appeared first on Mirantis | Pure Play Open Cloud.
Quelle: Mirantis
The global health pandemic has impacted every organization on the planet—no matter the size—their employees, and the customers they serve. The emphasis on social distancing and shelter in place orders have disrupted virtually every industry and form of business. The Media & Entertainment (M&E) industry is no exception. Most physical productions have been shut down for the foreseeable future. Remote access to post-production tools and content is theoretically possible, but in practice is fraught with numerous issues, given the historically evolved, fragmented nature of the available toolsets, vendor landscape, and the overall structure of the business
At the same time, more so today than ever before, people are turning to stories, content, and information to connect us with each other. If you need help or assistance with general remote work and collaboration, please visit this blog.
If you’d like to learn more about best practices and solutions for M&E workloads, such as VFX, editorial, and other post-production workflows—which are more sensitive to network latency, require specialized high-performance hardware and software in custom pipelines, and where assets are mostly stored on-premises (sometimes in air-gapped environments)—read on.
First, leveraging existing on-premises hardware can be a quick solution to get your creative teams up and running. This works when you have devices inside the perimeter firewall, tied to specific hardware and network configurations that can be hard to replicate in the cloud. It also enables cloud as a next step rather than a first step, helping you fully leverage existing assets and only pay for cloud as you need it. Solutions such as Teradici Cloud Access Software running on your artists’ machines enables full utilization of desktop computing power, while your networking teams provide a secure tunnel to that machine. No data movement is necessary, and latency impacts between storage and machine are minimized, making this a simple, fast solution to get your creatives working again. For more information, read Teradici’s Work-From-Home Rapid Response Guide and specific guidance for standalone computers with Consumer Grade NVIDIA GPUs.
Customers who need to enable remote artists with cloud workstations, while maintaining data on-premises, can also try out an experimental way to use Avere vFXT for Azure caching policies to further reduce latency. This new approach optimizes creation, deletion, and listing of files on remote NFS shares often impacted by increased latency.
Second, several Azure partners have accelerated work already in progress to provide customers with new remote options, starting with editorial.
Avid has made their new Avid Edit on Demand solution immediately available through their Early Access Program. This is a great solution for broadcasters and studios who want to spin up editorial workgroups of up to 30 users. While the solution will work for customers anywhere in the world, it is currently deployed in US West 2, East US 2, North Europe, and Japan East so customers closest to those regions will have the best user experience. You can apply to the Early Access Program here, and applications take about two days to process. Avid is also working to create a standardized Bring Your Own License (BYOL) and Software as a Service (SaaS) that addresses enterprise post-production requirements.
Adobe customers who purchase Creative Cloud for individuals or teams can use Adobe Premiere Pro for editing in a variety of remote work scenarios. Adobe has also extended existing subscriptions for an additional two months. For qualified Enterprise customers who would like to virtualize and deploy Creative Cloud applications in their environments, Adobe wanted us to let you know, “it is permitted as outlined in the Creative Cloud Enterprise Terms of Use.” Customers can contact their Adobe Enterprise representative for more details and guidance on best practices and eligibility.
BeBop, powered by Microsoft Azure, enables visual effects artists, editors, animators, and post-production professionals to create and collaborate from any corner of the globe, with high security, using just a modest internet connection. Customers can remotely access Adobe Creative Cloud applications, Foundry software, and Autodesk products and subscriptions including Over the Shoulder capabilities and BeBop Rocket File Transfer. You can sign up at Bebop’s website.
StratusCore provides a comprehensive platform for the remote content creation workforce including industry leading software tools through StratusCore’s marketplace; virtual workstation, render nodes and fast storage; project management, budget and analytics for a variety of scenarios. Individuals and small teams can sign up here and enterprises can email them here.
Third, while these solutions work well for small to medium projects, teams, and creative workflows, we know major studios, enterprise broadcasters, advertisers, and publishers have unique needs. If you are in this segment and need help enabling creative—or other Media and Entertainment specific workflows for remote work—please reach out to your Microsoft sales, support, or product group contacts so we can help
I know that we all want to get people in this industry back to work, while keeping everyone as healthy and safe as possible!
We’ll keep you updated as more guidance becomes available, but until then thank you for everything everyone is doing as we manage through an unprecedented time, together.
Quelle: Azure

Azure Monitor’s new source map support expands a growing list of tools that empower developers to observe, diagnose, and debug their JavaScript applications.
Difficult to debug
As organizations rapidly adopt modern JavaScript frontend frameworks such as React, Angular, and Vue, they are left with an observability challenge. Developers frequently minify/uglify/bundle their JavaScript application upon deployment to make their pages more performant and lightweight which obfuscates the telemetry collected from uncaught errors and makes those errors difficult to discern.
Source maps help solve this challenge. However, it’s difficult to associate the captured stack trace with the correct source map. Add in the need to support multiple versions of a page, A/B testing, and safe-deploy flighting, and it’s nearly impossible to quickly troubleshoot and fix production errors.
Unminify with one-click
Azure Monitor’s new source map integration enables users to link an Azure Monitor Application Insights Resource to an Azure Blob Services Container and unminify their call stacks from the Azure Portal with a single click. Configure continuous integration and continuous delivery (CI/CD) pipelines to automatically upload your source maps to Blob storage for a seamless end-to-end experience.
Microsoft Cloud App Security’s story
The Microsoft Cloud App Security (MCAS) Team at Microsoft manages a highly scalable service with a React JavaScript frontend and uses Azure Monitor Application Insights for clientside observability.
Over the last five years, they’ve grown in their agility to deploying multiple versions per day. Each deployment results in hundreds of source map files, which are automatically uploaded to Azure Blob container folders according to version and type and stored for 30 days.
Daniel Goltz, Senior Software Engineering Manager, on the MCAS Team explains, “The Source Map Integration is a game-changer for our team. Before it was very hard and sometimes impossible to debug and resolve JavaScript based on the unminified stack trace of exceptions. Now with the integration enabled, we are able to track errors to the exact line that faulted and fix the bug within minutes.”
Debugging JavaScript demo
Here’s an example scenario from a demo application:
Get started
Configure source map support once, and all users of the Application Insights Resource benefit. Here are three steps to get started:
Enable web monitoring using our JavaScript SDK.
Configure a Source Map storage account.
End-to-end transaction details blade.
Properties blade.
Configure CI/CD pipeline.
Note: Add an Azure File Copy task to your Azure DevOps Build pipeline to upload source map files to Blob each time a new version of your application deploys to ensure relevant source map files are available.
Manually drag source map
If source map storage is not yet configured or if your source map file is missing from the configured Azure Blob storage container, it’s still possible to manually drag and drop a source map file onto the call stack in the Azure Portal.
Submit your feedback
Finally, this feature is only possible because our Azure Monitor community spoke out on GitHub. Please keep talking, and we’ll keep listening. Join the conversation by entering an idea on UserVoice, creating a new issue on GitHub, asking a question on StackOverflow, or posting a comment below.
Quelle: Azure

Wegen des Coronavirus schickt Verizon offenbar kaum noch Techniker mehr zum Kunden nach Hause. (Verizon, Glasfaser)
Quelle: Golem

Nun können alle Spieler Stadia von Google ausprobieren – aber vorerst wegen der Coronakrise nur mit einer Auflösung von maximal 1080p. (Stadia, Google)
Quelle: Golem

Per Whitelist übertaktet Mediatek seine Chips für Smartphones – sportlich ist das nicht. (Mediatek, Benchmark)
Quelle: Golem
In the new “Building Secure and Reliable Systems: Best Practices for Designing, Implementing, and Maintaining Systems” book, engineers across Google’s security and SRE organizations share best practices to help you design scalable and reliable systems that are fundamentally secure. Reliability matters for businesses throughout all kinds of ups and downs. We’ve also heard that security is an essential tool for many of you building your own SRE practices, and we’re pleased to bring the followup “Building Secure and Reliable Systems” book to practitioners across industries. We think it will be an essential read for those of you tasked with ensuring the security and reliability of the systems you run. Just as the SRE Book quickly became foundational for practitioners across the industry, we think that the SRS Book will be an essential read for people responsible for the security and reliability of the systems they run. More than 150 contributors across dozens of offices and time zones present Google and industry stories, and share what we’ve learned over the years. We provide high-level principles and practical solutions that you can implement in a way that suits the unique environment specific to your product.What you’ll find in the SRS bookThis book was inspired by a couple of fundamental questions: Can a system be considered truly reliable if it isn’t fundamentally secure? Or can it be considered secure if it’s unreliable? At Google, we’ve spent a lot of time considering these concepts. When we published the SRE book (now inducted into a cybersecurity hall of fame!), security was one rather large topic that we didn’t have the bandwidth to delve into, given the already large scope of the book.Now, in the SRS book, we specifically explore how these concepts are intertwined. Because security and reliability are everyone’s responsibility, this book is relevant for anyone who designs, implements, or maintains systems. We’re challenging the dividing lines between the traditional professional roles of developers, SREs, and security engineers. We argue that everyone should be thinking about reliability and security from the very beginning of the development process, and should be integrating those principles as early as possible into the system life cycle. In the book, we examine security and reliability through multiple perspectives:Design strategies: For example, best practices to design for understandability, resilience, and recovery, as well as specific design principles such as least privilegeRecommendations for coding, testing, and debugging practicesStrategies to prepare for, respond to, and recover from incidentsCultural best practices to help teams across your organization collaborate effectively“Building Secure and Reliable Systems” is available now. You can find a freely downloadable copy on the Google SRE website. You can also purchase a physical copy from your preferred retailer.
Quelle: Google Cloud Platform
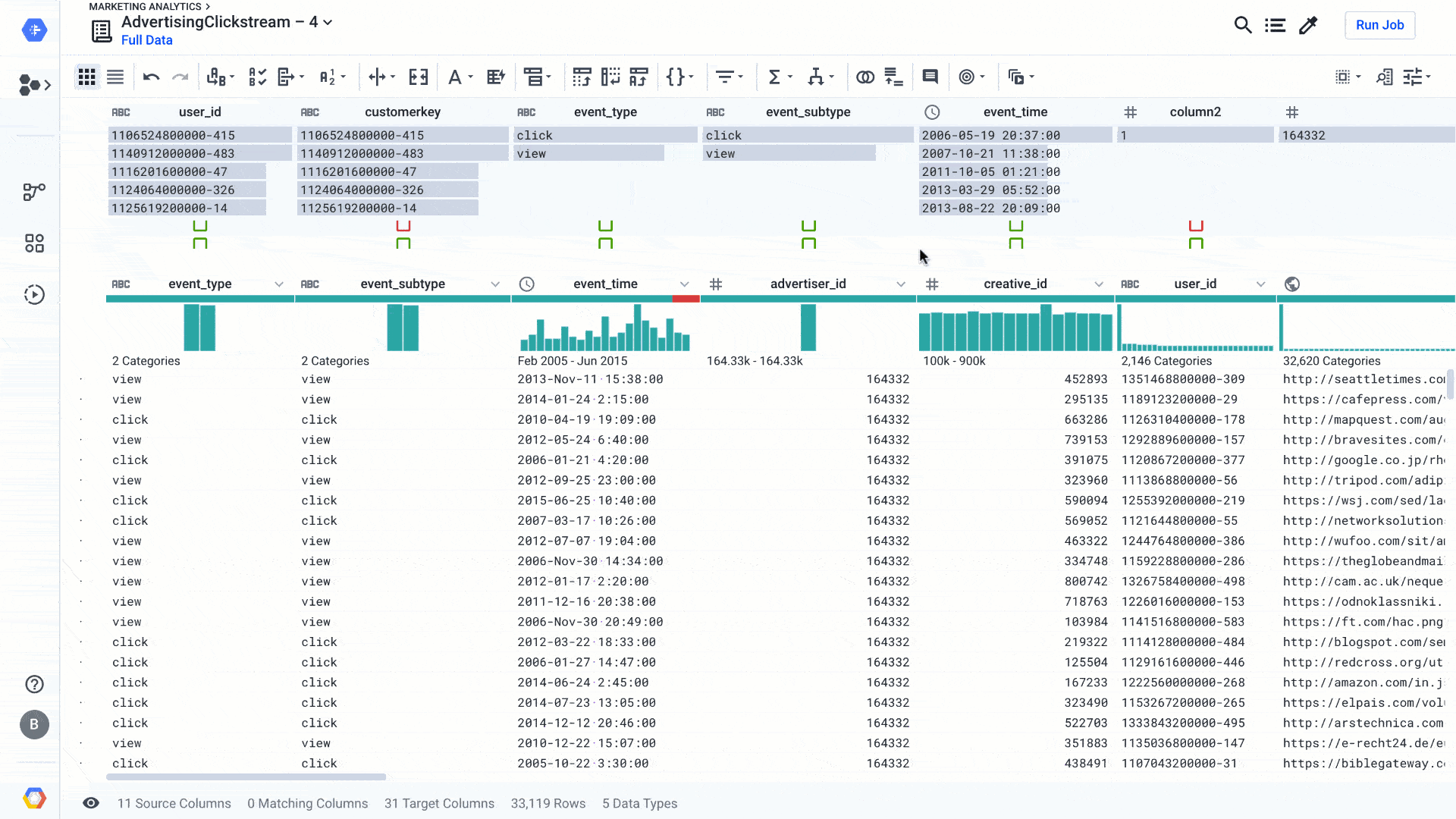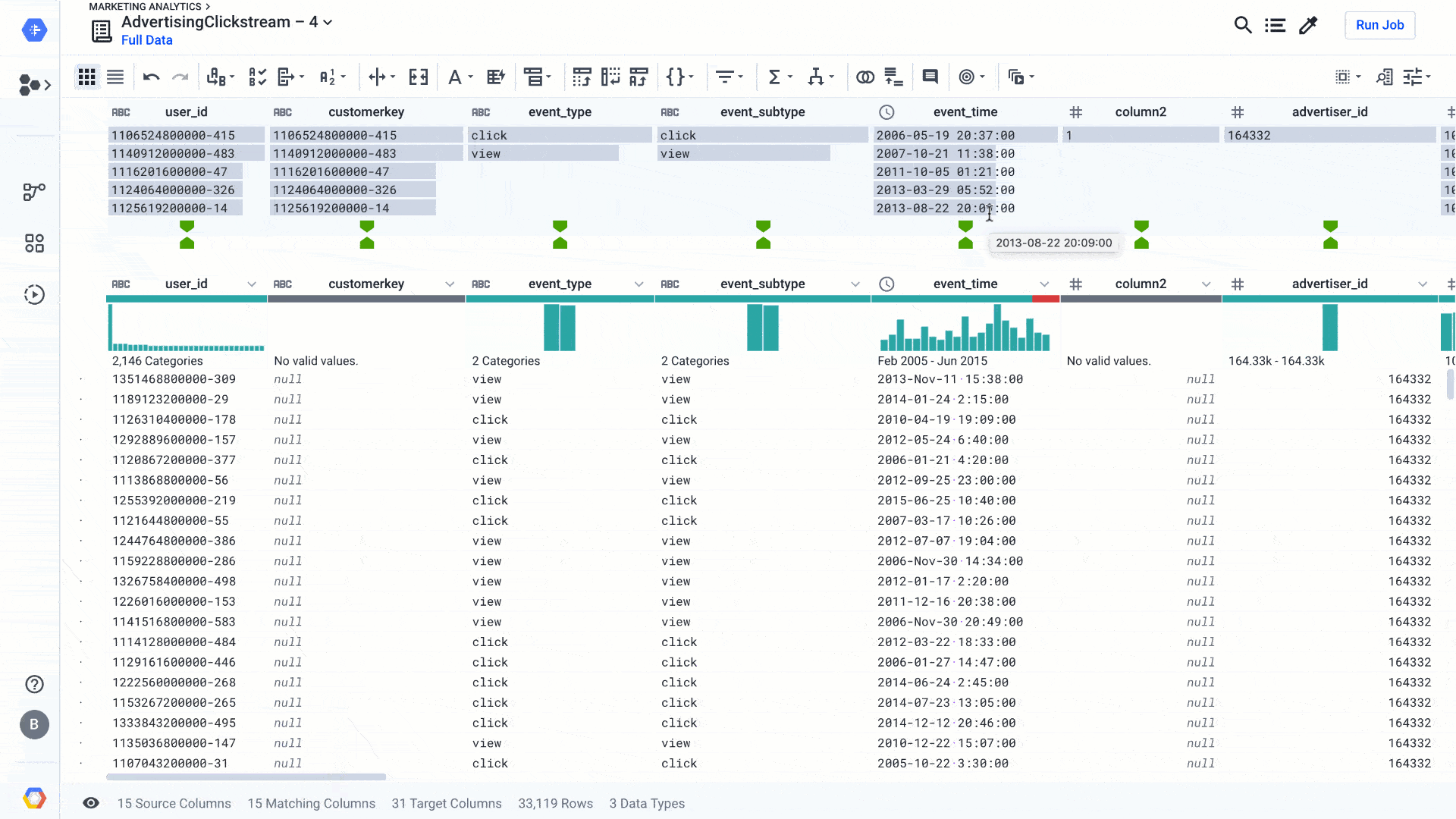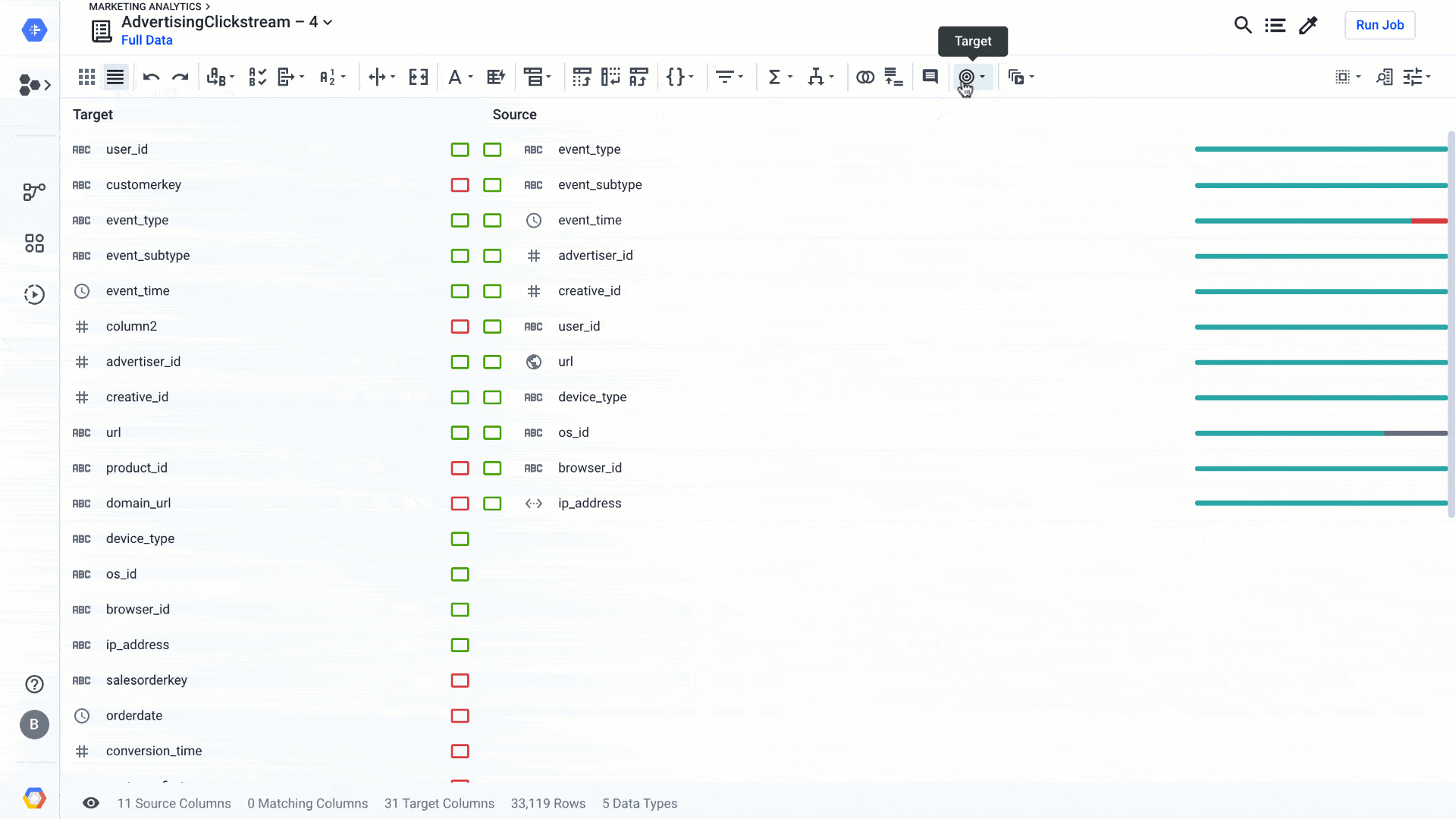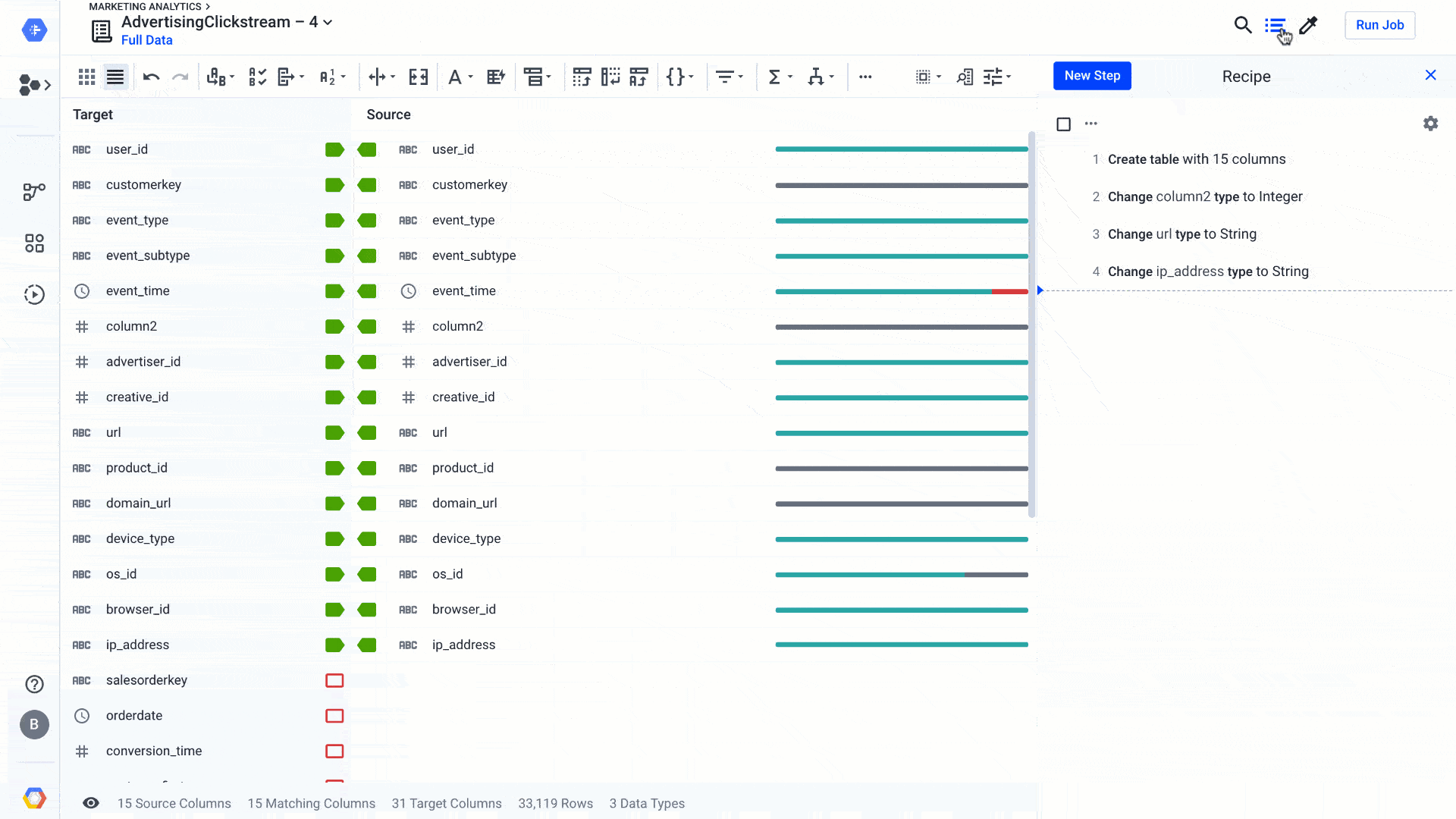
Since the inception of Cloud Dataprep by Trifacta, we’ve focused on making the data preparation work of data professionals more accessible and efficient, with a determined intention to make the work of preparing data more enjoyable (and even fun, in some cases!).The latest release of Dataprep brings new and enhanced AI-driven features to advance your wrangling experience a step further. We’ve improved the Dataprep core transformation experience, so it’s easier and faster to clean data and operationalize your wrangling recipes. We’ve been infusing AI-driven functions in many parts of Dataprep so it can suggest the best ways to transform data or figure out automatically how to clean the data, even for complex analytics cases. This effort has helped a broad set of business users access and leverage data in their transformational journey to become data-driven organizations. With data preparation fully integrated with our smart analytics portfolio, including ingestion, storage, processing, reporting, and machine learning, self-service analytics for everyone—not just data scientists and analysts—is becoming a reality.Let’s zoom in on a few new features and see how they can make data preparation easier.Improving fuzzy matching on rapid targetWhen you prepare your data using Dataprep, you can use the exploratory mode to figure out what the data is worth and how you might use it. You could also use exploratory mode to enhance an existing data warehouse or some production zones in a data lake. For the latter, you can use Rapid Target to quickly map your wrangling recipe to an existing data schema in BigQuery or a file in Cloud Storage. Using Rapid Target means you don’t have to bother matching your data transformation rules to an existing database schema; Dataprep will figure it out for you using AI. With the new release, in addition to matching schemas by strict column name equality, we have added fuzzy-matching algorithms to auto-align columns with the target schema by column name similarities or column content. Here’s what that looks like:Dataprep suggests best matches between the columns of your recipe and an existing data schema. You can accept it, change it, or go back to your recipe to modify it so the data can match. This is yet another feature that helps load the data warehouse faster, so you can focus on analyzing your data.Adding local settings and improved date/time interface When you work on a new data set, the first thing that Dataprep will figure out is the data structure and the data type of each column. Doing so, with the help of some AI algorithms, Dataprep can more easily identify data errors based on expected types and how to clean those types. However, some data types, such as dates or currencies, may be more complicated to infer based on the region you’re located in or the region the data is sourced from. For this particular reason, we’ve added a local setting option (at the project level and user level) so that Dataprep can infer data types—in particular, date and time when there is ambiguity in the data.For example, in the image below, changing the local setting to France will tell Dataprep to assume the dates should be in a French format, such as dd/mm/yyyy or 10-Mars-2020. The inference algorithms will determine the quality score of the data and the suggestions rules to clean that particular date column in a French format. This makes your job a whole lot easier.As a bonus to the date type management, we’ve streamlined the date/time data type menu. This new menu makes it far easier to find the exact date/time format you are looking for, letting you search instead of look at a list of 100 values, as shown here:Increasing cross-project data consistency with macro import/export As you’re going through your data preparation recipes, you will necessarily surface data pattern issues, such as similar data quality issues and similar ways to resolve them. Sometimes cleaning just one column requires a dozen steps, and you don’t want to rewrite all these steps every time this data issue occurs. That’s what macros are for.A macro is a sequence of steps that you can use as a single, customizable step in other data preparation recipes. So once you have defined one particular macro to apply data transformations, you can reuse it in other recipes so all your colleagues can benefit from it. This is particularly handy when you open a data lake sandbox and give access to business users to discover and transform data. By providing a set of macros to clean data, you will bring consistency across users, and if the data evolves you can also evolve the macros accordingly. With this new ability to import and export macros, you can maintain consistency across all of your Dataprep deployments across departments or stages of your projects (i.e., dev, test, production), create backups, and create an audit trail for your macros. You can also post or use existing macros from the Wrangler Exchange community, and build up a repository of commonly used macros, extending the flexibility of Dataprep’s Wrangle language.There are many more features that have been added to Dataprep, such as downloadable profile results, new trigonometry and statistical functions, shortcuts options, and many more. You can check them out in the release notes and learn more about Dataprep.Happy wrangling!
Quelle: Google Cloud Platform