NetzDG: Regierung stärkt Rechte von Nutzern
Auf soziale Netzwerke kommen mit der Änderung des NetzDG höhere Anforderungen zu. Sie müssen aber nicht bestimmte Nutzergruppen überwachen. (Netzwerkdurchsetzungsgesetz, Soziales Netz)
Quelle: Golem

Auf soziale Netzwerke kommen mit der Änderung des NetzDG höhere Anforderungen zu. Sie müssen aber nicht bestimmte Nutzergruppen überwachen. (Netzwerkdurchsetzungsgesetz, Soziales Netz)
Quelle: Golem

We’re announcing a key capability to help organizations govern their data in Google Cloud. Our new BigQuery column-level security controls are an important step toward placing policies on data that differentiate between classes. This allows for compliance with regulations that mandate such distinction, such as GDPR or CCPA. BigQuery already lets organizations provide controls to data containers, satisfying the principle of “least privilege.” But there is a growing need to separate access to certain classes of data—for example, PHI (patient health information) and PII (personally identifiable information)—so that even if you have access to a table, you are still barred from seeing any sensitive data in that table. This is where column-level security can help. With column-level security, you can define the data classes used by your organization. BigQuery column-level security is available as a new policy tag applied to columns in the BigQuery schema pane, and managed in a hierarchical taxonomy in Data Catalog. The taxonomy is usually composed of two levels: A root node, where a data class is defined, and Leaf nodes, where the policy tag is descriptive of the data type (for example, phone number or mailing address).The aforementioned abstraction layer lets you manage policies at the root nodes, where the recommended practice is to use those nodes as data classes; and manage/tag individual columns via leaf nodes, where the policy tag is actually the meaning of the content of the column. Organizations and teams working in highly regulated industries need to be especially diligent with sensitive data. “BigQuery’s column-level security allows us to simplify sharing data and queries while giving us comfort that highly secure data is only available to those who truly need it,” says Ben Campbell, data architect at Prosper Marketplace.Here’s how column-level security looks in BigQuery:In the above example, the organization has three broad categories of data sensitivity: restricted, sensitive, and unrestricted. For this specific organization, both PHI and PII are highly restricted, while financial data is sensitive. You will notice that individual info types, such as the ones detectable by Google Cloud Data Loss Prevention (DLP), are in the leaf nodes. This allows you to move a leaf node (or an intermediate node) from a restricted data class to a less sensitive one. If you manage policies on the root nodes, you will not need to re-tag columns to change the policy applied to them. This allows you to reflect changes in regulations or compliance requirements by moving leaf nodes. For example, you can take “Zipcode” from “Unrestricted Data,” move it to “PII,” and immediately restrict access to such data.Learn more about BigQuery column-level securityYou’ll be able to see the relevant policies that are applied to BigQuery’s columns within the BigQuery schema pane. If attempting to query a column you do not have access to (which is clearly indicated by the banner notice as well as the grayed-out nature of the field), the access will be securely denied. Access control applies to every method used to access BigQuery data (API, Views, etc.). Here’s what that looks like:Schema of BigQuery table. All but the first two columns have policy tags imposing column-level access restrictions. This user does not have access to them.We’re always working to enhance BigQuery’s (and Google Cloud’s) data governance capabilities to provide more controls around access, on-access data transformation, and data retention, and provide a holistic view of your data governance across Google Cloud’s various storage systems. You can try the capability out now.
Quelle: Google Cloud Platform
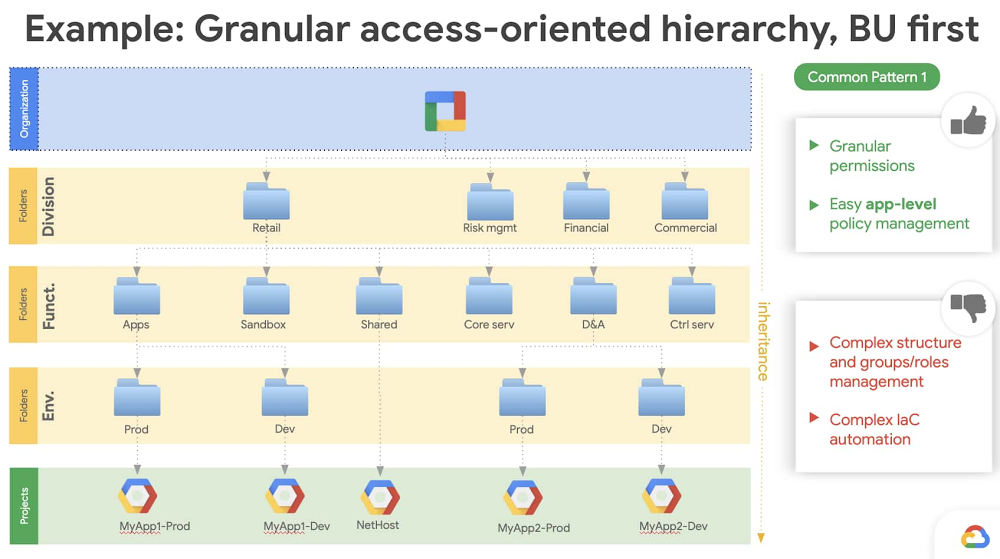
When businesses shift from solely on-premises deployments to using cloud-based services, identity management can become more complex. This is especially true when it comes to hybrid and multi-cloud identity management.Cloud Identity and Access Management (IAM) offers several ways to manage identities and roles in Google Cloud. One particularly important identity management task is identity and access governance (IAG): ensuring that your identity and access permissions are managed effectively, securely, and correctly. A major step in achieving IAG is designing an architecture that suits your business needs and also allows you to satisfy your compliance requirements. To manage the entire enterprise identity lifecycle you must consider the following core tasks: User provisioning and de-provisioningSingle sign-on (SSO)Access request and role-based access control (RBAC)Separation of duties (SoD)Reporting and access reviewsIn this post, we’ll discuss these tasks to show how you can achieve effective identity and access governance when using Google Cloud.User provisioning and deprovisioningLet’s start at the very beginning. Google Cloud offers several ways to onboard users. Cloud Identity is a centralized hub for Google Cloud and G Suite to define, setup, and manage users and groups—think of Cloud Identity as a provisioning and authentication solution, whereas Cloud IAM is principally an authorization solution. Once they’re onboarded, you’ll be able to assign permissions to these users and groups in Google Cloud IAM to allow them access to resources. Depending on your specific system of record, there are several scenarios to consider.If you’re using an on-premises Active Directory or LDAP directory as a centralized identity storeThis is the most common pattern for provisioning in enterprises. If your organization has a centralized directory server for provisioning all your users and groups, you can use that as a source of truth for Cloud Identity. Usually an enterprise provisioning solution connects the identities from the source of truth (HRMS or similar systems) to directories, so joiner, mover, and leaver workflows are already in place. To integrate an on-prem directory, Google offers a service called Google Cloud Directory Sync, which lets you synchronize users, groups, and other user data from your centralized directory service to Google Cloud domain directory (Cloud Identity uses Google Cloud domain directory). Cloud Directory Sync can synchronize user status, groups, and group memberships. If you do this, you can base your Google Cloud permissions on Active Directory (AD) groups.You can also run Active Directory in the cloud using a managed Active Directory service. You can use the managed AD service to deploy a standalone domain in multiple regions for your cloud-based workloads or connect your on-premises Active Directory domain to the cloud. This solution is recommended if: You have complex Windows workloads running in Google Cloud that need tight integration with Active Directory for user and access needs. You will eventually completely migrate to Google Cloud from your on-premises environment. In this case, this option will require minimal changes to how your existing AD dependencies are configured. If you primarily manage the user lifecycle with another identity management solutionIn this example, you don’t have a directory as a central hub. Instead you’re using a real-time provisioning solution like Okta, Ping, SailPoint, or others to manage the user lifecycle. These solutions provide a connector-based interface—usually referred to as an “application” or “app”—that uses Cloud Identity and User Management APIs to manage users and group memberships. Joiner, mover, and leaver workflows are managed directly from these solutions. The Cloud Identity account is disabled as soon as a termination event is processed by the leaver workflow, as is the user’s access to Google Cloud. In the case of a mover workflow, when users change job responsibility, the change is reflected in their Cloud Identity group membership which defines their new Google Cloud permissions.If you’re using a home-grown identity management systemCustom, home-grown identity systems are most commonly found when an organization’s complexity can’t be handled by an off-the-shelf product or when an organization wants greater flexibility than a commercial product can provide. In this case, the simplest option is to use a directory. You can interface with Cloud Identity using an LDAP compliant directory system. Users and groups provisioned via your custom identity management system can be synchronized to Cloud Identity using Cloud Directory Sync without having to write a custom provisioning solution for Cloud Identity.Single sign-onSingle sign-on (SSO) allows you to access applications without re-authenticating or maintaining separate passwords. Authorization usually comes in as a second layer to make sure authenticated users are permitted to access a given resource. As with user provisioning and de-provisioning, how you use SSO depends on your environment:SSO when using G Suite with Google Authentication. In this case, no special changes are required for Google Cloud sign-in. Google Cloud and G Suite both use the same sign-in, so as long as the right access is provisioned, users will be able to sign in to the Google Cloud console using their regular credentials.SSO when using G Suite with a third-party identity management solution. If G Suite sign-on has already been enabled, Google Cloud sign-on will also work. If a new G Suite and Google Cloud domain has been established, then you can create a new SAML 2.0-compliant integration using Cloud Identity with your identity management provider. For example, Okta and OneLogin provide a configurable SAML 2.0 integration using their out-of-the-box app. SSO when using an on-premises identity solution. Cloud Identity controls provisioning and authentication for Google Cloud, and provides a way to configure a SAML 2.0 compliant integration with your on-premises identity provider. SSO when using a multi-cloud model. When using multiple cloud service providers, you can use Cloud Identity or invest in a 3P identity provider to have a single source of truth for identities.Access request and role based access controlFor Google Cloud, “project” is the top level entity that hosts resources and workloads. Google Cloud relies on users/groups to define the role memberships that are used to provide access to projects. For easier organization and to maintain separation of control, projects can be grouped into folders and access can be granted at the folder level, but the principle remains the same. There are several roles within Google Cloud based on workloads. For example, if you’re using BigQuery, you’d assign predefined roles like BigQuery Admin, BigQuery Data Editor, or BigQuery User to users. The best practice is to always assign a role to Google Groups.Google Groups are synchronized from your directory environment or from your identity management solution into Cloud Identity. Again, think of Cloud Identity as your authentication system and Cloud IAM as your authorization system. These groups can be modeled based on project requirements and then be exposed in your identity management system. They can then be requested by the end user or assigned automatically based on their job requirements using enterprise roles. One way to structure your Google Cloud organization to separate workloads is to set up folders that mirror your organization’s business structure and match them to how you grant access to different teams within your organization:A top level of folders reflects your lines of business (LOB)Under a LOB folder you would have folders for departmentsUnder departments you would have folders for teams Under team folders you would have folders for product environments (e.g., DEV, TEST, STAGING, and PROD)With this structure in place, you would model Active Directory or identity management provider groups for access control based on this hierarchy, assign them based on roles, or expose them for access request/approval. You should also have “break glass” account request procedures and the pre-approved roles a user could be granted to manage potential emergency situations. Organizations that have frequent reorganizations might want to limit folder nesting. Ultimately, you can go as abstract or as deep as you’d like to balance flexibility and security. Let’s look at two examples of how this balance can be achieved.The figure below shows an example of structuring your Google Cloud organization with a business-unit-based hierarchies approach. The advantage of this structure is that it lets you go as granular as you’d like, however it is difficult to maintain since it doesn’t support organizational changes like reorganizations.Next we have an example of an environment-based hierarchies approach to your Google Cloud organization. This structure still lets you implement granular control over your workloads, and it’s also easier to implement using infrastructure-as-a-code (think Terraform).Separation of dutiesSeparation of duties (SoD) is a control that’s designed to prevent error or abuse by ensuring that at least two individuals are responsible for a task. Google Cloud provides several options to achieve SoD:As seen in the previous section, the Google Cloud resource hierarchy lets you create a structure that provides separation based on job responsibilities and organizational position. For example, an operational engineer working in one line of business usually wouldn’t have access to a project in another line of business, or a financial analyst wouldn’t have access to a project that deals with data analysis.Google Cloud lets you define IAM custom roles, which can simply be a collection of out-of-the-box roles. Google Cloud lets you bind roles to groups at various levels in your resource hierarchy. With this powerful feature, a group can be an organization level, a folder level, or a project level based on how the bindings are created.Here’s an example of how roles can be defined at an organizational level.In the next figure, we define a “Security admin group” and assign the appropriate IAM roles at the Org level.Then, along similar lines, you can think of groups that could be defined at a folder or project level.For example, below we define the “Site reliability engineers” group and assign the appropriate IAM roles at the folder or project level.Reporting and access reviewsUsers can gain access to a project either by having it directly granted to them or from organization- or folder-level inheritance. This can make it a bit unwieldy to meet compliance requirements that require you to have a report of “who has access to what” within Google Cloud. While you can get this “master” list using Cloud Asset Manager APIs or gcloud search-all-iam-policy commands, a better option is to export IAM policies to BigQuery using Asset Manager APIs’ export capabilities. Once this data is available in BigQuery, you can analyze it in Data Studio or import it into the tools of your choice.Putting it all togetherIdentity and access governance can be a challenging task. After reading this blog post, we hope that you have a clearer understanding of the options you have to address it on Google Cloud. To learn more about IAM, check out the technical documentation and our presentation at Cloud Next ‘19.
Quelle: Google Cloud Platform
Today marks the general availability of new Azure disk sizes, including 4, 8, and 16 GiB on both Premium and Standard SSDs, as well as bursting support on Azure Premium SSD Disks.
To provide the best performance and cost balance for your production workloads, we are making significant improvements to our portfolio of Azure Premium SSD disks. With bursting, even the smallest Premium SSD disks (4 GiB) can now achieve up to 3,500 input/output operations per second (IOPS) and 170 MiB/second. If you have experienced jitters in disk IOs due to unpredictable load and spiky traffic patterns, migrate to Azure and improve your overall performance by taking advantage of bursting support.
We offer disk bursting on a credit-based system. You accumulate credits when traffic is below the provisioned target and you consume credit when traffic exceeds it. It can be best leveraged for OS disks to accelerate virtual machine (VM) boot or data disks to accommodate spiky traffic. For example, if you conduct a SQL checkpoint or your application issues IO flushes to persist the data, there will be a sudden increase of writes against the attached disk. Disk bursting will give you the headroom to accommodate the expected and unexpected change in load.
Disk bursting will be enabled by default for all new deployments of burst eligible disks with no user action required. For any existing Premium SSD Managed Disks (less than or equal to 512GiB/P20), whenever your disk is reattached or VM is restarted, disk bursting will start to take effect and your workloads can then experience a boost on disk performance. To read more about how disk bursting works, refer to this Premium SSD bursting article.
Further, the new disk sizes introduced on Standard SSD disk provide you the most cost-efficient SSD offering in the cloud, providing consistent disk performance at the lowest cost per GiB. We've also increased the performance target for all Standard SSD disks less than 64GiB (E6) to 500 IOPS. It is an ideal replacement of HDD based disk storage from either on-premises or cloud. It is best suited for hosting web servers, business applications that are not IO intensive but require stable and predictable performance for your business operations.
In this post, we’ll be sharing how you can start leveraging these new disk capabilities to build your most high performance, robust, and cost-efficient solution on Azure today.
Getting started
You can create new managed disks using the Azure portal, Powershell, or command-line interface (CLI) now. You can find the specifications of burst eligible and new disk sizes in the table below. Both new disk sizes and bursting support on Premium SSD Disks are available in all regions in Azure Public Cloud, with support for sovereign clouds coming soon.
Azure Premium SSD Managed Disks
Here are the burst eligible disks including the newly introduced sizes. Disk bursting doesn’t apply to disk sizes greater than 512 GiB (above P20) as the provisioned target of these sizes are sufficient for most workloads. To learn more details on the disk sizes and performance targets, please refer to this "What disk types are available in Azure?" article.
30 mins
Burst capable disks
Disk size
Provisioned IOPS per disk
Provisioned bandwidth per disk
Max burst IOPS per disk
Max burst bandwidth per disk
Max burst duration at peak burst rate
P1—New
4 GiB
120
25 MiB/second
3,500
170 MiB/second
30 minutes
P2—New
8 GiB
120
25 MiB/second
3,500
170 MiB/second
30 minutes
P3—New
16 GiB
120
25 MiB/second
3,500
170 MiB/second
30 minutes
P4
32 GiB
120
25 MiB/second
3,500
170 MiB/second
30 minutes
P6
64 GiB
240
50 MiB/second
3,500
170 MiB/second
30 minutes
P10
128 GiB
500
100 MiB/second
3,500
170 MiB/second
30 minutes
P15
256 GiB
1,100
125 MiB/second
3,500
170/MiB/second
30 minutes
P20
512 GiB
2,300
150 MiB/second
3,500
170 MiB/second
30 minutes
Standard SSD Managed Disks
Here are the new disk sizes introduced on Standard SSD Disks. The performance targets define the max IOPS and bandwidth you can achieve on these sizes. Unlike Premium Disks, Standard SSD does not offer provisioned IOPS and bandwidth. For your performance-sensitive workloads or single instance deployment, we recommend leveraging Premium SSDs.
Disk size
Max IOPS per disk
Max bandwidth per disk
E1—New
4 GiB
500
25 MiB/second
E2—New
8 GiB
500
25 MiB/second
E3—New
16 GiB
500
25 MiB/second
Visit our service website to explore the Azure Disk Storage portfolio. To learn about pricing, you can visit the Azure Managed Disks pricing page.
Your feedback
We look forward to hearing your feedback; please reach out to us here with your comments.
Quelle: Azure

Vodafone bringt nun insgesamt fast 18 Millionen 1 GBit/s mit Docsis 3.1. (Vodafone, Kabelnetz)
Quelle: Golem

Die US-Datenfirma Palantir steht angeblich in Verhandlungen mit mehreren europäischen Ländern wegen der Corona-Krise. (Coronavirus, Telekom)
Quelle: Golem

Wer auf PS4 und Nintendo Switch im Multiplayer des Star-Wars-Actionspiels Jedi Academy ständig stirbt, könnte an PC-Gegner geraten sein. (Star Wars, Lucas Arts)
Quelle: Golem

Plötzlich soll der jahrelang schwebende Deal zwischen Telekom und Sprint durch sein. (Sprint, Telekom)
Quelle: Golem

Ein internationales Team hat in der Corona-Krise den Standard PEPP-PT für Infektionswarnungen getestet. Mit Hilfe der Bundeswehr. (Coronavirus, Google)
Quelle: Golem

Nur einer der vier Raumfahrer war noch nicht auf der ISS. (Raumfahrt, Nasa)
Quelle: Golem