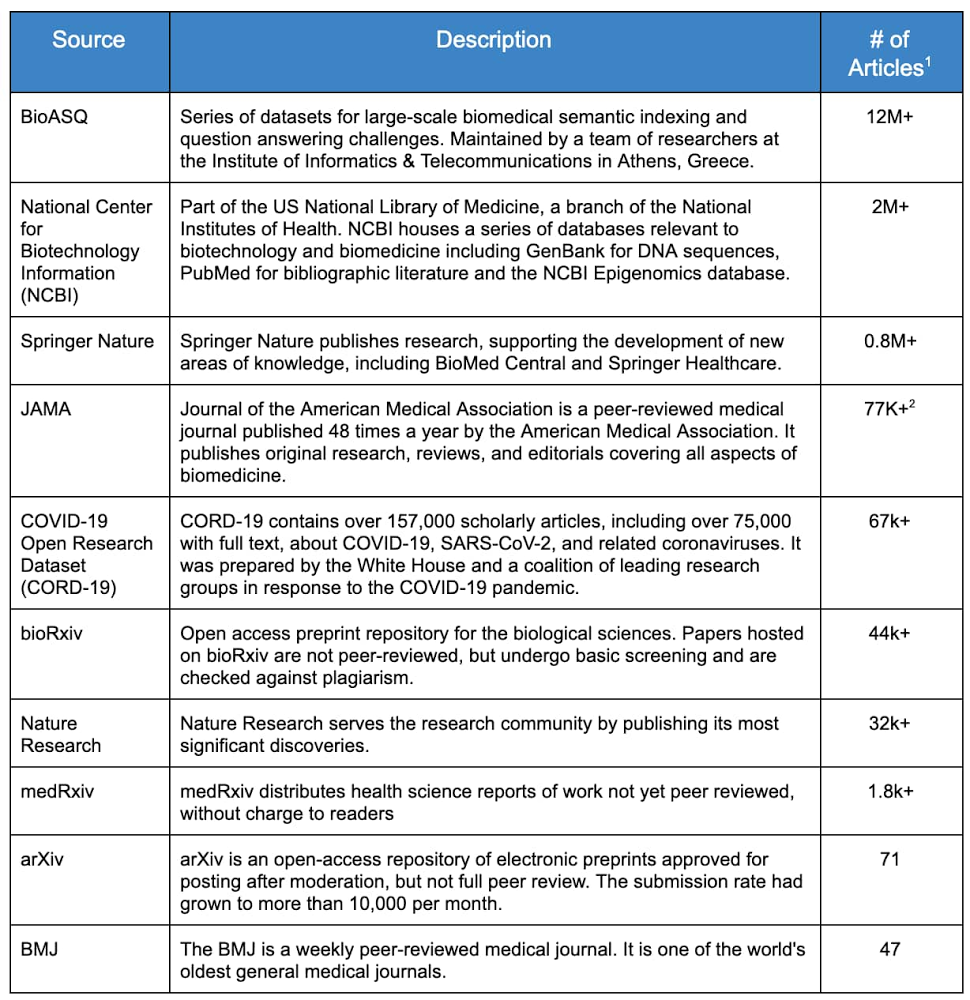
In response to the global pandemic, the White House and a coalition of research groups published the CORD19-dataset on Kaggle, the world’s largest online data science community. The goal—to further our understanding about coronaviruses and other diseases—caught the attention of many in the health policy, research and medical community. The Kaggle challenge has received almost 2 million page views since it launched in mid-March, according to this article in Nature. The dataset, freely available to researchers and the general public, contains over 150,000 scholarly articles, thousands just on COVID-19, making it almost impossible to stay up-to-date on the latest literature. Furthermore, there are millions of medical publications with information that could enhance our scientific understanding of COVID-19 and other diseases. However, much of this literature is not readily consumable by machines and is difficult to digest and analyze using modern natural language processing tools. Enter the Google artificial intelligence (AI) community. External to the company, this is a group of data scientists known as Machine Learning Google Developer Experts (ML GDEs). They are a highly skilled community of AI practitioners from all over the world. With the support of Google Cloud credits and credits from the TensorFlow Research Cloud (TFRC), the ML GDEs began to tackle the problem of understanding the research literature. While not healthcare experts, they quickly realized they could help with the current crisis by applying their knowledge of big data and AI to the biomedical domain.The team came together in April under the audacious name of ‘AI versus COVID-19’ (aiscovid19.org) and established the objective of using state of the art machine learning and cloud technologies to help biomedical researchers discover new insights, faster, from research literature. Designing the DatasetThe first step by the ML GDE team was to reach out to biomedical researchers to better understand their workflows, tools, challenges, and most importantly, the ‘relevance’ in medical literature. They found some common insights: overwhelming amount of existing and new informationambiguous and inconsistent sources of truthlimited information retrieval functionality in current toolssearch based only on simple keywords multiple scattered datasets inability to understand the meaning of words in context One of the pillars of the current AI revolution is the ability of these systems to become better as they analyze more data. Recent work (BERT, XLNEt, T5, GPT3) uses millions of documents to train state of the art neural networks for NLP tasks. Based on these insights, they determined the best way to help the research community was to create a single dataset containing a very large corpus of papers, and then to make that dataset available in machine usable formats. Inspired by the Open Accessmovement and initiatives such as the Chan Zuckerberg Institute’s Meta, they sought to find as many relevant and unique, freely available publications and collect them into one easily accessible dataset designed specifically to train AI systems.Introducing BREATHEThe Biomedical Research Extensive Archive To Help Everyone (BREATHE), is a large-scale biomedical database containing entries from top biomedical research repositories. The dataset contains titles, abstracts, and full body texts (when licensing permitted) for over 16 million biomedical articles published in English. They released the first version in June 2020, and expect to release new versions as the corpus of articles is constantly updated by their search crawlers. Collecting articles originally written in different languages (other than English) is among the ideas on how to further improve the dataset and the domain specific knowledge that it tries to capture. While there are several COVID-19 specific datasets, BREATHE differs in that it is: broad – contains many different sources machine readablepublicly accessible and free-to-usehosted on a scalable, easy to analyze, cost-effective data-warehouse – Google BigQueryBREATHE Development ApproachThe ML GDE team identified the top ten web archives, or `sources’, with potential material based on three main factors: amount of data, quality of data, and availability. These sources are listed in Table 1.Table 1: Medical ArchivesData Mining Approach & ToolsThe development and automation of the article download workflow was significantly accelerated by using Google Cloud infrastructure. This system, internally called the “ingestion pipeline”, has the classical three stages: Extract, Transform and Load (ETL). Google Cloud Platform BREATHE Dataset CreationExtract For all the resources, the ML GDE team first verified the content licensing, making sure they were abiding to the source’s terms of use, and then employed APIs and FTP servers when available. For the remaining resources, they adopted the ‘ethical scraping’ philosophy to ingest the public data.To easily prototype the main logic of the scrapers, their interns used a Google Colaboratory Notebook (or ‘Colab’). Colab is a hosted Python Jupyter notebook that enables users to write and execute Python in the browser, with no additional setup or configuration and provides free, limited access to GPUs, making it an attractive tool of choice for many machine learning practitioners. Google Colab provided us the ability to easily share code amongst our interns and collaborators. The scrapers are written using Selenium, a suite of tools for automating web browsers, among which they chose Chromium in headless mode (Chromium is the open source project on which the Google Chrome browser is based). All the raw data from the different sources is downloaded directly to their Google Cloud Storage bucket. TransformThe ML GDE team ingested over 16 million articles from ten different sources, each one with raw data formatted in CSV, JSON or XML and its own unique schema. Their tool of choice to efficiently process this amount of data was Google Dataflow. Google Dataflow is a fully managed service for executing Apache Beam pipelines on Google Cloud. In the transform stage the pipeline processes every single raw document, applying cleaning, normalization and multiple heuristic rules to extract a final general schema, formatted in JSONL. Some of the heuristic applied includes checks for null values, invalid strings, and duplicate entries. They also verified the consistency between fields with different names, in different tables, which represented the same entity. Documents going through these stages end up in three different sink buckets, based on the status of the operation: Success: for documents correctly processedRejected: for documents that did not match one or more of their rulesError: for documents that the pipeline failed to processApache Beam allows us to design logic that is not straightforward with an easy-to-read syntax (such as Snippet 1). Google Dataflow makes it easy to scale this process across many Google Cloud compute instances, without having to change any code. The pipeline was applied to the full raw data distilling it to 16.7 million records for a total of 100GB of JSONL text data.Snippet 1: Google Dataflow Processing ExampleLoadFinally the data was loaded into Google Cloud Storage buckets and Google BigQuery tables.BigQuery didn’t require us to manage any infrastructure nor does it need a database administrator – making it ideal for their project, which is composed mainly of data science experts. They iterated several times on the ingestion process, as they scaled the number of total documents processed. In the initial stages of data exploration, data scientists were able to explore the contents of the data loaded into BigQuery by simply using the standard Structured Query Language (SQL). One useful technique in this phase is to “sample” the dataset to discover non-conforming documents, for example to extract 5% of the whole dataset you can use this simple code:For more advanced queries, they used Google Colab and BigQuery Python API. For example, here’s how you can count the number of lines in each table:Using this approach, it was easy to calculate aggregate statistics about their dataset. If one considers all the abstracts in the BREATHE, there are 3.3 billion total words and 2.8 million unique words. Using Python and Colab, it was also easy to do some exploratory data analysis. For example, here’s a plot of the word frequencies:Google Public Dataset ProgramThe ML GDE team believes other data scientists may find value in the dataset, so they chose to make it available via the Google Public Dataset Program. This public dataset is hosted in Google BigQuery and is included in BigQuery’s free tier. Each user can process up to 1TB for free every month. This quota can be used by anyone to explore the BREATHE dataset using simple SQL commands. Watch this short video to learn about BigQuery and start querying BREATHE using the BigQuery public access program, today. What can YOU do with this dataset?The BREATHE dataset can be used in many ways to better understand and synthesize voluminous biomedical research and uncover new insights into biomedical challenges – such as the COVID-19 pandemic. The ML GDE team thinks there are many other interesting things that data scientists can build using BREATHE, such as training biomedical-specific language models, building biomedical information retrieval systems, or deriving new forms of unsupervised classification for niches of research in the vast biomedical domain. Some ideas may even address the challenging task of accurately translating articles to many different languages where non-native-english-speaking researchers and clinicians are often forced to understand and comprehend material in the original author’s language. The team is looking forward to seeing what the AI community can create with the BREATHE dataset.Cloud collaboration: it takes a villageOne of the distinct advantages of working in the cloud is that many geographically separated developers can work together on a single project. In this case, generating the dataset involved no less than 20 people on three continents and five time zones. Dan Goncharov, head of the 42 Silicon Valley AI and Robotics Lab led the team that drove the BREATHE dataset creation. 42 is a private, nonprofit and tuition-free computer programming school with 16 locations worldwide. The ML GDE team would like to acknowledge the work of Blaire Hunter, Simon Ewing, Khloe Hou, Gulnozai Khodizoda, Antoine Delorme, Ishmeet Kaur, Suzanne Repellin, Igor Popov, Uliana Popova, and especially the work of Ivan Kozlov, Francesco Mosconi (Zero to Deep Learning) and Fabricio Milo (Entropy Source).Next time: building a search tool using TensorFlow and state-of-the-art natural language architecturesIn this post, we went through the project background, the design principles, and the development process for creating BREATHE, a publicly available, machine readable dataset for biomedical researchers. In the next post, the ML GDE team will walk through how they built a simple search tool on top of this dataset using open source and state-of-the-art natural language understanding tools. Tools Used Creating BREATHEGoogle Networking & ComputeGoogle DataflowGoogle BigQuery (BQ)Google Cloud Storage (GCS)Google Cloud Public Dataset ProgramSelenium Google ColabPython 31. “Unique” articles as determined by DOI, however many that are listed with the same DOI contain valuable additional information.2. JAMA contained 70k+ articles with full body text that technically were duplicated in abstract form from other sources.
Quelle: Google Cloud Platform