Spielekonsole: Playstation 5 ist nicht zu älteren Spielen kompatibel
Das bestätigt Sony. Fans der PS 1, 2 und 3 könnte das abschrecken. Auch ist die Spielkonsole bei vielen Versandhändlern bereits vergriffen. (Playstation 5, Sony)
Quelle: Golem

Das bestätigt Sony. Fans der PS 1, 2 und 3 könnte das abschrecken. Auch ist die Spielkonsole bei vielen Versandhändlern bereits vergriffen. (Playstation 5, Sony)
Quelle: Golem

Der Dienst zum verschlüsselteN Dateiaustausch von Mozilla geht nicht wieder online. Auch Firefox Notes wird eingestellt. (Mozilla, Firefox)
Quelle: Golem

Monatliche Updates und ein besseres SDK für Mods: Microsoft zeigt, was die Flight-Simulator-Community in den kommenden Monaten erwartet. (Flugsimulator, Microsoft)
Quelle: Golem

Die “Shitrix” genannte Lücke in Citrix war wohl für einen Todesfall in der Düsseldorfer Uniklinik verantwortlich. (Citrix, Netzwerk)
Quelle: Golem
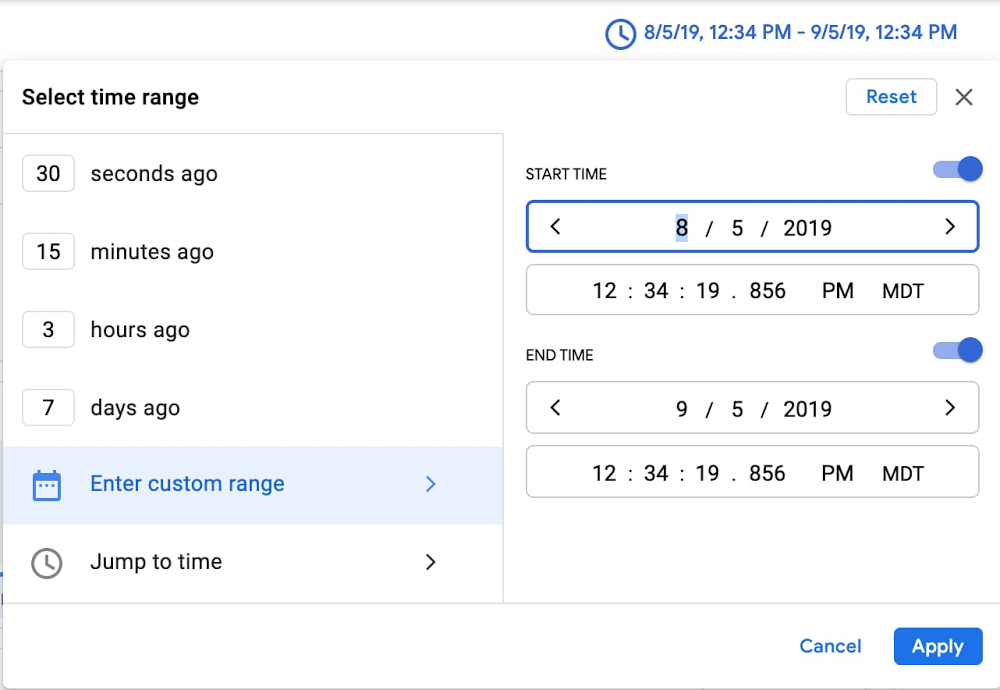
One of the most frequent questions customers ask is “how do I find this in my logs?”—often followed by a request to use regular expressions in addition to our logging query language. We’re delighted to announce that we recently added support for regular expressions to our query language — now you can search through your logs using the same powerful language selectors as you use in your tooling and software! Even with regex support, common queries and helpful examples in our docs, searching petabytes of structured or unstructured log data efficiently is an art, and sometimes there’s no substitute for talking to an expert. We asked Dan Jacques, a software engineering lead on logging who led the effort to add regular expressions to the logging query language, to share some background on how logging works and tips and tricks for exploring your logs.Can you tell me a little bit about Cloud Logging’s storage and query backend?Cloud Logging stores log data in a massive internal time-series database. It’s optimized for handling time-stamped data like logs, which is one of the reasons you don’t need to swap out old logs data to cold storage like some other logging tools. This is the same database software that powers internal Google service logs and monitoring. The database is designed with scalability in mind and processes over 2.5 EB (exabytes!) of logs per month, which thousands of Googlers and Google Cloud customers query to do their jobs every day…Can you tell me about your experience adding support for regular expressions into the logging query language?I used Google Cloud Platform and Cloud Logging as a Googler quite a bit prior to joining the team, and had experienced a lack of regular expression support as a feature gap. Championing regular expression support was high on my list of things to do. Early this year I got a chance to scope out what it would require. Shortly after, my team and I got to work implementing regular expression support.As someone who has to troubleshoot issues for customers, can you share some tips and best practices for making logging queries perform as well as possible?Cloud Logging provides a very flexible, largely free-form logging structure, and a very powerful and forgiving query language. There are clear benefits to this approach: log data from a large variety of services and sources fit into our schema, and you can issue queries using a simple and readable query notation. However, the downside of being general purpose is that it’s challenging to optimize for every data and query pattern. As a general guide, you can improve performance by narrowing the scope of your queries as much as possible, which in turn narrows the amount of data we have to search. Here are some specific ideas for narrowing scope and improving performance:Add “resource type” and “log name” fields to your query whenever you can. These fields are indexed in such a way that make them particularly effective at improving performance. Even if the rest of your query already only selects records from a certain log/resource, adding these constraints informs our system not to spend time looking elsewhere. The new Field Explorer feature can help drill down into specific resources.Original search: “CONNECTING”Specific search:LOG_ID(stdout) resource.type=”k8s_container”resource.labels.location=”us-central1-a”resource.labels.cluster_name=”test”resource.labels.namespace_name=”istio-system””CONNECTING”Choose as narrow a time range as possible. Let’s suppose you’re looking for a VM that was deleted about a year ago. Since our storage system is optimized for time, limiting your time range to a month will really help with performance. You can select the timestamp through the UI or by adding it to the search explicitly.Pro tip: you can paste a timestamp like the one below directly into the field for custom time. Original search: “CONNECTING”Specific search:timestamp>=”2019-08-05T18:34:19.856588299Z”timestamp<=”2019-09-05T18:34:19.856588299Z””CONNECTING”Put highly-queried data into indexed fields. You can use the Cloud Logging agent to route log data to indexed fields for improved performance, for example. Placing indexed data in the “labels” LogEntry field will generally yield faster look-ups.Restrict your queries to a specific field. If you know that the data you’re looking for is in a specific field, restrict the query to that field rather than using the less efficient global restriction.Original search: “CONNECTING”Specific search: textPayload =~ “CONNECTING”Can you tell us more about using regular expressions in Cloud Logging?Our filter language is very good at finding text, or values expressed as text, in some cases to the point of oversimplification at the expense of specificity. Prior to regular expressions, if you wanted to search for any sort of pattern complexity, you had to build a similitude of that complexity out of conjunctive and disjunctive terms, often leading to over-querying log entries and underperforming queries. Now, with support for regular expressions, you can perform a case-sensitive search, match complex patterns, or even substring search for a single “*” character.The RE2 syntax we use for regular expressions is a familiar, well-documented, and performant regular expression language. Offering it to users as a query option allows users to naturally and performantly express exactly the log data that they are searching for.For example, previously if you wanted to search for a text payload beginning with “User” and ending with either “Logged In” or “Logged Out”, you would have to use a substring expression like: (textPayload:User AND (textPayload:”Logged In” OR textPayload:”Logged Out”))Something like this deviates significantly from the actual intended query:There is no ordering in substring matching, so “I have Logged In a User” would match the filter’s constraints.Each term executes independently, so this executes up to three matches per candidate log entry internally, costing additional matching time.Substring matches are case-insensitive. There is no way to exclude e.g., “logged in”.But with a regular expression, you can execute:textPayload =~ “^User.*Logged (In|Out)$”This is simpler and selects exactly what you’re looking for.Since we dogfood our own tools and the Cloud Logging team uses Cloud Logging for troubleshooting, our team has found it really useful and I hope it’s as useful to our customers!Ready to get started with Cloud Logging? Keep in mind these tips from Dan that will speed up your searches:Add a resource type and log name to your query whenever possible, Keep your selected time range as narrow as possible.If you know that what you’re looking for is part of a specific field, search on that field rather than using a global search.Use regex to perform case sensitive searches or advanced pattern matching against string fields. Substring and global search are always case insensitive.Add highly-queried data fields into the indexed “labels” field.Head over to the Logs Viewer to try out these tips as well as the new regex support.
Quelle: Google Cloud Platform

Deploying code to production directly from your dev machine can lead to unforeseen issues: the code might have local changes, the process is manual and error prone, and tests can be bypassed. And later on, it makes it impossible to understand what actual code is running in production. A best practice for avoiding these hardships is to continuously deploy your code when changes are pushed to a branch of your source repository.As we announced at Google Cloud Next ‘20: OnAir, Cloud Run now allows you to set up continuous deployment in just a few clicks: From the Cloud Run user interface, you can now easily connect to your Git repository and set up continuous deployment to automatically build and deploy your code to your Cloud Run and Cloud Run or Anthos services. This feature is available for both new and existing services.You can select any repository that includes a Dockerfile or code written in Go, Node.js, Java, Python and .NET. Under the hood, the continuous deployment setup process configures a Cloud Build trigger that builds the code into a container using Docker or Google Cloud Buildpacks, pushes it to Google Container Registry and deploys it to your Cloud Run service. You can later customize this by adding steps to the Cloud Build trigger configuration, for example adding unit or integration tests before deploying.By default, your code is automatically built and deployed to a new Cloud Run revision, but you can decide if it should receive 100% of the incoming traffic immediately or not, and later gradually migrate traffic using the newly added traffic controls.With Continuous Deployment set up, the Cloud Run service detail page shows relevant in-context information:A link to the exact commit in the Git repository that was used for this deploymentA link to the build logs and the build trigger that created this revision / container.A quick preview of the health of the latest builds.Pushing your code directly to production was never a good idea. Now, Cloud Run makes it easy for you to embrace best practices like continuous deployment. Give it a try at http://cloud.run/.Related ArticleAccelerate your application development and deliveryAt Google Cloud Next ‘20: OnAir, we released a wealth of tools and capabiltiies to enhance developer productivity.Read Article
Quelle: Google Cloud Platform
Data warehouses are at the heart of an organization’s decision making process, which is why many businesses are moving away from the siloed approach of traditional data warehouses to a modern data warehouse that provides advanced capabilities to meet changing requirements. At Google Cloud, we often work with customers on data warehouse migration projects, including helping HSBC migrate to BigQuery, reducing more than 600 reports and several related applications and data pipelines. We’ve even assembled a migration framework that highlights how to prepare for each phase of migration to reduce risk and define a clear business case up front to get support from internal stakeholders. While we offer a data management maturity model, we still receive questions, specifically around how to prepare for migration. In this post, we’ll explore a few important questions that come up during the initial preparation and discovery phases, including the impact of modernizing a data warehouse in real life and how you can better prepare for and plan your migration to a modern data warehouse.Tackling the preparation phaseAn enterprise data warehouse has many stakeholders with a wide range of use cases, so it’s important to identify and involve the key stakeholders early in the process to make sure they’re aligned with the strategic goals. They can also help identify gaps and provide insight on potential use cases and requirements, which can help prioritize the highest impact use cases and identify associated risks. These decisions can then be approved and aligned with business metrics, which usually revolve around three main components:People. To make sure you’re getting input and buy-in for your migration, start with aligning leadership and business owners. Then, explore the skills of the project team and end users. You might identify and interview each functional group within the team by conducting workshops, hackathons, and brainstorming sessions. Remember while discussing issues to consider how to secure owner sign-off by setting success criteria and KPIs, such as: Time savedTime to create new reportsReporting usage increaseTalent acquired through innovationTechnology. By understanding the current technical landscape and classifying existing solutions to identify independent workloads, you can more easily separate upstream and downstream applications to further drill down into their dependency on specific use cases. For example, you can cluster and isolate different ETL applications/pipelines based on different use cases or source-systems being migrated to reduce the scope as well as underlying risks. Similarly, you can couple them with upstream applications and make a migration plan which moves dependent applications and related data pipelines together.In addition to understanding current migration technologies, it’s key that you are clear on what you are migrating. This includes identifying appropriate data sources with an understanding of your data velocity, data regionality, and licensing, as well as identifying business intelligence (BI) systems with current reporting requirements and desired modernizations during the migration. For example, you might want to move that daily report about sales to a real-time dashboard. You might also want to decide if any upstream or downstream applications should be replaced by a cloud-native application and could be driven by KPIs below:TCO of new solution vs. functionality gainsPerformance improvements and scalabilityLower manageabilityRisk of lock-in vs. using open sourceProcess. By discussing your process options, you can uncover dependencies between existing components and data access and governance requirements, as well as the ability to split migration components. For example, you should evaluate license expiration dependencies before defining any migration deadlines. Processes should be established to make effective decisions during migration and ensure optimal progress inline, using KPIs such as:Risk of data leakage and misuseRevenue growth per channelNew services launched vs. cost of launching themAdoption of ML-driven analyticsA strong understanding of the processes you intend to put in place can open up new opportunities for growth. For example, a well-known ecommerce retailer wanted to drive product and services personalization. Their existing data warehouse environment did not provide predictive analytics capabilities and required investments in new technology. BigQuery ML allowed them to be agile and apply predictive analytics, unlocking increased lifetime value, optimized marketing investment, improved customer satisfaction, and increased market share.Entering the discovery phaseThe discovery process is mainly concerned with two areas: business requirements and technical information.1. Understanding business requirementsThe discovery process of a data warehouse migration starts with understanding business requirements and usually has a number of business drivers. Replacing legacy systems has implications in many fronts, ranging from new team skill set requirements to managing ongoing license and operational costs. For example, upgrading your current system might require all of your company’s data analysts to be re-trained, as well as new additional licenses to be purchased. Quantifying these requirements, and associating them with costs, will allow you to make a pragmatic, fair assessment of the migration process. On the other hand, proposing and validating potential improvement gains by identifying gaps in the current solution will add value. This can be done by defining an approach to enhance and augment the existing tools with new solutions. For example, for a retailer, the ability to deliver new real-time reporting will increase revenue, since it provides significant improvements in forecasting and reduced shelf-outs.This retailer realized that shelf-outs were costing them millions in lost sales. They wanted to find an effective solution to predict inventory needs accurately. Their legacy data warehouse environment had reached its performance peak, so they wanted a cloud offering like BigQuery to help them analyze massive data workloads quickly. As a result of migrating, they were able tostream terabytes of data in real time and quickly optimize shelf availability to save on costs and get other benefits like:Incremental revenue increase with reduced shelf-outs2x accuracy vs. previous predictive modelBusiness challenges that were previously perceived as too difficult to solve can be identified as new opportunities by re-examining them using new technologies. For example, the ability to store and process more granular data can aid organizations in creating more targeted solutions. A retailer may look into seasonality and gauge customer behavior if Christmas Day falls on a Monday versus another day of the week. This can only be achieved with the ability to store and analyze increased amounts of data spanning across many years.Last but not least: Educating your users is key to any technology modernization project. In addition to learning paths defined above this can be done by defining eLearning plans for self study. In addition, staff should have time to be hands-on and start using the new system to learn by doing. You can also identify external specialized partners and internal champions early on to help bridge that gap.2. Technical information gatheringIn order to identify the execution strategy, you’ll want to answer the following question: Will your migration process focus on a solution layer or an end-to-end lift-and-shift approach? Going through some of the points below can make this decision simpler:Identify data sources for up and downstream applicationsIdentify datasets, tables and schemas relevant for use casesOutline ETL/ELT tools and frameworksDefine data quality and data governance solutionsIdentify Identity and Access Management (IAM) solutionsOutline BI and reporting toolsFurther, it is important to identify some of the functional requirements before making a decision around buy or build. Are there any out-of-the-box solutions available in the market that meet the requirements, or will you need a custom-built solution to meet the challenges you’ve identified? Make sure you know whether this project is core to your business, and would add value, before deciding on the approach.Once you’ve concluded the preparation and discovery phase, you’ll have some solid guidance on which components you’ll be replacing or refactoring with a move to a cloud data warehouse. Visit our website to learn more about BigQuery.Thanks to Ksenia Nekrasova for contributions to this post.
Quelle: Google Cloud Platform

Jenae Butler has been a Googler for just under a year, but she became well-known both inside and outside of the company in June during a national spotlight on racial injustices here in the U.S. She created a presentation to help her colleagues understand what was going on; people found it so helpful that her “Standing United” resource spread quickly within Google as well as on social media. It starts with the context of George Floyd’s death and the impact police brutality has on the Black community while offering actionable tips and advice for anyone looking to learn how to be a better ally to marginalized communities of color.We sat down with Jenae to hear about how she navigated her own path as a Black woman in tech, and how she advises her peers to practice allyship successfully.Tell us about your path to Google.When I was in college, internships in the technical field felt hard to obtain. It seemed like businesses were looking for a student who already had experience or other qualifications—which I found to be odd. I was a computer info systems major at Georgia State University and was looking to get into project management. I wasn’t lucky enough to get an internship at the time but I found a back door into technology by working at Microsoft’s retail stores. That was my first time getting real exposure to the tech field and ended up being the reason I got into my career field.I transitioned from the retail side of Microsoft through a college hire program offered by the company. I worked as a consultant focused on SQL-themed projects and eventually made my way into program management for Microsoft’s retail store support team. In that time I was heavily involved in community outreach through their Black community employee resource group (ERG) which is where my love for diversity, equity, and inclusion (DEI) stemmed from.I came to Google after 5 years of working at Microsoft to join the Cloud Systems team as a program manager in Austin. My team focuses on the continued improvement and maintenance of rep-facing tools. At that time, I was a technical program manager working directly with the engineers, tasked with maintaining their workloads by lifting blockers and collaborating with the product owners for timely solution deliveries. I now work as an enablement program manager for the same team, with a new focus on training and communication mediums. Tell us about the creation of the Standing United deck.A common theme in my career is being one of the very few Black people and/or women on my team. The upside to this is that I’ve gotten comfortable working in these spaces that are typically white-male dominated and can normally find ways to show impact. However, I find these spaces to typically be uncomfortable when racially charged protests begin. Having had those firsthand experiences, I knew that George Floyd’s death would spark conversations. I know how uncomfortable it can be for Black people to engage in this topic because it’s complex and is a conversation that is often met with resistance or defensiveness by non-Black people. While Google has many existing resources, I wanted to find a way to aid my team with information as well as process my own thoughts and translate my own experiences as a way to equip myself. I did not realize that my work would resonate for so many Googlers around the company. I didn’t predict that the deck would make its way into so many resource hubs, team meetings, and external networks. I’ve had the opportunity to speak to thousands of people over the summer, contribute to countless DEI working sessions and events, and even join some of these work groups and resource groups as a committee lead.I was afraid to do something this big, but allowing my natural instincts to guide me has had amazing results. I think we all can be shocked by what bravery produces—especially in regards to racial equity. I think it’s a must for those who want to be impactful and really change outdated and incorrect narratives and the systems that are structured around them. For myself, I didn’t realize that my small action would cause such a widespread impact. I believe this same sort of effort can be repeated by everyone, honestly. Any effort—of any capacity—can create a ripple effect and inspire more folks and change than expected.Do you have advice for others, particularly Black women in tech?Be yourself, whoever that is. You don’t have to look, act, or talk a certain way to be successful. I bring my locs, tattoos and piercings to work as a Black woman from the South every day. You may have to make sacrifices for your career, like location, but identity shouldn’t be one of them. Take time to find your community so you can have a home away from home—especially if you have to sacrifice leaving your community to pursue your career. The Black woman’s corporate experience requires so much strategy and as you try to find your place in this white-male dominated space, remember to commit to finding ways to show impact in whatever capacity you can. Your journey will be a sum of your persistence to overcome the challenges you will face, finding flexibility in your methods and staying committed to your goals.Allyship can be defined as supporting those in marginalized groups to which one does not identify.
Quelle: Google Cloud Platform

Community is a backbone of all sustainable open source projects and so at Docker, we’re particularly thrilled to announce that William Quiviger has joined the team as our new Head of Community.
William is a seasoned community manager based in Paris, having worked with open source communities for the past 15 years for a wide range of organizations including Mozilla Firefox, the United Nations and the Open Networking Foundation. His particular area of expertise is in nurturing, building and scaling communities, as well as developing mentorship and advocacy programs that help push leadership to the edges of a community.
To get to know William a bit more, we thought we’d ask him a few questions about his experience as a community manager and what he plans to focus on in his new role:
What motivated you most about joining Docker?
I started following Docker closely back in 2016 when I joined the Open Networking Foundation. There, I was properly introduced to cloud technologies and containerization and quickly realised how Docker was radically simplifying the lives of our developers and was the de-facto standard for anything deployed in the cloud. I was particularly impressed by the incredible passion and ever growing size of Docker’s community. Naturally, as a community manager, it’s a dream to have the opportunity to serve a community like Docker.
What are your main goals now that you’re part of the Docker team?
One of my main goals is to bring in my experience and learnings from my 15 years as a community manager in very different types of organizations and in different parts of the world. Through a lot of experimentation and trial and error, I’ve learned a ton. I want to take best practices and good ideas from other communities and apply them to the needs of Docker.
What will you focus on most in the next few months as you work to engage and help grow the Docker community?
That’s a tough question because there are so many areas I will be focusing on. Scaling a community is a big challenge and I want to make sure that the passion and excitement around Docker is translated into a growing, sustainable community that continues to bring value to our users and helps us achieve our business goals. A major challenge with growth is that processes and dynamics that worked well when the community was smaller can break down as the size of that community grows so the key is to empower leaders within the community to help scale efforts and push authority to the edges. That’s why the Docker Captains program will be a major focus for me. The Captains have been doing incredible work over the years and I want to help that program have even more impact in terms of engaging our existing community and the developer community at large. Another key area I will be focusing will be on developing community programs and initiatives that help us gather and surface user insights to our engineering and product teams. The more insights we gather about the way developers use Docker in their working lives, the better we can shape the direction of our products to fit their needs and use cases.
When you’re not building communities, what do you usually do in your spare time ?
When I’m not hunched over my laptop, I’m likely experimenting with a new recipe in my kitchen, reading history books or digging up rare recordings of my favorite Jazz artists. Lately though, I’ve become a chess addict so if you’re reading this and you’re into chess, ping me for a game!
The post A Chat With Docker’s New Community Manager appeared first on Docker Blog.
Quelle: https://blog.docker.com/feed/

In der Coronakrise brauchen Bewohner in Pflegeheimen WLAN, um mit Familie und Freunden in Kontakt zu bleiben. Doch das gibt es oft nicht. (Coronavirus, Telekommunikation)
Quelle: Golem