S-Pedelecs, E-Bikes und Motorroller: ADAC bietet E-Zweiräder im Abo an
Der ADAC will die Elektromobilität auf zwei Rädern fördern und bietet E-Bikes und E-Motorroller zur Miete an. Auch der Kauf ist möglich. (ADAC, Technologie)
Quelle: Golem

Der ADAC will die Elektromobilität auf zwei Rädern fördern und bietet E-Bikes und E-Motorroller zur Miete an. Auch der Kauf ist möglich. (ADAC, Technologie)
Quelle: Golem
Over the course of just a few years, the ways in which we consume content have changed dramatically. In order to compete in this new landscape and to adapt to the technological change that underpins it, media studios and other content producers should consider providing relatively open access to their proprietary content. This necessitates a cultural change across the industry. Cable television cancellation, or “cord cutting,” has increased significantly since 2010, and with the pandemic accelerating the trend, there are now more than 30 million cord-cutter U.S. households. The American digital content subscriber now watches streaming content across an average of more than three paid services. For several years, more video content has been uploaded to streaming services every 30 days than the major U.S. television networks have created in 30 years. With an abundance of content readily available across a growing number of platforms, each accessible from a plethora of different devices, media providers should invest in making it easier for consumers to find the video content they want to watch. If a viewer can’t access and stream something with minimal effort, they’ll likely move on to one of the countless alternatives readily at their disposal. Think about voice-based assistants and search services. When prompted to find a piece of content, these services sift through a multitude of third-party libraries, where access is permitted, and remove friction from the user experience. It’s important for media companies to evolve from siloed, closed-off content libraries to participation in digital ecosystems, where a host of partnership opportunities can precipitate wider reach and revenue opportunities. Ultimately, joining these communities facilitates the delivery of the right experience on the right device at the right time to the right consumer.Navigating a streaming jungle Legacy silos prevalent in the media and entertainment industry must be broken down to make way for richer viewing experiences. It’s critical that studios roll out content faster, distribute it more securely, and better understand their audiences so they can provide customers the content they want in the contexts they want. In order to achieve these goals, publishers must leverage technology that’s purpose-built for the demands of a more dynamic, competitive landscape.Publishers should consider embracing application programming interfaces, or APIs, to better connect with viewers and maximize return on content production. APIs, which facilitate interoperability between applications, allow publishers’ content to be consumed by more developers and publishing partners, who subsequently create more intelligent, connected experiences surrounding that content for the viewers. This new content value chain should leverage an API management tool that resides on top of cloud infrastructure to manage the partnerships that ultimately ensure media can easily make its way to the consumer on their ideal viewing platform. APIs let content owners and distributors interact with partner technologies to drive value from social interactions and attract a wider audience via insights derived from data and analytics. Perhaps most important is the ability for APIs to allow content to follow users as they start watching on one device, stop, and transfer to another. Content is increasingly separated from the device. APIs enable experiential continuity to be maintained when devices are changed, facilitating more seamless experiences across devices of different form factors and screen sizes. Consumers expect content to follow them wherever they go. How APIs improve content creation and distribution Last year, streaming services produced more original content than the entire television industry did in 2005—so for many media producers, adjusting to consumers’ new media consumption habits involves not only making content available on more devices but also producing more content, faster. Studios should explore solutions that help them collaborate globally and produce great content more securely and efficiently. In the content value chain, APIs are used to seamlessly connect artists and production crews to necessary resources and assets across multiple production technologies and locations. For example, via APIs, a film crew in one country can record, encode, and collaborate and share content with another studio in another country. These cloud-based production environments can offer a single destination for all contributors to access the assets they need while also keeping those assets accessible only to the right people in the right contexts. In addition, creating and distributing content requires a complex supply chain. APIs let multiple parties, each responsible for a different core function (such as content purchasing, storage, payments, physical media delivery, customer service, etc.), meld into a seamless experience for the customer. Rather than reimagining their strategy when it comes to these backend tasks, studios can leverage third-party APIs to expedite getting content in front of the right people and ultimately execute each of those functions more efficiently than they could on their own. Besides tapping into partner APIs, savvy media and entertainment companies can accelerate consumption of content by developing their own public APIs to securely provide access to their asset libraries, pricing, and other relevant information. This is important, as it lets media creators use the same API to serve content to a variety of services and device types, thus helping them scale content distribution without simultaneously having to scale security resources. Media companies’ APIs can also be implemented to deliver better customer experiences. Because APIs are involved each time a customer streams a video and every time a developer integrates a media asset into a new app or digital experience, API usage analytics can provide powerful insights into where, when, by whom, and on what devices different types of media—from traditional movies to augmented reality and other interactive content—are being accessed. Bringing it all together with an API management tool In order for studios to quickly adapt to a content value chain and distribute their content across multiple platforms, it’s important that they implement an API management tool on top of the cloud environment that powers content creation and distribution. For instance, Google Cloud offers Apigee, which sits on top of its public cloud. This added layer facilitates the integration between a studio’s proprietary environment and the strategic partnerships that APIs make possible. The API lifecycle can be rather complex, especially when multiple APIs are leveraged. It can include:Planning, design, implementation, testing, publication, operation, consumption, maintenance, versioning, and retirement of APIsLaunch of a developer portal to target, market to, and govern communities of developers who leverage APIsRuntime managementEstimation of APIs’ valueAnalytics to understand patterns of API usageUsing a management layer such as Apigee increases the likelihood that media and entertainment companies can combine the ability offered by public clouds and APIs to adapt to the requirements of new devices and protocols. It brings next-generation technology together to ensure studios can scale, secure, monitor, and analyze digital content creation and distribution.Related ArticleHelping media companies navigate the new streaming normalAs media and entertainment companies evolve their future plans as a result of COVID-19, they should keep new audience behaviors top of mi…Read Article
Quelle: Google Cloud Platform
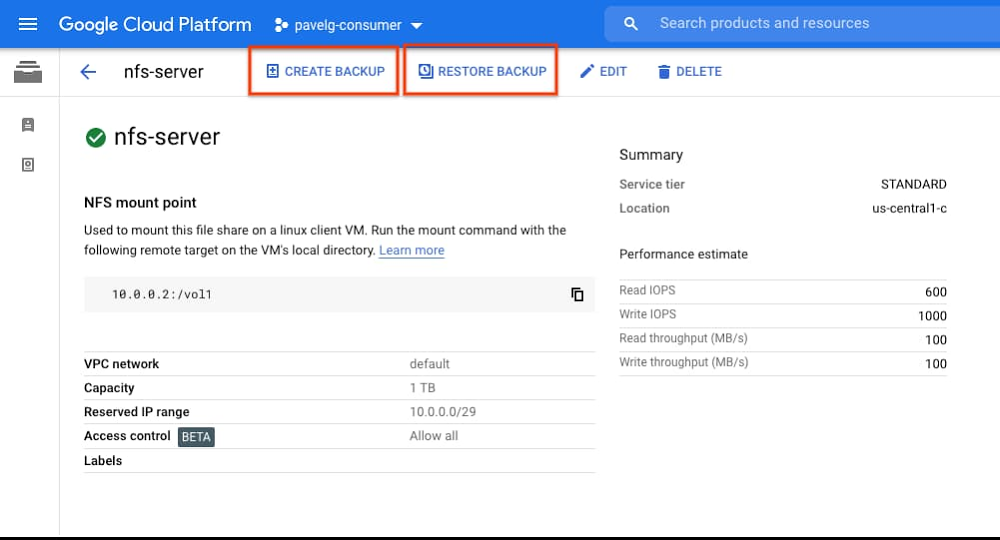
When you’re considering migrating mission-critical workloads to the cloud, it’s important to make it as easy as possible. We think maintaining your established, on-prem best practices can make a cloud migration a lot easier. Using established best practices reduces the need to rearchitect applications, and also helps ensure continuity as you migrate your infrastructure. We’re announcing the availability of Filestore Backups preview in all regions, making it easier to migrate your business continuity, disaster recovery and backup strategy for your file systems in Google Cloud.File system backups serve use cases such as disaster recovery, protection against accidental data changes, file system cloning and migration of data, all of which benefit from the ability to efficiently store a copy of data and metadata in a separate storage system. File system backups form a central component of any solid backup strategy, as they let you safely retain point-in-time copies of data shared across VMs and applications. While resiliency is an essential aspect of nearly every industry today, websites and ecommerce are one example where 24×7 uptime and reliability is critical. Downtime or lost data can mean a direct and immediate impact to a business. Google Cloud customer Liferay, one of the leading platforms for websites and ecommerce businesses, relies on Filestore backups to make sure they are supporting their customers with best-in-class reliability. “On Liferay DXP Cloud, we work with customers from all sizes and backgrounds with different storage and compliance needs,” says Eduardo Lundgren, CTO of Liferay Cloud. “Using Filestore allowed us to support all these needs while focusing on delivering new features instead of managing storage. Filestore Backups enable us to create daily snapshots of each customer, and if needed, restore their data quickly and safely.” Filestore backups can be used to restore a file system back to a previous state or to create a new Filestore instance whose data is identical to the original at the point in time the backup was taken. Filestore Backups features were designed to answer the requirements of enterprise file users. Here are a few of the benefits that Filestore Backups offers:Regional availability – Filestore backups are regional resources, which enables them to protect users against the rare case of inaccessibility of a given zone. If data in a zone is inaccessible, users can restore the data using the regional backup and continue working in any available zone. Cross-region creation – Filestore backups can also be created and stored to a region different from that of the origin file system. This enables users to protect their workloads against the inaccessibility of an entire region or to efficiently migrate file system data between regions. Compression and incremental data retention – To reduce costs, backups within a region are created incrementally based on previous backups and are automatically compressed. This means that the first backup you create is a compressed copy of the file share, and subsequent backups include only the new or modified data that is not contained in the previous backup.‘Create’ and ‘Restore’ functionality across Filestore Basic HDD and Filestore Basic SSD – Filestore backups can be created for either Filestore Basic HDD or Filestore Basic SSD instances and can be restored to either tier. This means that Filestore backups can be used to migrate data from Filestore Basic HDD to Basic SSD to increase performance or from Filestore Basic SSD to Basic HDD to reduce costs. Customers may use the backup feature to optimize cost and performance based on actual workload needs.Independent lifecycle of backup and filestore instance – Once a backup of a file system is created, the original instance may be safely deleted. As backups are stored on separate storage, the backup will be retained until it is deleted by the user. If access to the data in the backup is required a new filesystem can be created from the backup recreating the data and metadata of the deleted file system.These features let you use Filestore backups across multiple use cases, including:Backing up data for disaster recovery – Use Cloud Scheduler to regularly back up instances to a remote region. In the event of a disaster you can create a new instance in another location from any previous backup.Backing up data to protect against accidental changes – To protect your data against accidental deletions or changes due to human or software errors, back up your file system regularly and before major changes or upgrades. In the event of inadvertent loss or change to a file, you can identify the backup with the version of the file needed, create a new Filestore instance, and copy the original file over. Alternatively, you can do an in-place restore where the backup data is directly restored to the original Filestore instance.Creating clones for development and testing – If your Filestore instance serves production traffic and you want to run a test with the data in the file system as an input, simply create a clone Filestore instance from a backup to enable testing and development usage without interfering with production files systems.Migrating data – If you need to migrate a Filestore instance to another region, you can simply create a backup and restore the Filestore instance in the new region. This same method may also be used to create multiple copies of a file system across a collection of regions.Creating a backup or restoring from a backup is easy from the Google Cloud Console:The list of existing Filestore backups with more details is available in a separate “Backups” tab.Creation of a new instance from a backup details page is just a single click away:To get started, check out the Filestore Backup documentation or create a backup in the Google Cloud Console.This blog is dedicated to Allon Cohen, our colleague and friend who passed away this month. We want to thank Allon for his contributions to Filestore and Google Cloud.
Quelle: Google Cloud Platform
Over the years there’s been an explosion in infrastructure platforms and application frameworks that form the foundation of “cloud native.” Modern infrastructure platforms range from container orchestrators such as Kubernetes to serverless platforms aimed at rapid application development. In parallel, shell scripts that administrators used to deploy, configure, and manage these platforms evolved into what is now called Infrastructure as Code (IaC), which formalizes the use of higher level programming languages such as Python or Ruby or purpose-built languages such as HashiCorp’s HCL (through Terraform). Though IaC has been broadly adopted, it suffers from a major flaw: code does not provide a contract between the developer’s intent and runtime operation. Contracts are the foundation of a consistent, secure and high-velocity IT environment. But every time you modify or refactor code, you need to run validation tools to determine its intent.Which begs the question, why are admins using programming languages in the first place? Why is all of this so complicated? In many ways it’s an attempt to automate the unknown, the unpredictable. But by nature, most infrastructure is loosely defined and requires baling wire and duct tape to stick things together in ways that mimic what a system administrator would do when logged into a server.Furthermore, while provisioning infrastructure is important, IT practitioners also need to deploy and manage both infrastructure and applications from day two onwards in order to maintain proper operations. Ideally, you could use the same configuration management tools to deploy and manage both your infrastructure and applications holistically. The Kubernetes wayThings are different with Kubernetes…Instead of taking an imperative or procedural approach, Kubernetes relies on the notion of Configuration as Data, taking a declarative approach to deploying and managing cloud infrastructure as well as applications. You declare your desired state without specifying the precise actions or steps for how to achieve it. Every Kubernetes resource instance is defined by Configuration as Data expressed in YAML and JSON files. Creating a Deployment? Defining a Service? Setting a policy? It’s all Configuration as Data, and Kubernetes users have been in on the secret for the past six years. Want to see what we mean? Here’s a simple Kubernetes example…In just 10 lines of YAML, you can define a Service with a unique version of your application, set up the network to create a route, ingress, Service, and load balancer, and automatically scale up and down based on traffic. How does Configuration as Data work? Within the Kubernetes API Server are a set of controllers that are responsible for ensuring the live infrastructure state matches the declarative state that you express. For example, the Kubernetes service controller might ensure that a load balancer and Service proxy are created, that the corresponding Pods are connected to the proxy, and all necessary configuration is set up and maintained to achieve your declared intent. The controller maintains that configured state forever, until you explicitly update or delete that desired state.What’s less well known is that the Kubernetes Resource Model (KRM) that powers containerized applications can manage non-Kubernetes resources including other infrastructure, platform, and application services. For example, you can use the Kubernetes Resource Model to deploy and manage cloud databases, storage buckets, networks, and much more. Some Google Cloud customers also manage their applications and services using Kubernetes controllers that they developed in-house with open-source tools.How do you start leveraging the KRM for managing Google Cloud resources? Last year, Google Cloud released Config Connector, which provides built-in controllers for Google Cloud resources. Config Connector lets you manage your Google Cloud infrastructure the same way you manage your Kubernetes applications—by defining your infrastructure configurations as data—reducing the complexity and cognitive load for your entire team.Following our service example above, let’s say we want to deploy a Google Cloud Redis instance as a backing memory store for our service. We can use KRM by creating a simple YAML representation that is consistent with the rest of our application:We can create the Redis instance via KRM and Config Connector:Where CaD meets IaCDoes that mean you no longer need traditional IaC tools like Terraform? Not necessarily. There will always be a need to orchestrate configuration between systems, for example, collecting service IPs and updating external DNS sources. That’s where those tools come in. The benefit when managing Google Cloud resources with Config Connector is that the contract will be much stronger. This model also offers a better integration story and cleanly separates the responsibility for configuring a resource and managing it. Here’s an example with Terraform:Terraform is used to provision a Google Cloud network named “demo_network” via the Terraform provider for Google and to create a Google Cloud Redis instance connected to it via the Terraform Kubernetes provider and KRM. On the surface, the contract between Terraform and the two providers looks the same, but beneath the surface lies a different story.The Terraform provider for Google calls the Google Cloud APIs directly to create the networking resources. If you wanted to use another configuration tool you would need to create a new set of Google Cloud API integrations. Furthermore, you will jump back and forth between Kubernetes and Terraform to view resources created separately in each interface.On the other hand, the Kubernetes provider is backed by a controller running in Kubernetes that presents a KRM interface for configuring Redis instances. Once Terraform submits configuration in the form of data to a Kubernetes API server, the resource is created and is actively managed by Kubernetes. Configuration as Data establishes a strong contract between tools and interfaces for consistent results. You’re able to remain in the Kubernetes interface to manage resources and applications together. The Kubernetes API server continuously reconciles the live Google Cloud state with the desired state you established in Terraform with KRM. Configuration as Data complements Terraform with consistency between Terraform executions that may be hours, days, or weeks apart.To make a long story short, Configuration as Data is an exciting approach to infrastructure and app management that enables fluid interaction between native resources and configuration tools like IaC and command lines. It’s also an area that’s moving quickly. Stay tuned for more about Configuration as Data coming soon. In the meantime, try Config Connector with your Google Cloud projects and share your feedback about what you did, what worked, and what new features you’d like to see.Related ArticleUnify Kubernetes and GCP resources for simpler and faster deploymentsThe new Config Connector lets you manage GCP resources as if they were in Kubernetes.Read Article
Quelle: Google Cloud Platform

Docker is pleased to announce that as of today the integration with Docker Compose and Amazon ECS has reached V1 and is now GA!
We started this work way back at the beginning of the year with our first step – moving the Compose specification into a community run project. Then in July we announced how we were working together with AWS to make it easier to deploy Compose Applications to ECS using the Docker command line. As of today all Docker Desktop users will now have the stable ECS experience available to them, allowing developers to use docker compose commands with an ECS context to run their containers against ECS.
As part of this we want to thank the AWS team who have helped us make this happen: Carmen Puccio, David Killmon, Sravan Rengarajan, Uttara Sridhar, Massimo Re Ferre, Jonah Jones and David Duffey.
Getting started with Docker Compose & ECS
As an existing ECS user or a new starter all you will need to do is update to the latest Docker Desktop Community version (2.5.0.1 or greater) store your image on Docker Hub so you can deploy it (you can get started with Hub here), then you will need to get yourself setup on AWS and then lastly you will need to create an ECS context using that account. You are then read to use your Compose file to start running your applications in ECS.
We have done a couple of blog posts and videos along with AWS to give you an idea of how to get started or use the ECS experience.
Amazon’s GA announcement of the experienceDocker Announcement / AWS announcement Open sourcing the integration Deploying WordPress to ECS Amazon unboxing of ECS experience Docker Docs
If you have other questions about the experience or would like to give us feedback then drop us a message in the Compose CLI repo or in the #docker-ecs channel in our community Slack.
New in the Docker Compose ECS integration
We have been adding new features to the ECS integration over the last few months and we wanted to run you through some of the ones that we are more excited about:
GPU support
As part of the more recent versions of ECS we have provided the ability to deploy to EC2 (rather than the default fargate) to allow developers to make use of unique instance types/features like GPU within EC2.
To do this all you need to do is specify that you need a GPU instance type as part of your Compose file and the Compose CLI will take care of the rest!
services:
learn:
image: itamarost/object-detection-app:latest-gpu
command: python app.py
ports:
– target: 8000
protocol: tcp
x-aws-protocol: http
deploy:
resources:
# devices:
# – capabilities: [”gpu”]
reservations:
memory: 30Gb
generic_resources:
– discrete_resource_spec:
kind: gpus
value: 1
EFS support
We heard early feedback from developers that when you are trying to move to the cloud you may not be ready to move to managed service to persist your data and may still want to use volumes with your application. To solve this we have added Elastic File System (EFS) volume support to the Compose CLI allowing users to create volumes and use them as part of their Compose applications. This is created with a Retain policy so data won’t be deleted on application shut-down. If the same application (same project name) is deployed again, the file system will be re-attached to offer the same user experience developers are used to locally with docker-compose.
To do this I can either specify an existing file system that I have already created:
volumes:
my-data:
external: true
name: fs-123abcd
Or I can create a new one from scratch by providing information about how I want it configured:
volumes:
my-data:
driver_opts:
# Filesystem configuration
backup_policy: ENABLED
lifecycle_policy: AFTER_14_DAYS
performance_mode: maxIO
throughput_mode: provisioned
provisioned_throughput: 1024
I can also manage these through the docker volume command which lets me list and manage my resources allowing me to remove them when I no longer need them.
Context creation improvements
We have also been looking at how we improve the context creation flow to make this simpler and more interactive – while also allowing power users to specify things more up front if they know how they want to configure your context.
When you get started we now have 3 options for creating a new context:
? Create a Docker context using: [Use arrows to move, type to filter]
> An existing AWS profile
A new AWS profile
AWS environment variables
If you select an existing profile, we will list your available profiles to choose from and allow you to simply select the profile you want to have associated with this context.
$ docker context create ecs test2
? Create a Docker context using: An existing AWS profile
? Select AWS Profile nondefault
Successfully created ecs context “test2″
$ docker context inspect test2
[
{
“Name”: “test2″,
“Metadata”: {
“Description”: “(eu-west-3)”,
“Type”: “ecs”
},
“Endpoints”: {
“ecs”: {
“Profile”: “nondefault”,
}
…
}
]
If you want to create a new profile, we will ask you for the credentials needed to do this as part of the creation flow and will save this profile for you:
? Create a Docker context using: A new AWS profile
? AWS Access Key ID fiasdsdkngjgwka
? Enter AWS Secret Access Key *******************
? Region eu-west-3
Saving to profile “test3″
Successfully created ecs context “test3″
$ docker context inspect test3
[
{
“Name”: “test3″,
“Metadata”: {
“Description”: “(eu-west-3)”,
“Type”: “ecs”
},
“Endpoints”: {
“ecs”: {
“Profile”: “test3″,
}
},
…
}
]
If you want to do this using your existing AWS environment variables, then you can choose this option we will create the context with a reference to these env vars so we continue to respect them as you work with them:
$ docker context create ecs test1
? Create a Docker context using: AWS environment variables
Successfully created ecs context “test1″
$ docker context inspect test1
[
{
“Name”: “test1″,
“Metadata”: {
“Description”: “credentials read from environment”,
“Type”: “ecs”
},
“Endpoints”: {
“ecs”: {
“CredentialsFromEnv”: true
}
},
…
}
]
We hope this new simplified way of getting started and the flags we have added in here to allow you to override parts of this will help you get started with ECS even faster than before.
We are really excited about the new experience we have built with ECS, if you have any feedback on the experience or have ideas for other backends for the Compose CLI please let us know via our Public Roadmap.
Join our workshop “I Didn’t Know I Could Do That with Docker – AWS ECS Integration” with Docker’s Peter McKee and AWS’ Jonah Jones Tuesday, November 24, 2020 – 10:00am PT / 1:00pm ET. Register here.
The post Docker Compose for Amazon ECS Now Available appeared first on Docker Blog.
Quelle: https://blog.docker.com/feed/

Der Flexscan EV3895 ist ungewöhnlich, da Eizo normalerweise keine Monitore im 24:10-Format baut. Zudem sind viele Ports vorhanden, auch RJ45. (Eizo, Display)
Quelle: Golem

Es soll wieder Ausnahmen von der Routerfreiheit geben. Das sieht ein neuer Absatz im Entwurf der Novelle des Telekommunikationsgesetzes vor. (Routerfreiheit, Vodafone)
Quelle: Golem

Was am 19. November 2020 neben den großen Meldungen sonst noch passiert ist, in aller Kürze. (Kurznews, Firefox)
Quelle: Golem

Wie viele Ladesäulen sind für den Umstieg auf die Elektromobilität erforderlich? Das hängt laut einer Studie von mehreren Faktoren ab. (Elektroauto, Tesla)
Quelle: Golem

Fast zwei Jahre verhandelt United-Internet-Chef Ralph Dommermuth mit den drei Netzbetreibern. Doch alles was sie anbieten, ist ihm zu teuer. (United Internet, Telekom)
Quelle: Golem