Microsoft: Windows 10 stürzt nach Verbinden mit WPA3-WLAN ab
Mit einem Hotfix will Microsoft den ungewöhnlichen Bluescreen beheben. Der entsteht durch einen Fehler bei der Verbindung mit WPA3-Netzwerken. (Windows 10, WLAN)
Quelle: Golem

Mit einem Hotfix will Microsoft den ungewöhnlichen Bluescreen beheben. Der entsteht durch einen Fehler bei der Verbindung mit WPA3-Netzwerken. (Windows 10, WLAN)
Quelle: Golem

Wer ein Elektroauto kaufen will, muss teilweise sehr lange Wartezeiten einkalkulieren oder sich kurzfristig für ein anderes Modell entscheiden. (Elektroauto, Technologie)
Quelle: Golem

February is Black History Month—a time for us to come together to celebrate and remember the important people and history of the African heritage. Over the next four weeks, we will highlight four Black-led startups and how they use Google Cloud to grow their businesses. Our second feature highlights Zirtue and its founder, Dennis. Specifically, Dennis talks about how the team was able to innovate quickly with easy to use Google Cloud tools and services. I’m sure many of you have loaned money to your family and friends—and experienced the awkwardness of asking for that money back. While we all want to support our loved ones, we also want to ensure the money is going toward the right causes and that we will get paid back as promised. I founded my startup Zirtue,to provide a simple, easy and non-threatening way to formalize the loan process between friends and family.Predatory lending—low-income communities and the military Growing up in low-income housing in Monroe, Louisiana, I witnessed predatory lending practices in my community firsthand. Check cashing establishments take 20% of checks, or up to 400% for some payday lenders. I personally was targeted by predatory lenders after my military service. Lenders would set up shop next to military bases and charge interest up to 300% on short-term loans. The recent Military Lending Act helps mitigate this by capping the interest rate at 36%. While this is a good start, there is still more we can do to help those who have served, as well as other targets of predatory lending, such as people of color. Low-income communities have fewer resources to begin with and lenders take a portion of their already minimal earnings. Our goal at Zirtue is to help these communities and provide them with alternatives to the aggressive lending practices of the past. We aim to give people a hand up to help them continuously thrive, as opposed to a one-off hand out. Zirtue—a fair and equitable lending optionZirtue is a relationship-based lending application that simplifies loans between friends, family, and trusted relationships with automatic ACH (automated clearing house) loan payments. Everything is done through our app: the lender sets their payment terms, receives a loan request from a friend or family member, the borrower gets the funds, and the lender is able to easily track payments. The app also handles reminding the borrower to stick to the agreed upon terms and gets you paid back—avoiding that awkward follow-up call or text. Currently, both parties must have a bank account to set up a Zirtue account. However, approximately 25% of our target market is unbanked or underbanked and thus, ineligible for a loan. So we’re proud to be launching a Zirtue banking card this summer, to empower customers to link their transactions to our card instead of a bank. Funds will automatically load onto the card, and can be used to direct deposit paychecks, as well as a form of payment for goods and services. Using the card will help users graduate to other banking products in the future. Good Zirtue performance metrics can function as an alternate credit history, giving banks the data they need to confidently provide additional services and ultimately help break the cycle of predatory lending. Our recent infusion of $250K in funding from Morgan Stanley, as part of the Rise of the Rest Pitch Competition, and $250K from the Revolution Fund will help us achieve this major goal.Google Cloud technology for the greater good – Building Trust & SecurityFinancial transactions happen almost entirely online these days, so Zirtue relies on Google Cloud technology, including reCAPTCHA to make our app work day in and day out. Since we are handling sensitive financial information, security is top of mind. We are very proactive when it comes to protecting the integrity of the application and user data, including the use of bank-level encryption (AES-256), tokenization, hashing (SHA-512) and Two-Factor Authentication throughout the application. Further Google Cloud helps with security by encrypting data at rest and in transit.Our customers rely on us to send and receive money quickly, so it is vital to keep interruptions in service to a minimum. Firebase Crashlyticsprovides us with realtime crash reports that allow us to quickly troubleshoot problems within our app. Currently, we are growing 45% month over month, so there is no shortage of data to train and build out our AI/ML models. We are utilizing Cloud AutoML, which has the ability to train our ML models with a wealth of data from Zirtue borrowers using video to fill out their loan applications. The speech to text API transcribes the videos that are used to train our ML models to provide a more seamless user experience. This will also be used as an accessibility feature through the translation API, allowing customers to speak in their preferred language throughout the application process. Google for Startups Black Founder FundFirst, came the struggle of getting investors to believe in the app and—more importantly—believe that they should invest in a Black-owned business. The Black Founders Fund illuminates the struggles Black-led startups face when competing against their white counterparts, and proves what we can do when given access to the same resources.Next, it was difficult to take Zirtue to the next level. Hardcoding the front end of the app and outsourcing the back end meant that it was all hands on deck from every member of the team, 24/7. The $100K in non-dilutive funding from Google for Startups Black Founders Fund has been incredibly valuable for Zirtue, but the access to subject matter and product experts in AutoML and Google Cloud Team is priceless. Mentorship in marketing, SEO, and engineering—in combination with technology and the experts to implement it—has allowed us to deliver on our product promise and increase the impact we can have with our customers (special shoutout to Chandni Sharma and Daniel Navarro).It is an honor to be able to help those who historically have been viciously targeted by predatory lending practices—and an honor to help redefine what it means to be a successful founder while doing so. The Black Founders Fund means that we will be able to reach even more people with our efforts, and pave the way for future Black founders to come. With Google’s ongoing support, the financial technology industry—and the startup landscape—will never be the same. If you want to learn more about how Google Cloud can help your startup, visit our startup page here and sign up for our monthly startup newsletter to get a peek at our community activities, digital events, special offers, and more.Related ArticleBlack History Month: Celebrating the success of Black founders with Google Cloud: TQIntelligenceFebruary is Black History Month—a time for us to come together to celebrate and remember the important people and history of the African …Read Article
Quelle: Google Cloud Platform

Unser Wunschsmartphone lässt zu wünschen übrig – die Woche im Video. (librem5, Urheberrecht)
Quelle: Golem

Von den Airpods Pro waren wir begeistert und deshalb gespannt auf Apples Airpods Max – im Test finden wir keine Rechtfertigung für den hohen Preis. Ein Test von Ingo Pakalski (Airpods, Apple)
Quelle: Golem
omgubuntu.co.uk – Installing Docker on Ubuntu 20.04 is easy, and in this short guide we show you how easy! You learn how to install Docker on your system, step-by-step.
Quelle: news.kubernauts.io

With Valentine’s Day upon us, there is nothing the U.S. National Oceanic and Atmospheric Administration (NOAA) loves more than having our environmental data open and accessible to all—and the cloud is the perfect match for NOAA’s goal to disseminate its environmental data more broadly than ever before.In 2019, as part of the Google Cloud Public Datasets Program and NOAA’s Big Data Program, NOAA and Google signed a contract with the potential to span 10 years, so we could continue our partnership and expand our efforts to provide timely, open, equitable, and useful public access to NOAA’s unique, high-quality environmental information. Democratizing data analysis and access for everyoneNOAA sits on a treasure trove of environmental information, gathering and distributing scientific data about everything from the ocean to the sun. Our mission includes understanding and predicting changes in climate, weather, oceans, and coasts to help conserve and manage ecosystems and natural resources. But like many federal agencies, we struggle with data discoverability and adopting emerging technologies. The reality is that on our own, it would be difficult to share our massive volumes of data at the rate people want it. Partnering up with cloud service providers such as Google and migrating to cloud platforms like Google Cloud lets people access our datasets without driving up costs or increasing the risks that come with using federal data access services. It also unlocks other powerful processing technologies like BigQuery and Google Cloud Storage that enhance data analysis and improve accessibility. Google Cloud and other cloud-based platforms help us achieve our vision of making our data free and open and also aligns well with the overall agenda of the U.S. Government. The Foundations for Evidence-Based Policy Making Act, signed in January 2019, generally requires U.S. Government data to be open and available to the public. Working with cloud service providers such as Google Cloud helps NOAA democratize access to NOAA data—it’s truly a level playing field. Everyone has the same access in the cloud, and it puts the power of data in the hands of many, rather than a select few. Another critical benefit of data dissemination public-private partnerships, like our relationship with Google Cloud, is their ability to jumpstart the economy and promote innovation. In the past, the bar for an entrepreneur to enter a market like the private weather industry was extremely high. You needed to be able to build and maintain your own systems and infrastructure, which limited entry to larger organizations with the right resources and connections available to them. Today, to access our data on Google Cloud, all you need is a laptop and a Google account to get started. You can spin up your own HPC cluster on Google Cloud, run your model, and put it out into the marketplace without being burdened with the long-term maintenance. As a result, we see small businesses being able to leverage our data and operate in areas where previously they simply didn’t exist.Public-private data partnerships at the heart of innovationNOAA’s datasets have contributed to a number of innovative use cases that highlight the benefits of public-private data partnerships. Here are some projects to date: Acoustic detection of humpback whalesUsing over 15 years of underwater audio recordings from the Pacific Islands Fisheries Science Center of NOAA, Google helped develop algorithms to identify humpback whale calls. Historically, passive acoustic monitoring to identify whales was done manually by somebody sitting with a pair of headphones on all day, but using audio event analysis helped automate these tasks—and moved conservation goals forward by decades. Researchers now have new techniques at their disposal that help them automatically identify the presence of humpback whales so they can mitigate anthropogenic impacts on whales, such as ship traffic and other offshore activities. Our National Centers for Environmental Information established an archive of the full collection of multi-year acoustic data, which is now hosted on Google Cloud as a public dataset.Megaptera novaeangliae, the humpback whale, and a spectrogram of its call, one of the audio events found in the dataset, with time on the x-axis and frequency on the y-axis.Weather forecasting for fire detectionOne of the most important aspects of our mission is the protection of life—and the cloud and other advanced technologies are driving the discovery of new potential life-saving capabilities that keep people informed and safe. NOAA’s GOES-16 satellite and GOES-17 satellite provide critical datasets that help detect fires, identify their locations, and track their movements in near real-time. Combining our data and Google Earth Engine’s data analysis capabilities, Google recently introduced a new wildfire boundary map to provide deeper insights for areas impacted by ongoing wildfires.Using data from NOAA’s GOES satellites and Google Earth Engine, Google creates a digital polygon to represent the approximate wildfire impact area on Search and Google Maps.Start exploring and experimenting with NOAA’s datasets, including those found on Google Cloud Public Datasets. If you’re already using our public datasets, we’d love to hear from you. What data are you using and how? What are you looking forward to using the most?
Quelle: Google Cloud Platform

As the owner of Analytics, Monetization and Growth Platforms at Yahoo, one of the core brands of Verizon Media, I’m entrusted to make sure that any solution we select is fully tested across real-world scenarios. Today, we just completed a massive migration of Hadoop and enterprise data warehouse (EDW) workloads to Google Cloud’s BigQuery andLooker.In this blog we’ll walk through the technical and financial considerations that led us to our current architecture. Choosing a data platform is more complicated than just testing it against standard benchmarks. While benchmarks are helpful to get started, there is nothing like testing your data platform against real world scenarios. We’ll discuss the comparison that we did between BigQuery and what we’ll call the Alternate Cloud (AC), where each platform performed best, and why we chose BigQuery and Looker. We hope that this can help you move past standard industry benchmarks and help you make the right decision for your business. Let’s get into the details.What is a MAW and how big is it?Yahoo’s MAW (Media Analytics Warehouse) is the massive data warehouse which houses all the clickstream data from Yahoo Finance, Yahoo Sports, Yahoo.com, Yahoo Mail, Yahoo Search and various other popular sites on the web that are now part of Verizon Media. In one month in Q4 2020, running on BigQuery, we measured the following stats for active users, number of queries, and bytes scanned, ingested, and stored.Who uses the MAW data and what do they use it for?Yahoo executives, analysts, data scientists, and engineers all work with this data warehouse. Business users create and distribute Looker dashboards, analysts write SQL queries, scientists perform predictive analytics and the data engineers manage the ETL pipelines. The fundamental questions to be answered and communicated generally include: How are Yahoo’s users engaging with the various products? Which products are working best for users? And how could we improve the products for better user experience?The Media Analytics Warehouse and analytics tools built on top of it are used across different organizations in the company. Our editorial staff keeps an eye on article and video performance in real time, our business partnership team uses it to track live video shows from our partners, our product managers and statisticians use it for A/B testing and experimentation analytics to evaluate and improve product features, and our architects and site reliability engineers use it to track long-term trends on user latency metrics across native apps, web, and video. Use cases supported by this platform span across almost all business areas in the company. In particular, we use analytics to discover rends in access patterns and in which partners are providing the most popular content, helping us assess our next investments. Since end-user experience is always critical to a media platform’s success, we continually track our latency, engagement, and churn metrics across all of our sites. Lastly, we assess which cohorts of users want which content by doing extensive analyses on clickstream user segmentation.If this all sounds similar to questions that you ask of your data, read on. We’ll now get into the architecture of products and technologies that are allowing us to serve our users and deliver these analytics at scale.Identifying the problem with our old infrastructureRolling the clock back a few years, we encountered a big problem: We had too much data to process to meet our users’ expectations for reliability and timeliness. Our systems were fragmented and the interactions were complex. This led to difficulty in maintaining reliability and it made it hard to track down issues during outages. That leads to frustrated users, increasingly frequent escalations, and the occasional irate leader. Managing massive-scale Hadoop clusters has always been Yahoo’s forte. So that was not an issue for us. Our massive-scale data pipelines process petabytes of data every day and they worked just fine. This expertise and scale, however, were insufficient for our colleagues’ interactive analytics needs. Deciding solution requirements for analytics needsWe sorted out the requirements of all our constituent users for a successful cloud solution. Each of these various usage patterns resulted in a disciplined tradeoff study and led to four critical performance requirements:Performance RequirementsLoading data requirement: Load all previous day’s data by next day at 9am. At forecasted volumes, this requires a capacity of more than 200TB/day.Interactive query performance: 1 to 30 seconds for common queriesDaily use dashboards: Refresh in less than 30 secondsMulti-week data: Access and query in less than one minute.The most critical criteria was that we would make these decisions based on user experience in a live environment, and not based on an isolated benchmark run by our engineers.In addition to the performance requirements, we had several system requirements that spanned the multiple stages that a modern data warehouse must accommodate: simplest architecture, scale, performance, reliability, interactive visualization, and cost.System RequirementsSimplicity and architectural integrationsANSI SQL compliantNo-op/serverless—ability to add storage and compute without getting into cycles of determining the right server type, procuring, installing, launching, etc.Independent scaling of storage and computeReliabilityReliability and availability: 99.9% monthly uptimeScaleStorage capacity: hundreds of PBQuery capacity: exabyte per monthConcurrency: 100+ queries with graceful degradation and interactive responseStreaming ingestion to support 100s of TB/dayVisualization and interactivityMature integration with BI toolsMaterialized views and query rewriteCost-efficient at scaleProof of concept: strategy, tactics, resultsStrategically, we needed to prove to ourselves that our solution could meet the requirements described above at production scale. That meant that we needed to use production data and even production workflows in our testing. To focus our efforts on our most critical use cases and user groups, we focused on supporting dashboarding use cases with the proof-of-concept (POC) infrastructure. This allowed us to have multiple data warehouse (DW) backends, the old and the new, and we could dial up traffic between them as needed. Effectively, this became our method of doing a staged rollout of the POC architecture to production, as we could scale up traffic on the CDW and then do a cut over from legacy to the new system in real time, without needing to inform the users.Tactics: Selecting the contenders and scaling the dataOur initial approach to analytics on an external cloud was to move a three petabyte subset of data. The dataset we selected to move to the cloud also represented one complete business process, because we wanted to transparently switch a subset of our users to the new platform and we did not want to struggle with and manage multiple systems. After an initial round of exclusions based on the system requirements, we narrowed the field to two cloud data warehouses. We conducted our performance testing in this POC on BigQuery and “Alternate Cloud.” To scale the POC, we started by moving one fact table from MAW (note: we used a different dataset to test ingest performance, see below). Following that, we moved all the MAW summary data into both clouds. Then we would move three months of MAW data into the most successful cloud data warehouse, enabling all daily usage dashboards to be run on the new system. That scope of data allowed us to calculate all of the success criteria at the required scale of both data and users.Performance testing resultsRound 1: Ingest performance.The requirement is that the cloud load all the daily data in time to meet the data load service-level agreement (SLA) of “by 9 am the next day”—where day was local day for a specific time zone. Both the clouds were able to meet this requirement.Bulk ingest performance: TieRound 2: Query performanceTo get an apples-to-apples comparison, we followed best practices for BigQuery and AC to measure optimal performance for each platform. The charts below show the query response time for a test set of thousands of queries on each platform. This corpus of queries represents several different workloads on the MAW. BigQuery outperforms AC particularly strongly in very short and very complex queries. Half (47%) of the queries tested in BigQuery finished in less than 10 sec compared to only 20% on AC. Even more starkly, only 5% of the thousands of queries tested took more than 3 minutes to run on BigQuery whereas almost half (43%) of the queries tested on AC took 3 minutes or more to complete.Query performance: BigQueryRound 3: ConcurrencyOur results corroborated this study from AtScale: BigQuery’s performance was consistently outstanding even as the number of concurrent queries expanded.Concurrency at scale: BigQueryRound 4: Total cost of ownershipThough we can’t discuss our specific economics in this section, we can point to third-party studies and describe some of the other aspects of TCO that were impactful.We found the results in this paper from ESG to be both relevant and accurate to our scenarios. The paper reports that for comparable workloads, BigQuery’s TCO is 26% to 34% less than competitors.Other factors we considered included: Capacity and Provisioning EfficiencyScaleWith 100PB of storage and 1EB+ of query over those bytes each month, AC’s 1PB limit for a unified DW was a significant barrier. Separation of Storage and ComputeAlso with AC, you cannot buy additional compute without buying additional storage, which would lead to significant and very expensive overprovisioning of compute.Operational and Maintenance CostsServerlessWith AC, we needed a daily standup to look at ways of tuning queries (a bad use of the team’s time). We had to be upfront about which columns would be used by users (a guessing game) and alter physical schema and table layout accordingly. We also had a weekly “at least once” ritual of re-organizing the data for better query performance. This required reading the entire data set and sorting it again for optimal storage layout and query performance. We also had to think ahead of time (at least by a couple of months) about what kind of additional nodes were required based on projections around capacity utilization. We estimated this tied up significant time for engineers on the team and translated into a cost equivalent to 20+ person hours per week. The architectural complexity on the alternate cloud – because of its inability to handle this workload in a true serverless environment – resulted in our team writing additional code to manage and automate data distribution and aggregation/optimization of data load and querying. This required us to dedicate effort equivalent to two full time engineers to design, code and manage tooling around alternate cloud limitations. During a time of material expansion, this cost would go up further. We included that personnel cost in our TCO. With BigQuery, the administration and capacity planning has been much easier, taking almost no time. Infact, we barely even talk within the team before sending additional data over to Bigquery. With BigQuery we spend zero/little time doing maintenance or performance tuning activities.Productivity ImprovementsOne of the advantages of using Google BigQuery as the database, was that we could now simplify our data model and also unify our semantic layer by leveraging a then new BI tool – Looker. We timed how long it took our analysts to create a new dashboard using BigQuery with Looker and compared it to a similar development on AC with a legacy BI tool. The time for an analyst to create a dashboard went from one to four hours to just 10 minutes – a 90+% productivity improvement across the board. The single biggest reason for this improvement was a much simpler data model to work with and the fact that all the datasets could now be together in a single database. With hundreds of dashboards and analysis conducted every month, saving about one hour per dashboard returns thousands of person-hours in productivity to the organization.The way BigQuery handles peak workloads also drove a huge improvement in user experience and productivity versus the AC. As users logged-in and started firing their queries on the AC, they would get stuck because of the workload. Instead of a graceful degradation in query performance, we saw a massive queueing up of workloads. That created a frustrating cycle of back-and-forth between users, who were waiting for their queries to finish, and the engineers, who would be scrambling to identify and kill expensive queries, to allow for other queries to complete.TCO SummaryIn these dimensions—finances, capacity, ease of maintenance and productivity improvements— BigQuery was the clear winner with a lower total cost of ownership than the alternative cloud.Lower TCO: BigQueryRound 5: The intangiblesAt this point in our testing, the technical outcomes were pointing solidly to BigQuery. We had very positive experiences working with the Google account, product and engineering teams as well. Google was transparent, honest and humble in their interactions with Yahoo. In addition, the data analytics product team at Google Cloud conducts monthly meetings of a customer council that have been exceedingly valuable.Another reason why we saw this kind of success with our prototyping project, and eventual migration, was the Google team with whom we engaged. The account team, backed by some brilliant support engineers stayed on top of issues and resolved them expertly. Support and Overall Customer ExperiencePOC SummaryWe designed the POC to replicate our production workloads, data volumes, and usage loads. Our success criteria for the POC were the same SLAs that we have for prod. Our strategy of mirroring a subset of our production with the POC paid off well. We fully tested the capabilities of the data warehouses; and consequently we have very high confidence that the chosen tech, products, and support team will meet our SLAs at our current load and future scale.Lastly, the POC scale and design are sufficiently representative of our prod workloads that other teams within Verizon can use our results to inform their own choices. We’ve seen other teams in Verizon move to BigQuery, at least partly informed by our efforts.Here’s a roundup of the overall proof-of-concept trial that helped us pick BigQuery as the winner:With these results, we concluded that we would move more of our production work to BigQuery by expanding the number of dashboards that hit the BigQuery backend as opposed to Alternate Cloud. The experience of that rollout was very positive, as BigQuery continued to scale in storage, compute, concurrence, ingest and reliability as we added more and more users, traffic, and data. I’ll explore our experience fully using BigQuery in production in the second blog post of this series.
Quelle: Google Cloud Platform
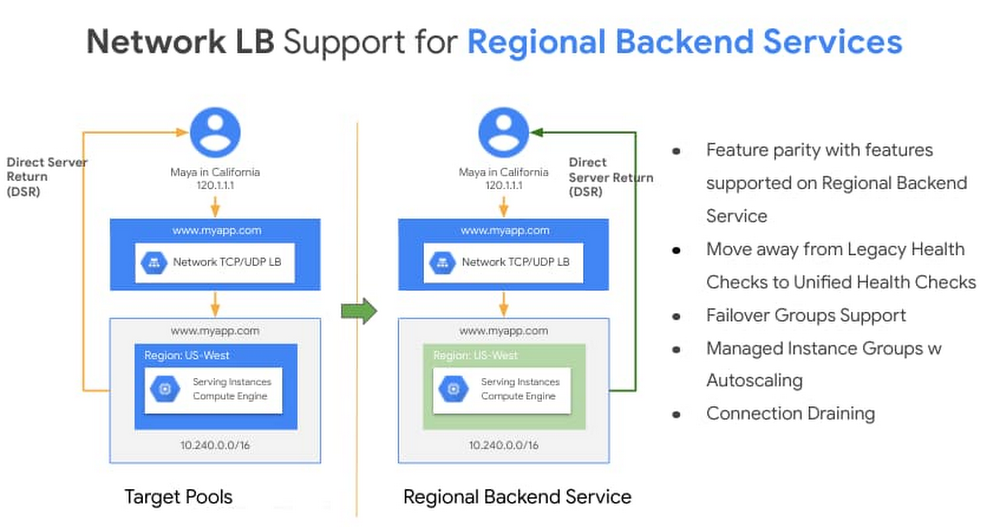
With Network Load Balancing, Google Cloud customers have a powerful tool for distributing external TCP and UDP traffic among virtual machines in a Google Cloud region. In order to make it easier for our customers to manage incoming traffic and to control how the load balancer behaves, we recently added support for backend services to Network Load Balancing. This provides improved scale, velocity, performance and resiliency to our customers in their deployment—all in an easy to manage way. As one of the earliest members of the Cloud Load Balancing family, Network Load Balancing uses a 5-tuple hash consisting of the source and destination IP address, protocol and source and destination ports. Network load balancers are built using Google’s own Maglev, which load-balances all traffic that comes into our data centers and front-end engines at our network edges, and can scale to millions of requests per-second, optimizing for latency and performance with features like direct server return, and minimizing the impact of unexpected faults on connection oriented protocols. In short, Network Load Balancing is a great Layer-4 load balancing solution if you want to preserve a client IP address all the way to the backend instance and perform TLS termination on the instances. We now support backend services with Network Load Balancing—a significant enhancement over the prior approach, target pools. A backend service defines how our load balancers distribute incoming traffic to attached backends and provides fine-grained control for how the load balancer behaves. This feature now provides a common unified data model for all our load-balancing family members and accelerates the delivery of exciting features on Network Load Balancing. As a regional service, a network load balancer has one regional backend service. In this blog post, we share some of the new features and benefits you can take advantage of with regional backend services and how to migrate to them. Then, stay tuned for subsequent blogs where we’ll share some novel ways customers are using Network Load Balancing, upcoming features and ways to troubleshoot regional backend services. Regional backend services bring the benefitsChoosing a regional backend service as your load balancer brings a number of advantages to your environment.Click to enlargeOut of the gate, regional backend services provide:High-fidelity health checking with unified health checking – With regional backend services you can now take full advantage of load balancing health check features, freeing yourself from the constraints of legacy HTTP health checks. For compliance reasons, TCP health checks with support for custom request and response strings or HTTPS were a common request for Network Load Balancing customers. Better resiliency with failover groups – With failover groups, you can designate an Instance Group as primary and another one as secondary and failover the traffic when the health of the instances in the active group goes below a certain threshold. For more control on the failover mechanism, you can use an agent such as keepalived or pacemaker and have a healthy or failing health check exposed based on changes of state of the backend instance.Scalability and high availability withManaged Instance Groups – Regional backend services support Managed Instance Groups as backends. You can now specify a template for your backend virtual machine instances and leverage autoscaling based on CPU utilization or other monitoring metrics.In addition to the above you will be able to take advantage of Connection Draining for connection oriented protocol (TCP) and faster programming time for large deployments.Migrating to regional backend servicesYou can migrate from target pools to regional backend services in five simple steps.1.Create unified health checks for your backend service.2. Create instance-groups from existing instances in the target pool3. Create a backend service and associate it with the newly created health checks.4. Configure your backend service and add the instance groups.5. Run get-health on your configured Backend Services to make sure the set of backends are accurate and health-status determined. Then use the set-target API to update your existing forwarding rules to the newly created backend service. UDP with regional backend services Google Cloud networks forward UDP fragments as they arrive. In order to forward the UDP fragments of a packet to the same instance for reassembly, set session affinity to None (NONE). This indicates that maintaining affinity is not required, and hence the load balancer uses a 5-tuple hash to select a backend for unfragmented packets, but 3-tuple hash for fragmented packets.Next stepsWith support for regional backend services with Network Load Balancing, you can now use high-fidelity health checks including TCP, getter better performance in programming times, use a uniform data model for configuring your load-balancing backends be they Network Layer Load Balancing or others, get feature parity with Layer 4 Internal Load Balancing with support for connection draining and failure groups. Learn more about regional backend services here and get a head start on your migration. We have a compelling roadmap for Network Load Balancing ahead of us, so stay tuned for more updates.Related ArticleGoogle Cloud networking in depth: Cloud Load Balancing deconstructedTake a deeper look at the Google Cloud networking load balancing portfolio.Read Article
Quelle: Google Cloud Platform
Over the past year, we (Mete and Guillaume) have developed a picture sharing application, named Pic-a-Daily, to showcase Google Cloud serverless technologies such as Cloud Functions, App Engine, and Cloud Run. Into the mix, we’ve thrown a pinch of Pub/Sub for interservice communication, a zest of Firestore for storing picture metadata, and a touch of machine learning for a little bit of magic.We also created a hands-on workshop to build the application, and slides with explanations of the technologies used. The workshop consists of codelabs that you can complete at your own pace. All the code is open source and available in a GitHub repository. Initial event-driven architectureThe Pic-a-Daily application evolved progressively. As new services were added over time, a loosely-coupled, event-driven architecture naturally emerged, as shown in this architecture diagram:To recap the event-driven flow:Users upload pictures on an App Engine web frontend. Those pictures are stored in a Google Cloud Storage bucket, which triggers file creation and deletion events, propagated through mechanisms such as Pub/Sub and Eventarc. A Cloud Function (Image analysis) reacts to file creation events. It calls the Vision API to assign labels to the picture, identify the dominant colors, and check if it’s a picture safe to show publicly. All this picture metadata is stored in Cloud Firestore. A Cloud Run service (Thumbnail service) also responds to file creation events. It generates thumbnails of the high-resolution images and stores them in another bucket. On a regular schedule triggered by Cloud Scheduler, another Cloud Run service (Collage services) creates a collage from thumbnails of the four most recent pictures. Last but not least, a third Cloud Run service (Image garbage collector) responds to file deletion events received through (recently generally available) Eventarc. When a high-resolution image is deleted from the pictures bucket, this service deletes the thumbnail and the Firestore metadata of the image.These services are loosely coupled and take care of their own logic, in a smooth choreography of events. They can be scaled independently. There’s no single point of failure, since services can continue to operate even if others have failed. Event-based systems can be extended beyond the current domain at play by plugging in other events and services to respond to them.However, monitoring such a system in its entirety usually becomes complicated, as there’s no centralized place to see where we’re at in the current business process that spans all the services. Speaking of business processes, it’s harder to capture and make sense of the flow of events and the interplay between services. Since there’s no global vision of the processes, how do we know if a particular process or transaction is successful or not? And when failures occur, how do we deal properly and explicitly with errors, retries, or timeouts?As we kept adding more services, we started losing sight of the underlying “business flow”. It became harder to isolate and debug problems when something failed in the system. That’s why we decided to investigate an orchestrated approach.Orchestration with WorkflowsWorkflows recently became generally available. It offered us a great opportunity to re-architect our application and use an orchestration approach, instead of a completely event-driven one. In orchestration, instead of microservices responding to events, there is an external service, such as Workflows, calling microservices in a predefined order. After some restructuring, the following architecture emerged with Workflows:Let’s recap the orchestrated approach:App Engine is still the same web frontend that accepts pictures from our users and stores them in the Cloud Storage bucket. The file storage events trigger two functions, one for the creation of new pictures and one for the deletion of existing pictures. Both functions create a workflow execution. For file creation, the workflow directly makes the call to the Vision API (declaratively instead of via Cloud Function code) and stores picture metadata in Firestore via its REST API. In between, there’s a function to transform the useful information of the Vision API into a document to be stored in Firestore. Our initial image analysis function has been simplified: The workflow makes the REST API calls and only the data transformation part remains. If the picture is safe to display, the workflow saves the information in Firestore, otherwise, that’s the end of the workflow. This branch of the workflow ends with calls to Thumbnail and Collage Cloud Run services. This is similar to before, but with no Pub/Sub or Cloud Scheduler to set up. The other branch of the workflow is for the picture garbage collection. The service itself was completely removed, as it mainly contained API calls without any business logic. Instead, the workflow makes these calls. There is now a central workflows.yaml file capturing the business flow. You can also see a visualization of the flow in Cloud Console:The Workflows UI shows which executions failed, at which step, so we can see which one had an issue without having to dive through heaps of logs to correlate each service invocation. Workflows also ensures that each service call completes properly, and it can apply global error and retry policies.With orchestration, the business flows are captured more centrally and explicitly, and can even be version controlled. Each step of a workflow can be monitored, and errors, retries, and timeouts can be laid out clearly in the workflow definition. When using Cloud Workflows in particular, services can be called directly via REST, instead of relying on events on Pub/Sub topics. Furthermore, all the services involved in those processes can remain independent, without knowledge of what other services are doing.Of course, there are downsides as well. If you add an orchestrator into the picture, you have one more component to worry about, and it could become the single point of failure of your architecture (fortunately, Google Cloud products come with SLAs!). Last, we should mention that relying on REST endpoints might potentially increase coupling, with a heavier reliance on strong payload schemas vs lighter events formats.Lessons learnedWorking with Workflows was refreshing in a number of ways and offered us some lessons that are worth sharing. Better visibilityIt is great to have a high-level overview of the underlying business logic, clearly laid out in the form of a YAML declaration. Having visibility into each workflow execution was useful, as it enabled us to clearly understand what worked in each execution, without having to dive into the logs to correlate the various individual service executions.Simpler codeIn the original event-driven architecture, we had to deal with three types of events:Cloud Functions’ direct integration with Cloud Storage eventsHTTP wrapped Pub/Sub messages with Cloud Storage events for Cloud RunEventarc’s CloudEvents based Cloud Storage events for Cloud RunAs a result, the code had to cater to each flavor of events:In the orchestrated version, there’s only a simple REST call and HTTP POST body to parse:Less codeMoving REST calls into the workflow definition as a declaration (with straightforward authentication) enabled us to eliminate quite a bit of code in our services; one service was trimmed down into a simple data transformation function, and another service completely disappeared! Two functions for triggering two paths in the workflow were needed though, but with a future integration with Eventarc, they may not be required anymore. Less setupIn the original event-driven architecture, we had to create Pub/Sub topics, and set up Cloud Scheduler and Eventarc to wire-up services. With Workflows, all of this setup is gone. Workflows.yaml is the single source of setup needed for the business flow. Error handlingError handling was also simplified in a couple of ways. First, the whole flow stops when an error occurs, so we were no longer in the dark about exactly which services succeeded and which failed in our chain of calls. Second, we now have the option of applying global error and retry policies. Learning curveNow, everything is not always perfect! We had to learn a new service, with its quirks and limited documentation — it’s still early, of course, and the documentation will improve over time with feedback from our customers.Code vs. YAML As we were redesigning the architecture, an interesting question came up over and over: “Should we do this in code in a service or should we let Workflows make this call from the YAML definition?”In Workflows, more of the logic lands in the workflow definition file in YAML, rather than code in a service. Code is usually easier to write, test, and debug than YAML, but it also requires more setup and maintenance than a step definition in Workflows. If it’s boilerplate code that simply makes a call to some API, that should be turned into YAML declarations. However, if the code also has extra logic, then it’s probably better to leave it in code, as YAML is less testable. Although there is some level of error reporting in the Workflows UI, it’s not a full-fledged IDE that helps you along the way. Even when working in your IDE on your development machine, you’ll have limited help from the IDE, as it only checks for valid YAML syntax.Loss of flexibilityThe last aspect we’d like to mention is perhaps a loss of flexibility. Working with a loosely-coupled set of microservices that communicate via events is fairly extensible, compared to a more rigid solution that mandates a strict definition of the business process descriptions.Choreography or orchestration?Both approaches are totally valid, and each has its pros and cons. We mentioned this topic when introducing Workflows. When should you choose one approach over the other? Choreography can be a better fit if services are not closely related, or if they can exist in different bounded contexts. Whereas orchestration might be best if you can describe the business logic of your application as a clear flow chart, which can then directly be described in a workflow definition. Next stepsTo go further, we invite you to have a closer look at Workflows, and its supported features, by looking at the documentation, particularly the reference documentation and the examples. We also have a series of short articles that cover Workflows, with various tips and tricks, as well as introductions to Workflows, with a first look at Workflows and some thoughts on choreography vs orchestration.If you want to study a concrete use case, with an event-based architecture and an equivalent orchestrated approach, feel free to look into our Serverless Workshop. It offers codelabs spanning Cloud Functions, Cloud Run, App Engine, Eventarc, and Workflows. In particular, lab 6 is the one in which we converted the event-based model into an orchestration with Workflows. All the code is also available as open source on GitHub.We look forward to hearing from you about your workflow experiments and needs. Feel free to reach out to us on Twitter at @glaforge and @meteatamel.Related ArticleGet to know Workflows, Google Cloud’s serverless orchestration engineGoogle Cloud’s purpose-built Workflows tool lets you orchestrate complex, multi-step processes more effectively than general-purpose tools.Read Article
Quelle: Google Cloud Platform