Vertriebschef Zellmer: VW plant Verbrenner-Ausstieg bis spätestens 2035
In Europa will Volkswagen spätestens ab 2035 keine Fahrzeuge mit Verbrennermotor mehr verkaufen. Das kündigte VW-Vertriebschef Klaus Zellmer an. (VW, Technologie)
Quelle: Golem

In Europa will Volkswagen spätestens ab 2035 keine Fahrzeuge mit Verbrennermotor mehr verkaufen. Das kündigte VW-Vertriebschef Klaus Zellmer an. (VW, Technologie)
Quelle: Golem

Tesla muss eine Art Rückruf für mehr als 285.000 seiner Fahrzeuge in China durchführen. Grund ist ein Sicherheitsproblem beim adaptiven Tempomaten. (Tesla, Technologie)
Quelle: Golem

Quelle: <a href="US Intelligence Agencies Are Trying To Solve Scientific Mysteries And Failing Badly“>BuzzFeed

Google Cloud Compute VMs are built on the same global infrastructure that runs Google’s search engine, Gmail, YouTube and other services. And over the years, we’ve continued to launch more and more Compute family and VMs types to serve your workload needs at the price point you’re looking for. When you take a bird’s eye look at our Compute offerings, you’ll notice the following family types:General Purpose(E2/N2/N2D/N1): Virtual machines well suited when you need a balance between customization, performance, and total cost of ownership.Compute Optimized (C2/C2D): Performance sensitive workloads where CPU frequency and consistency are required, or applications that require more powerful cores and a higher core:memory ratios.Memory Optimized(M1/M2): Virtual machines for the largest memory requirements for business critical workloads.Accelerator Optimized(A2): These are the highest performance GPUs for ML, HPC, and massive parallelized computation.As their names might suggest, each family is optimized for specific workload requirements. While they cover use cases like dev/test, enterprise apps, HPC, and large in-memory databases, many customers still have compute requirements for scale-out workloads, like large scale Java apps, web-tier applications, and data analytics. They want focused VM features without breaking the bank or sacrificing developer productivity. The Tau VM family is the new VM family that extends Compute Engine’s VM offerings for those looking for cost-effective performance for scale-out workloads with full x86 compatibility. Check out the official blog post and my video below to get a quick intro to the new Tau VM family and T2D, its first instance type. If you’re like me and still want help understanding when to use T2D VMs and how they stack up, here are 5 Tau VM facts that should help:1. T2D VMs are built on the latest 3rd generation AMD EPYCTM processorsAMD EPYC processors are x86-64 microprocessors based on AMD’s Zen microarchitecture (introduced in 2017). The third generation, Milan, came out in March 2021, building upon the previous generation with additional compute density and performance for the cloud. At our data centers, we’re able to get more performance per socket per rack, and pass that over to workloads running on T2D VMs. The AMD EPYC processor-based VMs also preserve x86 compatibility so that you don’t need to utilize technical resources and time redesigning applications and instead can immediately take full advantage of x86 processing speed and ecosystem depth. 2. T2D VMs are well suited for cloud-native and scale-out workloadsCloud-native workloads have led to the continued proliferation of distributed architectures. Data analytics and media streaming, for example, often leverage scale-out (horizontally scalable) multi-tier architectures. That means when additional processing power is needed, you can scale out by statically adding or removing resources to meet changing application demands. As cluster sizes increase, the communication requirements between compute notes rise quickly. AMD EPYC processors are built using the Zen 3 architecture, which uses a new “unified complex” design that dramatically reduces core-to-core and core-to-cache latencies. This reduces communication penalties when you need fast scale-out across compute nodes.T2D VMs offer the ideal combination of performance and price for your scale-out workloads including web servers, containerized microservices, media transcoding, and large-scale Java applications. T2D VMs will come in predefined VM shapes, with up to 60 vCPUs per VM, and 4 GB of memory per vCPU, and offer up to 32 Gbps networking.3. T2D VMs win against other major cloud providers on absolute performance and price-performanceLet’s take an example. A 32vCPU VM with 128GB RAM will be priced at $1.3520 per hour for on-demand usage in us-central1. This makes T2D the lowest cost solution for scale-out workloads, with 56% higher absolute performance and 42% higher price-performance compared to general-purpose VMs of any of the leading public cloud vendors. You can check out how we collected these benchmark results and how to reproduce them here.* Results are based on estimated SPECrate®2017_int_base run on production VMs of two other leading cloud vendors and pre-production Google Cloud Tau VMs using vendor recommended compilers. View testing detailshere. SPECrate is a trademark of the Standard Performance Evaluation Corporation. More information available at www.spec.org4. Google Kubernetes Engine support from day oneGoogle Kubernetes Engine (GKE) supports Tau VMs, helping you optimize price-performance for your containerized workloads. You can add T2D nodes to your GKE clusters by specifying the T2D machine type in your GKE node pools.This is useful if you’re leveraging GKE’s cluster autoscaler, for example, which resizes the number of nodes in a given node pool, based on the demands of your workloads (another example of horizontal scaling). You specify a minimum and maximum size for the node pool, and the rest is automatic. T2D VMs in this case would provide scale-out performance and low latency during autoscaling events.In addition, cluster autoscaler considers the relative cost of the instance types in the various pools, and attempts to expand the least expensive possible node pool. Coupled with the T2D VMs price-performance ratio, you can experience a lower total cost of ownership without sacrificing performance and scale. 5. We worked with pre-selected customers to test Tau VM performanceSnap, Inc. is continuing to improve their scale-out compute infrastructure for key capabilities like AR, Lenses, Spotlight, and Maps. After testing the T2D VMs with Google Kubernetes Engine, they saw the potential for a double-digit performance gain in the companies’ real-world workloads. Likewise, Twitter shared their excitement about the price-performance enhancements critical for their infrastructure used to serve the global public conversation. If you’re interested in signing up to try out the Tau VMs (slated for Q3 2021), you can sign up here. Want to connect? Find me online at @stephr_wong. Related ArticleNew Tau VMs deliver leading price-performance for scale-out workloadsCompute Engine’s new Tau VMs based on AMD EPYC processors provide leading price/performance for scale-out workloads on an x86-based archi…Read Article
Quelle: Google Cloud Platform

Es wird wieder abgemahnt und Windows 11 ist offiziell. Die Woche im Video. (Golem-Wochenrückblick, Microsoft)
Quelle: Golem

Sechs Ryzen-Kerne samt einer Radeon RX 6700 XT sind dank Smart Acess Memory und FidelityFX Super Resolution exzellent für Gaming. (AMD Zen, AMD)
Quelle: Golem
The “housekeeping” stage of a software’s life cycle, known as Day 2 operations, is key to promoting the overall stability and health of your software. But what are Day 2 operations exactly, and how does Red Hat support them?
Quelle: CloudForms
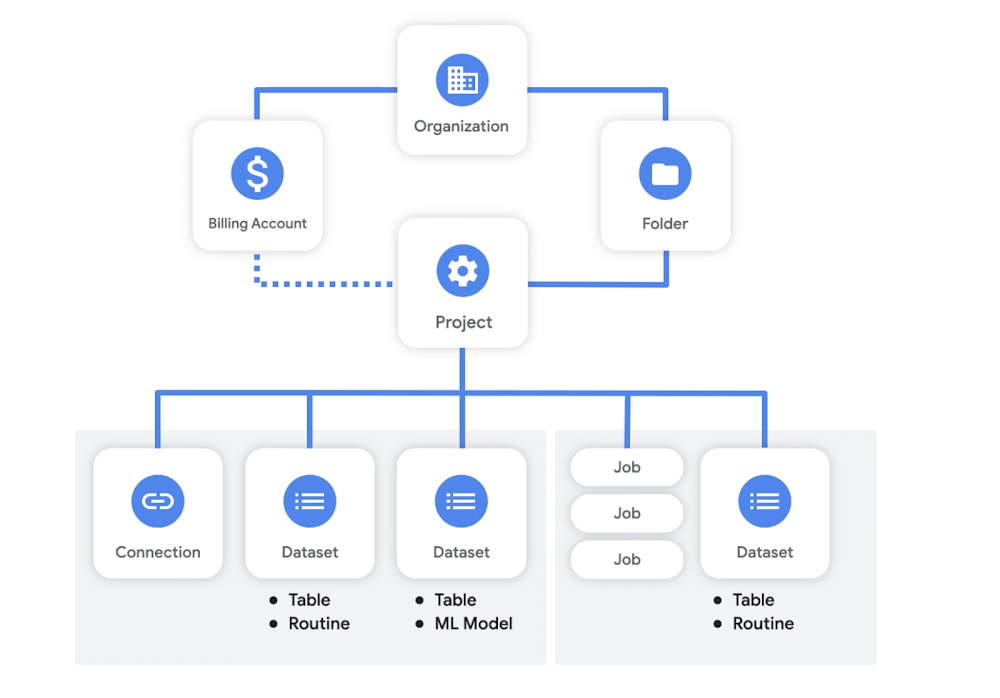
Starting this week, we’re adding new content to the BigQuery Spotlight Youtube series. Throughout the summer we’ll be adding new videos and blog posts focused on helping new BigQuery architects and administrators master the fundamentals. You can find complimentary material for the topics discussed in the official BigQuery documentation, which is linked below. First up, the BigQuery Resource Model!BigQuery, like other Google Cloud resources, is organized hierarchically where the Organization node is the root node, the Projects are the children of the Organization, and Datasets are descendants of Projects. In this post, we will look closer at the BigQuery resource model and discuss key considerations for architecting your deployment based on business needs. BigQuery core Resource Model Organizations, folders & billing accountsThe Organization resource is the root node of the Google Cloud resource hierarchy. It represents a company and is closely associated with your organization’s domain by being linked to one Google Workspace or Cloud Identity account. While an Organization is not required to get started using BigQuery, it is recommended. With an Organization resource, projects belong to your organization instead of the employee who created the project. Furthermore, organization administrators have central control of all resources. Folders are an additional grouping mechanism on top of Projects. They can be seen as sub-organizations within the Organization. Folders can be used to model different legal entities, departments, and teams within a company. Folders act as apolicy inheritance point – IAM roles granted on a folder are automatically inherited by all Projects and folders included in that folder. For BigQuery flat-rate customers, slots (units of CPU) can be assigned to Organizations, Folders or Projects where they are distributed fairly among projects to handle job workloadsA Billing Account is required to use BigQuery, unless you are using the BigQuery sandbox. Many times, different teams will want to be billed individually for consuming resources in Google Cloud. Therefore, each billing group will have its own billing account, which results in a single invoice and is tied to a Google Payments profile. ProjectsA Project is required to use BigQuery and forms the basis for using all Google Cloud services. Projects are analogous to databases in other systems.A project is used both for storing data and for running jobs on, or querying, data. And because storage and compute are separate, these don’t need to be the same project. You can store your data in one project and query it from another, this includes combining data stored in multiple projects in a single query. A project can have only one billing account, the project will be billed for data stored in the project and jobs run in the project. Watch out for per-project limitations and quotas. DatasetsDatasets are top-level containers, within a project, that are used to organize and control access to tables, views, routines and machine learning models. A table must belong to a dataset, so you need to create at least one dataset before loading data into BigQuery.Your data will be stored in the geographic location that you chose at the dataset’s creation time. After a dataset has been created, the location can’t be changed. One important consideration is that you will not be able to query across multiple locations, you can read details on location considerations here. Many users chose to store their data in a multi-region location, however some chose to set a specific region that is close to on-premise databases or ETL jobs.Access controlsAccess to data within BigQuery can be controlled at different levels in the resource model, including the Project, Dataset, Table or even column. However, it’s often easier to control access higher in the hierarchy for simpler management. Examples of common BigQuery project structures:By now you probably realize that deciding on a Project structure can have a big influence on data governance, billing and even query efficiency. Many customers chose to deploy some notion of data lakes and data marts by leveraging different Project hierarchies. This is mainly a result of cheap data storage, more advanced SQL offerings which allow for ELT workloads and in-database transformations, plus the separation of storage and compute inside of BigQueryCentral data lake, department data martsWith this structure, there is a common project that stores raw data in BigQuery (Unified Storage project), also referred to as a Data Lake. It’s common for a centralized data platform team to create a pipeline that actually ingest data from various sources into BigQuery within this project. Each department or team would then have their own datamart projects (e.g. Department A Compute) where they can query the data, save results and create aggregate views.How it works:Central data engineering team is granted permission to ingest and edit data in the storage projectDepartment analysts are granted BigQuery Data Viewer role for specific datasets in the Unified Storage projectDepartment analysts are also granted BigQuery Data Editor role and BigQuery Job User role for their department’s compute projectEach compute project would be connected to the team’s billing accountThis is especially useful for when:Each business unit wants to be billed individually for their queriesThere is a centralized platform or data engineering team that ingests data into BigQuery across business unitsDifferent business units access their data in their own tools or directly in the consoleYou need to avoid too many concurrent queries running in the same project (due to per-project quotas)Department data lakes, one common data warehouse projectWith this option, data for each department is ingested into separate projects – essentially giving each department their own data lake. Analysts are then able to query these datasets or create aggregate views in a central data warehouse project, which can also easily be connected to a business intelligence tool.How it works:Data engineers who are responsible for ingesting specific data sources are granted BQ Data Editor and BQ Job User roles in their department’s storage projectAnalysts are granted BQ Data Viewer role to underlying data at the project level, for example an HR analyst might be granted data viewer access to the entire HR storage projectService accounts that are used to connect BigQuery to external business intelligence tools can be also be granted data viewer access to specific projects that contain datasets to be used in visualizationsAnalysts and Service Account are then granted BQ Job User and BQ Data Editor roles in the Central Data Warehouse projectThis is especially useful for when:It’s easier to manage raw data access at the project / department levelCentral analytics team would rather have a single project for compute, which could make monitoring queries simpler Users are accessing data from a centralized business intelligence toolSlots can be assigned to the data warehouse project to handle all queries from analysts and external toolsNote that this structure may result in a lot of concurrent queries, so watch out for per-project limitations. This structure works best for flare-rate customers with lifted concurrency limits. Department data lakes and department data martsHere, we combine the previous approaches and create a data lake or storage project for each department. Additionally, each department might have their own datamart project where analysts can run queries.How it works:Department data engineers are granted BQ Data Editor and BQ Job User roles for their department’s data lake projectDepartment data analysts are granted BQ Viewer roles for their department’s data lake projectDepartment data analysts are granted BQ Data Editor and BQ Job User roles for their department’s data mart projectAuthorized views and authorized user defined functions can be leveraged to give data analysts access to data in projects where they themselves don’t have accessThis is especially useful for when:Each business unit wants to be billed individually both for data storage and computeDifferent business units access their data in their own tools or directly in the consoleYou need to avoid too many concurrent queries running in the same projectIt’s easier to manage raw data access at the project / department levelNow you should be well on your way to beginning to architect your BigQuery Data Warehouse! Be sure to keep an eye out for more in this series by following me on LinkedIn and Twitter!Related ArticleSpring forward with BigQuery user-friendly SQLThe newest set of user-friendly SQL features in BigQuery are designed to enable you to load and query more data with greater precision, a…Read Article
Quelle: Google Cloud Platform

Today we’re featuring a blog from Pablo Chico de Guzmán at Okteto, who writes about how the developers’ love of Docker Compose inspired Okteto to create Okteto Stacks, a fully compatible Kubernetes backend for Docker Compose
It has been almost 7 years since the Docker Compose v1.0.0 release went live. Since that time, Docker Compose has become the dominant tool for local development environments. You run one command and your local development environment is up and running. And it works the same way on any OS, and for any application.
At the same time, Kubernetes has grown to become the dominant platform to deploy containers in production. Kubernetes lets you run containers on multiple hosts for fault tolerance, monitors the health of your applications, and optimizes your infrastructure resources. There is a rich ecosystem around it, and all major providers have native support for Kubernetes: GKE, AKS, EKS, Openshift…
We’ve interacted with thousands of developers as we build Okteto (a cloud-native platform for developers). And we kept hearing the same complaint: there’s a very steep learning curve when you go from Docker Compose to Kubernetes. At least, that was the case until today. We are happy to announce that you can now run your Docker Compose files in Kubernetes with Okteto!
Why developers need Docker Compose in Kubernetes
Developers love Docker Compose, and they love it for good reasons. A Docker Compose file for five microservices might be around 30 lines of yaml, but the same application in Kubernetes would be 500+ lines of yaml and about 10-15 different files. Also, the Docker Compose CLI rebuilds and redeploys containers when needed. In Kubernetes, you need additional tools to build your images, tag them, push them to a Docker Registry, update your Kubernetes manifests, and redeploy them. It’s too much friction for something that’s wholly abstracted away by Docker Compose.
But there are some use cases where running your Docker Compose files locally presents some challenges. For example, you might need to run dozens of microservices that exhausts your local CPU/Memory resources, you might need access to GPUs to develop a ML application, or you might want to integrate with a service deployed in a remote Kubernetes cluster. For these scenarios, running Docker Compose in Kubernetes is the perfect solution. This way, developers get access to on demand CPU/Memory/GPU resources, direct access to other services running in the cluster, and more realistic end-to-end integration with the cluster configuration (ingress controllers, SSL termination, monitoring tools, secret manager tools…), while still using the application definition format they know and love.
Docker Compose Specification to the rescue
Luckily, the Docker Compose Specification was open-sourced in 2020. This allowed us to implement Okteto Stacks, a fully compatible Kubernetes backend for Docker Compose. Okteto Stacks are unique with respect to other Kubernetes backend implementations of the Docker Compose Specification because they provide:
In-cluster builds for better performance and caching behavior.Ingress Controller integration and SSL termination for public ports.Bidirectional synchronization between your local filesystem and your containers in Kubernetes.
Okteto’s bidirectional synchronization is pretty handy: it reloads your application on the cluster while you edit your code locally. It’s equivalent to mounting your code inside a container using Docker Compose host volumes, but for containers running in a remote cluster.
How to get started
Okteto Stacks are compatible with any Kubernetes cluster (you will need to install the Okteto CLI and a cluster-side Kubernetes application). But the easiest way to get started with Okteto Stacks is Okteto Cloud, the SaaS version of our cloud-native development platform.
To show the possibilities of Okteto Stacks, let’s deploy the famous Voting App. My team @Tutum developed the Voting App for the DockerCon keynote (EU 2015) to showcase the power of Tutum (later acquired by Docker that year). The demo gods were appeased with an offering of grapes that day. And I hope they are appeased again as you follow this tutorial:
First, install the Okteto CLI if you haven’t done it yet.
Next, configure access to your Okteto Cloud namespace. To do that, execute the following command:
$ okteto namespace
Authentication required. Do you want to log into Okteto? [y/n]: y
What is the URL of your Okteto instance? [https://cloud.okteto.com]:
Authentication will continue in your default browser
✓ Logged in as cindy
✓ Updated context ‘cloud_okteto_com’ in ‘/Users/cindy/.kube/config’
Get a local version of the Voting App by executing the following commands:
$ git clone https://github.com/okteto/compose-getting-started
$ cd compose-getting-started
Execute the following command to deploy the Voting App:
$ okteto stack deploy –wait
✓ Created volume ‘redis’
✓ Deployed service ‘vote’
✓ Deployed service ‘redis’
✓ Stack ‘compose-getting-started’ successfully deployed
The deploy command will create the necessary deployments, services, persistent volumes, and ingress rules needed to run the Voting App. Go to the Okteto Cloud dashboard and you will get the URL of the application.
Now that the Voting App is running, let’s make a small change to show you the full development workflow.
Instead of our pet, let’s ask everyone to vote on our favorite lunch item. Open the “vote/app.py” file in your IDE and modify the lines 16-17. Save your changes.
def getOptions():
option_a = “Tacos”
option_b = “Burritos”
Once you’re happy with your changes, execute the following command:
$ okteto up
✓ Images successfully pulled
✓ Files synchronized
Namespace: cindy
Name: vote
* Serving Flask app ‘app’ (lazy loading)
* Environment: development
* Debug mode: on
* Running on http://10.8.4.205:8080/ (Press CTRL+C to quit)
* Restarting with stat * Debugger is active! * Debugger PIN: 139-182-328
Check the URL of your application again. Your code changes were instantly applied. No commit, build, or push required. And from this moment, any changes done from your IDE will be immediately applied to your application!
That’s all!
Go to the Okteto Stacks docs to learn more about our Docker Compose Kubernetes backend. We’re just starting, so we’d love to hear your thoughts on this.
Happy coding!
The post From Compose to Kubernetes with Okteto appeared first on Docker Blog.
Quelle: https://blog.docker.com/feed/

Was unter iOS bislang nur bei System-Apps möglich war, geht ab Version 15 auch bei Anwendungen von Drittanbietern: Zugriff auf mehr Arbeitsspeicher. (Apple, iPhone)
Quelle: Golem