Google: Chromebooks sperrten Nutzer nach Update aus
Durch einen simplen Tippfehler kam es bei einem Chrome-OS-Update zu einem folgenreichen Fehler – den Google mittlerweile beseitigt hat. (Chrome OS, Google)
Quelle: Golem

Durch einen simplen Tippfehler kam es bei einem Chrome-OS-Update zu einem folgenreichen Fehler – den Google mittlerweile beseitigt hat. (Chrome OS, Google)
Quelle: Golem

Im Gesundheitssystem werden derzeit Messenger wie Whatsapp genutzt. Künftig gibt es einen Matrix-Chat für 150.000 Organisationen. (Matrix, Instant Messenger)
Quelle: Golem
We recently announced the availability of Red Hat JBoss Enterprise Application Platform (JBoss EAP) as a native offering in Microsoft Azure via the Azure Marketplace. At the same time, we noted that work was underway to make JBoss EAP available in Azure App Service as a fully supported runtime managed by Microsoft.
Quelle: CloudForms
Sigstore is an open source project originally conceived and prototyped at Red Hat and now under the auspices of the Linux Foundation with backing from Red Hat, Google and other IT leaders. Sigstore offers a method to better secure software supply chains in an open, transparent and accessible manner. So why do we need something like sigstore, exactly? And what does sigstore do that existing technologies, built to certify and sign digital technologies, don’t?
Quelle: CloudForms
Beyond the latest and greatest in Linux, Kubernetes, and cloud technology, Red Hat Summit Virtual Experience also included a host of Red Hat Services sessions focusing on processes and culture. Catch up on the sessions you might have missed to take the next step in your organization’s digital transformation.
Quelle: CloudForms
Often you know what you want to do, you just can’t remember the vocabulary or syntax for how to do it. This Kubernetes cheat sheet is designed to help solve that problem. Kubernetes provides a way to orchestrate containers to provide a robust, cloud native environment. The architecture looks something like this: Kubernetes Terms Terms … Continued
Quelle: Mirantis

We are excited to bring GPUs to the world of big data processing, in partnership with NVIDIA, to unlock new possibilities for you. With Dataflow GPU, users can now leverage the power of NVIDIA GPUs in their data pipelines. This brings together the simplicity and richness of Apache Beam, serverless and no-ops benefits of Dataflow, and the power of GPU based computing. Dataflow GPUs are provisioned on-demand and you only pay for the duration of your job. Businesses of all sizes and industries are going through hard data driven transformations today. A key element of that transformation is using data processing in conjunction with machine learning to analyze and make decisions about your systems, users, devices and the broader ecosystem that they operate in. Dataflow enables you to process vast amounts of data (including structured data, log data, sensor data, audio video files and other unstructured data) and use machine learning to make decisions that impact your business and users. For example, users are using Dataflow to solve problems such as detecting credit card fraud, physical intrusion detection by analyzing video streaming, and detecting network intrusion by analyzing network logs. Benefits of GPUsUnlike CPUs, which are optimized for general purpose computation, GPUs are optimized for parallel processing. GPUs implement an SIMD (single instruction, multiple data) architecture, which makes them more efficient for algorithms that process large blocks of data in parallel. Applications that need to process media and apply machine learning typically benefit from the highly parallel nature of GPUs.Google Cloud customers can now use NVIDIA GPUs to accelerate data processing tasks as well as image processing and machine learning tasks such as predictions. To understand the potential benefits, NVIDIA ran tests to compare the performance of the Dataflow pipeline that uses a TensorRT optimized BERT (Bidirectional Encoder Representations from Transformers) ML model for natural language processing. The following table captures the results of the tests: using Dataflow GPU to accelerate the pipeline resulted in an order of magnitude reduction in CPU and memory usage for the pipeline.We recommend testing Dataflow GPU with your workloads since the extent of the benefit depends on the data and the type of computation that is performed.What customers are saying Cloud to Street, uses satellites and AI to track floods in near real-time anywhere on earth to insure risk and save lives. The company produces flood maps at scale for disaster analytics and response by using Dataflow pipelines to automate batch processing and downloading of satellite data at large scale. Cloud to Street uses Dataflow GPU to not only process satellite imagery but also apply resource intensive machine learning tasks in the Dataflow pipeline itself. “GPU-enabled Dataflow pipelines asynchronously apply machine learning algorithms to satellite imagery. As a result, we are able to easily produce maps at scale without wasting time manually scaling machines, maintaining our own clusters, distributing workloads, or monitoring processes,” said Veda Sunkara, Machine Learning Engineer, Cloud to Street.Getting started with Dataflow GPUWith Dataflow GPU, customers have the choice and flexibility to use any of the following high performance NVIDIA GPUs: NVIDIA® T4 Tensor Core, NVIDIA® Tesla® P4, NVIDIA® V100 Tensor Core, NVIDIA® Tesla® P100, NVIDIA® Tesla® K80.Using Dataflow GPU is straightforward. Users can specify the type and number of GPUs to attach to Dataflow workers using the worker_accelerator parameter. We have also made it easy to install GPU drivers by automating the installation process. You instruct Dataflow to automatically install required GPU drivers by specifying the install-nvidia-driver parameter. Apache Beam notebooks with GPUApache Beam notebooks enable users to iteratively develop pipelines, inspect your pipeline graph interactively using JupyterLab notebooks. We have added support for GPU to Apache Beam notebooks which enables you to easily develop a new Apache Beam job that leverages GPU and test it iteratively before deploying the job to Dataflow. Follow the instructions at Apache Beam notebooks documentation to start a new notebooks instance to walk through a built in sample pipeline that uses Dataflow GPU.Integrated monitoringFurthermore, we have integrated monitoring of GPU into Cloud Monitoring. As a result you can easily monitor the performance and usage of GPU resources in your pipeline and optimize accordingly.Looking ahead: Right Fitting for GPUWe are also announcing a new breakthrough capability called Right Fitting as part of Dataflow Prime Preview. Right Fitting allows you to specify the stages of the pipeline that need GPU resources. That allows the Dataflow service to provision GPUs only for the stages of the pipeline that need it, thereby reducing the cost of your pipelines substantially. You can learn more about the Right Fitting capability here. You can find more details about Dataflow GPU at Dataflow support for GPU. Dataflow GPU are priced on a usage basis. You can find pricing information at Dataflow Pricing.Related ArticleDataflow Prime: bring unparalleled efficiency and radical simplicity to big data processingCreate even better data pipelines with Dataflow Prime, coming to Preview in Q3 2021.Read Article
Quelle: Google Cloud Platform
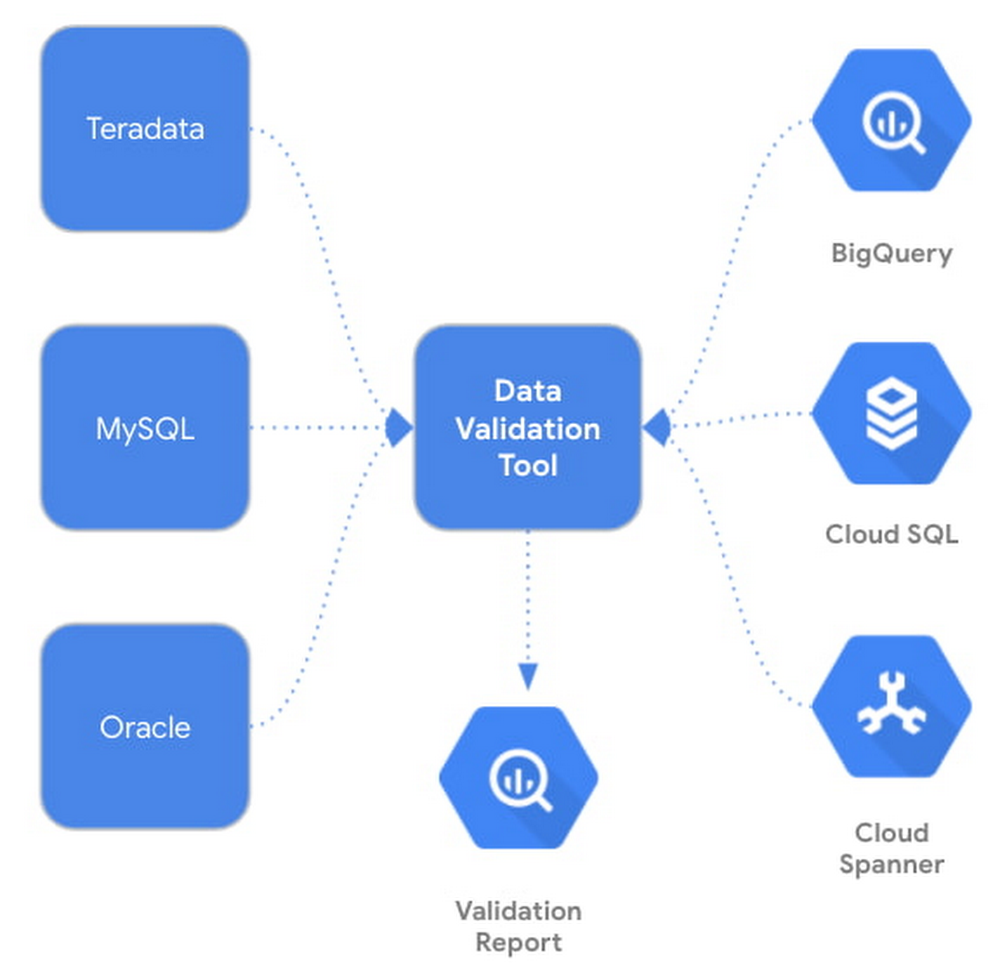
Data validation is a crucial step in data warehouse, database, or data lake migration projects. It involves comparing structured or semi-structured data from the source and target tables and verifying that they match after each migration step (e.g data and schema migration, SQL script translation, ETL migration, etc.) Today, we are excited to announce the Data Validation Tool (DVT), an open sourced Python CLI tool that provides an automated and repeatable solution for validation across different environments. The tool uses the Ibis framework to connect to a large number of data sources including BigQuery, Cloud Spanner, Cloud SQL, Teradata, and more.Why DVT?Cross platform data validation is a non-trivial and time-consuming effort, and many customers have to build and maintain a custom solution to perform such tasks. The DVT provides a standardized solution to validate customer’s newly migrated data in Google Cloud against the existing data from their on-prem systems. DVT can be integrated with existing enterprise infrastructure and ETL pipelines to provide a seamless and automated validation. SolutionThe DVT provides connectivity to BigQuery, Cloud SQL, and Spanner as well as third-party database products and file systems. In addition, it can be easily integrated into other Google Cloud services such as Cloud Composer, Cloud Functions and Cloud Run. DVT supports the following connection types:BigQueryCloud SQLFileSystem (GCS, S3, or local files)HiveImpalaMySQLOraclePostgresRedshiftSnowflakeSpannerSQL ServerTeradataThe DVT performs multi-leveled data validation functions, from the table level all the way to the row level. Below is a list of the validation features:Table levelTable row countGroup by row countColumn aggregationFilters and limitsColumn levelSchema/Column data type Row level Hash comparison (BigQuery only)Raw SQL explorationRun custom queries on different data sourcesHow to Use the DVTThe first step to validating your data is creating a connection. You can create a connection to any of the data sources listed previously. Here’s an example of connecting to BigQuery:Now you can run a validation. This is how a validation between a BigQuery and a MySQL table would look:The default validation if no aggregation is provided is a COUNT *. The tool will count the number of columns in the source table and verify it matches the count on the target table.The DVT supports a lot of customization while validating your data. For example, you can validate multiple tables, run validations on specific columns, and add labels to your validations.You can also save your validation to a YAML configuration file. This way you can store previous validations and modify your validation configuration. By providing the `config-file` flag, you can generate the YAML file. Note that the validation will not execute when this flag is provided – only the file is created.Here is an example of a YAML configuration file for a GroupedColumn validation:Once you have a YAML configuration file, it is very easy to run the validation.Validation reports can be output to stdout (default) or to a result handler. The tool currently supports BigQuery as the result handler. In order to output to BigQuery, simply add the `–bq-result-handler` or `-bqrh` flag.Below is an example of the validation results in BigQuery. View the complete schema for validation reports in BigQuery here.Getting StartedReady to start integrating the DVT into your data movement processes? Check out the tool on PyPi here and contribute to the tool via GitHub. We’re actively working on new features to make the tool as useful to our customers. Happy validating!Related ArticleHighway to the landing zone: Google Cloud migration made easyMigration to cloud is the first step to digital transformation because it offers a quick, simple path to cost savings and enhanced flexib…Read Article
Quelle: Google Cloud Platform
Spending wisely is a top priority for many companies—especially when it comes to their cloud compute infrastructure. Last year, we introduced Compute Engine’s E2 VM family, which delivers cost-optimized performance for a wide variety of workloads. Our E2 machines provide up to 31% lower Total Cost Ownership (TCO) compared to our N1 machines, consistent performance across CPU platforms, and instances with up to 32 vCPUs and 128 GB of memory. This is thanks to Google’s dynamic resource management technology, which is enabled by large and efficient physical servers, intelligent VM placement, performance-aware live migration, and a specialized hypervisor CPU scheduler.This combination of performance and cost-efficiency is driving significant growth in E2 adoption amongst our customers. They are increasingly choosing E2 as an essential building block for their various types of workloads, including web serving applications, small / medium databases, microservices and development environments, among others.For example, Google Cloud security partner ForgeRock runs several of its identity-based solutions on E2.”As a global IAM software company, we are tasked with addressing the world’s greatest security challenges with speed and agility, at scale. With that in mind, we are constantly exploring ways to optimize our cloud infrastructure spend while at the same time delivering on performance and reliability. By moving compute workloads to E2 VMs we were able to satisfy all of our criteria. Across the board, E2 VMs have delivered greater infrastructure efficiency for our digital identity platform and we are able to invest in a more delightful customer experience with additional features for our enterprise customers.” —Simon Harding, Senior Staff Site Reliability Engineer at ForgeRockHands-on experience with E2 VMsThroughout this past year, we strengthened our investment in dynamic resource management, and improved the at-scale scheduling algorithms that govern E2 VM performance. Our telemetry shows that E2 VMs deliver steady performance across a variety of workloads, even for those that are CPU-intensive. As a result, Alphabet services such as Android and ChromeOS infrastructure are now successfully running on E2 VMs. Google Kubernetes Engine (GKE) control-plane nodes also work seamlessly with E2 VMs.To provide an illustrative example, we measured a latency-sensitive web application running on a replicated set of e2-standard-4 VMs actively serving requests for a time period of sixteen days. The application serves about ~247 QPS (queries-per-second) of CPU-intensive work per replica. All replicas reply within ±10% latency variation, at the median.In this particular example, E2’s Dynamic Resource Management relied on two Compute Engine technologies to provide sustained consistent performance. The first, our VM placement technology, makes scheduling decisions that leverage resource observations from various workloads in order to predict performance across different target hosts. The second, our custom hypervisor CPU scheduler, minimizes the noisy-neighbour effects from adjacent VMs by providing sub-microsecond average wake-up latencies and fast context switching. During our sixteen-day observation window, the application underwent a maintenance event that triggered live migration in one of the replicas. Compute Engine relies on its battle-tested and performance-aware live migration technology to keep your VMs running during maintenance events, moving them seamlessly to another host in the same zone instead of requiring them to be rebooted.The following chart shows that the performance impact of live migration remained negligible while the replica was relocated to a different host. The VM’s overhead averaged between 0.02% to 0.1% of CPU time per second during the event.The timeseries above depicts vCPU availability % in a web application replica that underwent a maintenance event. vCPU throughput was 99.90% right before migration, and stabilized at 99.98% The total VM wait time at the time of the migration was about 160 milliseconds.The clients connected to the replica during the maintenance event did not observe any connectivity loss or degradation; in fact, they noticed a 1 millisecond improvement in latency.The timeseries above depicts query latency in milliseconds in a web application replica that underwent a maintenance event. This resulted in a live migration between two different hosts. The total VM wait time at the time of the migration was about ~160 milliseconds.Another E2 VM benefit enabled by dynamic resource management is its access to the largest pool of compute resources available in Compute Engine to any VM Family. By leveraging dynamic resource management, E2 VMs are scheduled seamlessly across x86 platforms from a combined pool of Intel and AMD based servers. In fact, our application’s replicas were scheduled in a mix of hosts powered by CPUs from both vendors and ran smoothly without experiencing any host errors, without the need to be rebuilt for a specific CPU vendor. As designed, per-vendor overall performance remained comparable, within 0.1% difference in total QPS served, 10% difference in median latency and CPU utilization stable at 55% for Intel-based hosts and 60% for the AMD equivalent. Putting it all together, Compute Engine’s design of E2 VMs centered around running on a large multi-vendor x86 platform pool and powered by Google Cloud’s dynamic resource management, provides a consistently performant environment for your applications. Get startedIf you’re looking for cost-efficiency, E2 VMs are a great choice. Since E2’s initial launch, we’ve added several new features and capabilities to E2 VMs:Support for 32 vCPU instances – To meet the processing power required by a diverse range of workloads, we now support sizes up to 32 vCPU with the addition of e2-standard-32 and e2-highcpu-32.Custom memory for E2 shared-core machine types – For small workloads, we’ve extended custom machine types to support e2-micro, e2-small, and e2-medium. These VMs range from 0.25 vCPU to 1.0 vCPU with the ability to burst up to 2 vCPU, and now support a customized amount of memory ranging from 1 to 8 GB.Stay tuned for updates to the Google Cloud Free Tier that will soon include one non-preemptible e2-micro instance for use each month for free. The e2-micro instance will provide you with two vCPUs, each for 12.5% of CPU uptime (0.25 vCPU), and 1 GB of memory.Enhancements to E2 are a part of a broader effort to meet your application needs with a diverse product portfolio that includes Tau VMs, our latest addition focused on industry leading price/performance. To learn more about E2 VMs and the complete portfolio of Compute Engine VM Families, visit the E2 and the VM Families documentation.Related ArticlePerformance-driven dynamic resource management in E2 VMsA technical look at dynamic resource management behind E2 VM machine typesRead Article
Quelle: Google Cloud Platform
Modern tech-savvy customers today are looking for digital-first, connected, and seamless business interactions. And businesses are looking not only to keep up with the fast-changing customer expectations but also maintain their profitability. They must find ways to balance both by leaning into sustainable innovation across every aspect of business. Innovation at speed is easier said than done, especially when you have legacy systems to manage, when you face a shortage of skilled resources, or when your business is operating in silos. This is where application programming interfaces, or APIs come into the picture, as application innovation is achievable at a significantly faster rate when it’s fueled by APIs. They are like the foundational building blocks that make it easy to deliver modern digital experiences, connect siloed units and systems, and help realize the true business value of your investments.How APIs can take on large-scale app innovationYou may know APIs as small lines of code, but they play a large role in powering app innovation in today’s digital age. Those small lines of code let developers access data and functionality in different systems, which turns those digital assets into modular building blocks that let your enterprise try new things and link together different parts of the buyer’s journey. APIs are inherently made to connect – and be connected – whether the link is between different parts of your business, from your business to a myriad of devices from tablets to computers to smart watches, third-party partners, marketplaces, data analysis tools, or from your business to developer communities. When designed and managed for reuse and developer consumption, APIs help businesses innovate at scale by combining digital assets to create engaging, unique, and personalized experiences for customers, for example: opting for contactless curbside pickup, collecting and redeeming loyalty points across channels, or getting product recommendations based on shopping behaviors . Plus, APIs come with an added bonus. Businesses can choose to package their valuable assets as APIs so that they can be monetized, and sold just like any product you’d find on a store shelf—which means if you have a particularly popular and valuable data or service, outsiders may be interested in purchasing access. To build and scale your API program, an API management platform, like Google Cloud’s Apigee, is key. APIs are the access points for many of your business’s most valuable systems, so access needs to be managed, usage needs to be understood, performance needs to be maintained, and security must be continually bolstered. Apigee manages your APIs all in one place, allowing you to design, iterate, deploy, secure, analyze, and scale your APIs from cradle to grave. The innovation we are describing isn’t an abstract concept, just like the notion of the technology “cloud” isn’t an imaginary untappable place in the sky that stores pictures of you from ten years ago. To help demystify, we’ve broken down API-powered application innovation into a three-phase journey:Deliver personalized experiences consistently at scaleAPIs enable companies – regardless of size – to build and deliver personalized experiences for customers. An API-first architecture simplifies how developers can build customizable experiences and thereby reduces time to market for new products and services. Imagine your team has built an API for your call center which recommends new products based on the customer’s profile. That API isn’t limited to that one, initial purpose but can also be embedded into other places and technologies such as your mobile device, app, and/or voice app. When built more efficiently and faster with APIs, these experiences can become more personalized, adaptable, and consistent.Build powerful digital business ecosystems By securely sharing your APIs with partners outside your business, you can unlock a range of ecosystem strategies that stretch and scale the value of your innovations. By making your APIs available to third parties, you can increase the number of innovators harnessing your digital assets, potentially exposing your business to new customers and use cases that wouldn’t have developed through internal innovation alone. Likewise, by combining your data and functionality with third-party APIs, your business and its partners can symbiotically produce more value together than either can by itself. For instance, partners can securely leverage your company’s proprietary data, accessible as an API, along with their expertise to create unique experiences for customers that you may not be able to reach on your own. APIs can be connected to, securely shared with, and even packaged and sold to developers, partners, and customers, allowing you to both deepen the integration with other companies and grow your revenue streams. As the owner of your APIs, you’re able to retain control of what is shared with whom, letting you maintain security while still leaving appropriate partners free to innovate with your data. Power your innovation with dataAs great digital experiences roll out to customers and APIs gain traction throughout your business ecosystems, you can use API management capabilities to measure and analyze API usage data, letting you optimize innovations and iterate on the cycle again and again. APIs make it simple and secure to share desired data insights with suppliers, customers, and partners to foster more innovation. In other words, APIs not only link data to data and data to people, but also provide you and your business with established data aggregation and analysis tools. Data-powered innovation enables you to make more informed data-driven decisions for your business and derive maximum value from your APIs and the connections they forge. What’s Stopping You? Start Here.To ensure every business is equipped with the knowledge and tools needed to innovate, Google Cloud is releasing a series that expands upon the three pillars of API-powered Application Innovation. If you’re ready to embark on a journey of innovation, watchthe first Application Innovation webinar in our series.Related ArticleRead Article
Quelle: Google Cloud Platform