Hochwasser in Deutschland: Keine Datenschutzbedenken bei Cell Broadcast
Gegen Warn-SMS per Cell Broadcast sind immer wieder Bedenken beim Datenschutz angeführt worden. Der Bundesbeauftragte widerspricht. (Politik/Recht, Mobilfunk)
Quelle: Golem

Gegen Warn-SMS per Cell Broadcast sind immer wieder Bedenken beim Datenschutz angeführt worden. Der Bundesbeauftragte widerspricht. (Politik/Recht, Mobilfunk)
Quelle: Golem

Quelle: <a href="Venmo Is Ending The Public Feed. It Still Needs One More Privacy Fix.“>BuzzFeed
On June 16, 2021, WordPress.com presented a live webinar focused on Managed Hosting with WordPress.com. The topic expert was Rudy Faile, Automattic Systems Engineer. Hosting the webinar was Sam Vaidya, Automattic Happiness Engineer. If you missed the live event, don’t worry. You can watch the recording at your convenience on Youtube or view it right here.
What Does the WordPress.com Managed Hosting Webinar Cover?
In this webinar, you’ll learn from WordPress.com Happiness Engineers and product experts how to build a fast, secure, and scalable website using WordPress – the publishing platform that now powers over 41% of the web.
Managed hosting is a convenient service offered by WordPress.com, which is 100% dedicated to hosting the open-source WordPress software. Managed hosting is an excellent option for people who don’t want to deal with running a website’s back-end technical operations. You get all of the freedom of WordPress, with none of the hassles.
Here’s what you get with WordPress.com managed hosting:
A faster website. Powerful, built-in SEO. Security and systems experts. Scalability and uptime you can depend on. Automatic WordPress Updates. Real-time backups.
Watched the Webinar but Still Have Questions?
Attendees at the live event asked great questions throughout the presentation. We’ve created an FAQ that answers many of them, along with other questions you might have. If you want to know more about WordPress.com’s managed hosting, the FAQ is a great place to start.
Quelle: RedHat Stack

A few weeks ago, we launched a new dataset into Google Cloud’s public dataset program: Google Trends. If you’re not familiar with our datasets program, we host a variety of datasets in BigQuery and Cloud Storage for you to access and integrate into your analytics. Google pays for the storage of these datasets and provides public access to the data, e.g., via the bigquery-public-data project. You only pay for queries against the data. Plus, the first 1 TB per month is free! Even better, all of these public datasets will soon be accessible and shareable via Analytics Hub. The Google Trends dataset represents the first time we’re adding Google-owned Search data into the program. The Trends data allows users to measure interest in a particular topic or search term across Google Search, from around the United States, down to the city-level. You can learn more about the dataset here, andcheck out the Looker dashboard here! These tables are super valuable in their own right, but when you blend them with other actionable data you can unlock whole new areas of opportunity for your team. You can view and run the queries we demonstrate here.Focusing on areas that matterEach day, the top 25 search terms are added to the top_terms table. Additionally, information about how that term has fluctuated over time for each region, Nielsen’s Designated Market Area® (DMA), is recorded with a score. A value of 100 is the peak popularity for the term. This regional information can offer further insight into trends for your organization.Let’s say I have a BigQuery table that contains information about each one of my physical retail locations. Like we mentioned in our previous blog post, depending on how that data is brought into BigQuery we might enhance the base table by using the Google Maps Geocoding API to convert text-based addresses into lat-lon coordinates.So now how do I join this data with the Google Trends data? This is where BigQuery GIS functions, plus the public boundaries dataset comes into play. Here I can use the DMA table to determine which DMA each store is in. From there I can simply join back onto the trends data using the DMA ID and focus on the top three terms for each store, which is based on terms with the highest score for that area within the past week.With this information, you can figure out what trends are most important to customers in the areas you care about, which can help you optimize marketing efforts, stock levels, and employee coverage. You may even want to compare across your stores to see how similar term interest is, which may offer new insight into localized product development. Filtering for relevant search termsSearch terms are constantly changing and it might not be practical for your team to dig into each and every one. Instead, you might want to focus your analysis on terms that are relevant to you. Let’s imagine that you have a table that contains all your product names. These names can be long and may contain lots of words or phrases that aren’t necessary for this analysis. For example:“10oz Authentic Ham and Sausages from Spain”Like most text problems, you should probably start with some preprocessing. Here, we’re using a simple user-defined functionthat converts the string to lowercase, tokenizes it, and removes words with numbers, and stop words or adjectives that we’ve hard-coded.For a more robust solution, you might want to leverage a natural language processing package, for example NLTK in Python. You can even process words to use only the stem or find some synonyms to include in your search. Next, you can join the products table onto the trends data, selecting search terms that contain one of the words from the product name.It looks like `Spain vs Croatia` was recently trending because of the Euro Cup. This might be a great opportunity to create a new campaign and capitalize on momentum: “Spain beat Croatia and is on to the next round, show your support by celebrating with some authentic Spanish ham!” Now going a bit further, if we take a look at the top rising search terms from yesterday (as of writing this on 6/30), we can see that there are a lot of names for people. But it’s unclear who these people are or why they’re trending. What we do know is we’re looking for a singer to strike up a brand deal with. More specifically, we have a great new jingle for our authentic ham and we’re looking for some trendy singers to bring attention to our company.Using the Wikipedia Open API you can perform an open search for the term, for example “Jamie Lynn Spears”:https://en.wikipedia.org/w/api.php?action=opensearch&search=jamie+lynn+spears&limit=1&namespace=0&format=json This gives you a JSON response that contains the name of first wikipedia page returned in the search, which you can then use to perform a query against the API:https://en.wikipedia.org/w/api.php?action=query&prop=extracts&exintro&titles=Jamie_Lynn_Spears&format=jsonFrom here you can grab the first sentence on the page (hint: this usually tells us if the person in question is a singer or not): “Jamie Lynn Marie Spears (born April 4, 1991) is an American actress and singer.”Putting this together, we might create a Google Cloud functionthat selects new BigQuery search terms from the table, calls the wikipedia API for each of them, grabs that first sentence and searches for the word “singer.” If we have a hit, then we simply add the search term to the table.Check out some sample code here! Not only does this help us keep track of who the most trendy singers are, but we can use the historical scores to see how their influence has changed over time. Staying notifiedThese queries, plus many more, can be used to make various business decisions. Aside from looking at product names, you might want to keep tabs on competitor names so that you can begin a competitive analysis against rising challengers in your industry. Or maybe you’re interested in a brand deal with a sports player instead of a singer, so you want to make sure you’re aware of any rising stars in the athletic world. Either way you probably want to be notified when new trends might influence your decision making. With another Google Cloud Function, you can programmatically run any interesting SQL queries and return the results in an email. With Cloud Scheduler, you can make sure the function runs each morning, so you stay alert as new trends data is added to the public dataset. Check out the details on how to implement this solution here. Ready to get started?You can explore the new Google Trends dataset in your own project, or if you’re new to BigQuery spin up a project using the BigQuery sandbox. The trends data, along with all the other Google Cloud Public Datasets, will be available in Analytics Hub – so make sure to sign up for the preview, which is scheduled to be available in the third quarter of 2021, by going to g.co/cloud/analytics-hub.Related ArticleMost popular public datasets to enrich your BigQuery analysesCheck out free public datasets from Google Cloud, available to help you get started easily with big data analytics in BigQuery and Cloud …Read Article
Quelle: Google Cloud Platform

Migrating your company’s applications to the cloud has many benefits, including improved customer satisfaction, reduction of technical debt, and the ability to lay the foundations of operational excellence. But there are also many challenges. Organizations often stop short because they don’t know how to get started, lacking prescriptive guidance and partnership from their cloud provider. In our new white paper, we hope to provide simple, direct guidance to help with the most important part of your digital transformation: the beginning. Application migration can be challenging because there isn’t a one-size-fits-all solution – every digital transformation has its own nuances and unique considerations. Before starting out on this journey, you need to understand the advantages and disadvantages of the options available to you, so you can create a migration plan that makes the most sense for your business. That’s why we’ve outlined the benefits of different migration paths to help you decide what’s right for your organization, the options of which you can see in the diagram below: Cloud migration options diagramAt Google Cloud, we’re here to help make sure your migration goes successful from start to finish (and beyond)! To learn more, download this white paper. Or, if you’re really ready to jump start your migration today, you can take advantage of our current offer by signing up for a free discovery and assessment or exploring our Rapid Assessment and Migration Program (also known as RAMP).
Quelle: Google Cloud Platform
Editors note: In early 2020, Chess.com was experiencing steady growth and had projected that it would hit around 4 million daily active users in 10 years. Then the pandemic hit, and alongside the release of the Netflix smash hit, The Queen’s Gambit, they reached this active user number in six months. In this post, Saad Abdali, Director of Technology at Chess.com, explains how handling this surge would have been impossible without the help of their migration to Google Cloud. Happy International Chess Day! Chess is often seen as a game that’s elitist and stodgy —something your grandfather played back in the day. In fact, nothing could be further from the truth. Thanks to the internet and sites like ours, chess has never been more vibrant than it is today.Each day, millions of people visit Chess.com to learn the game, solve puzzles, play against similarly skilled opponents, watch live tournaments, and connect with other chess aficionados. During the pandemic, interest in the sport grew faster than at any time in history. By adopting Google Cloud, we have been able to achieve things that were difficult or impossible when relying solely on our on-premise hardware. The greatest benefit Google Cloud provides is the ability to scale instantly as demand increases. And in 2020, the demand for online chess surged in a way we had never seen before.Controlling the boardWe first began noticing unpredictable spikes in traffic when our weekly Titled Tuesday event began surging in popularity in 2019. Titled Tuesday is a contest where the best players in the world (those who have the title of Master or better) compete in high-stakes one-hour matches for prize money. We introduced the event in 2014, and by 2018 the event was attracting nearly 400 of the chess world’s brightest stars each week, along with the legions of fans who wanted to watch them play.. Keeping our on-premise servers up and running during these increasingly high-stakes events was a growing challenge.Then the pandemic hit. Almost overnight, traffic to Chess.com tripled. Since our launch in 2007, we had been growing at a steady rate of about 20-50% every year. But in March 2020 alone, our number of daily active users rose from 280,000 to more than 1 million. Fortunately for us, we’d begun migrating significant functionality to Google Cloud in mid-2019. Before then, we’d run entirely on hardware we owned and deployed to physical data centers. So when our traffic surged, we were able to click a few buttons and spin up all the virtual servers we needed. A new gambit Traffic remained at that high level throughout the summer and early fall. And then, after The Queen’s Gambit debuted on Netflix last November, it doubled again. The fictional story of Beth Harmon’s rise to chess mastery inspired a new generation of players, especially young women. At the peak, we were serving up to 6 million users each day. The surge in popularity inspired us to create chess-playing bots that use a Monte Carlo tree search system to mimic Harmon’s style of play, as well as the styles of living grandmasters like Hikaru Nakamura and Maxime Vachier-Lagrave.Our ability to quickly expand capacity with Google Cloud is what allowed Chess.com to meet all of that rapidly increasing demand. It also enabled us to roll out new game types, like Puzzle Battle, where players compete against similarly skilled opponents to solve a series of increasingly complex chess problems. Puzzle Battle was the first major feature that we designed from the ground up to run in Google Cloud. Not only did this avoid adding load to our on-premise hardware, but we found that it significantly accelerated the development process. We’re currently migrating all gameplay from Chess.com, as well as its companion site, ChessKid.com, to a new distributed gameplay system hosted entirely on Google Cloud. In addition to helping us scale, the new cloud architecture provides a number of other benefits, including the ability to deploy a truly global service. One of the most popular game types on Chess.com is Bullet Chess, in which each player gets just one minute on the clock; these extremely fast games are quite time-sensitive. Google Cloud is enabling us to deploy gameplay nodes across the world, so that each player can enjoy a low-latency connection to a nearby Chess.com node.Check and mate After The Queen’s Gambit, our site traffic stabilized to around 4 million daily active users. Still, the site experienced 10 years’ worth of projected growth in just six months. There is no way Chess.com could have handled that surge without the move to Google Cloud. With Google Cloud’s nearly infinite ability to scale in response to demand, we don’t have to forecast what our site traffic is going to be at any point in time. We no longer worry about whether the site is resilient enough to withstand unexpected surges, or end up wasting money by over-provisioning servers that go unused. It also gives us the freedom to experiment with new projects at minimal risk. We can try out new features for the site. If they fail, we can spin down the virtual machines and stop paying for them. If they are a wild success, we can simply add more machines to spread the load. Our greater mission is to share our love of chess with the world, and to enable existing players to expand their horizons. It’s one of the reasons why we’ve created sites like ChessKid.com, and recently together with The International Chess Federation (FIDE), announced the first-ever Women’s World Cup.Chess began as a game, turned into a community, and is becoming a movement. We’re proud of the role Chess.com has played in that evolution, and grateful for the help Google Cloud has provided in allowing us to make it a reality.Related ArticleBringing Pokémon GO to life on Google CloudThroughout my career as an engineer, I’ve had a hand in numerous product launches that grew to millions of users. User adoption typically…Read Article
Quelle: Google Cloud Platform
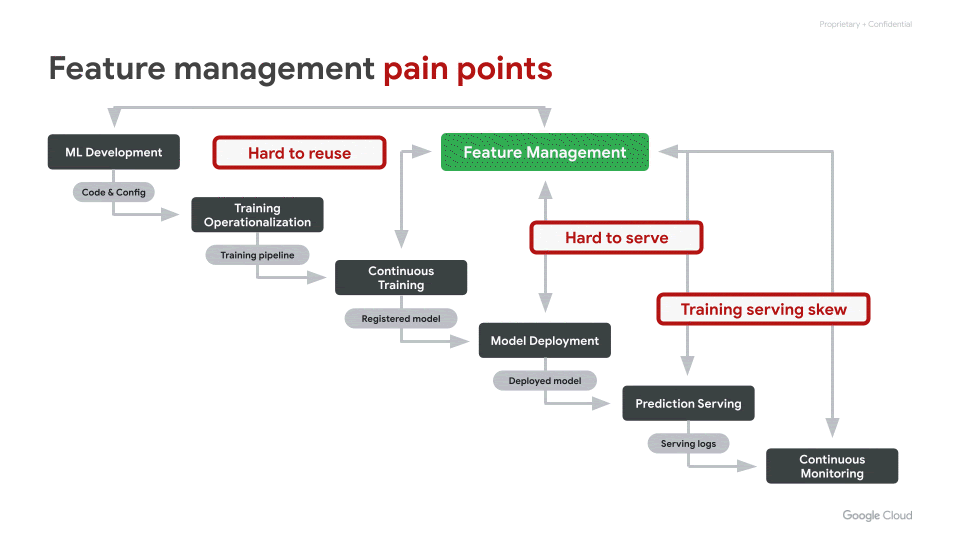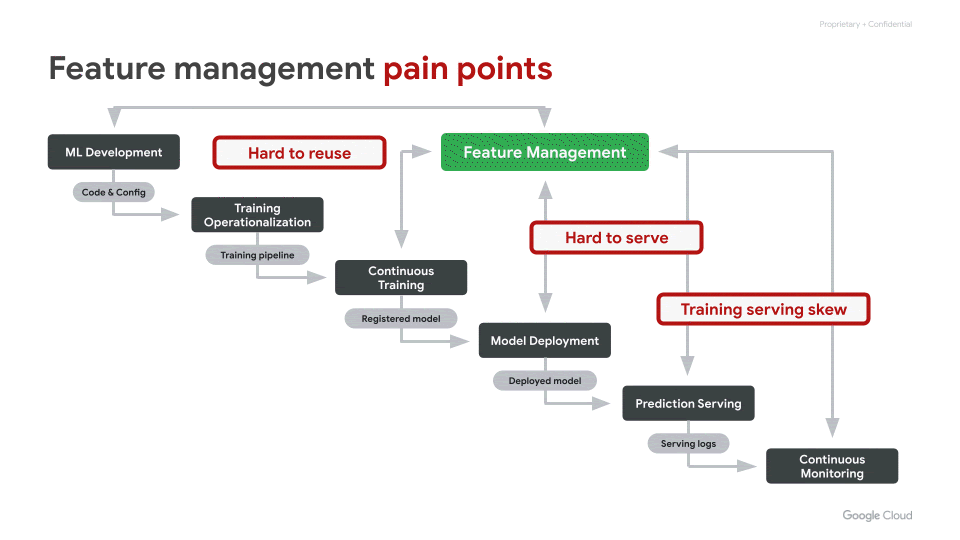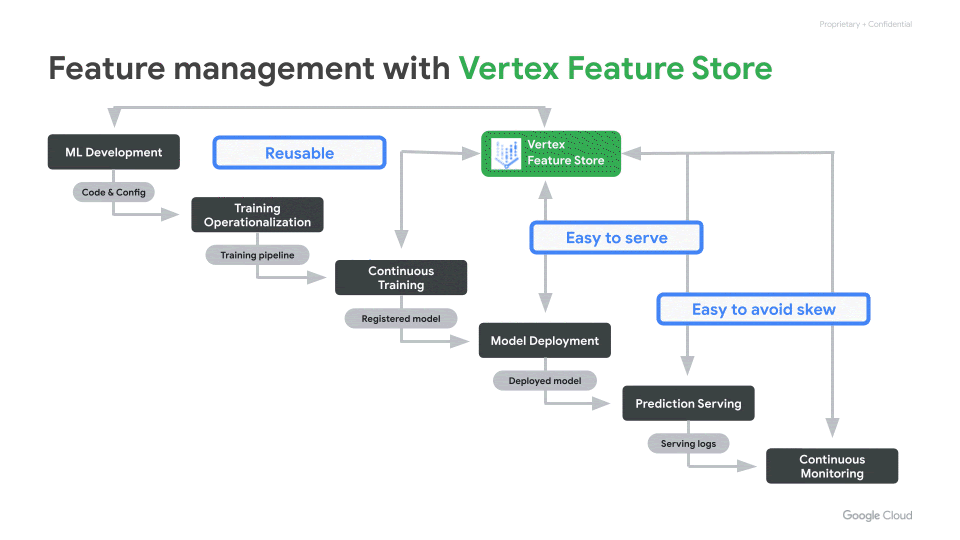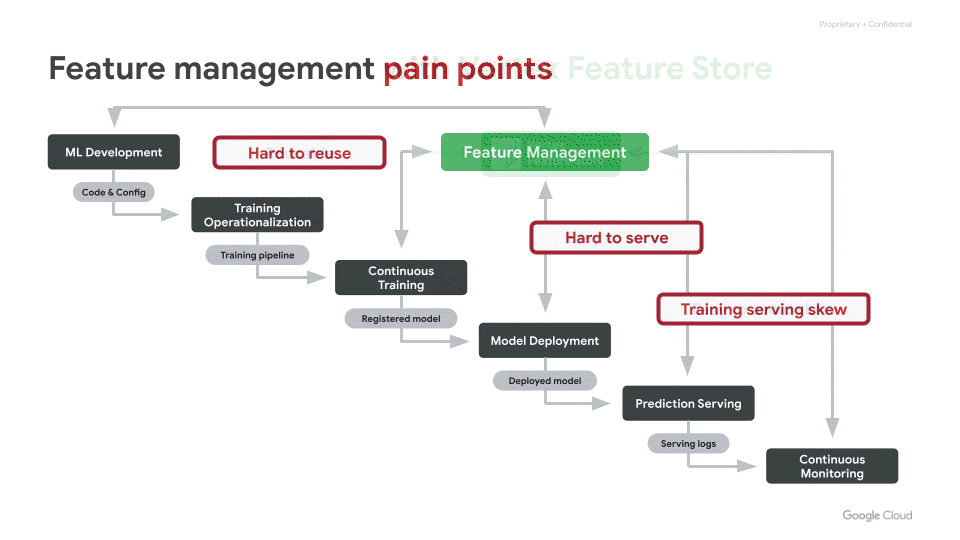
We often hear from our customers that over 70% of the time spent by Data Scientists goes into wrangling data. More specifically, the time is spent in feature engineering — the transformation of raw data into high quality input signals for machine learning (ML) models — and in reliably deploying these ML features in production. However, today, this process is often inefficient and brittle.There are three key challenges with regards to ML features that come up often: Hard to share and reuseHard to serve in production, reliably with low latencyInadvertent skew in feature values between training and serving In this blog post, we explain how the recently launched Vertex Feature Store helps address the above challenges. It helps enterprises reduce the time to build and deploy AI/ML applications by making it easy to manage and organize ML features. It is a fully managed and unified solution to share, discover, and serve ML features at scale, across different teams within an organization.Vertex Feature Store solves the feature management problemsSimple and easy to useAs illustrated in the overview diagram below, Vertex Feature Store uses a combination of storage systems and components under the hood. However, our goal is to abstract away the underlying complexity and deliver a managed solution that exposes a few simple APIs and corresponding SDKs. High level animated illustration of the Feature StoreThe key APIs are:Batch Import API to ingest computed feature values. We will soon be launching a Streaming Import API as well. When a user ingests feature values via an ingestion API, the data is reliably written both to an offline store and to an online store. The offline store will retain feature values for a long duration of time, so that they can later be retrieved for training. The online store will contain the latest feature values for online predictions.Online Serving API to serve the latest feature values from the online store, with low latency. This API will be used by client applications to fetch feature values to perform online predictions.Batch Serving API to fetch data from the offline store, for training a model or for performing batch predictions. To fetch the appropriate feature values for training, the Batch Serving API performs “point-in-time lookups”, which are described in more detail below.Now lets do a deeper dive into how the Feature Store addresses the three challenges mentioned above.Making it easy to discover, share, and re-use featuresReducing redundancy: Within a broader organization, it is common for different machine learning use cases to have some identical features as inputs to their models. In the absence of a feature store, each team invariably does the work of authoring and maintaining their own feature engineering pipelines, even for the identical features. This is redundant work, reducing productivity, that can be avoided.Maximizing the impact of feature engineering efforts: Coming up with sophisticated high quality features entails non-trivial creativity and effort. A high quality feature can often add value across many diverse use cases. However, when the feature goes underutilized, it is a lost opportunity for the organization. Hence, it is important to make it easy for different teams to share and re-use their ML features.Vertex Feature Store can serve as a shared feature repository for the entire organization. It provides an intuitive UI and APIs to search and discover existing features. Access to the features can also be controlled by setting appropriate permissions over groups of features.Discovery without trust is not very useful. Hence, Vertex Feature Store provides metrics that convey information about the quality of the features, such as: What is the distribution of the feature values? How often are a particular feature’s values updated? How widely is the feature consumed by other teams?Feature monitoring on the Feature Store consoleMaking it easy to serve ML features in productionMany compelling machine learning use cases deploy their models for online serving, so that predictions can be served in real-time with low latency. The Vertex Prediction service makes it easy to deploy a model as an HTTP or RPC endpoint, at scale, with high availability and reliability. However, in addition to deploying the model, the features required by the model as inputs need to be served online. Today, in most organizations there is a disconnect: it is the Data Scientist that creates new ML features, but the serving of ML features is handled by Ops or Engineering teams. This makes Data Scientists dependent on other teams to deploy their features in production. This dependence causes an undesirable bottleneck. Data Scientists would prefer to be in control of the full ML feature lifecycle. They want the freedom and agility to create and deploy new features quickly. Vertex Feature Store gives Data Scientists autonomy by providing a fully-managed and easy to use solution for scalable, low-latency online feature serving. Simply use the Ingestion APIs to ingest new feature values to a feature store. Once ingested, they are ready for online serving. Mitigating training-serving skewIn real world machine learning applications, one can run into a situation where a model performs very well on offline test data, but fails to perform as expected when deployed in production. This is often called Training-Serving Skew. While there can be many nuanced causes of model training-serving skew, often it boils down to skew between the features provided to the model during training and the features provided while making predictions.At Google, there is a rule of thumb to avoid training-serving skew: you train like you serve.A rule for mitigating training-serving skew(from Rules of Machine Learning)Discrepancies between the features provided to the model during training and serving are predominantly caused by the following three issues:A. Different code paths for generating features for training and serving. If there are different code paths, inadvertently some deviations can creep inB. A change in the raw data between when the model was trained and when it is subsequently used in production. This is called data drift and often impacts long-running models.C. A feedback loop between your model and your algorithm, also called data leakage or target leakage. Please read the following two links for a good description of this phenomenon: a. https://www.kaggle.com/dansbecker/data-leakage b. https://cloud.google.com/automl-tables/docs/beginners-guide#prevent_data_leakage_and_training-serving_skewLet’s see how Vertex Feature Store addresses the aforementioned three causes of feature skew:The feature store addresses (A) by ensuring that a feature value is ingested once into Vertex Feature Store, and then re-used for both training and serving. Since the feature value is only computed once, it avoids discrepancy due to duplicate code paths. (B) is addressed by constantly monitoring the distributions of feature values ingested into the feature store, so that users can identify when the feature values start to drift and change over time.(C) is addressed by what we call “point-in-time lookups” of features for training. This is described in more detail below. Essentially, this addresses data-leakage by ensuring that feature values provided for training were computed prior to the timestamp of the corresponding labeled training instance. The labelled instances used for training a model correspond to events that occurred at a specific time. As described by the data leakage links above, information generated after the label event should not be incorporated into the corresponding features. After all, that would effectively constitute “peeking” into the future:Point-in-time lookups to fetch training dataFor model training, you need a training data set that contains examples of your prediction task. These examples consist of instances that include their features and labels. For example, an instance might be a home and you want to determine its market value. Its features might include its location, age, and the prices of nearby homes that were sold. A label is an answer for the prediction task, such as the home eventually sold for $100K.Because each label is an observation at a specific point in time, you need to fetch feature values that correspond to that point in time when the observation was made, like what were the prices of nearby homes when a particular home was sold. As labels and feature values are collected over time, those feature values change. Hence, when you fetch data from a feature store for model training, it performs point-in-time lookups to fetch the feature values corresponding to the time of each label. What is noteworthy is that the Feature Store performs these point-in-time lookups efficiently, even when the training dataset has tens of millions of labels.In the following example, we want to retrieve feature values for two training instances with labels L1 and L2. The two labels are observed at time T1 and T2, respectively. Imagine freezing the state of the feature values at those timestamps. Hence, for the point-in-time lookup at T1, Vertex Feature Store returns the latest feature values up to time T1 for Feature 1, Feature 2, and Feature 3 and does not leak any values past T1. As time progresses, the feature values change and, consequently, so does the label. So, at T2, Vertex Feature Store returns different feature values for that point in time.Point-in-time Lookup for preventing the data leakA virtuous flywheel for faster AI/ML application developmentA rich feature repository can kick start a virtuous flywheel effect that can significantly reduce the time and cost of building and deploying ML applications. With Vertex Feature Store, Data Scientists don’t need to start from scratch, rather they can build each ML application faster by discovering and reusing features created for prior applications. Moreover, Vertex Feature Store ensures maximum return on investment for each newly crafted feature, ensuring that it benefits the entire organization and further speeds up subsequent applications, leading to a virtuous flywheel effect.Kick start your AI/ML flywheel by following the tutorials and getting started samples in the product documentation.Related ArticleGoogle Cloud unveils Vertex AI, one platform, every ML tool you needGoogle Cloud launches Vertex AI, a managed platform for experimentation, versioning and deploying ML models into production.Read Article
Quelle: Google Cloud Platform

Scoped tokens are here !
Scopes give you more fine grained control over what access your tokens have to your content and other public content on Docker Hub!
It’s been a while since we first introduced tokens into Docker Hub (back in 2019!) and we are now excited to say that we have added the ability for accounts on a Pro or Team plan to apply scopes to their Personal Access Tokens (PATs) as a way to authenticate with Docker Hub.
Access tokens can be used as a substitute for your password in Docker Hub, adding scopes to these tokens gives you more fine grained control over what access the machine logged in has. This is great for setting up things like service accounts in CI systems, registry mirrors or even on your local machine to make sure you are not giving too much access away.
PATs are an alternative to using passwords for authentication to Docker Hub (link to https://hub.docker.com/ ) when using Docker command line
docker login –username <username>
When prompted for your password you can simply provide a token. The other advantages of tokens are that you can create and manage multiple tokens at once, being able to see when they were last used and if things look wrong – revoke the tokens access. This and our API support make it easy to manage the rotation of your tokens to help improve the security of your supply chain.
Create and Manage Personal Access Tokens in Docker Hub
Personal access tokens are created and managed in your Account Settings.
Then head to security:
From here, you can:
Create new access tokensModify existing tokensDelete access tokens
The other way you can manage your tokens is through the Hub APIs. We have Swagger docs for our APIs and the new docs for scoped tokens can be found here:
http://docs.docker.com/docker-hub/api/latest/#tag/access-tokens
Scopes available
When you are creating a token Pro and Team plan members will now have access to 4 scopes:Read, write, delete: The scope of this token allows you to read, write and delete all of the repos that you have access to. (It does not allow you to modify account settings as a password authentication would)
Read, write: This scope is for read/write within repos you have access to (all the public content on Hub & your private content). This is the sort of scope to use within a CI that is also pushing to a repo
Read only: This scope is read only for all repos you have have access to, this is great when used in production where it only needs to pull content from your repos to run it/
Public repo read only: This scope is for reading only public content, so nothing from your or your team’s repos. This is great when you want to set up a system which is just pulling say Docker Official Images or Verified content from Docker Hub.
These scopes are for Pro accounts (which get 5 tokens) and Team accounts (which give each team member unlimited tokens). Free users can continue to use their single read, write, delete token and revoke/reissue this as they need.
Scoped access tokens levels up the security of Docker users supply chain with how you can authenticate into Docker Hub. Available for Pro and Team plans, we are excited for you to try the scope tokens out and start giving us some feedback.
Want to learn more about Docker Scoped Tokens? Make sure to follow us on Twitter: @Docker. We’ll be hosting a live Twitter Spaces event on Thursday, Jul 22, 2021 from 8:30 – 9:00 am PST, where you’ll hear from Docker engineers, product managers and a Docker Captain!
If you have feedback or other ideas, remember to add them to our public roadmap. We are always interested in what you would like us to build next!
The post Level Up Security with Scoped Access Tokens appeared first on Docker Blog.
Quelle: https://blog.docker.com/feed/

Die Kundenfrequenz nach der Öffnung liege weiter unter dem Niveau vor der Pandemie, beklagt der Mutterkonzern von Media Markt und Saturn. (Media Markt, Wirtschaft)
Quelle: Golem

Die Executive Fingerprint Secure verwendet Fingerabdrücke statt Passwörter, um Daten abzusichern. Es gibt sie als HDD oder SSD mit USB-C. (Festplatte, Speichermedien)
Quelle: Golem