Datenschutz: Lehrerverband will weiter Teams erlauben
Erst von Schülern, nun von Lehrern: Trotz Datenschutzbedenken gibt es neue Forderungen, kommerzielle Software an Schulen zu erlauben. (Schulen, Datenschutz)
Quelle: Golem

Erst von Schülern, nun von Lehrern: Trotz Datenschutzbedenken gibt es neue Forderungen, kommerzielle Software an Schulen zu erlauben. (Schulen, Datenschutz)
Quelle: Golem
AWS Application Migration Service (AWS MGN) ist jetzt in vier weiteren AWS-Regionen verfügbar: USA West (Nordkalifornien), Asien-Pazifik (Osaka), Kanada (Zentral) und Südamerika (São Paulo).
Quelle: aws.amazon.com
Workflow Studio ist ein neuer visueller Workflow-Designer für AWS Step Functions, der die Erstellung von Workflows über eine Drag-and-Drop-Oberfläche in der AWS-Konsole schneller und einfacher macht.
Quelle: aws.amazon.com

Nintendos Switch bekommt ein neues Display und Amazon Prime bekommt mehr Werbung. Die Woche im Video. (Golem-Wochenrückblick, Amazon)
Quelle: Golem
At Red Hat, we take customer feedback seriously. In our Customer Portal, you will find a page dedicated to showing the actions we’ve implemented based on feedback we’ve received called “You Asked. We Acted.” See some examples of your feedback in action in this post.
Quelle: CloudForms
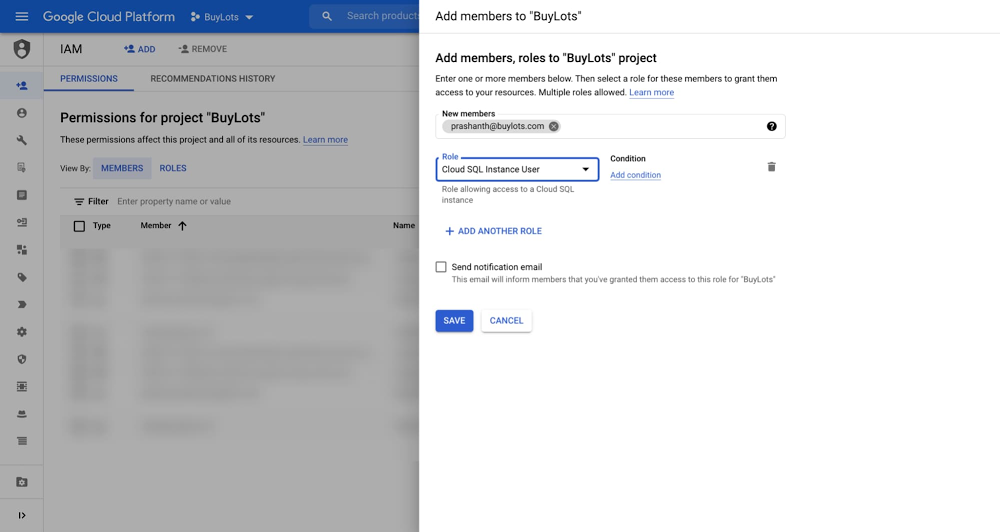
When enterprise IT administrators design their data systems, security is among the most important considerations they have to make. Security is key to defining where data is stored and how users access it. Traditionally, IT administrators have managed user access to systems like SQL databases through issuing users a separate, dedicated username and password. Although it’s simple to set up, distributed access control requires administrators to spend a lot of time securing each system, instituting password complexity and rotation policies. For some enterprises, such as those bound by SOX or PCI-DSS rules, these measures may be required in each system for regulatory compliance. To minimize management effort and the risk of an oversight, IT administrators often prefer centralized access control, in which they can use a single hub to grant or revoke access to any system, including SQL databases.To achieve that centralized access control, we’ve released IAM database authentication for Cloud SQL for MySQL into general availability. With IAM database authentication, administrators can use Cloud Identity and Access Management (IAM), Google Cloud’s centralized access management system, to govern not only administrative access, but also connection access for their MySQL databases. With Cloud IAM, administrators can reduce the administrative effort associated with managing passwords for each Cloud SQL database. Furthermore, with Cloud Identity’s robust password security system, administrators can establish a strong, unified security posture and maintain compliance across all Google Cloud systems, including Cloud SQL. With IAM database authentication, end-users can log in to the Cloud SQL database with their Cloud Identity credentials. First, users log in to Google Cloud. When ready to access the database, the user uses gcloud or the Google Cloud API to request an access token and then presents their Google username along with the token to the database instance in order to log in. Before the user can log in to the database, Cloud IAM checks to make sure that the user has permission to connect. Compared with the database’s built-in authentication method, IAM database authentication means users have one less password to manage. Both individual end users and applications can use IAM database authentication to connect to the database. How to Set Up IAM Database AuthenticationTo illustrate with an example, let’s say the IT administrator team at a retailer named BuyLots wants to let Prashanth from the data analyst team authenticate to a new US Reporting MySQL database instance running in Cloud SQL. Prashanth already has a Cloud Identity account.First, the administrator goes to Cloud IAM and grants Prashanth’s Cloud Identity account the Cloud SQL Instance User role. This ensures that Cloud IAM will respond affirmatively when Cloud SQL checks to see if Prashanth should be allowed to access the database during login.Click to enlargeNext, the administrator heads to Cloud SQL and edits the configuration of the US Reporting database instance, enabling IAM database authentication by turning on the “cloudsql_iam_authentication” flag.Click to enlargeAfter that, the administrator creates a new MySQL user account for Prashanth on the US Reporting database instance, selecting Cloud IAM for the authentication method. The administrator submits Prashanth’s full Cloud Identity username (“prashanth@buylots.com”). The administrator notes that because of MySQL character limits, Prashanth’s MySQL username is his Cloud Identity username without the domain (“prashanth”).Click to enlargeFinally, the administrator needs to open up MySQL and explicitly grant the appropriate privileges to Prashanth so that he can access the correct tables with the right level of permissions. While Cloud IAM handles authentication, Cloud SQL still uses MySQL’s privilege system to determine what actions the user is authorized to perform. New IAM database authentication MySQL users have no privileges when they are created. The administrator grants Prashanth read access to all tables in the sales database in the US Reporting database instance.The administrator has now successfully set up Prashanth to connect to the Cloud SQL for MySQL instance using IAM database authentication.How to Log in with IAM Database AuthenticationIt’s time for Prashanth to log in to the US Reporting database instance to pull some data for his monthly report. Prashanth uses the Cloud SDK from his laptop to access Google Cloud. For his MySQL queries, Prashanth uses the MySQL Command-Line Client, and he connects to BuyLots databases through the Cloud SQL Auth proxy. Prashanth uses the Cloud SQL Auth proxy because it makes connecting simpler. The proxy directs connection requests so that US Reporting looks local to Prashanth’s MySQL Command-Line Client. Furthermore, the Cloud SQL Auth proxy takes care of SSL encryption for him, so Prashanth doesn’t have to worry about self-managed SSL certificates.First, Prashanth uses the Cloud SDK to log in to Google Cloud and enters his Cloud Identity credentials through the web browser.Next, Prashanth fires up the Cloud SQL Auth proxy. Prashanth passes in the instance connection name and the port number for the MySQL connection request to use. Since Prashanth already logged in earlier to Google Cloud, the Cloud SQL Auth proxy can use Prashanth’s Cloud SDK credentials to authorize his connections to the instance.Lastly, Prashanth uses a command to connect to MySQL from his operating system’s command line interface. For the MySQL username, Prashanth passes in his Cloud Identity username, leaving off the BuyLots domain name. In place of a traditional MySQL password, Prashanth passes in a command invoking the Cloud SDK to return his Cloud Identity access token. Prashanth also has to specify the cleartext option in the connection request. Since he’s using the Cloud SQL Auth proxy, he can indicate that the host is local.Prashanth has now connected to his Cloud SQL for MySQL database using IAM database authentication! Learn MoreWith IAM database authentication, enterprise IT administrators can now further secure access to Cloud SQL databases and centrally manage access through Cloud IAM. To learn more about IAM database authentication for Cloud SQL for MySQL, see our documentation.Related ArticleImproving security and governance in PostgreSQL with Cloud SQLManaged cloud databases need security and governance, and Cloud SQL just added pgAudit and Cloud IAM integrations to make security easier.Read Article
Quelle: Google Cloud Platform
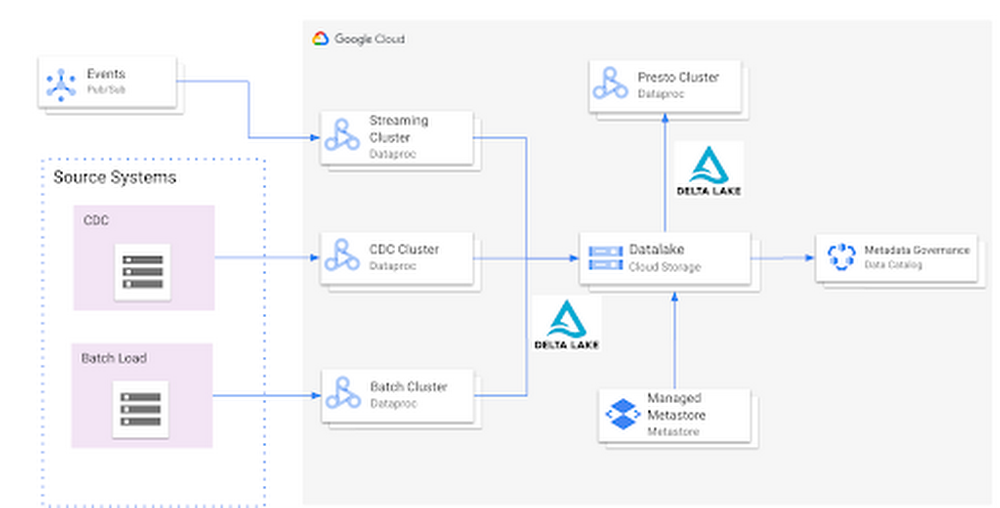
Organizations today build data lakes to process, manage and store large amounts of data that originate from different sources both on-premise and on cloud. As part of their data lake strategy, organizations want to leverage some of the leading OSS frameworks such as Apache Spark for data processing, Presto as a query engine and Open Formats for storing data such as Delta Lake for the flexibility to run anywhere and avoiding lock-ins.Traditionally, some of the major challenges with building and deploying such an architecture were:Object Storage was not well suited for handling mutating data and engineering teams spent a lot of time in building workarounds for thisGoogle Cloud provided the benefit of running Spark, Presto and other varieties of clusters with the Dataproc service, but one of the challenges with such deployments was the lack of a central Hive Metastore service which allowed for sharing of metadata across multiple clusters.Lack of integration and interoperability across different Open Source projectsTo solve for these problems, Google Cloud and the Open Source community now offers:Native Delta Lake support in Dataproc, a managed OSS Big Data stack for building a data lake with Google Cloud Storage, an object storage that can handle mutationsA managed Hive Metastore service called Dataproc Metastore which is natively integrated with Dataproc for common metadata management and discovery across different types of Dataproc clustersSpark 3.0 and Delta 0.7.0 now allows for registering Delta tables with the Hive Metastore which allows for a common metastore repository that can be accessed by different clusters.ArchitectureHere’s what a standard Open Cloud Datalake deployment on GCP might consist of:Apache Spark running on Dataproc with native Delta Lake SupportGoogle Cloud Storage as the central data lake repository which stores data in Delta formatDataproc Metastore service acting as the central catalog that can be integrated with different Dataproc clustersPresto running on Dataproc for interactive queriesSuch an integration provides several benefits:Managed Hive Metastore serviceIntegration with Data Catalog for data governanceMultiple ephemeral clusters with shared metadataOut of the box integration with open file formats and standardsReference implementationBelow is a step by step guide for a reference implementation of setting up the infrastructure and running a sample applicationSetupThe first thing we would need to do is set up 4 things:Google Cloud Storage bucket for storing our dataDataproc Metastore ServiceDelta Cluster to run a Spark Application that stores data in Delta formatPresto Cluster which will be leveraged for interactive queriesCreate a Google Cloud Storage bucketCreate a Google Cloud Storage bucket with the following command using a unique name.Create a Dataproc Metastore serviceCreate a Dataproc Metastore service with the name “demo-service” and with version 3.1.2. Choose a region such as us-central1. Set this and your project id as environment variables.Create a Dataproc cluster with Delta LakeCreate a Dataproc cluster which is connected to the Dataproc Metastore service created in the previous step and is in the same region. This cluster will be used to populate the data lake. The jars needed to use Delta Lake are available by default on Dataproc image version 1.5+Create a Dataproc cluster with Presto Create a Dataproc cluster in us-central1 region with the Presto Optional Component and connected to the Dataproc Metastore service.Spark ApplicationOnce the clusters are created we can log into the Spark Shell by SSHing into the master node of our Dataproc cluster “delta-cluster”.. Once logged into the master node the next step is to start the Spark Shell with the delta jar files which are already available in the Dataproc cluster. The below command needs to be executed to start the Spark Shell. Then, generate some data.# Write Initial Delta format to GCSWrite the data to GCS with the following command, replacing the project ID.# Ensure that data is read properly from SparkConfirm the data is written to GCS with the following command, replacing the project ID.Once the data has been written we need to generate the manifest files so that Presto can read the data once the table is created via the metastore service.# Generate manifest filesWith Spark 3.0 and Delta 0.7.0 we now have the ability to create a Delta table in Hive metastore. To create the table below command can be used. More details can be found here # Create Table in Hive metastoreOnce the table is created in Spark, log into the Presto cluster in a new window and verify the data. The steps to log into the Presto cluster and start the Presto shell can be found here.#Verify Data in PrestoOnce we verify that the data can be read via Presto the next step is to look at schema evolution. To test this feature out we create a new dataframe with an extra column called “z” as shown below:# Schema Evolution in SparkSwitch back to your Delta cluster’s Spark shell and enable the automatic schema evolution flagOnce this flag has been enabled create a new dataframe that has a new set of rows to be inserted along with a new column Once the dataframe has been created we leverage the Delta Merge function to UPDATE existing data and INSERT new data # Use Delta Merge Statement to handle automatic schema evolution and add new rowsAs a next step we would need to do two things for the data to reflect in Presto:Generate updated schema manifest files so that Presto is aware of the updated dataModify the table schema so that Presto is aware of the new column.When the data in a Delta table is updated you must regenerate the manifests using either of the following approaches:Update explicitly: After all the data updates, you can run the generate operation to update the manifests.Update automatically: You can configure a Delta table so that all write operations on the table automatically update the manifests. To enable this automatic mode, you can set the corresponding table property using the following SQL command.However, in this particular case we will use the explicit method to generate the manifest files againOnce the manifest file has been re-created the next step is to update the schema in Hive metastore for Presto to be aware of the new column. This can be done in multiple ways, one of the ways to do this is shown below:# Promote Schema Changes via Delta to PrestoOnce these changes are done we can now verify the new data and new column in Presto as shown below:# Verify changes in PrestoIn summary, this article demonstrated:Set up the Hive metastore service using Dataproc Metastore, spin up Spark with Delta lake and Presto clusters using DataprocIntegrate the Hive metastore service with the different Dataproc clustersBuild an end to end application that can run on an OSS Datalake platform powered by different GCP servicesNext stepsIf you are interested in building an Open Data Platform on GCP please look at the Dataproc Metastore service for which the details are available here and for details around the Dataproc service please refer to the documentation available here. In addition, refer to this blog which explains in detail the different open storage formats such as Delta & Iceberg that are natively supported within the Dataproc service.Related ArticleMigrating Apache Hadoop to Dataproc: A decision treeAre you using the Apache Hadoop and Spark ecosystem? Are you looking to simplify the management of resources while continuing to use the …Read Article
Quelle: Google Cloud Platform
Docker’s Peter McKee hosts serverless wizard and open sorcerer Yaron Schneider for a high-octane tour of DAPR (as in Distributed Application Runtime) and how it leverages Docker. A principal software engineer at Microsoft in Redmond, Washington, Schneider co-founded the DAPR project to make developers’ lives easier when writing distributed applications.
DAPR, which Schneider defines as “essentially a sidecar with APIs,” helps developers build event-driven, resilient distributed applications on-premises, in the cloud, or on an edge device. Lightweight and adaptable, it tries to target any type of language or framework, and can help you tackle a host of challenges that come with building microservices while keeping your code platform agnostic.
How do I reliably handle a state in a distributed environment? How do I deal with network failures when I have a lot of distributed components in my ecosystem? How do I fetch secrets securely? How do I scope down my applications? Tag along as Schneider, who also co-founded KEDA (Kubernetes-based event-driven autoscaling), demos how to “dapr-ize” applications while he and McKee discuss their favorite languages and Schneider’s collection of rare Funco pops!
Watch the video (Duration 0:50:36):
The post Video: Docker Build: Simplify Cloud-native Development with Docker & DAPR appeared first on Docker Blog.
Quelle: https://blog.docker.com/feed/

In einer Videokonferenz-Software für Schulen hat Lilith Wittmann eine Sicherheitslücke entdeckt. Die IT-Sicherheitsexpertin glaubt nicht, dass es das letzte Problem war. (Schulen, Videotelefonie)
Quelle: Golem

Die deutsche Polizei meldet eine steigende Zahl alkoholisierter Menschen auf E-Scootern. Die sind sich in Kontrollen oft keiner Schuld bewusst. (E-Scooter, Internet)
Quelle: Golem