Google: Frustrierte Mitarbeiter verlassen Google-Pay-Team
Google hat zahlreiche Mitarbeiter des Google-Pay-Teams verloren. Ein Grund soll der langsame Fortschritt bei der Entwicklung sein. (Google Pay, Google)
Quelle: Golem

Google hat zahlreiche Mitarbeiter des Google-Pay-Teams verloren. Ein Grund soll der langsame Fortschritt bei der Entwicklung sein. (Google Pay, Google)
Quelle: Golem

Echtzeitabwehr gegen Betrug bei Transaktionen: Mit der Telum-CPU bringt IBM künstliche Intelligenz im Doppelpack-Aufbau in den Mainframe. (IBM, Prozessor)
Quelle: Golem
According to “The State of Enterprise Open Source” report Red Hat published earlier this year, open source will continue to play an important role in the future of telecommunications. Let’s see how it’s positioning telecommunications providers to keep up with their technology revolution.
Quelle: CloudForms

One of the beautiful advantages of multi-cloud is the flexibility to choose the best cloud infrastructure for each of your workloads. For latency-sensitive applications like trading, telecommunications, MMORPGs, and telemedicine, this means having infrastructure close to customers and internet exchanges so you can shave off precious milliseconds from packet round-trip time. Here at Mirantis, we … Continued
Quelle: Mirantis
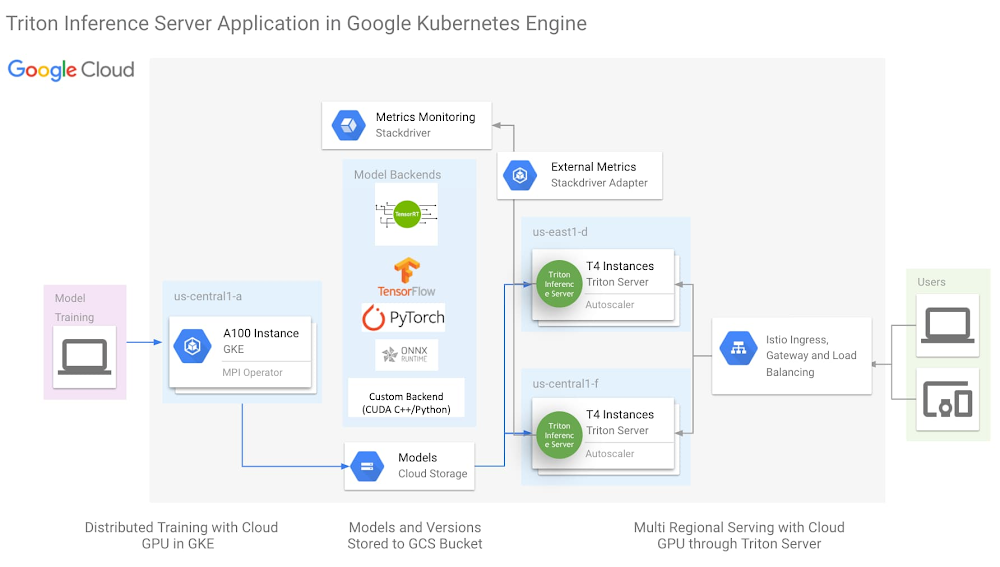
tl;dr: We introduce the One-Click Triton Inference Server in Google Kubernetes Engine (GKE) Marketplace solution (solution, readme) to help jumpstart NVIDIA GPU-enabled ML inference projects.Deep Learning research in the past decade has provided a number of exciting and useful models for a variety of different use cases. Less than 10 years ago, AlexNet was the state-of-the-art image classification model and brought the Imagenet moment marked as ground zero for deep learning explosion. Today, Bidirectional Encoder Representations from Transformers (BERT) and related family of models enable a variety of complex natural language use cases from Text Classification to Question and Answering (Q&A). While top researchers are creating bleeding edge models exceeding hundreds of millions of parameters, bringing these models to production in large-scale exposes additional challenges we have to solve.Scale Inference with NVIDIA Triton Inference Server on Google Kubernetes EngineWhile recent ML frameworks have made model training and experimentation more accessible, serving ML models, especially in a production environment, is still difficult. When building an inference environment, we commonly run into the following pain points:Complex dependencies and APIs of DL Frameworks backend Production workflow includes not just model inference but also preprocessing stepsHard to find nobs to maximize accelerator performanceToo much scripting and configurations about robust Ingress and load balancingIn this blog, we will introduce the One-Click Triton Inference Server in Google Kubernetes Engine (GKE), and how the solution scales these ML models, meet stringent latency budgets, and optimize operational costs.Click to enlargeThe architecture above is the One-Click NVIDIA Triton Inference Server solution (click here to try now), with the following key aspects:NVIDIA Triton Inference ServerIstio for simplified Ingress and Load BalancingHorizontal Pod Autoscaler(HPA) monitoring external metric through Stackdriver Triton Inference Server is an open source inference server from NVIDIA with backend support for most ML Frameworks, as well as custom backend for python and C++. This flexibility simplifies ML infrastructure by reducing the need to run different inference servers to serve different frameworks. While Triton was created to leverage all the advanced features of the GPU, it is also designed to be highly performant on the CPU. With this flexibility in ML framework and processing hardware support, Triton can reduce the complexity of model serving infrastructure.More detailed description of the One-Click Triton solution could be found here. NVIDIA Triton Inference Server for mission-critical ML model servingOrganizations today are looking to create a shared-service ML platform to help democratize ML across their business units. To be successful, a share-service ML serving platform must be reliable and cost effective. To address these requirements NVIDIA has created two capabilities that are unique to the Triton Inference Server:Model PriorityTensorRT Maximizing Utilization and ROI with Model PriorityWhen we build a shared-service inference platform, we will need to expect to support models for multiple use cases, each with different latency sensitivity, business criticality, and transient load fluctuations. At the same time, we also need to consider control costs through standardization and economy of scale. However, these requirements are often in conflict. For example, a business-critical, latency-sensitive model with a strict Service Level Objective (SLO) will present to us two choices: do we pre-provision compute resources in anticipation of transient load fluctuations and pay for the excess unused compute, or do we provision only the typical compute resources needed to save cost, and risk violating the latency SLO when transient loads spike?In the population of models we serve, we can usually find a subset that are both latency-sensitive and business critical. These can be treated as Tier-1 models, with the remaining as Tier-2.Click to enlargeWith Triton Inference Server, we have the ability to mark a model as PRIORITY_MAX. This means when we consolidate multiple models in the same Triton instance and there is a transient load spike, Triton will prioritize fulfilling requests from PRIORITY_MAX models (Tier-1) at the cost of other models (Tier-2).Below is an illustration of three common load spiking scenarios. In the first (1) scenario, load spikes but load is within the provisioned compute limit. Both models continue normally. In the second (2) scenario, the Tier-1 model spikes and the combined compute load exceeds the provisioned compute limit. Triton prioritizes the Tier-1 model by reducing compute on the Tier-2 model. In the third (3) scenario, the Tier-2 model spikes. Triton ensures the Tier-1 model will receive the compute resources it needs. In all three scenarios.Click to enlargeWhile GKE provides autoscaling, relying only on GKE to autoscale on transient load spikes can lead to SLO violation, as load spikes can appear in seconds, whereas GKE autoscales in minutes. Model priority provides a short window to buffer transient spikes to help maintain Tier-1 model SLO while GKE autoscales its nodepool. For a description of options to address transient load spikes, please refer to the reference guide Mitigating transient load effects on ML serving latency.Maximizing Performance and Cost Effectiveness with NVIDIA TensorRTWhile Triton offers a multitude of backend framework support and a highly pluggable architecture, the TensorRT backend offers the best performance benefits.NVIDIA TensorRT (TRT) is an SDK for high performance deep learning inference on NVIDIA GPU’s, leveraging out-of-box performance enhancements by applying optimization such as layer fusion, mixed precision and structured sparsity. With the latest NVIDIA A100 GPU as an example, TensorRT incorporates Tensor Cores, a region of the GPU optimized for FP16 and INT8 matrix math, with support for structured sparsity. For optimizations TensorRT applied to the BERT model, please visit the referenceblog.The following Triton configuration will help GPU inference performance and utilization when used with TensorRT:Concurrent execution: a separate copy of the model is run in its own separate CUDA stream, allowing for concurrent CUDA kernel executions simultaneously. This allows for increased parallelization.Dynamic batching: Triton will dynamically group together multiple inference requests on the server-side within the constraint of specified latency requirements.TensorRT Impact on BERT Inference Performance We deploy CPU BERT BASE and Distill BERT on n1-standard-96, and GPU BERT BASE, Distill BERT and BERT BASE with TRT optimization on n1-standard-4 with 1 T4 GPU, with sequence length of the BERT model being 384 token. We measure the latency and throughput with a concurrency sweep with Triton’s performance analyzer. The latency includes Istio ingress/load balancing and reflects the true end to end cost in the same GCP zone.Click to enlargeWith n1-standard-96 priced at $4.56/hr and n1-standard-4 at $0.19/hr and T4 at $0.35/hr totaling $0.54/hr. While achieving a much lower latency, the TCO of BERT inference with TensorRT on T4 is over 163 times that of Distill BERT inference on n1-standard-96.ConclusionNVIDIA Triton Inference Server, running on GKE with GPU and TensorRT, provides a cost-effective and high-performance foundation to build an enterprise-scale, shared-service ML inference platform. We also introduced the One-Click Triton Inference Server solution to help jumpstart ML inference projects. Finally, we provided a few recommendations that will help you get a GPU-enabled inference project off the ground:Use TensorRT to optimize Deep Learning model inference performance.Leverage concurrent serving and dynamic batching features in Triton.To take full advantage of the newer GPUs, use FP16 or INT8 precision for the TensorRT models. Use Model Priority to ensure latency SLO compliance for Tier-1 models.ReferencesCheaper Cloud AI deployments with NVIDIA T4 GPU price cutEfficiently scale ML and other compute workloads on NVIDIA’s T4 GPU, now generally availableNew Compute Engine A2 VMs—first NVIDIA Ampere A100 GPUs in the cloudTurbocharge workloads with new multi-instance NVIDIA GPUs on GKEMitigating transient load effects on ML serving latencyAcknowledgements: David Goodwin, Principal Software Engineer, NVIDIA; Mahan Salehi, Triton Product Manager, NVIDIA; Jill Milton, Senior Account Manager, NVIDIA; Dinesh Mudrakola, Technical Solution Consultant, GCP and GKE Marketplace Team
Quelle: Google Cloud Platform

PurposeProcessing streaming data to extract insights and powering real time applications is becoming more and more critical. Google Cloud Dataflow and Pub/Sub provides a highly scalable, reliable and mature streaming analytics platform to run mission critical pipelines. One very common challenge that developers often face when designing such pipelines is how to handle duplicate data. In this blog, I want to give an overview of common places where duplicate data may originate in your streaming pipelines and discuss various options that are available to you to handle them. You can also check out this tech talk on the same topic.Origin of duplicates in streaming data pipelinesThis section gives an overview of the places where duplicate data may originate in your streaming pipelines. Numbers in red boxes in the following diagram indicate where this may happen.Some duplicates are automatically handled by Dataflow while for others developers may need to use some techniques to handle them. This is summarized in the following table.1. Source generated duplicateYour data source system may itself produce duplicate data. There could be several reasons like network failure, system errors etc that can produce duplicate data. Such duplicates are referred to as ‘source generated duplicates’.One example where this could happen is when you set trigger notifications from Google Cloud Storage to Pub/Sub in response to object changes to GCS buckets. This feature guarantees at-least-once delivery to Pub/Sub and can produce duplicate notifications.2. Publisher generated duplicates Your publisher when publishing messages to Pub/Sub can generate duplicates due to at-least-once publishing guarantees. Such duplicates are referred to as ‘publisher generated duplicates’. Pub/Sub automatically assigns a unique message_id to each message successfully published to a topic. Each message is considered successfully published by the publisher when Pub/Sub returns an acknowledgement to the publisher. Within a topic all messages have a unique message_id and no two messages have the same message_id. If success of the publish is not observed for some reason (network delays, interruptions etc) the same message payload may be retried by the publisher. If retries happen, we may end up with duplicate messages with different message_id in Pub/Sub. For Pub/Sub these are unique messages as they have different message_id.3. Reading from Pub/SubPub/Sub guarantees at least once delivery for every subscription. This means that a message may be delivered more than once by the same subscription if Pub/Sub doesn’t receive acknowledgement within the acknowledgement deadline. The subscriber may acknowledge after the acknowledgement deadline or the acknowledgement may be lost due to transient network issues. In such scenarios the same message would be redelivered and subscribers may see duplicate data. It is the responsibility of the subscribing system (for example Dataflow) to detect such duplicates and handle accordingly.When Dataflow receives messages from Pub/Sub subscription, messages are acknowledged after they are successfully processed by the first fused stage. Dataflow does optimization called fusion where multiple stages can be combined into a single fused stage. A break in fusion happens when there is a shuffle which happens if you have transforms like GROUP BY, COMBINE or I/O transforms like BigQueryIO. If a message has not been acknowledged within its acknowledgement deadline, Dataflow attempts to maintain the lease on the message by repeatedly extending the acknowledgement deadline to prevent redelivery from Pub/Sub. However this is best effort and there is a possibility that messages may be redelivered. This can be monitored using metrics listed here.However, because Pub/Sub provides each message with a unique message_id, Dataflow uses it to deduplicate messages by default if you use the built-in Apache Beam PubSubIO. Thus Dataflow filters out such duplicates originating from redelivery of the same message by Pub/Sub. You can read more about this topic on one of our earlier blog under the section “Example source: Cloud Pub/Sub”4. Processing data in DataflowDue to the distributed nature of processing in Dataflow each message may be retried multiple times on different Dataflow workers. However Dataflow ensures that only one of those tries wins and the processing from the other tries does not affect downstream fused stages. Dataflow does guarantee exactly once processing by leveraging checkpointing at each stage to ensure such duplicates are not reprocessed affecting state or output. You can read more about how this is achieved in this blog.5. Writing to a sinkEach element can be retried multiple times by Dataflow workers and may produce duplicate writes. It is the responsibility of the sink to detect these duplicates and handle them accordingly. Depending on the sink, duplicates may be filtered out, over-written or appear as duplicates.File systems as sinkIf you are writing files, exactly once is guaranteed as any retries by Dataflow workers in event of failure will overwrite the file. Beam provides several I/O connectors to write files, all of which guarantees exactly once processing.BigQuery as sinkIf you use the built-in Apache Beam BigQueryIO to write messages to BigQuery using streaming inserts, Dataflow provides a consistent insert_id (different from Pub/Sub message_id) for retries and this is used by BigQuery for deduplication. However, this deduplication is best effort and duplicate writes may appear. BigQuery provides other insert methods as well with different deduplication guarantees as listed below.You can read more about BigQuery insert methods at the BigQueryIO Javadoc. Additionally for more information on BigQuery as a sink check out the section “Example sink: Google BigQuery” in one of our earlier blog. For duplicates originating from places discussed in points 3), 4) and 5) there are built-in mechanisms in place to remove such duplicates as discussed above, assuming BigQuery is a sink. In the following section we will discuss deduplication options for ‘source generated duplicates’ and ‘publisher generated duplicates’. In both cases, we have duplicate messages with different message_id, which for Pub/Sub and downstream systems like Dataflow are two unique messages.Deduplication options for source generated duplicates and publisher generated duplicates1. Use Pub/Sub message attributesEach message published to a Pub/Sub topic can have some string key value pairs attached as metadata under the “attributes” field of PubsubMessage. These attributes are set when publishing to Pub/Sub. For example, if you are using the Python Pub/Sub Client Library, you can set the “attrs” parameter of the publish method when publishing messages. You can set the unique fields (e.g: event_id) from your message as attribute value and field name as attribute key.Dataflow can be configured to use these fields to deduplicate messages instead of the default deduplication using Pub/Sub message_id. You can do this by specifying the attribute key when reading from Pub/Sub using the built-in PubSubIO.For Java SDK, you can specify this attribute key in the withIdAttribute method of PubsubIO.Read() as shown below.In the Python SDK, you can specify this in the id_label parameter of the ReadFromPubSub PTransform as shown below.This deduplication using a Pub/Sub message attribute is only guaranteed to work for duplicate messages that are published to Pub/Sub within 10 minutes of each other.2. Use Apache Beam Deduplicate PTransformApache Beam provides deduplicate PTransforms which can deduplicate incoming messages over a time duration. Deduplication can be based on the message or a key of a key value pair, where the key could be derived from the message fields. The deduplication window can be configured using the withDuration method, which can be based on processing time or event time (specified using the withTimeDomain method). This has a default value of 10 mins.You can read the Java documentation or the Python documentation of this PTransform for more details on how this works.This PTransform uses the Stateful API under the hood and maintains a state for each key observed. Any duplicate message with the same key that appears within the deduplication window is discarded by this PTransform.3. Do post-processing in sinkDeduplication can also be done in the sink. This could be done by running a scheduled job that periodically deduplicates rows using a unique identifier.BigQuery as a sinkIf BigQuery is the sink in your pipeline, scheduled query can be executed periodically that writes the deduplicated data to another table or updates the existing table. Depending on the complexity of the scheduling you may need orchestration tools like Cloud Composer or Dataform to schedule queries.Deduplication can be done using a DISTINCT statement or DML like MERGE. You can find sample queries about these methods on these blogs (blog 1, blog 2).Often in streaming pipelines you may need deduplicated data available in real time in BigQuery. You can achieve this by creating materialized views on top of underlying tables using a DISTINCT statement.Any new updates to the underlying tables will be updated in real time to the materialized view with zero maintenance or orchestration.Technical trade-offs of different deduplication optionsRelated ArticleAfter Lambda: Exactly-once processing in Google Cloud Dataflow, Part 1Learn the meaning of “exactly once” processing in Dataflow, its importance for stream processing overall and its implementation in stream…Read Article
Quelle: Google Cloud Platform
AWS Security Hub hat 18 neue Kontrollen für seinen Foundational-Security-Best-Practice-Standard veröffentlicht, um die Überwachung des Cloud-Sicherheitsstatus der Kunden zu verbessern. Diese Kontrollen führen vollautomatische Prüfungen anhand bewährter Sicherheitspraktiken für Amazon API Gateway, Amazon EC2, Amazon ECS, Elastic Load Balancing, Amazon Elasticsearch Service, Amazon RDS, Amazon Redshift und Amazon SQS durch. Sofern Sie Security Hub so eingestellt haben, dass neue Kontrollen automatisch aktiviert werden und Sie bereits AWS-Foundational-Security-Best-Practices verwenden, sind diese Kontrollen standardmäßig aktiviert. Security Hub unterstützt jetzt 159 Sicherheitskontrollen zur automatischen Überprüfung Ihres Sicherheitsstatus in AWS.
Quelle: aws.amazon.com

Ein schwedisches Gericht hat nicht die beschlagnahmten Bitcoin erwähnt, sondern den damaligen Gegenwert in Kronen. Der Rest muss jetzt erstattet werden. (Bitcoin, Internet)
Quelle: Golem

Disney hat einen neuen Trailer zur kommenden Serie Star Wars: Visions parat. Dort werden Stimmen von Hollywood-Schauspielern zu hören sein. (Star Wars, Disney)
Quelle: Golem

Studierende aus Deutschland und Luxemburg haben die Chance, dass ihr Experiment auf die ISS geflogen wird. (ISS, Nasa)
Quelle: Golem