Pocuter: Mini-Computer mit OLED-Display ist so groß wie eine Münze
Der Pocuter ist ein winziger Bastelcomputer. Trotzdem ist er mit OLED-Display, Akku, SD-Kartenslot und WLAN ein vollständiges System. (Bastelrechner, OLED)
Quelle: Golem

Der Pocuter ist ein winziger Bastelcomputer. Trotzdem ist er mit OLED-Display, Akku, SD-Kartenslot und WLAN ein vollständiges System. (Bastelrechner, OLED)
Quelle: Golem

Quelle: <a href="Elizabeth Holmes Might Accuse Her Ex-Boyfriend Of Clouding Her Judgement Due To Mental And Sexual Abuse“>BuzzFeed
buoyant.io – mTLS is a hot topic in the Kubernetes world, especially for anyone tasked with getting “encryption in transit” for their applications. But what is mTLS, what kind of security does it provide, and why…
Quelle: news.kubernauts.io

Time series anomaly detection is currently a trending topic—statisticians are scrambling to recalibrate their models for retail demand forecasting and more given the recent drastic changes in consumer behavior. As an intern, I was given the task of creating a machine-learning based solution for anomaly detection on Vertex AI to automate these laborious processes of building time series models. In this article, you will get a glimpse into the kinds of hard problems Google interns are working on, learn more about TensorFlow Probability’s Structural Time Series APIs, and learn how to run jobs on Vertex Pipelines.Vertex PipelinesVertex Pipelines is Google Cloud’s MLOps solutions to help you “automate, monitor, and govern your ML systems by orchestrating your ML workflows.” More specifically, our demo runs on the open source Kubeflow Pipelines SDK that can run on services such as Vertex Pipelines, Amazon EKS, and Microsoft Azure AKS. In this article we demonstrate how to use Vertex Pipelines to automate the process of analyzing new time series data, flagging anomalies, and analyzing these results. To learn more about Vertex Pipelines, read this article.Google Cloud Pipeline ComponentsGoogle Cloud Pipeline Components is Kubeflow Pipeline’s new initiative to offer various solutions as components. Our time series anomaly detection component is the first applied ML component offered in this SDK. You can view our open source component in the SDK’s Github repo, and you can use the component by loading it via url.Note that the component is in experimental mode and has not yet been officially released.TensorFlow Probability Anomaly Detection APITensorFlow Probability has a library of APIs for Structural Time Series (STS), a class of Bayesian statistical models that decompose a time series into interpretable seasonal and trend components. Previously, users had to hand define the trend and seasonal components for their models, for example the demo uses a model with a local linear trend and month-of-year seasonal effect for CO2 concentration forecasting. In conjunction with this intern project, the TensorFlow Probability team built a new anomaly detection API where these components are inferred based on the input time series. This means that users can now do anomaly detection in one line of code:This end-to-end API regularizes the input time series, infers a seasonal model, fits the model, and flags anomalies based on the predictive bounds of acceptable values. It is currently available in the TensorFlow Probability Github repository and will be included in the next official release. Our Google Cloud Pipeline Component packages this API onto the Vertex Pipelines ecosystem and demonstrates an example workflow using this anomaly detection algorithm.Demo NotebookIn our demo, we benchmark the performance of the TensorFlow Probability anomaly detection algorithm on the NYC Taxi task from the Numenta Anomaly Benchmark. This dataset records the total number of NYC taxi passengers from July 2014 – January 2015 in 30-minute increments. There are ~10k data points and 5 anomalies that occur during events like Christmas and the NYC marathon.Here we visualize the results of our pipeline. In the top graph, the black line marks the original time series of taxi passengers over time. The blue distribution marks the forecast distribution that the algorithm deems as likely given the previous time points, meaning any point above or below the forecast is flagged as anomalous. In the bottom graph, the black boxes mark the residual, i.e. the difference between the observed and expected counts of passengers. Here we see that there is a high residual on December 25th and the algorithm correctly flags the day as an anomaly.We also run the custom scoring script from the Numenta Anomaly Benchmark on our predictions to compare the algorithm with others. We see that our algorithm performs the best on this NYC Taxi task as it is able to detect more anomalies with minimal false positives.ConclusionWant to start building your own time series models on Vertex AI? Check out the resources below to dive in:Colab notebook for time series anomaly detectionDocumentation on building your first KFP componentTensorFlow Probability blog post on Structural Time Series ModelingTensorFlow Probability demo for Structural Time Series Modeling Case StudiesRelated ArticleBuild a reinforcement learning recommendation application using Vertex AIIn this article, we’ll demonstrate an RL-based movie recommender system, including a MLOps pipeline, built with Vertex AI and TF-Agents.Read Article
Quelle: Google Cloud Platform

Mehr Deutsche mögen Elektroautos und ein Beinahe-Pornoverbot: die Woche im Video. (Gamescom, Elektroauto)
Quelle: Golem
Many of the largest businesses in the world are at some stage of a substantial SAP migration. Learn more about how Red Hat Integration has the tools to make integrating SAP applications simpler and faster.
Quelle: CloudForms
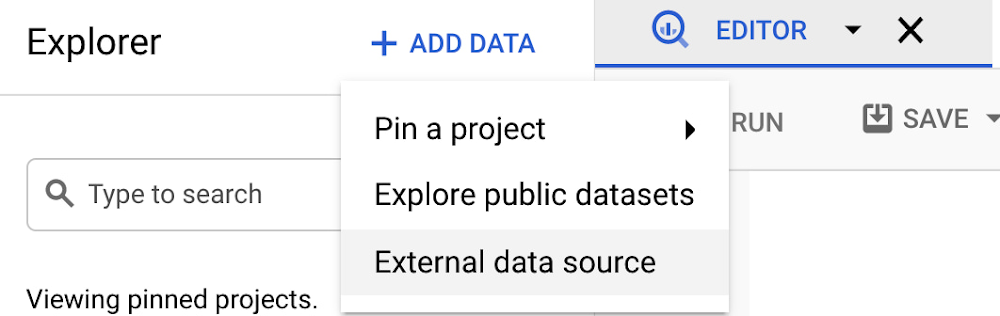
As enterprises compete for market share, their need for real-time insights has given rise to increased demand for transactional databases to support data analytics. Whether it’s to provide dashboards that inform rapid decision-making, to perform analysis on a lookup table stored in a transactional database, or to conduct complex hybrid transactional analytical workloads, there is a growing demand for analyzing large volumes of data in transactional databases.Cloud Spanner is Google Cloud’s fully managed relational database for transactional workloads, and today, with the general availability of Spanner federated queries with BigQuery, it gets even more powerful. BigQuery is Google Cloud’s market-leading serverless, highly scalable, multi-cloud data warehouse that makes analytics easy by bringing together data from multiple sources. With Spanner’s BigQuery federation, you can query data residing in Spanner in real time without moving or copying the data, bridging the gap between operational data and analytics and creating a unified data lifecycle.It’s already been possible to use tools like Dataflow to copy data from Spanner over to BigQuery, but if you haven’t set up these ETL workflows — or you simply need to do a quick lookup on data that’s in Spanner — you can now take advantage of BigQuery’s query federation support to run real-time queries on data that’s stored in Spanner. In this post, we’ll look at how to set up a federated query in BigQuery that accesses data stored in Spanner.How to run a federated querySuppose you’re an online retailer that uses Spanner to store your shopping transactions, and you have a Customer 360 application built in BigQuery. You can now use federated queries to include this customer’s shopping transactions in your Customer 360 application without needing to copy the data over to BigQuery from Spanner.To run a Customer 360 query in BigQuery that includes the shopping transactions that are stored in Spanner, follow these steps:Launch BigQuery and choose the Google Cloud project that contains the Spanner instance that includes the shopping transactions database.Set up an external data source for the Spanner shopping database in BigQuery. You’ll need to have bigquery.admin permissions to set this up.Write a query in BigQuery that accesses the shopping data in the Spanner data source. If you’d like other users to access this external data source in BigQuery, simply grant them permission to use the connection resource you just created.Setting up an external data sourceTo setup a Spanner external data source, select “Add data” and choose “External Data Source”From here, add the connection settings for your Spanner database.Writing a query that accesses the Spanner data sourceOnce you’ve created the external data source, it will be listed as one of the external connections in your project in the BigQuery Explorer.Now, you simply use the EXTERNAL_QUERY function to send a query statement to Spanner, using Spanner’s native SQL dialect. The results are converted to BigQuery standard SQL data types and can be joined with other data in BigQuery.Here’s the syntax for using EXTERNAL_QUERY:SELECT * FROM EXTERNAL_QUERY(connection_id, external_database_query);Connection_id(string): The name of the Spanner database connection resource. It is of the form: projects/projectID/locations/us/connections/ConnectionID. ConnectionID is the connection ID you created when you set up the external data source.external_database_query (string): a read-only query in Spanner’s SQL dialect. The query is executed in Spanner and returned as a table in BigQuery.For example:And it’s as simple as that. There’s no need to copy data from Spanner over to BigQuery — EXTERNAL_QUERY takes care of everything. Moreover, EXTERNAL_QUERY returns a table that is no different from any other table in BigQuery, so you can JOIN to it, add it to materialized and authorized views, populate a dashboard with it, and even schedule the query using BigQuery’s scheduler.Advantages of using Spanner federated queries with BigQuery When you use query federation, the query is run by Spanner, and the results are returned to BigQuery as a table. The data is accessed in real-time; there’s no need to wait for an ETL job to complete for the freshest of data.The query will be executed by Spanner, so you’ll be able to take advantage of the same query optimizer and SQL capabilities that you’ll find in Spanner. You’ll also have the option to take advantage of Spanner’s PartitionQuery capabilities. You’ll likely find EXTERNAL_QUERY is useful for lookups and simple analytics in Spanner tables rather than intensive analytics that would benefit from BigQuery’s strong analytic capabilities. For more intensive analytics, you can still use EXTERNAL_QUERY to copy the data over to BigQuery rather than writing ETL jobs, and continue to run the analytics in BigQuery, such as the following:Learn moreTo get started with Spanner, create an instanceor try it out with a Spanner Qwik Start.To learn more about Spanner federated queries with BigQuery, see the documentation.Related ArticleRegistration is open for Google Cloud Next: October 12–14Register now for Google Cloud Next on October 12–14, 2021Read Article
Quelle: Google Cloud Platform
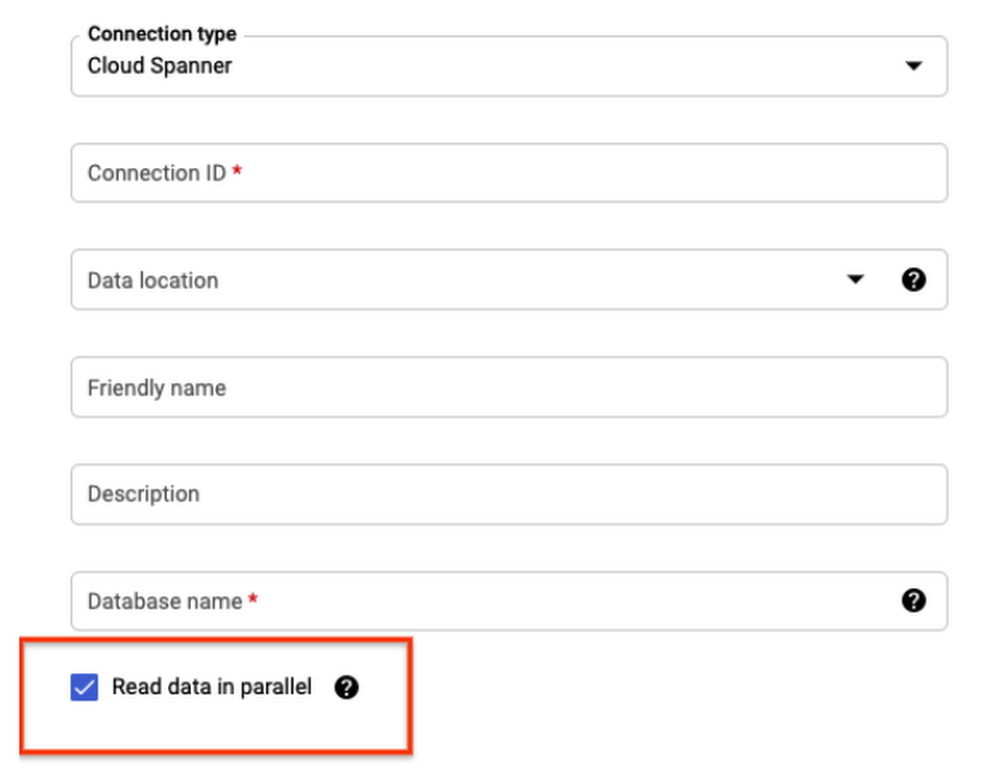
Cloud Spanner is GCP’s native and distributed Online Transaction Processing System (OLTP). Due to its distributed nature, it can scale horizontally and therefore is suitable for workloads with very high throughputs containing large volumes of data. This invites a huge opportunity to do analytics on top of it. Thanks to Cloud Spanner BigQuery Federation, you can now easily fetch Cloud Spanner data into BigQuery for analytics. In this post, you will learn how to efficiently use this feature to replicate large tables with high throughput (lots of inserts or updates written per second), with low to medium replication lag.ELT process optimizationsSetting up an efficient Extract Load and Transform (ELT) to fetch data from Cloud Spanner to BigQuery is the key for low replication lag. After performing an initial full load, you will need to set up incremental loads. For large tables in Cloud Spanner, refreshing full data every time can be slow and costly. Therefore it is more efficient to extract only new changes and merge with existing data in BigQuery.Designing Cloud Spanner for incremental dataTaking an example table schema such as below:In order to identify incremental changes, you will need to add a commit timestamp column (say lastUpdateTime). In addition, your application will need to pass PENDING_COMMIT_TIMESTAMP(), so that Cloud Spanner updates the corresponding field post commit.To efficiently read the rows changed after a certain timestamp you will need to create an index. Since indexes on monotonically increasing values can cause hotspots you will need to add another column (say shardid) and create a composite index using (shardid, lastUpdatedTime). Updated schema would look as below:In the above example, I have added LastUpdateTime as a commit timestamp column. Also added ShardId as a generated column which will produce values in range of -18 to +18. This helps in avoiding hotspots when indexing timestamp by creating composite an index on (ShardId, LastUpdateTime). Further you can make it a NULL FILTERED index to keep it light. You can periodically update LastUpdateTime as null for old records. Read here for a more detailed solution.Now to query incremental changes from the table SQL query will be as follows:Above sql query reads data from all shards as well as filters on LastUpdateTime. Therefore using the index to optimize reading speed from large tables.Initial loading of data into BigQueryLoading data for the first time is likely to read the entire table in Cloud Spanner and send results into BigQuery. Therefore you should create a connection with the “Read Data in Parallel” option.Below is an example sql query to do the initial load.Incrementally loading data into BigQueryUpdate the connection (or create new connection) with “Read data in parallel” unchecked.This is because (at the time of writing), Spanner queries using indices are not root partitionable and the result cannot be read in parallel. This might get changed in future.After getting incremental data from Cloud Spanner it should be stored into a staging table in BigQuery, thus completing the Extract and Load part of (ELT). Finally you will need to write a Merge statement to consolidate incremental data into a BigQuery table.Thanks to BigQuery’s scripting all of this ELT can be combined into a single script as below and further it can be configured as scheduled query.Above script finds last time bigquery was updated for that table. It constructs a SQL Query to fetch any incremental data post last fetch and store it as a staging table. Then merge new data into bigquery table and finally delete the staging table. Explicit dropping of table ensures that two parallel executions of above script will fail. This is important so that if there is a sudden surge then no data shall be missed.Other considerationsCreating table partitions in BigQueryIt is common to create table partitions and clustering based on your reads / analytics requirements. However, this can lead to a low merge performance. You should make use of BigQuery partitioning and clustering in such cases.Clustering can improve match performance, therefore you can add clustering on the PK of the table. Merging data rewrites entire partitions, having partition filters can limit volume of data rewritten. Handling deleted rowsAbove solution will skip over deleted rows, which might be acceptable for many use-cases. However if you need to track the deletes then the application will need to implement soft deletes like add a column isDeleted = true/false. Data from Cloud Spanner should be hard deleted after some delay so that changes are synchronized into BigQuery first.During merge operation in bigquery you can conditionally delete based on the above flag.What’s nextIn this article you learned about how to replicate data from Cloud Spanner to BigQuery. If you want to test this in action, use Measure Cloud Spanner performance using JMeter for a step by step guide on generating sample data on Cloud Spanner for your workload schema.Related ArticleMeasuring Cloud Spanner performance for your workloadIn this post, we will explore a middle ground to performance testing using JMeter. Performance test Cloud Spanner for a custom workload b…Read Article
Quelle: Google Cloud Platform
Mit Amazon AppFlow und dem SAP-Betriebsdaten-Bereitstellungs-Framework (Operational Data Provisioning, ODP) können Sie jetzt mit nur wenigen Klicks Daten aus SAP-ERP-Anwendungen (ECC, BW, BW4/HANA und S/4HANA) an AWS-Services senden.
Quelle: aws.amazon.com
AWS IoT Greengrass ist ein Edge-Laufzeit- und Cloud-Service für das Internet of Things (IoT), der Kunden beim Erstellen, Bereitstellen und Verwalten von Gerätesoftware unterstützt. Unsere Version 2.4 enthält zwei neue Funktionen, die die Bereitstellung großer IoT-Geräteflotten vereinfachen und eine fein abgestimmte Steuerung der Systemressourcen von IoT-Geräten aus der Cloud ermöglichen:
Quelle: aws.amazon.com