All you need to know about Cloud Storage
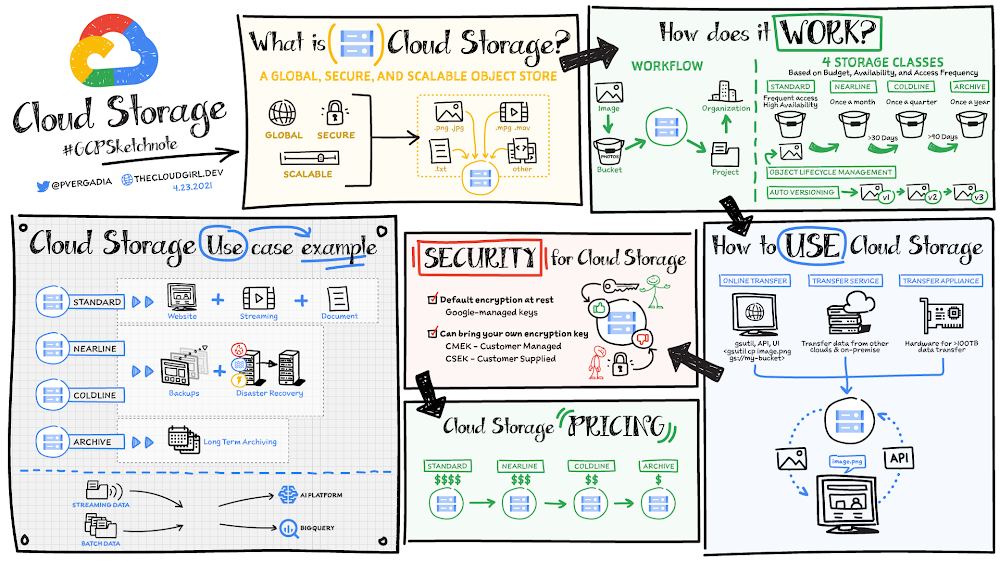
Cloud Storage is a global, secure, and scalable object store for immutable data such as images, text, videos, and other file formats. You can add data to it or retrieve data from it as often as your application needs. The objects stored have an ID, metadata, attributes, and the actual data. The metadata can include all sorts of things, including the security classification of the file, the applications that can access it, and similar information. The ID, metadata, and attributes make object storage an appealing storage choice for a large variety of applications ranging from web serving to data analytics. Click to enlargeStorage classesYou store objects in buckets that are associated with a project, which are, in turn, grouped under an organization. There are four storage classes that are based on budget, availability, and access frequency. Standard buckets for high-performance, frequent access, and highest availabilityRegional or dual-regional locations for data accessed frequently or high-throughput needsMulti-region for serving content globallyNearline for data accessed less than once a month Coldline for data accessed roughly less than once a quarterArchive for data that you want to put away for years (accessed less than once a year)It costs a bit more to use standard storage because it is designed for short-lived and/or frequently accessed data. Nearline, coldline, and archive storage offer a lower monthly storage cost for longer-lived and less frequently accessed data. Choosing a location for your use caseCloud Storage lets you store your data in three types of locations:Regional: all of your data is stored redundantly in a single region. Regional buckets usually offer the lowest monthly storage price and are suitable for a wide range of use cases, including high-performance analytics where it is important to co-locate your compute and storage in the same region.Multi-region: all of your data is stored redundantly across a continent but it’s not visible which specific regions your data is in. Availability is higher than regional because your data can be served from more than one region. Multi-regions cost a little more than single regions, but are great choices for content serving to the Internet.Dual-regions: all of your data is stored in two specific regions. Dual-regions provide the best of regions and multi-regions — providing you with high availability and protection against regional failures while also giving you the high-performance characteristics of regional storage. Business-critical workloads are often best implemented on top of dual-regions. Dual-regions can also be a great choice for a data lake for streaming as well as for batch uploading of data for big data and ML projects.No matter the location that you select, all four storage classes are available to you so that you can optimize your costs over time, storing your most active “hot” data in Standard and moving it down to colder classes as it becomes older and less frequently accessed.How to use Cloud Storage With Object Lifecycle Management you can automatically transition your data to lower-cost storage classes when it reaches a certain age or when other lifecycle rules that you’ve set up apply. Cloud Storage also offers automatic object versioning, so you can restore older versions of objects—which can be especially helpful as protection against accidental deletion.You can upload objects to the bucket and download objects from it using the console or gsutilcommands, Storage Transfer Service, Transfer Appliance, or transfer online. Once you have stored the data, accessing it is easy with a single API call for all storage classes. For a more in depth look at optimizing location and costs for your Cloud Storage buckets, check out this article: Optimizing object storage costs in Google Cloud: location and classes.SecurityBy default 100% of data in Cloud Storage is automatically encrypted at rest and in transit with no configuration required by customers. You can grant permission to specific members and teams or make the objects fully public for use cases such as websites.If you want more direct control over encryption you have two additional key management options available to you that go beyond the built-in encryption that Google manages for you: You can use customer-managed encryption keys (CMEK) via Google Cloud Key Management Service (KMS). You can define access controls to encryption keys, establish rotation policies, and gather additional logging into encryption/decryption activities. In both the default and customer-managed case, Google remains the root of trust for encryption/decryption activities. You can use customer-supplied encryption keys (CSEK) in which Google is no longer in the root of trust. Using CSEK comes with some additional risk of data loss, as Google cannot help you decrypt data if you lose your encryption keys.Furthermore, you do not have to choose one key management option only. You can make use of the default encryption for most of your workloads, and add some extra control for select applications.ConclusionWhether you need to store data for regulatory compliance, disaster recovery, analytics, or simply serving it on the web, Cloud Storage has you covered. For a more in-depth look check out the Cloud Storage Bytes video series. For more #GCPSketchnote, follow the GitHub repo. For similar cloud content follow me on Twitter @pvergadia and keep an eye out on thecloudgirl.dev.
Quelle: Google Cloud Platform



