At Docker, we’re incredibly proud of our vibrant, diverse and creative community. From time to time, we feature cool contributions from the community on our blog to highlight some of the great work our community does. Are you working on something awesome with Docker? Send your contributions to Ajeet Singh Raina (@ajeetraina) on the Docker Community Slack and we might feature your work!
Tons of developers use Docker containers to package their Spring Boot applications. According to VMWare’s State of Spring 2021 report, the number of organizations running containerized Spring apps spiked to 57% — compared to 44% in 2020.
What’s driving this significant growth? The ever-increasing demand to reduce startup times of web applications and optimize resource usage, which greatly boosts developer productivity.
Why is containerizing a Spring Boot app important?
Running your Spring Boot application in a Docker container has numerous benefits. First, Docker’s friendly, CLI-based workflow lets developers build, share, and run containerized Spring applications for other developers of all skill levels. Second, developers can install their app from a single package and get it up and running in minutes. Third, Spring developers can code and test locally while ensuring consistency between development and production.
Containerizing a Spring Boot application is easy. You can do this by copying the .jar or .war file right into a JDK base image and then packaging it as a Docker image. There are numerous articles online that can help you effectively package your apps. However, many important concerns like Docker image vulnerabilities, image bloat, missing image tags, and poor build performance aren’t addressed. We’ll tackle those common concerns while sharing nine tips for containerizing your Spring Boot code.
A Simple “Hello World” Spring Boot application
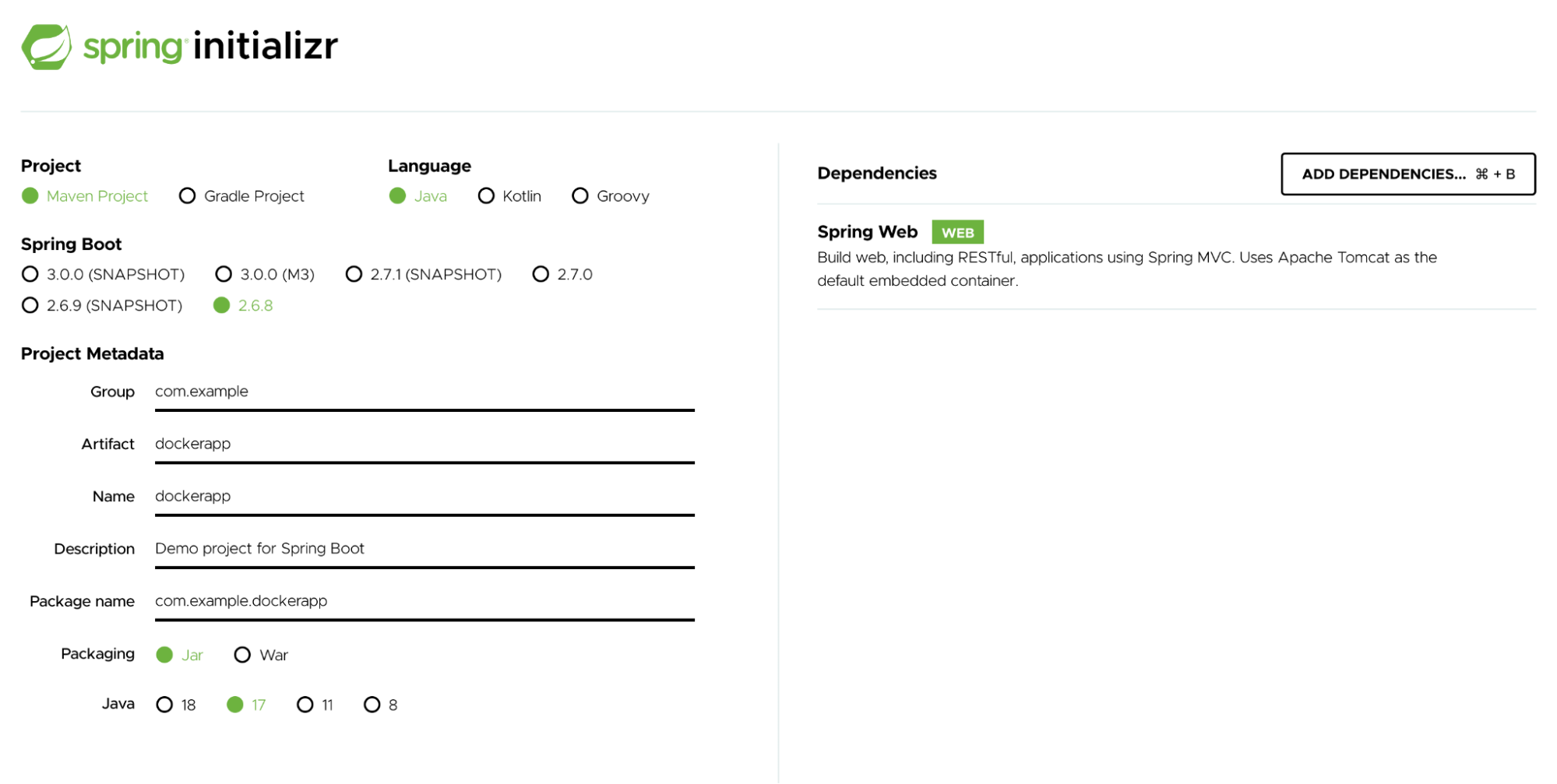
To better understand the unattended concern, let’s build a sample “Hello World” application. In our last blog post, you saw how easy it is to build the “Hello World!” application by downloading this pre-initialized project and generating a ZIP file. You’d then unzip it and complete the following steps to run the app.
Under the src/main/java/com/example/dockerapp/ directory, you can modify your DockerappApplication.java file with the following content:
package com.example.dockerapp;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@SpringBootApplication
public class DockerappApplication {
@RequestMapping("/")
public String home() {
return "Hello World!";
}
public static void main(String[] args) {
SpringApplication.run(DockerappApplication.class, args);
}
}
The following command takes your compiled code and packages it into a distributable format, like a JAR:
./mvnw package
java -jar target/*.jar
By now, you should be able to access “Hello World” via http://localhost:8080.
In order to Dockerize this app, you’d use a Dockerfile. A Dockerfile is a text document that contains every instruction a user could call on the command line to assemble a Docker image. A Docker image is composed of a stack of layers, each representing an instruction in our Dockerfile. Each subsequent layer contains changes to its underlying layer.
Typically, developers use the following Dockerfile template to build a Docker image.
FROM eclipse-temurin
ARG JAR_FILE=target/*.jar
COPY ${JAR_FILE} app.jar
EXPOSE 8080
ENTRYPOINT ["java", "-jar", "/app.jar"]
The first line defines the base image which is around 457 MB. The ARG instruction specifies variables that are available to the COPY instruction. The COPY copies the JAR file from the target/ folder to your Docker image’s root. The EXPOSE instruction informs Docker that the container listens on the specified network ports at runtime. Lastly, an ENTRYPOINT lets you configure a container that runs as an executable. It corresponds to your java -jar target/*.jar command.
You’d build your image using the docker build command, which looks like this:
$ docker build -t spring-boot-docker .
Sending build context to Docker daemon 15.98MB
Step 1/5 : FROM eclipse-temurin
—a3562aa0b991
Step 2/5 : ARG JAR_FILE=target/*.jar
—Running in a8c13e294a66
Removing intermediate container a8c13e294a66
—aa039166d524
Step 3/5 : COPY ${JAR_FILE} app.jar
COPY failed: no source files were specified
One key drawback of our above example is that it isn’t fully containerized. You must first create a JAR file by running the ./mvnw package command on the host system. This requires you to manually install Java, set up the JAVA_HOME environment variable, and install Maven. In a nutshell, your JDK must reside outside of your Docker container — adding even more complexity into your build environment. There has to be a better way.
1) Automate all the manual steps
We recommend building up the JAR during the build process within your Dockerfile itself. The following RUN instructions trigger a goal that resolves all project dependencies, including plugins, reports, and their dependencies:
FROM eclipse-temurin
WORKDIR /app
COPY .mvn/ .mvn
COPY mvnw pom.xml ./
RUN ./mvnw dependency:go-offline
COPY src ./src
CMD ["./mvnw", "spring-boot:run"]
💡 Avoid copying the JAR file manually while writing a Dockerfile
2) Use a specific base image tag, instead of latest
When building Docker images, it’s always recommended to specify useful tags which codify version information, intended destination (prod or test, for instance), stability, or other useful information for deploying your application in different environments. Don’t rely on the automatically-created latest tag. Using latest is unpredictable and may cause unexpected behavior. Every time you pull the latest image, it might contain a new build or untested release that could break your application.
For example, using the eclipse-temurin:latest Docker image as a base image isn’t ideal. Instead, you should use specific tags like eclipse-temurin:17-jdk-jammy , eclipse-temurin:8u332-b09-jre-alpin etc.
💡 Avoid using FROM eclipse-temurin:latest in your Dockerfile
3) Use Eclipse Temurin instead of JDK, if possible
On the OpenJDK Docker Hub page, you’ll find a list of recommended Docker Official Images that you should use while building Java applications. The upstream OpenJDK image no longer provides a JRE, so no official JRE images are produced. The official OpenJDK images just contain “vanilla” builds of the OpenJDK provided by Oracle or the relevant project lead.
One of the most popular official images with a build-worthy JDK is Eclipse Temurin. The Eclipse Temurin project provides code and processes that support the building of runtime binaries and associated technologies. These are high performance, enterprise-caliber, and cross-platform.
FROM eclipse-temurin:17-jdk-jammy
WORKDIR /app
COPY .mvn/ .mvn
COPY mvnw pom.xml ./
RUN ./mvnw dependency:go-offline
COPY src ./src
CMD ["./mvnw", "spring-boot:run"]
4) Use a Multi-Stage Build
With multi-stage builds, a Docker build can use one base image for compilation, packaging, and unit tests. Another image holds the runtime of the application. This makes the final image more secure and smaller in size (as it does not contain any development or debugging tools). Multi-stage Docker builds are a great way to ensure your builds are 100% reproducible and as lean as possible. You can create multiple stages within a Dockerfile and control how you build that image.
You can containerize your Spring Boot applications using a multi-layer approach. Each layer may contain different parts of the application such as dependencies, source code, resources, and even snapshot dependencies. Alternatively, you can build any application as a separate image from the final image that contains the runnable application. To better understand this, let’s consider the following Dockerfile:
FROM eclipse-temurin:17-jdk-jammy
ARG JAR_FILE=target/*.jar
COPY ${JAR_FILE} app.jar
EXPOSE 8080
ENTRYPOINT ["java", "-jar", "/app.jar"]
Spring Boot uses a “fat JAR” as its default packaging format. When we inspect the fat JAR, we see that the application forms a very small part of the entire JAR. This portion changes most frequently. The remaining portion contains the Spring Framework dependencies. Optimization typically involves isolating the application into a separate layer from the Spring Framework dependencies. You only have to download the dependencies layer — which forms the bulk of the fat JAR — once, plus it’s cached in the host system.
The above Dockerfile assumes that the fat JAR was already built on the command line. You can also do this in Docker using a multi-stage build and copying the results from one image to another. Instead of using the Maven or Gradle plugin, we can also create a layered JAR Docker image with a Dockerfile. While using Docker, we must follow two more steps to extract the layers and copy those into the final image.
In the first stage, we’ll extract the dependencies. In the second stage, we’ll copy the extracted dependencies to the final image:
FROM eclipse-temurin:17-jdk-jammy as builder
WORKDIR /opt/app
COPY .mvn/ .mvn
COPY mvnw pom.xml ./
RUN ./mvnw dependency:go-offline
COPY ./src ./src
RUN ./mvnw clean install
FROM eclipse-temurin:17-jre-jammy
WORKDIR /opt/app
EXPOSE 8080
COPY –from=builder /opt/app/target/*.jar /opt/app/*.jar
ENTRYPOINT ["java", "-jar", "/opt/app/*.jar" ]
The first image is labeled builder. We use it to run eclipse-temurin:17-jdk-jammy, build the fat JAR, and unpack it.
Notice that this Dockerfile has been split into two stages. The later layers contain the build configuration and the source code for the application, and the earlier layers contain the complete Eclipse JDK image itself. This small optimization also saves us from copying the target directory to a Docker image — even a temporary one used for the build. Our final image is just 277 MB, compared to the first stage build’s 450MB size.
5) Use .dockerignore
To increase build performance, we recommend creating a .dockerignore file in the same directory as your Dockerfile. For this tutorial, your .dockerignore file should contain just one line:
target
This line excludes the target directory, which contains output from Maven, from the Docker build context. There are many good reasons to carefully structure a .dockerignore file, but this simple file is good enough for now. Let’s now explain the build context and why it’s essential . The docker build command builds Docker images from a Dockerfile and a “context.” This context is the set of files located in your specified PATH or URL. The build process can reference any of these files.
Meanwhile, the compilation context is where the developer works. It could be a folder on Mac, Windows or a Linux directory. This directory contains all necessary application components like source code, configuration files, libraries, and plugins. With the .dockerignore file, we can determine which of the following elements like source code, configuration files, libraries, plugins, etc. to exclude while building your new image.
Here’s how your .dockerignore file might look if you choose to exclude the conf, libraries, and plugins directory from your build:
6) Favor Multi-Architecture Docker Images
Your CPU can only run binaries for its native architecture. For example, Docker images built for an x86 system can’t run on an Arm-based system. With Apple fully transitioning to their custom Arm-based silicon, it’s possible that your x86 (Intel or AMD) Docker Image won’t work with Apple’s recent M-series chips. Consequently, we always recommended building multi-arch container images. Below is the mplatform/mquery Docker image that lets you query the multi-platform status of any public image, in any public registry:
docker run –rm mplatform/mquery eclipse-temurin:17-jre-alpine
Image: eclipse-temurin:17-jre-alpine (digest: sha256:ac423a0315c490d3bc1444901d96eea7013e838bcf7cc09978cf84332d7afc76)
* Manifest List: Yes (Image type: application/vnd.docker.distribution.manifest.list.v2+json)
* Supported platforms:
– linux/amd64
We introduced the docker buildx command to help you build multi-architecture images. Buildx is a Docker component that enables many powerful build features with a familiar Docker user experience. All builds executed via Buildx run via the Moby BuildKit builder engine. BuildKit is designed to excel at multi-platform builds, or those not just targeting the user’s local platform. When you invoke a build, you can set the –platform flag to specify the build output’s target platform, (like linux/amd64, linux/arm64, or darwin/amd64):
docker buildx build –platform linux/amd64, linux/arm64 -t spring-helloworld .
7) Run as non-root user for security purposes
Running applications with user privileges is safer, since it helps mitigate risks. The same applies to Docker containers. By default, Docker containers and their running apps have root privileges. It’s therefore best to run Docker containers as non-root users. You can do this by adding USER instructions within your Dockerfile. The USER instruction sets the preferred user name (or UID) and optionally the user group (or GID) while running the image — and for any subsequent RUN, CMD, or ENTRYPOINT instructions:
FROM eclipse-temurin:17-jdk-alpine
RUN addgroup demogroup; adduser –ingroup demogroup –disabled-password demo
USER demo
WORKDIR /app
COPY .mvn/ .mvn
COPY mvnw pom.xml ./
RUN ./mvnw dependency:go-offline
COPY src ./src
CMD ["./mvnw", "spring-boot:run"]
8) Fix security vulnerabilities in your Java image
Today’s developers rely on third-party code and applications while building their services. By using external software without care, your code may be more vulnerable. Leveraging trusted images and continually monitoring your containers is essential to combatting this. Whenever you build a “Hello World” Docker image, Docker Desktop prompts you to run security scans of the image to detect any known vulnerabilities, like Log4Shell:
exporting to image 0.0s
== exporting layers 0.0s
== writing image sha256:cf6d952a1ece4eddcb80c8d29e0c5dd4d3531c1268291 0.0s
== naming to docker.io/library/spring-boot1 0.0s
Use ‘docker scan’ to run Snyk tests against images to find vulnerabilities and learn how to fix them
Let’s use the the Snyk Extension for Docker Desktop to inspect our Spring Boot application. To begin, install Docker Desktop 4.8.0+ on your Mac, Windows, or Linux machine and Enable Extension Marketplace.
Snyk’s extension lets you rapidly scan both local and remote Docker images to detect vulnerabilities.
Install the Snyk extension and supply the “Hello World” Docker Image.
Snyk’s tool uncovers 70 vulnerabilities of varying severity. Once you’re aware of these, you can begin remediation to galvanize your image.
💡 In order to perform a vulnerability check, you can use the following command directly against the Dockerfile: docker scan -f Dockerfile spring-helloworld
9) Use the OpenTelemetry API to measure Java performance
How do Spring Boot developers ensure that their apps are faster and performant? Generally, developers rely on third-party observability tools to measure the performance of their Java applications. Application performance monitoring is essential for all kinds of Java applications, and developers must create top notch user experiences.
Observability isn’t just limited to application performance. With the rise of microservices architectures, the three pillars of observability — metrics, traces, and logs — are front and center. Metrics help developers to understand what’s wrong with the system, while traces help you discover how it’s wrong. Logs tells you why it’s wrong, letting developers dig into particular metrics or traces to holistically understand system behavior.
Observing Java applications requires monitoring your Java VM metrics via JMX, underlying host metrics, and Java app traces. Java developers should monitor, analyze, and diagnose application performance using the Java OpenTelemetry API. OpenTelemetry provides a single set of APIs, libraries, agents, and collector services to capture distributed traces and metrics from your application. Check out this video to learn more.
Conclusion
In this blog post, you saw some of the many ways to optimize your Docker images by carefully crafting your Dockerfile and securing your image by using Snyk Docker Extension Marketplace. If you’d like to go further, check out these bonus resources that cover recommendations and best practices for building secure, production-grade Docker images.
Docker Development Best Practices
Dockerfile Best Practices
Build Images with BuildKit
Best Practices for Scanning Images
Getting Started with Docker Extensions
Quelle: https://blog.docker.com/feed/