Load balancing Google Cloud VMware Engine with Traffic Director
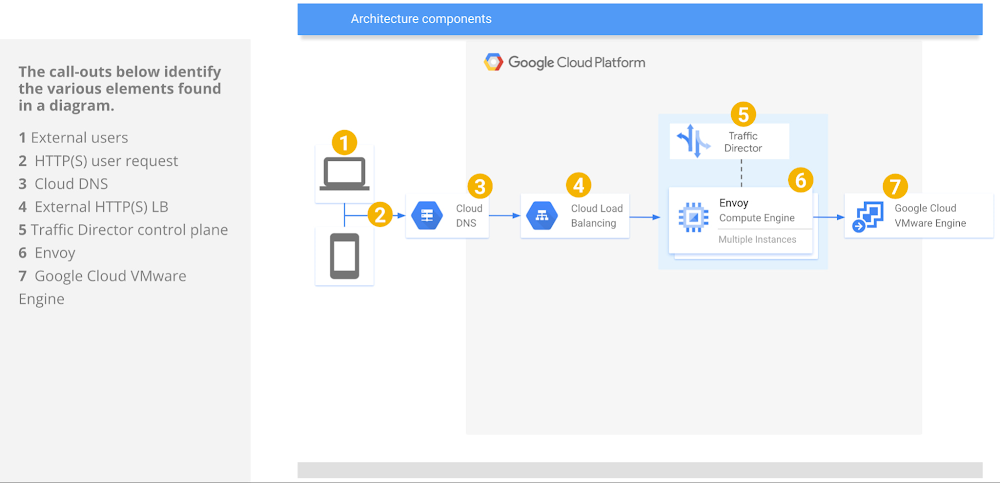
The following solution brief discusses a GCVE + Traffic Director implementation aimed at providing customers an easy way to scale out web services, while enabling application migrations to Google Cloud. The solution is built on top of a flexibleandopen architecture that exemplifies the unique capabilities of Google Cloud Platform. Let’s elaborate:Easy: The full configuration takes minutes to implement and can be scripted or defined with Infrastructure-as-Code (IaC) for rapid consumption and minimal errors.Flexible and open: The solution relies on Envoy, an open source platform that enjoys tremendous popularity with the network and application communities.The availability of Google Cloud VMware Engine (GCVE) has given GCP customers the ability to deploy Cloud applications on a certified VMware stack that is managed, supported and maintained by Google. Many of these customers also demand seamless integration between their applications running on GCVE, and the various infrastructure services that are provided natively by our platform such as Google Kubernetes Engine (GKE), or serverless frameworks like Cloud Functions, App Engine or Cloud Run. Networking services are at the top of that list.In this blog, we discuss how Traffic Director, a fully managed control plane for Service Mesh, can be combined with our portfolio of load balancers and withhybrid network endpoint groups (hybrid NEG) to provide a high-performance front-end for web services hosted in VMware Engine.Traffic Director also serves as the glue that links the native GCP load balancers and the GCVE backends, with the objective of enabling these technical benefits:Certificate Authority integration, for full lifecycle management of SSL certificates.DDoS protection with Cloud Armor, helps protect your applications and websites against denial of service and web attacks.Cloud CDN, for cached content delivery.Intelligent anycast with a Single IP and Global Reach, for improved failover, resiliency and availability. Bring Your Own IP (BYOIP), to provision and use your own public IP addresses for Google Cloud resources.Diverse backend types integration in addition to GCVE, such as GCE, GKE, Cloud Storage and serverless. Scenario #1 – External load balancerThe following diagram provides a summary of the GCP components involved in this architecture:This scenario shows an external HTTP(S) load balancer used to forward traffic to the Traffic Director dataplane component, implemented as a fleet of Envoy proxies. Users can create routable NSX segments and centralize the definition of all traffic policies in Traffic Director. The GCVE VM IP and port pairs are specified directly in the hybrid NEG, meaning all network operations are fully managed by a Google Cloud control plane.Alternatively, GCVE VMs can be deployed to a non-routable NSX segment behind an NSX L4 load balancer configured at the Tier-1 level, and the Load Balancer VIP can be exported to the customer VPC via the import and export of routes in the VPC Peering connection. It is important to note that in GCVE, it is highly recommended that NSX-T load balancers be associated with Tier-1 gateways, and not the Tier-0 gateway.The steps to configure load balancers in NSX-T, including server pools, health checks, virtual servers and distribution algorithms are documented by VMware and not covered in this document.Fronting the web applications with an NSX load balancer would allow for the following:Only VIP routes are announced, allowing the use of private IP addresses in the web tier, as well as overlapping IP addresses in case of multi-tenant deployments.Internal clients (applications inside of GCP or GCVE) can point to the VIP of the NSX Load Balancer, while external clients can point to the public VIP in front of a native, GCP external load balancer.A L7 NSX load balancer can also be used (not discussed in this example), for advanced application-layer services, such as cookie session persistence, URL mapping, and more.To recap, the implementation discussed in this scenario shows an external HTTP(S) load balancer, but please note that an external TCP/UDP network load balancer or TCP Proxy could also be used for supporting protocols other than HTTP(S). There are certain restrictions when using Traffic Director in L4 mode, such as a single backend service per target proxy, which need to be accounted for when implementing your architecture.Scenario #2 – Internal load balancerIn this scenario, the only change is the load balancing platform used to route requests to Traffic Director-managed Envoy proxies. This use case may be appropriate in certain situations, for instance, whenever the users want to take advantage of advanced traffic management capabilities not supported without Traffic Director, as documented here.The Envoy-managed proxies controlled by Traffic Director can send traffic directly to GCVE workloads:Alternately, and similar to what was discussed in Scenario #1, an NSX LB VIP can be used instead of the explicit GCVE VM IPs, which introduces an extra load balancing layer:To recap, this scenario shows a possible configuration with L7 Internal Load Balancer, but an L4 Internal Load Balancer can also be used for supporting protocols other than HTTP(S). Please note there are certain considerations when leveraging L4 vs. L7 load balancers in combination with Traffic Director, which are all documented here.ConclusionWith the combination of multiple GCP products, customers can take advantage of the various distributed network services offered by Google, such as global load balancing, while hosting their applications on a Google Cloud VMware Engine environment that provides continuity for their operations, without sacrificing availability, reliability or performance.Go ahead and review the GCVE networking whitepaper today. For additional information about VMware Engine, please visit the VMware Engine landing page, and explore our interactive tutorials. And be on the lookout for future articles, where we will discuss how VMware Engine integrates with other core GCP infrastructure and data services.Related ArticleNew in Google Cloud VMware Engine: Single nodes, certifications and moreThe latest version of Google Cloud VMware Engine now supports single node clouds, compliance certs and Toronto availabilityRead Article
Quelle: Google Cloud Platform