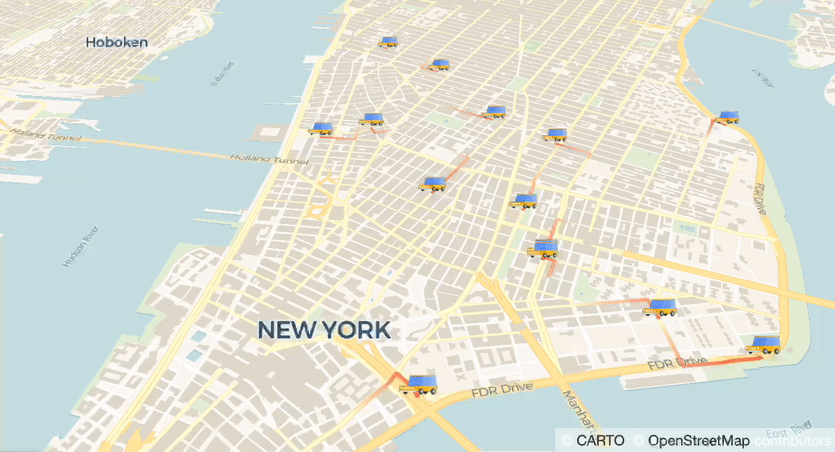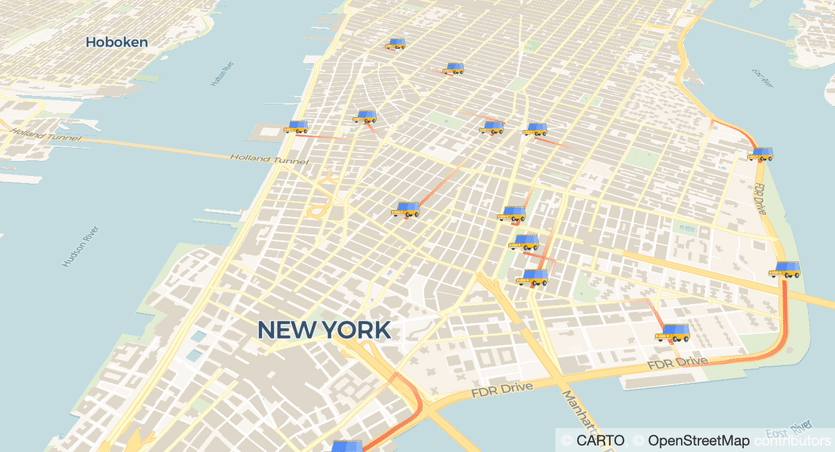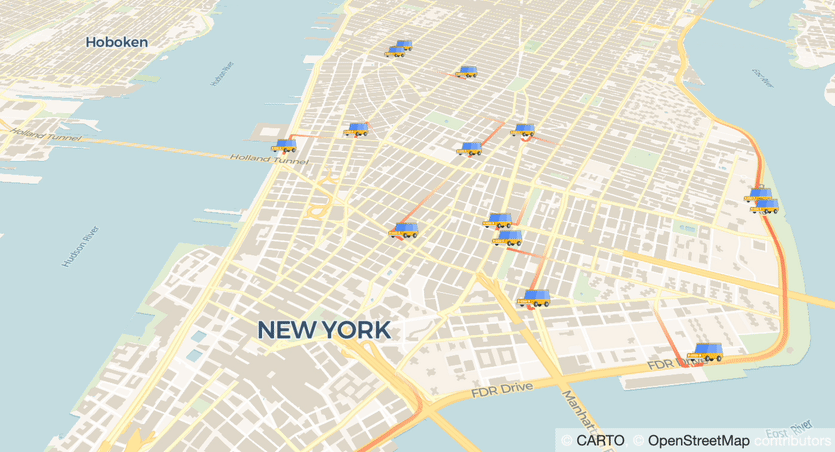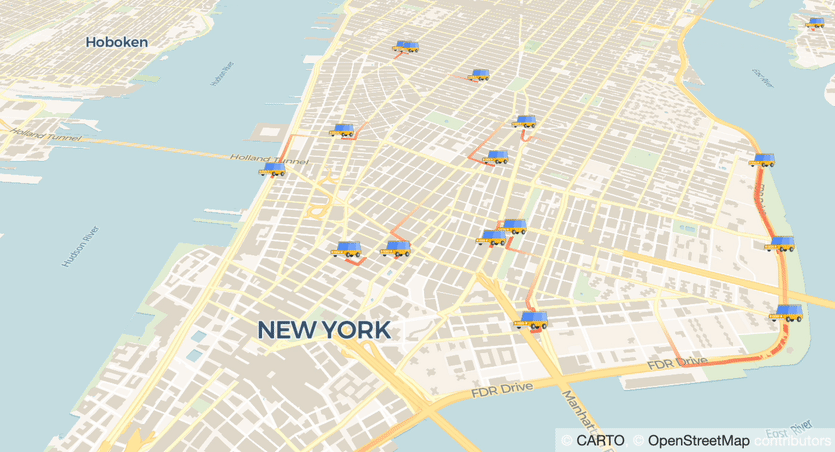
Visualization is the key to understanding massive amounts of data. Today we have BigQuery and Looker to analyze petabytes scale data and to extract insights in a sophisticated way. But how about monitoring data that actively changes every second? In this post, we will walk through how to build a real-time dashboard with Cloud Run and Firestore.Mobility DashboardThere are many business use cases that require real-time updates. For example, inventory monitoring in retail stores, security cameras, and MaaS (Mobility as a Service) applications such as share ride. In the MaaS business area, locations of vehicles are very useful in making business decisions. In this post, we are going to build a mobility dashboard, monitoring vehicles on a map in real-time.The ArchitectureThe dashboard should be accessible from the web browser without any setups on the client side. Cloud Run is a good fit because it can generate URLs, and of course, scalable that can handle millions of users. Now we need to implement an app that can plot geospatial data, and a database that can broadcast its update. Here are my choices and architecture.Cloud Run — Hosting a web app (dashboard)(streamlit — a library to visualize data and to make web app)(pydeck — a library to plot geospatial data)Firestore — a full managed database that keeps your data in syncThe diagram below illustrates a brief architecture of the system. In the production environment, you may also need to implement a data ingestion and transform pipeline.Before going to the final form, let’s take some steps to understand each component.Step 1: Build a data visualization web app with Cloud Run + streamlitstreamlit is an OSS web app framework that can create beautiful data visualization apps without knowledge of the front-end (e.g. HTML, JS). If you are familiar with pandas DataFrame for your data analytics, it won’t take time to implement. For example, you can easily visualize your DataFrame in a few lines of code.code_block[StructValue([(u’code’, u”import streamlit as strnchart_data = pd.DataFrame(rn np.random.randn(20, 3),rn columns=[‘a’, ‘b’, ‘c’])rnst.line_chart(chart_data)”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e54a26e3d90>)])]The chart on the webapp (Source)Making this app runnable on Cloud Run is easy. Just add streamlit in requirements.txt, and make Dockerfile from a typical python webapp image. If you are not familiar with Docker, buildpacks can do the job. Instead of making Dockerfile, make Procfile with just 1 line as below.code_block[StructValue([(u’code’, u’web: streamlit run app.py –server.port $PORT –server.enableCORS=false’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e54a3261350>)])]To summarize, the minimum required files are only as below.code_block[StructValue([(u’code’, u’.rn|– app.pyrn|– Procfilern|– requirements.txt’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e54b4265b10>)])]Deployment is also easy. You can deploy this app to Cloud Run with just a command.code_block[StructValue([(u’code’, u’$ gcloud run deploy mydashboard –source .’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e54b4265310>)])]This command will build and make your image with buildpacks and Cloud Build, thus you don’t need to set up a build environment in your local system. Once deployment is completed, you can access your web app with the generated URL like https://xxx-[…].run.app. Copy and paste the URL into your web browser, and you will see your first dashboard webapp.Step 2: Add a callback function that receive changes in Firestore databaseIn the STEP 1, you can visualize your data with fixed conditions or interactively with UI functions on streamlit. Now we want it to update by itself.Firestore is a scalable NoSQL database, and it keeps your data in sync across client apps through real-time listeners. Firestore is available on Android and iOS, and also provides SDKs in major programming languages. Since we use streamlit in Python, let us use a Python client.In this post we don’t cover detailed usage of Firestore though, it is easy to implement a callback function that is called when a specific “Collection” has been changed. [reference]code_block[StructValue([(u’code’, u”from google.cloud import firestore_v1rnrndb = firestore_v1.Client()rncollection_ref = db.collection(u’users’)rnrndef on_snapshot(collection_snapshot, changes, read_time):rn for doc in collection_snapshot.documents:rn print(u'{} => {}’.format(doc.id, doc.to_dict()))rnrn# Watch this collectionrncollection_watch = collection_ref.on_snapshot(on_snapshot)”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e54b42658d0>)])]In this code, on_snapshot callback function is called when users Collection has been changed. You can also watch changes of Document.Since Firestore is a fully managed database, you would not need to provision the service ahead. You only need to choose “mode” and location. To use real-time sync functionality, select “Native mode”. Also select nearest or desired location.Using Firestore with streamlitNow let’s implement Firestore with streamlit. We add on_snapshot callback and update a chart with the latest data sent from Firestore. Here is one quick note when you use the callback function with streamlit. on_snapshot function is executed in a sub thread, instead UI manipulation in streamlit must be executed in a main thread. Therefore, we use Queue to sync the data between threads. The code will be something like below.code_block[StructValue([(u’code’, u’from queue import Queuernrnq = Queue()rndef on_snapshot(collection_snapshot, changes, read_time):rn for doc in collection_snapshot.documents:rn q.put(doc.to_dict()) # Put data into the Queuernrn# below will run in main threadrnsnap = st.empty() # placeholderrnrnwhile True:rn # q.get() is a blocking function. thus recommend to add timeoutrn doc = q.get() # Read from the Queuern snap.write(doc) # Change the UI’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e54a36850d0>)])]Deploy this app and write something in the collection you refer to. You will see the updated data on your webapp.Step 3: Plot a geospatial data with streamlitWe learned how to host web apps on Cloud Run, then how to update data with Firestore. Now we want to know how to plot geospatial data with streamlit. streamlit has multiple ways to plot geospatial data which includes latitude and longitude, we here used pydeck_plot(). This function is a wrapper of deck.gl, a geospatial visualization library.For example, provide data in latitude and longitude as to plot, add layers to visualize them.code_block[StructValue([(u’code’, u’import streamlit as strnimport pydeck as pdkrnimport pandas as pdrnimport numpy as nprnrndf = pd.DataFrame(rn np.random.randn(1000, 2) / [50, 50] + [37.76, -122.4],rn columns=[‘lat’, ‘lon’])rnst.pydeck_chart(pdk.Deck(rn map_provider=”carto”,rn map_style=’road’,rn initial_view_state=pdk.ViewState(rn latitude=37.76,rn longitude=-122.4,rn zoom=11,rn pitch=50,rn ),rn layers=[rn pdk.Layer(rn ‘HexagonLayer’,rn data=df,rn get_position='[lon, lat]’,rn radius=200,rn elevation_scale=4,rn elevation_range=[0, 1000],rn pickable=True,rn extruded=True,rn ),rn pdk.Layer(rn ‘ScatterplotLayer’,rn data=df,rn get_position='[lon, lat]’,rn get_color='[200, 30, 0, 160]’,rn get_radius=200,rn ),rn ],rn ))’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e54a3685750>)])]Plotting with pydeck_plot (Source)pydeck supports multiple map platforms. We here chose CARTO. If you would like to know more about great examples using CARTO and deck.gl, please refer to this blog.Step 4: Plot mobility dataWe are very close to the goal. Now we want to plot locations of vehicles. pydeck supports some ways to plot data, and TripsLayer would be a good fit to plot mobility data.Demo using Google Maps JavaScript API (Source)TripsLayer can visualize location data in time sequential. That means, when selecting a specific timestamp, it plots lines from location data in the time including last n periods. It also draws like an animation when you change the time in sequential order.In the final form, we also add IconLayer to identify the latest location. This layer is also useful when you want to plot a static location, and it just works like a “pin” on Google Maps.Now we need to think about how to use this plot with Firestore. Let’s make Document per vehicle, and only save the latest latitude, longitude, and timestamp of every vehicle. Why not save the history of locations? In that case, we should rather use BigQuery. We just want to see the latest locations that update in realtime.Firestore is useful and scalable, yet NoSQL. Note that there are some good fits and bad fits in NoSQL.Location data in Firestore ConsoleStep 5: RunFinally, we are here. Now let’s ride in a car and record data… if possible.For demo purposes, now we ingest dummy data into Firestore. It is easy to write data by using a client library.code_block[StructValue([(u’code’, u”db = firestore.Client()rncol_ref = db.collection(‘connected’)rncol_ref.document(str(vehicle_ind)).set({rn ‘lonlat': [-74, 40.72],rn ‘timestamp': 0rn})”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e54a350c950>)])]With writing dummy data, open the web page hosted on Cloud Run. you will see the map is updated upon new data coming.Firestore syncs data on streamlitNote that we used dummy data and manipulated the timestamps. Consequently, the location data updates much faster than actual time. This can be fixed once you use proper data and update cycle.Try it with your dataIn this post, we learned how to build a dashboard updated in real-time with Cloud Run and Firestore. Let us know when you find other use-cases with those nice Google Cloud products.Find out more automotive solutions here.Haven’t used Google Cloud yet? Try it from here.Check out the source code on GitHub.Related ArticleDiscover our new edge concepts at Hannover Messe that bring smart factories to lifeIntel and Google Cloud demonstrate edge-to-cloud technology at Hannover Messe.Read Article
Quelle: Google Cloud Platform