Successfully running your container images on a variety of CPU architectures can be tricky. For example, you might want to build your IoT application — running on an arm64 device like the Raspberry Pi — from a specific base image. However, Docker images typically support amd64 architectures by default. This scenario calls for a container image that supports multiple architectures, which we’ve highlighted in the past.
Multi-architecture (multi-arch) images typically contain variants for different architectures and OSes. These images may also support CPU architectures like arm32v5+, arm64v8, s390x, and others. The magic of multi-arch images is that Docker automatically grabs the variant matching your OS and CPU pairing.
While a regular container image has a manifest, a multi-architecture image has a manifest list. The list combines the manifests that show information about each variant’s size, architecture, and operating system.
Multi-architecture images are beneficial when you want to run your container locally on your x86-64 Linux machine, and remotely atop AWS Elastic Compute Cloud (EC2) Graviton2 CPUs. Additionally, it’s possible to build language-specific, multi-arch images — as we’ve done with Rust.
Follow along as we learn about each component behind multi-arch image builds, then quickly create our image using Buildx and Docker Desktop.
Building Multi-Architecture Images with Buildx and Docker Desktop
You can build a multi-arch image by creating the individual images for each architecture, pushing them to Docker Hub, and entering docker manifest to combine them within a tagged manifest list. You can then push the manifest list to Docker Hub. This method is valid in some situations, but it can become tedious and relatively time consuming.
Note: However, you should only use the docker manifest command in testing — not production. This command is experimental. We’re continually tweaking functionality and any associated UX while making docker manifest production ready.
However, two tools make it much easier to create multi-architectural builds: Docker Desktop and Docker Buildx. Docker Buildx enables you to complete every multi-architecture build step with one command via Docker Desktop.
Before diving into the nitty gritty, let’s briefly examine some core Docker technologies.
Dockerfiles
The Dockerfile is a text file containing all necessary instructions needed to assemble and deploy a container image with Docker. We’ll summarize the most common types of instructions, while our documentation contains information about others:
The FROM instruction headlines each Dockerfile, initializing the build stage and setting a base image which can receive subsequent instructions.
RUN defines important executables and forms additional image layers as a result. RUN also has a shell form for running commands.
WORKDIR sets a working directory for any following instructions. While you can explicitly set this, Docker will automatically assign a directory in its absence.
COPY, as it sounds, copies new files from a specified source and adds them into your container’s filesystem at a given relative path.
CMD comes in three forms, letting you define executables, parameters, or shell commands. Each Dockerfile only has one CMD, and only the latest CMD instance is respected when multiple exist.
Dockerfiles facilitate automated, multi-layer image builds based on your unique configurations. They’re relatively easy to create, and can grow to support images that require complex instructions. Dockerfiles are crucial inputs for image builds.
Buildx
Buildx leverages the docker build command to build images from a Dockerfile and sets of files located at a specified PATH or URL. Buildx comes packaged within Docker Desktop, and is a CLI plugin at its core. We consider it a plugin because it extends this base command with complete support for BuildKit’s feature set.
We offer Buildx as a CLI command called docker buildx, which you can use with Docker Desktop. In Linux environments, the buildx command also works with the build command on the terminal. Check out our Docker Buildx documentation to learn more.
BuildKit Engine
BuildKit is one core component within our Moby Project framework, which is also open source. It’s an efficient build system that improves upon the original Docker Engine. For example, BuildKit lets you connect with remote repositories like Docker Hub, and offers better performance via caching. You don’t have to rebuild every image layer after making changes.
While building a multi-arch image, BuildKit detects your specified architectures and triggers Docker Desktop to build and simulate those architectures. The docker buildx command helps you tap into BuildKit.
Docker Desktop
Docker Desktop is an application — built atop Docker Engine — that bundles together the Docker CLI, Docker Compose, Kubernetes, and related tools. You can use it to build, share, and manage containerized applications. Through the baked-in Docker Dashboard UI, Docker Desktop lets you tackle tasks with quick button clicks instead of manually entering intricate commands (though this is still possible).
Docker Desktop’s QEMU emulation support lets you build and simulate multiple architectures in a single environment. It also enables building and testing on your macOS, Windows, and Linux machines.
Now that you have working knowledge of each component, let’s hop into our walkthrough.
Prerequisites
Our tutorial requires the following:
The correct Go binary for your OS, which you can download here
The latest version of Docker Desktop
A basic understanding of how Docker works. You can follow our getting started guide to familiarize yourself with Docker Desktop.
Building a Sample Go Application
Let’s begin by building a basic Go application which prints text to your terminal. First, create a new folder called multi_arch_sample and move to it:
mkdir multi_arch_sample && cd multi_arch_sample
Second, run the following command to track code changes in the application dependencies:
go mod init multi_arch_sample
Your terminal will output a similar response to the following:
go: creating new go.mod: module multi_arch_sample
go: to add module requirements and sums:
go mod tidy
Third, create a new main.go file and add the following code to it:
package main
import (
"fmt"
"net/http"
)
func readyToLearn(w http.ResponseWriter, req *http.Request) {
w.Write([]byte("<h1>Ready to learn!</h1>"))
fmt.Println("Server running…")
}
func main() {
http.HandleFunc("/", readyToLearn)
http.ListenAndServe(":8000", nil)
}
This code created the function readyToLearn, which prints “Ready to learn!” at the 127.0.0.1:8000 web address. It also outputs the phrase Server running… to the terminal.
Next, enter the go run main.go command to run your application code in the terminal, which will produce the Ready to learn! response.
Since your app is ready, you can prepare a Dockerfile to handle the multi-architecture deployment of your Go application.
Creating a Dockerfile for Multi-arch Deployments
Create a new file in the working directory and name it Dockerfile. Next, open that file and add in the following lines:
# syntax=docker/dockerfile:1
# specify the base image to be used for the application
FROM golang:1.17-alpine
# create the working directory in the image
WORKDIR /app
# copy Go modules and dependencies to image
COPY go.mod ./
# download Go modules and dependencies
RUN go mod download
# copy all the Go files ending with .go extension
COPY *.go ./
# compile application
RUN go build -o /multi_arch_sample
# network port at runtime
EXPOSE 8000
# execute when the container starts
CMD [ "/multi_arch_sample" ]
Building with Buildx
Next, you’ll need to build your multi-arch image. This image is compatible with both the amd64 and arm32 server architectures. Since you’re using Buildx, BuildKit is also enabled by default. You won’t have to switch on this setting or enter any extra commands to leverage its functionality.
The builder builds and provisions a container. It also packages the container for reuse. Additionally, Buildx supports multiple builder instances — which is pretty handy for creating scoped, isolated, and switchable environments for your image builds.
Enter the following command to create a new builder, which we’ll call mybuilder:
docker buildx create –name mybuilder –use –bootstrap
You should get a terminal response that says mybuilder. You can also view a list of builders using the docker buildx ls command. You can even inspect a new builder by entering docker buildx inspect <name>.
Triggering the Build
Now, you’ll jumpstart your multi-architecture build with the single docker buildx command shown below:
docker buildx build –push
–platform linux/amd64,linux/arm64
–tag your_docker_username/multi_arch_sample:buildx-latest .
This does several things:
Combines the build command to start a build
Shares the image with Docker Hub using the push operation
Uses the –platform flag to specify the target architectures you want to build for. BuildKit then assembles the image manifest for the architectures
Uses the –tag flag to set the image name as multi_arch_sample
Once your build is finished, your terminal will display the following:
[+] Building 123.0s (23/23) FINISHED
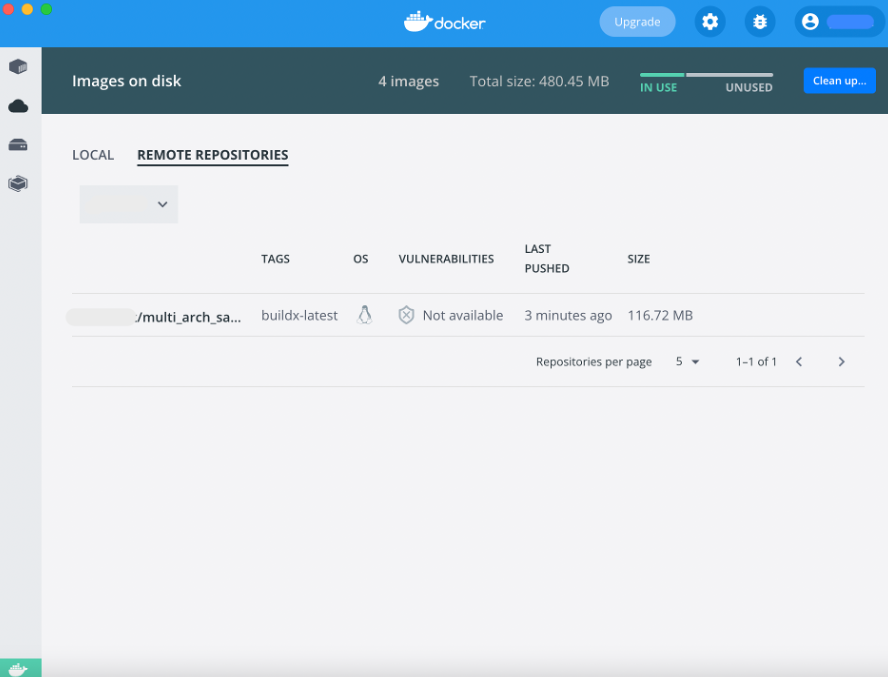
Next, navigate to the Docker Desktop and go to Images > REMOTE REPOSITORIES. You’ll see your newly-created image via the Dashboard!
Conclusion
Congratulations! You’ve successfully explored multi-architecture builds, step by step. You’ve seen how Docker Desktop, Buildx, BuildKit, and other tooling enable you to create and deploy multi-architecture images. While we’ve used a sample Go web application, you can apply these processes to other images and applications.
To tackle your own projects, learn how to get started with Docker to build more multi-architecture images with Docker Desktop and Buildx. We’ve also outlined how to create a custom registry configuration using Buildx.
Quelle: https://blog.docker.com/feed/