Verkaufsräume: Vietnamesische E-Autos kommen nach Deutschland
Vinfast will 50 Läden in Deutschland, Frankreich und den Niederlanden eröffnen, um dort die Elektroautos des Unternehmens zu verkaufen. (Elektroauto, Auto)
Quelle: Golem

Vinfast will 50 Läden in Deutschland, Frankreich und den Niederlanden eröffnen, um dort die Elektroautos des Unternehmens zu verkaufen. (Elektroauto, Auto)
Quelle: Golem

Führungskräfte in der IT fallen nicht einfach vom Himmel. Dabei sind sie im Unternehmen unerlässlich. Damit Arbeitnehmer wie Arbeitgeber profitieren, sind passende fachliche und persönliche Qualifikationen gefragt. (Golem Karrierewelt, Internet)
Quelle: Golem

ONE will Akkukapazität von Elektroautos mit allen Mitteln verdoppeln und kann das auch schaffen. Fraglich ist, ob die Technik das richtige Ziel hat. Von Frank Wunderlich-Pfeiffer (Elektromobilität, Elektroauto)
Quelle: Golem
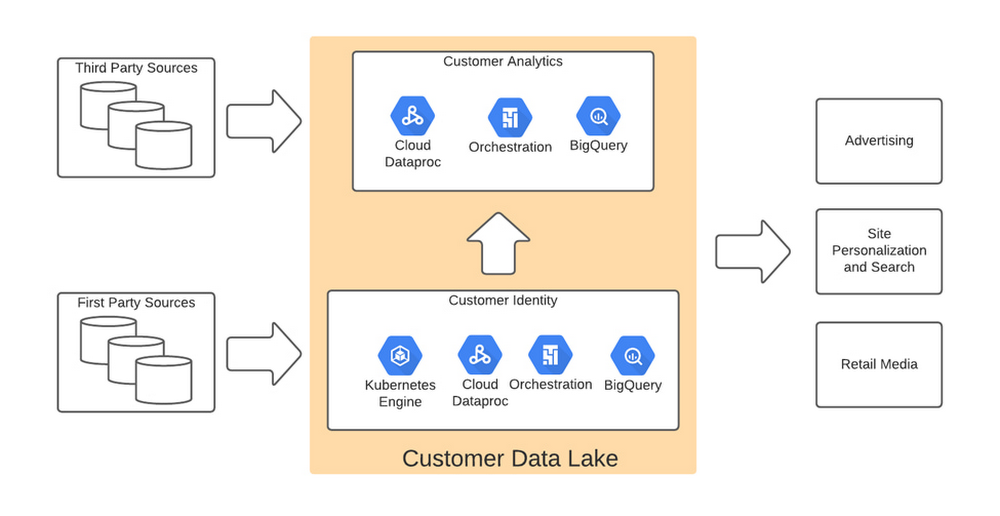
The Home Depot, Inc., is the world’s largest home improvement retailer with annual revenue of over $151B. Delighting our customers—whether do-it-yourselfers or professionals—by providing the home improvement products, services, and equipment rentals they need, when they need them, is key to our success. We operate more than 2,300 stores throughout the United States, Canada, and Mexico. We also have a substantial online presence through HomeDepot.com, which is one of the largest e-commerce platforms in the world in terms of revenue. The site has experienced significant growth both in traffic and revenue since the onset of Covid-19.Because many of our customers shop at both our brick-and-mortar stores and online, we’ve embarked on a multi-year strategy to offer a shopping experience that seamlessly bridges the physical and digital worlds. To maximize value for the increasing number of online shoppers, we’ve shifted our focus from event marketing to personalized marketing, as we found it to be far more effective in improving the customer experience throughout the sales journey. This led to changing our approach to marketing content, email communications, product recommendations, and the overall website experience.Challenge: launching a modern marketing strategy using legacy ITFor personalized marketing to be successful, we had to improve our ability to recognize a customer at the point of transaction so we could—among other things—suspend irrelevant and unnecessary advertising. Most of us have experienced the annoyance of receiving ads for something we’ve already purchased, which can degrade our perception of the brand itself. While many online retailers can identify 100% of their customer transactions due to the rich information captured during checkout, most of our transactions flow through physical stores, making this a more difficult problem to solve.Our old legacy IT system, which ran in an on-premises data center and leveraged Hadoop, also challenged us since maintaining both the hardware and software stack required significant resources. When that system was built, personalized marketing was not a priority, so it took several days to process customer transaction data and several weeks to roll out any system changes. Further, managing and maintaining the large Hadoop cluster base presented its own set of issues in terms of quality control and reliability, as did keeping up with open-source community updates for each data processing layer. Adopting a hybrid approachAs we worked through the challenges of our legacy system, we started thinking about what we wanted our future system to look like. Like many companies, we began with a “build vs. buy” analysis. We looked at several products on the market and determined that while each of them had their strengths, none was able to offer the complete set of features we needed.Our project team didn’t think it made sense to build a solution from scratch, nor did we have access to the third-party data we needed. After much consideration, we decided to adopt a solution that combined a complete rewrite of the legacy system with the support of a partner to help with the customer transaction matching process.Building the foundation on Google CloudWe chose Google Cloud’s data platform, specifically BigQuery, Dataflow, DataProc, Cloud Storage, and Cloud Composer. Google Cloud platform empowered us to break down data silos and unify each stage of the data lifecycle from ingestion, storage, and processing to analysis and insights. Google Cloud offered best-in-class integration with open-source standards and provided the portability and extensibility we needed to make our hybrid solution work well. The open standards of BigQuery’s BQ Storage API allowed us to leverage fast BQ storage layers to be utilized with other compute platforms, e.g., DataProc. We used BigQuery combined with Dataflow to integrate our first- and third-party data into an enterprise data and analytics data lake architecture. The system then combined previously siloed data and used BigQuery ML to create complete customer profiles spanning the entire shopping experience, both in-store and online. Understanding the customer journey with the help of Dataflow and BigQueryThe process of developing customer profiles involves aggregating a number of first- and third-party data sources to create a 360-degree view of the customer based on both their history and intent. It starts with creating a single historical customer profile through data aggregation, deduplication, and enrichment. We used several vendors to help with customer resolution and NCOA (Change of Address) updates, which allows the profile to be house-holded and transactions to be properly reconciled to both the individual and the household. This output is then matched to different customer signals to help create an understanding of where the customer is in their journey—and how we can help.The initial implementation used Google Dataflow, Google’s streaming analytics solution, to load data from Google Cloud Storage into BigQuery and perform all necessary transformations. The Dataflow process was converted into BQML (BigQuery Machine Learning) since this significantly reduced costs and increased visibility into data jobs. We used Google Cloud Composer, a fully managed workflow orchestration service, to help orchestrate all data operations and DataProc and Google Kubernetes Engine to enable special case data integration so we could quickly pivot and test new campaigns. The architecture diagram below shows the overall structure of our solution.Taking full advantage of cloud-native technology In our initial migration to Google Cloud, we moved most of our legacy processes in their original form. However, we quickly learned that this approach didn’t take full advantage of the cloud-native and more improved features Google Cloud offered such as auto scaling of resources, flexibility to decouple storage from the compute layer, and a wide variety of options to choose the best tool for the job. We refactored our Hadoop-based data pipelines written in Java-based Map Reduce and our Pig Latin jobs to Dataflow and BigQuery jobs. This dramatically reduced processing time and made our data pipeline code concise and efficient. Previously, our legacy system processes ran longer than intended, and data was not used efficiently. Optimizing our code to be cloud-native and leveraging all the capabilities of Google Cloud services resulted in reduced run times. We decreased our data processing window from 3 days to 24 hours, improved resource usage by dramatically reducing the amount of compute we used to possess this data, and built a more streamlined system. This in turn reduced cloud costs and provided better insight. For example, DataFlow offers powerful native features to monitor data pipelines, enabling us to be more agile.Leveraging the flexibility and speed of the cloud to improve outcomes Today, using a continuous integration/continuous delivery (CI/CD) approach, we can deploy multiple system changes each week to further improve our ability to recognize in-store transactions. Leveraging the combined capabilities of various Google Cloud systems—BigQuery, DataFlow, Cloud Composer, Dataproc, and Cloud Storage–we drastically increased our ability to recognize transactions and can now connect over 75% of all transactions to an existing household. Further, the flexible Google Cloud environment coupled with our cloud-native application makes our team more nimble and better able to respond to emerging problems or new opportunities. Increased speed has led to better outcomes in our ability to match transactions across all sales channels to a customer and thereby improve their experience. Before moving to Google Cloud, it took 48 to 72 hours to match customers to their transactions, but now we can do it in less than 24 hours. Making marketing more personal—and more efficientThe ability to quickly match customers to transactions has huge implications for our downstream marketing efforts in terms of both cost and effectiveness. By knowing what a customer has purchased, we can turn off ads for products they’ve already bought or offer ads for things that support what they’ve bought recently. This helps us use our marketing dollars much more efficiently and offer an improved customer experience. Additionally, we can now apply the analytical models developed using BQML and Vertex AI to sort customers into audiences. This allows us to more quickly identify a customer’s current project, such as remodeling a kitchen or finishing a basement, and then personalize their journey by offering them information on products and services that matter most at a given point through our various marketing channels. This provides customers with a more relevant and customized shopping journey that mirrors their individual needs. Protecting a customer’s privacyWith this ability to better understand our customers, we also have the responsibility to ensure we have good oversight and maintain their data privacy. Google’s cloud solutions provide us the security needed to help protect our customers’ data, while also being flexible enough to allow us to support state and federal regulations, like the California Customer Privacy Act. This way we can provide a customer the personalized experience they desire without having to fear how their data is being used.With flexible Google Cloud technology in place, The Home Depot is well positioned to compete in an industry where customers have many choices. By putting our customers’ needs first, we can stay top of mind whenever the next project comes up.Related ArticleHow The Home Depot helps doers get more done with SAP and Google CloudThe Home Depot’s decision to migrate to cloud-based infrastructure, including migrating its SAP applications, has set it up for success i…Read Article
Quelle: Google Cloud Platform
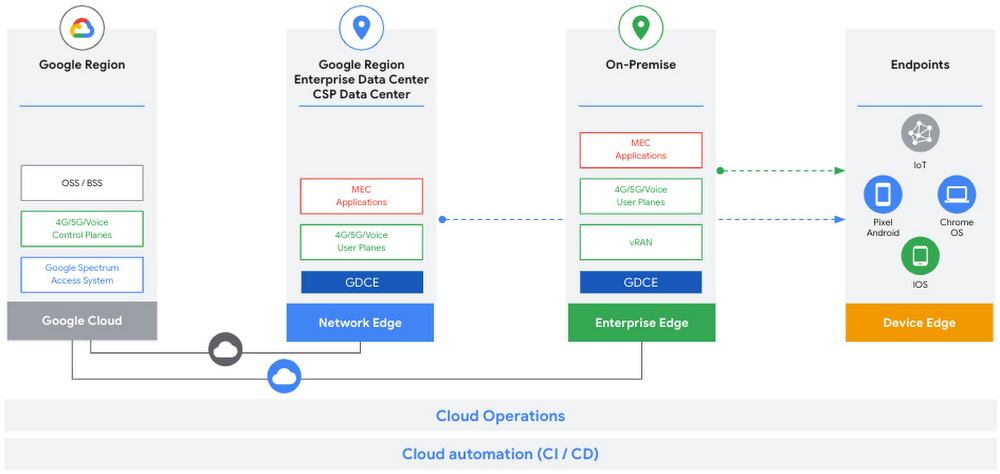
Today, we’re announcing a new private networking solutions portfolio to further accelerate adoption of private cellular networks. Based on Google Distributed Cloud Edge and leveraging our ISV ecosystem, these solutions address the distinct performance, service-level, and economic needs of key industry verticals by combining dedicated network capabilities with full edge-computing application stacks.Enterprises today are facing a network coverage and quality of service challenge that strains existing solutions like WiFi. Whether being used to add users, deploy industry-specific workloads, or support Internet of Things (IoT) and other connected devices, existing networking solutions struggle to deliver the connectivity, control, and scalability that enterprises need. Private networks based on cellular technologies like 5G offer a variety of benefits over WiFi for several enterprise use cases. For example, WiFi can be noisy and deliver inconsistent performance in terms of both latency and bandwidth, which impacts its ability to deliver the Quality of Service (QoS) you need for real-time applications like video monitoring and robotic manufacturing. It’s also hard to use WiFi to provide capacity and coverage in large areas like entertainment venues, nor is WiFi well suited for connecting large numbers of sensors and IoT devices. And in places where a connected device is on the move, like in a warehouse or distribution center, WiFi doesn’t offer the seamless connectivity that workers and vehicles require. Private networks, meanwhile, allow organizations to introduce local private cellular networks to complement existing WiFi and public cellular connectivity. For example, manufacturers can deploy a private network across a large factory site bridging operations, automation, and IoT devices, with robust baseline connectivity and support for next-generation functionality such as predictive maintenance and quality control through computer vision analytics. For educators, private networks can extend connectivity to underserved communities and students, enabling distance learning outside the classroom. Building and venue owners can use private networks to improve occupant safety, reduce costs and lower energy consumption via smart-building applications, and deliver new occupant and visitor experiences. And critically, cellular networks’ built-in security provides peace of mind for data privacy in a way that other approaches do not.A flexible, mature solutionMany enterprises have been experimenting with private networks but operating and scaling them presents numerous challenges. With this new portfolio, built upon Google Distributed Cloud (GDC) Edge and new key partnerships, customers can rapidly adopt turn-key, private network solutions with the flexibility to deploy management, control, and user plane functions both in the cloud and at the edge. GDC Edge has access to Google Cloud services and is backed by Google’s security best practices. By building on a mature, cloud-native management experience, powered by Anthos, enterprises benefit from a consistent developer and operational model across their entire IT estate. In addition, Distributed Cloud Edge offers the flexibility to scale to other use cases that need low latency and Quality of Service (QoS) for critical applications.Every enterprise has unique topography, latency and QoS requirements for their applications. Google Distributed Cloud Edge provides a centralized control and management plane for secure networks, scaling from one to thousands of locations. With GDC Edge, customers can run private networks including virtualized RAN for connectivity and edge applications in a single solution. Our partnerships with Communications Service Providers (CSPs) further enable enterprises with roaming connectivity while retaining control of their private environments.A broad ecosystem of partnersGiven the variety of needs across different industries, we are working with key ISV ecosystem partners to deliver integrated solutions built on our GDC Edge portfolio combined with their own distinct solutions. Our launch partners include:Betacom will deploy its fully managed private wireless service, 5G as a Service (5GaaS), on GDC Edge, giving enterprises access to cost-effective, high-performance 5G networks that are designed, deployed and managed to support new intelligent manufacturing applications. Boingo Wireless will deploy its fully managed, end-to-end private cellular networks for enterprise customers using GDC Edge at major airports, stadiums, hospitals, manufacturing facilities, and U.S. military bases. Celona’s 5G LAN solution automates rollout of private cellular networks that are tightly integrated with existing security and app QoS policies. Celona’s 5G LAN network operating system can also be deployed as a resource within GDC Edge, further accelerating private cellular adoption. Crown Castle owns and operates communications infrastructure, including wireless infrastructure and fiber networks, that serves the demands of telecommunications network operators, enterprises, and the public sector, and seeks to enable the next wave of deployments with partners leveraging GDC Edge for private network deployments. Kajeet will deploy its 5G solution on GDC Edge with a mission to connect students and communities with safe, simple, and secure high-speed wireless Internet to eliminate the digital divide once and for all.Several countries including the US, UK, Germany, Japan, and South Korea allocate spectrum for private networking, and CSPs have spectrum that can be extended for private use as well. In the US, private network solution partners can also utilize our Spectrum Access System (SAS) to leverage the Citizens Broadband Radio Service (CBRS). Google Cloud has led the way in this space, laying the foundation for low-friction private network deployments by promoting industry-wide adoption of CBRS, and by operating a market-leading SAS. Get started todayThe network is the backbone of any business, and running a private network solution on Google Distributed Cloud Edge opens the door to new use cases predicated on fast, flexible and secure connectivity. Click here to learn more about Google Distributed Cloud Edge, and check out the news releases from our partners Betacom, Celona, and Kajeet. And if you want to become a private 5G solution early adopter, reach out to us at private-networks@google.com.Related ArticleDeploying and operating cloud-based 5G networksCloud services and networks can help Communication Service Providers (CSPs) deliver next-generation 5G networks to their customers quickly.Read Article
Quelle: Google Cloud Platform
Learning how to install and manage Kubernetes clusters can be a big obstacle between your organization and all the potential magic of a container orchestration platform. You have to consider tasks like provisioning machines, choosing OS and runtime, and setting up networking and security. Plus, integrating it all correctly and understanding it well enough to roll out new updates can take months (if not, years). When adopting containers, you should always ask yourself: Does my startup or tech company have the skills, resources, and time to maintain, upgrade, and secure my platform?If the answer is no, you can instead use a fully-managed Kubernetes service. If you’re on AWS, that would mean EKS. If you’re on Azure, that will mean AKS. And if you’re on Google Cloud, that will mean Google Kubernetes Engine (GKE).This post examines the benefits of managed container platforms covered in our recent whitepaper, “The future of infrastructure will be containerized,” which is informed by our work with startups and tech companies choosing Google Cloud.The benefits of embracing managed servicesGoing for a fully-managed service has many positive implications for your business that can help you keep moving forward as efficiently as possible. Firstly, a fully-managed container service eliminates most of the Kubernetes platform operational overhead. For instance, GKE offers fully-integrated IaaS ranging from VM provisioning of Tau VMs, autoscaling across multiple zones, and on-demand upgrades for GPUs, TPUs for machine learning, storage volumes, and security credentials. Simply put your application into a container and select the system that works best for your needs.If you don’t want the responsibility of provisioning, scaling, and upgrading clusters, you can opt for the production-ready GKE Autopilot mode that manages your cluster infrastructure, control plane, and nodes. For cases where you don’t need total control over container orchestration and operations, you can simplify app delivery by leveraging a managed serverless compute platform like Cloud Run. While GKE is a fully-managed service, you still need to think about key decisions, such as which zones to run in, where to store logs, and how to manage traffic between different application versions. Cloud Run eliminates all of those decisions, allowing you to run cloud native workloads and scale based on incoming requests without having to configure or manage a Kubernetes cluster. Using Cloud Run also lets your teams focus on more impactful work: developers can focus more on writing code; and rather than dedicating lots of time to automation or operational tasks, DevOps engineers and cloud system admins can instead focus on application performance, security, compliance, API integration. Beyond easing the management of containers, managed services also help ease other aspects of operating in today’s modern digital world, such as the increasing need to operate in multiple clouds. Being able to mix and match providers that work best for individual workloads is key for making the best use of existing assets, increasing flexibility and resilience, and leveraging new technologies and capabilities in the future. And when it comes to implementing a multicloud strategy, the migrations that work best are those that leverage open standards. Let’s say, for example, that AWS is your cloud provider for your VMs. You can manage and maintain any Kubernetes clusters you have, no matter where they are, using GKE Connect. And because GKE has a provider-agnostic API, you can build tooling and workflows once and deploy them across multiple clouds while making updates from a single, central platform. With Kubernetes, your startup or tech company can save huge amounts of time on deployments and automation without having to build and maintain separate infrastructures for each individual cloud provider.Always be building towards an open future Containers and managed services based on open standards are a powerful combination that allow you to take advantage of best-of-breed capabilities on any platform, while simultaneously standardizing skills and processes. As a leader at a startup or tech company, you’re always looking for ways to move faster, work more efficiently, and make the most of the technical talent you have. You want to spend more time on roadmap priorities and spend the minimum amount of resources on maintaining your infrastructure. When you choose open platforms and technology, you are ensuring that your team and business will have a front-row seat to cutting-edge innovations that will deliver new ways to build great products. Plus, developers and engineers want to work with systems and projects where they can have transferable versus proprietary systems, and where they can enrich their career development. To learn more about how containers and Kubernetes can help you get to market faster, we highly recommend reading our previous post on this whitepaper, and for a deeper dive into how managed containers can help streamline app development in the cloud, read the full whitepaper. To learn more about how startups and tech companies are working with Google Cloud, check out this post or visit the Google Cloud page for startups and tech companies.Related ArticleHow tech companies and startups get to market faster with containers on Google CloudGoogle Cloud’s whitepaper explores how startups and tech companies can move faster with a managed container platformRead Article
Quelle: Google Cloud Platform
The Cloud DNS team is pleased to announce the Preview launch of managed zone permissions. Cloud DNS is integrated with the Identity and Access Management (IAM) service, which gives you the ability to control access to Cloud DNS resources and prevent unwanted access. This launch enables enterprises with distributed DevOps teams to delegate Cloud DNS managed zone administration to their individual application teams. Up until now, Cloud DNS supported resource permissions at the project level only. This allowed for centralized management of IAM permissions at a higher level of granularity. Any user with a specific permission in a project would have that permission apply to all the resources under it. If the project contained multiple managed zones for instance, a single user with project access could make changes to the DNS records in any of the managed zones in that project. This created two challenges for some customers: It resulted in the reliance on a centralized team to manage all the DNS zones and record creations. This is usually fine when the deployment sizes are small. However for customers with a large number of managed DNS zones, administration becomes a toil usually borne by the central team.A single user could modify the DNS records in multiple managed zones, resulting in either broken DNS records or causing security issues. With this launch, Cloud DNS will allow access controls at a finer granularity at a managed zone level. This allows admins to delegate responsibilities for managed zone operations to individual application teams and prevents one application team from accidentally changing the DNS records of another application. It also allows for a better security posture because only authorized users will be able to modify managed zones and better supports the principle of least privilege. The launch does not change the IAM roles and permissions; we’ve merely added additional granularity to use when needed. For more details on IAM roles for Cloud DNS, please see Access control with IAM.This capability also helps when customers are using a Shared VPC environment. A typical Shared VPC setup has service projects that take ownership of a virtual machine (VM) application or services, while the host project takes ownership of the VPC network and network infrastructure. Often, a DNS namespace is created from the VPC network’s namespace to match the service project’s resources. For such a setup, it can be easier to delegate the administration of each service project’s DNS namespace to the administrators of each service project (which are often different departments or businesses). Cross-project binding lets you separate the ownership of the DNS namespace of the service project from the ownership of the DNS namespace of the entire VPC network. This, coupled with managed zone permissions, ensures that the managed zone within the service project can only be administered by service project owners while allowing for the host project (and other service projects) to access the namespace from their respective projects. For more details on how to configure and use managed zone permissions, please look at our documentation.Related ArticleAnnouncing private network solutions on Google Distributed Cloud EdgeWith a private cellular network running on Google Distributed Cloud Edge, enterprises can solve the connectivity problems of many new use…Read Article
Quelle: Google Cloud Platform

Testing is an important exercise in the life cycle of developing a machine learning system to ensure high-quality operations. We use tests to confirm that something functions as it should. Once tests are created, we can run them automatically whenever we make a change to our system and continue to improve them over time. It is a good practice to reward the implementation of tests and identify sources of mistakes as early as possible in the development cycle to prevent rising downstream expenses and lost time.
In this blog, we will look at testing machine learning systems from a Machine Learning Operations (MLOps) perspective and learn about good case practices and a testing framework that you can use to build robust, scalable, and secure machine learning systems. Before we delve into testing, let’s see what MLOps is and its value to developing machine learning systems.
Figure 1: MLOps = DevOps + Machine Learning.
Software development is interdisciplinary and is evolving to facilitate machine learning. MLOps is a process for fusing machine learning with software development by coupling machine learning and DevOps. MLOps aims to build, deploy, and maintain machine learning models in production reliably and efficiently. DevOps drives machine learning operations. Let’s look at how that works in practice. Below is an MLOps workflow illustration of how machine learning is enabled by DevOps to orchestrate robust, scalable, and secure machine learning solutions.
Figure 2: MLOps workflow.
The MLOps workflow is modular, flexible, and can be used to build proofs of concept or operationalize machine learning solutions in any business or industry. This workflow is segmented into three modules: Build, Deploy, and Monitor. Build is used to develop machine learning models using an machine learning pipeline. The Deploy module is used for deploying models in developer, test, and production environments. The Monitor module is used to monitor, analyze, and govern the machine learning system to achieve maximum business value. Tests are performed primarily in two modules: the Build and Deploy modules. In the Build module, data is ingested for training, the model is trained using ingested data, and then it is tested in the model testing step.
1. Model testing: In this step, we evaluate the performance of the trained model on a separated set of data points named test data (which was split and versioned in the data ingestion step). The inference of the trained model is evaluated according to selected metrics as per the use case. The output of this step is a report on the trained model's performance. In the Deploy module, we deploy the trained models to dev, test, and production environments, respectively. First, we start with application testing (done in dev and test environments).
2. Application testing: Before deploying an machine learning model to production, it is vital to test the robustness, scalability, and security of the model. Hence, we have the "application testing" phase, where we rigorously test all the trained models and the application in a production-like environment called a test, or staging, environment. In this phase, we may perform tests such as A/B tests, integration tests, user acceptance tests (UAT), shadow testing, or load testing.
Below is the framework for testing that reflects the hierarchy of needs for testing machine learning systems.
Figure 3: Hierarchy of needs for testing machine learning systems.
One way to think about machine learning systems is to consider Maslow's hierarchy of needs. Lower levels of a pyramid reflect “survival,” and the true human potential is unleashed only after basic survival and emotional needs are met. Likewise, tests that inspect robustness, scalability, and security ensure that the system not only performs at the basic level but reaches its true potential. One thing to note is that there are many additional forms of functional and nonfunctional testing, including smoke tests (rapid health checks) and performance tests (stress), but they may all be classified as system tests.
Over the next three posts, we’ll cover each of the three broad levels of testing, starting with robustness and then moving on to scalability and finally, security.
For further details and to learn about hands-on implementation, check out the Engineering MLOps book, or learn how to build and deploy a model in Microsoft Azure Machine Learning using MLOps in the Get Time to Value with MLOps Best Practices on-demand webinar.
Source for images: Engineering MLOps book
Quelle: Azure

As the cloud continues to expand into a ubiquitous and highly distributed fabric, a new breed of application is emerging: Modern Connected Applications. We define these new offerings as network-intelligent applications at the edge, powered by 5G, and enabled by programmable interfaces that give developer access to network resources. Along with internet of things (IoT) and real-time AI, 5G is enabling this new app paradigm, unlocking new services and business models for enterprises, while accelerating their network and IT transformation.
At Mobile World Congress this year, Microsoft announced a significant step towards helping enterprises in this journey: Azure Private 5G Core, available as a part of the Azure private multi-access edge compute (MEC) solution. Azure Private 5G Core enables operators and system integrators (SIs) to provide a simple, scalable, and secure deployment of private 4G and 5G networks on small footprint infrastructure, at the enterprise edge.
This blog dives a little deeper into the fundamentals of the service and highlights some extensions that enterprises can leverage to gain more visibility and control over their private network. It also includes a use case of an early deployment of Azure Kubernetes Services (AKS) on an edge platform, leveraged by the Azure Private 5G Core to rapidly deploy such networks.
Building simple, scalable, and secure private networks
Azure Private 5G Core dramatically simplifies the deployment and operation of private networks. With just a few clicks, organizations can deploy a customized set of selectable 5G core functions, radio access network (RAN), and applications on a small edge-compute platform, at thousands of locations. Built-in automation delivers security patches, assures compliance, and performs audits and reporting. Enterprises benefit from a consistent management experience and improved service assurance experience, with all logs and metrics from cloud to edge available for viewing within Azure dashboards.
Enterprises need the highest level of security to connect their mission critical operations. Azure Private 5G Core makes this possible by natively integrating into a broad range of Azure capabilities. With Azure Arc, we provide seamless and secure connectivity from an on-premises edge platform into the Azure cloud. With Azure role-based access control (RBAC), administrators can author policies and define privileges that will allow an application to access all necessary resources. Likewise, users can be given appropriate access to manage all resources in a resource group, such as virtual machines, websites, and subnets. Our Zero Trust security frameworks are integrated from devices to the cloud to keep users and data secure. And our complete, “full-stack” solution (hardware, host and guest operating system, hypervisor, AKS, packet core, IoT Edge Runtime for applications, and more) meets standard Azure privacy and compliance benchmarks in the cloud and on the enterprise edge, meaning that data privacy requirements are adhered to in each geographic region.
Deploying private 5G networks in minutes
Microsoft partner Inventec is a leading design manufacturer of enterprise-class technology solutions like laptops, servers, and wireless communication products. The company has been quick to see the potential benefit in transforming its own world-class manufacturing sites into 5G smart factories to fully utilize the power of AI and IoT.
In a compelling example of rapid private 5G network deployment, Inventec recently installed our Azure private MEC solution in their Taiwan smart factory. It took only 56 minutes to fully deploy the Azure Private 5G Core and connect it to 5G access points that served multiple 5G endpoints—a significant reduction from the months that enterprises have come to expect. Azure Private 5G Core leverages Azure Arc and Azure Kubernetes Service on-prem to provide security and manageability for the entire core network stack. Figures 1 and 2 below show snapshots from the trial.
Figure 1: Screenshot of logs with time stamps showing start and completion of the core network deployment.
Figure 2: Screenshot from the trial showing one access point successfully connected to seven endpoints.
Inventec is developing applications for manufacturing use-cases that leverage private 5G networks and Microsoft’s Azure Private 5G Core. Examples of these high-value MEC use cases include Automatic Optical Inspection (AOI), facial recognition, and security surveillance systems.
Extending enterprise control and visibility from the 5G core
Through close integration with other elements of the Azure private MEC solution, our Azure Private 5G Core essentially acts as an enterprise “control point” for private wireless networks. Through comprehensive APIs, the Azure Private 5G Core can extend visibility into the performance of connected network elements, simplify the provisioning of subscriber identity modules (SIMs) for end devices, secure private wireless deployments, and offer 5G connectivity between cloud services (like IoT Hub) and associated on-premises devices.
Figure 3: Azure Private 5G Core is a central control point for private wireless networks.
Customers, developers, and partners are finding value today with a number of early integrations with both Azure and third-party services that include:
Plug and play RAN: Azure private MEC offers a choice of 4G or 5G Standalone radio access network (RAN) partners that integrate directly with the Azure Private 5G Core. By integrating RAN monitoring with the Azure Private 5G Core, RAN performance can be made visible through the Azure management portal. Our RAN partners are also onboarding their Element Management System (EMS) and Service Management and Orchestrator (SMO) products to Azure, simplifying the deployment processes and have a framework for closed-loop radio performance automation.
Azure Arc managed edge: The Azure Private 5G Core takes advantage of the security and reliability capabilities of Azure Arc-enabled Azure Kubernetes Service running on Azure Stack Edge Pro. These include policy definitions with Azure Policy for Kubernetes, simplified access to AKS clusters for High Availability with Cluster Connect and fine-grained identity and access management with Azure RBAC.
Device and Profile Management: Azure Private 5G Core APIs integrate with SIM management services to securely provision the 5G devices with appropriate profiles. In addition, integration with Azure IoT Hub enables unified management of all connected IoT devices across an enterprise and provides a message hub for IoT telemetry data.
Localized ISV MEC applications: Low-latency MEC applications benefit from running side-by-side with core network functions on the common (Azure private MEC) edge-compute platform. By integrating tightly with the Azure Private 5G Core using Azure Resource Manager APIs, third-party applications can configure network resources and devices. Applications offered by partners are available in, and deployable from the Azure Marketplace.
It’s easy to get started with Azure private MEC
As innovative use cases for private wireless networks continue to develop and industry 4.0 transformation accelerates, we welcome ISVs, platform partners, operators, and SIs to learn more about Azure private MEC.
Application ISVs interested in deploying their industry or horizontal solutions on Azure should begin by onboarding their applications to Azure Marketplace.
Platform partners, operators, and SIs interested in partnering with Microsoft to deploy or integrate with private MEC can get started by reaching out to the Azure private MEC Team.
Microsoft is committed to helping organizations innovate from the cloud, to the edge, and to space—offering the platform and ecosystem strong enough to support the vision and vast potential of 5G. As the cloud continues to expand and a new breed of modern connected apps at the edge emerges, the growth and transformation opportunities for enterprises will be profound. Learn more about how Microsoft is helping developers embrace 5G.
Quelle: Azure

Getting an idea, planning it out, implementing your Rust code, and releasing the final build is a long process full of unexpected issues. Cross compilation of your code will allow you to reach more users, but it requires knowledge of building executables for different runtime environments. Luckily, this post will help in getting your Rust application running on multiple architectures, including x86 for Windows.
Overview
You want to vet your idea with as many users as possible, so you need to be able to compile your code for multiple architectures. Your users have their own preferences on what machines and OS to use, so we should do our best to meet them in their preferred set-up. This is why it’s critical to pick a language or framework that lends itself to support multiple ways to export your code for multiple target environments with minimal developer effort. Also, it’d be better to have tooling in place to help automate this export process.
If we invest some time in the beginning to pick the right coding language and automation tooling, then we’ll avoid the headaches of not being able to reach a wider audience without the use of cumbersome manual steps. Basically, we need to remove as many barriers as possible between our code and our audience.
This post will cover building a custom Docker image, instantiating a container from that image, and finally using that container to cross compile your Rust code. Your code will be compiled, and an executable will be created for your target environment within your working directory.
What You’ll Need
Your Rust code (to help you get started, you can use the source code from this git repo)
The latest version of Docker Desktop
Getting Started
My Rust directory has the following structure:
.
├── Cargo.lock
├── Cargo.toml
└── src
└── main.rs
The lock file and toml file both share the same format. The lock file lists packages and their properties. The Cargo program maintains the lock file, and this file should not be manually edited. The toml file is a manifest file that specifies the metadata of your project. Unlike the lock file, you can edit the toml file. The actual Rust code is in main.rs. In my example, the main.rs file contains a version of the game Snake that uses ASCII art graphics. These files run on Linux machines, and our goal is to cross compile them into a Windows executable.
The cross compilation of your Rust code will be done via Docker. Download and install the latest version of Docker Desktop. Choose the version matching your workstation OS — and remember to choose either the Intel or Apple (M-series) processor variant if you’re running macOS.
Creating Your Docker Image
Once you’ve installed Docker Desktop, navigate to your Rust directory. Then, create an empty file called Dockerfile within that directory. The Dockerfile will contain the instructions needed to create your Docker image. Paste the following code into your Dockerfile:
FROM rust:latest
RUN apt update && apt upgrade -y
RUN apt install -y g++-mingw-w64-x86-64
RUN rustup target add x86_64-pc-windows-gnu
RUN rustup toolchain install stable-x86_64-pc-windows-gnu
WORKDIR /app
CMD ["cargo", "build", "–target", "x86_64-pc-windows-gnu"]
Setting Up Your Image
The first line creates your image from the Rust base image. The next command upgrades the contents of your image’s packages to the latest version and installs mingw, an open source program that builds Windows applications.
Compiling for Windows
The next two lines are key to getting cross compilation working. The rustup program is a command line toolchain manager for Rust that allows Rust to support compilation for different target platforms. We need to specify which target platform to add for Rust (a target specifies an architecture which can be compiled into by Rust). We then install that toolchain into Rust. A toolchain is a set of programs needed to compile our application to our desired target architecture.
Building Your Code
Next, we’ll set the working directory of our image to the app folder. The final line utilizes the CMD instruction in our running container. Our command instructs Cargo, the Rust build system, to build our Rust code to the designated target architecture.
Building Your Image
Let’s save our Dockerfile, and then navigate to that directory in our terminal. In the terminal, run the following command:
docker build . -t rust_cross_compile/windows
Docker will build the image by using the current directory’s Dockerfile. The command will also tag this image as rust_cross_compile/windows.
Running Your Container
Once you’ve created the image, then you can run the container by executing the following command:
docker run –rm -v ‘your-pwd’:/app rust_cross_compile/windows
The -rm option will remove the container when the command completes. The -v command allows you to persist data after a container has existed by linking your container storage with your local machine. Replace ‘your-pwd’ with the absolute path to your Rust directory. Once you run the above command, then you will see the following directory structure within your Rust directory:
.
├── Cargo.lock
├── Cargo.toml
└── src
└── main.rs
└── target
└── debug
└── x86_64-pc-windows-gnu
└── debug
termsnake.exe
Running Your Rust Code
You should now see a newly created directory called target. This directory will contain a subdirectory that will be named after the architecture you are targeting. Inside this directory, you will see a debug directory that contains the executable file. Clicking the executable allows you to run the application on a Windows machine. In my case, I was able to start playing the game Snake:
Running Rust on armv7
We have compiled our application into a Windows executable, but we can modify the Dockerfile like the below in order for our application to run on the armv7 architecture:
FROM rust:latest
RUN apt update && apt upgrade -y
RUN apt install -y g++-arm-linux-gnueabihf libc6-dev-armhf-cross
RUN rustup target add armv7-unknown-linux-gnueabihf
RUN rustup toolchain install stable-armv7-unknown-linux-gnueabihf
WORKDIR /app
ENV CARGO_TARGET_ARMV7_UNKNOWN_LINUX_GNUEABIHF_LINKER=arm-linux-gnueabihf-gcc CC_armv7_unknown_Linux_gnueabihf=arm-linux-gnueabihf-gcc CXX_armv7_unknown_linux_gnueabihf=arm-linux-gnueabihf-g++
CMD ["cargo", "build", "–target", "armv7-unknown-linux-gnueabihf"]
Running Rust on aarch64
Alternatively, we could edit the Dockerfile with the below to support aarch64:
FROM rust:latest
RUN apt update && apt upgrade -y
RUN apt install -y g++-aarch64-linux-gnu libc6-dev-arm64-cross
RUN rustup target add aarch64-unknown-linux-gnu
RUN rustup toolchain install stable-aarch64-unknown-linux-gnu
WORKDIR /app
ENV CARGO_TARGET_AARCH64_UNKNOWN_LINUX_GNU_LINKER=aarch64-linux-gnu-gcc CC_aarch64_unknown_linux_gnu=aarch64-linux-gnu-gcc CXX_aarch64_unknown_linux_gnu=aarch64-linux-gnu-g++
CMD ["cargo", "build", "–target", "aarch64-unknown-linux-gnu"]
Another way to compile for different architectures without going through the creation of a Dockerfile would be to install the cross project, using the cargo install -f cross command. From there, simply run the following command to start the build:
cross build –target x86_64-pc-windows-gnu
Conclusion
Docker Desktop allows you to quickly build a development environment that can support different languages and frameworks. We can build and compile our code for many target architectures. In this post, we got Rust code written on Linux to run on Windows, but we don’t have to limit ourselves to just that example. We can pick many other languages and architectures. Alternatively, Docker Buildx is a tool that was designed to help solve these same problems. Checkout more documentation of Buildx here.
Quelle: https://blog.docker.com/feed/