WiTricity: Siemens will kabelloses Laden für E-Autos forcieren
Siemens investiert in WiTricity, das Lösungen für kabelloses Laden von Elektroautos anbietet. Es sollen neue Standards entwickelt werden. (Siemens, Technologie)
Quelle: Golem

Siemens investiert in WiTricity, das Lösungen für kabelloses Laden von Elektroautos anbietet. Es sollen neue Standards entwickelt werden. (Siemens, Technologie)
Quelle: Golem

Die Digitalpolitische Sprecherin der Linken bestreitet, dass ein ausreichend bemessener Universaldienst den FTTH-Ausbau in Deutschland bremst. Die Konzerne hätten nur ein Interesse. (Anke Domscheit-Berg, Technologie)
Quelle: Golem

Das Verkehrs- und Digitalministerium muss sich bei der Digitalisierung jetzt mit dem Bundeskanzleramt und anderen Ministerien abstimmen. (Volker Wissing, Security)
Quelle: Golem

Der US-Festnetzbetreiber hat bereits 5 GBit/s symmetrisch im Angebot. Nun kam AT&T im Labor auf 20 GBit/s. (AT&T, Technologie)
Quelle: Golem

MG Motor hat Bilder des Kompakt-Elektroautos MG4 veröffentlicht, das gegen den ID.3 von Volkswagen positioniert wird. (Elektroauto, Technologie)
Quelle: Golem
Ab heute sind die R5n-Instances von Amazon EC2 in den Regionen Afrika (Kapstadt) und Europa (Mailand) verfügbar.
Quelle: aws.amazon.com

Apple zeigt neue Hard- und Software und es gibt Kabelsalat: die Woche im Video. (Golem-Wochenrückblick, Apple)
Quelle: Golem

Nach dem Erfolg von Star Wars 1977 wollten viele Filmemacher profitieren – und schreckten nicht vor dreisten Imitationen zurück. Von Peter Osteried (Star Wars, George Lucas)
Quelle: Golem
At Super Evil Megacorp our vision is to push the creative and technical boundaries of video games. This was the driving force behind Vainglory, released in 2014, which showcased AAA-quality games can be successful on mobile while filling a gap for multiplayer online battle arena games on mobile. Our vision continues with the development of our next free-to-play game, Catalyst Black, a AAA mobile multiplayer action game hosted on Google Cloud.Setting up the stage for a new kind of real-time mobile gameOur community enjoys developing complex skills and strategies whilst playing our games; they expect beautiful games that can keep up with their quick dexterity and creative thinking. Catalyst Black has been developed with this in mind. To match player expectations, we partnered with Google Cloud very early in our development process. We had a number of learnings from the development of Vainglory that Google Cloud was primed with solutions for. For starters, we wanted to roll our own deployment process and to automate certain aspects of our infrastructure management. Previously, we had five engineers rotating on-call so if a server went down someone could get it back up or spin up a new server manually in case of a sudden spike in players. Now, we use Google Kubernetes Engine to automatically scale our servers up and down as needed. By leveraging an infrastructure that takes care of itself, we can focus instead on creating an engrossing game with exciting features. This allows our team to push the boundaries of how multiplayer games on mobile can foster human connections, with new developments such as a drop-in/drop-out feature that allows players to join a friend’s match with minimal delay. The game is also cross-platform, which means that players on both Android and iOS can team up, no matter what device they use. Tailoring gaming experiences to players with data analyticsTo create great games we need to learn from our players, and for that we need a robust analytics pipeline with low latency. Data analytics enables us to recognize individual players and how they like to play so we can serve them a relevant, tailored gaming experience they’ll enjoy. When players log in, for example, we build a profile for them on our analytics pipeline to understand what kind of player they are. Based on their performance during the game tutorial and subsequent matches, we can understand their skill level, whether they’re interested in purchasing gear for loadouts in-play, what style they like to play, and so on. With this, we can then match a player with others that have similar skill levels and adjust our push notifications depending on how often they join the game.For our data analytics pipeline which informs all of our product decisions, we rely on BigQuery and Looker to scale our analytics frameworks and understand the players’ journey through our live operations, statistical modeling, and A/B testing. We also rely heavily on Looker for observability. That includes looking at crash rates, application responsiveness rates, uptime of all services, and latency across all regions so that players can interact with each other in near real time, which is a must for combat games. Capturing large amounts of detailed data is critical in helping us understand how players behave and how the game itself is performing. Thanks to Google Cloud, we have gained the scalability and compute power needed to support this kind of big data analysis that we rely on daily. With Catalyst Black in beta, with a small user base, we generated millions of events per day. That will go up several orders of magnitude once we launch. That’s a big operation to handle but relying on Google Cloud means we have no concerns that the technical side of things will keep up; we trust Google Cloud to scale.We also need data to make efficient decisions around marketing and products to sustain our business so that we can continue to offer free-to-play games. We use Google Analytics to maximize ROI on our paid media spend through traditional social media and advertising channels. We also use BigQuery ML models to estimate the lifetime of a user and predict ROS and ROI so we can optimize our ad spend.What we’ve noticed so far is that Google Cloud offers outstanding performance and speed for analyzing data and addressing potential issues because its analytics and infrastructure solutions are very well integrated in the Google Cloud environment. For example, by monitoring our player activities we can notice if there’s a sudden dip in latency in any region around the world, and simply spin up new servers to better serve the population there using Compute Engine. By migrating to Google Cloud we’re now spending only a fifth on a per DAU basis compared to what we spent with our previous provider while working on Vainglory. Democratizing great gaming experiencesThe launch of a new game is a big day for us, but it’s also the start of a long journey ahead. We expect to see a significant spike in the number of players following the launch of Catalyst Black, and we also expect to see those numbers eventually flatten down to hundreds of thousands daily. By then, we’ll have a better understanding of who Catalyst Black players are and what their vision is for the future of the game, which we can then collaborate on together.Additionally, with our in-house E.V.I.L. game engine, we can perform on devices that are much older. We can run on Samsung S7s, a device originally released in 2016, with the same 30 frames per second that the latest devices can run. The idea is for anyone to be able to access great games, no matter where they are and what device they have. On 25 May 2022, we launched Catalyst Black. Collaborating with Google Cloud means that we’re prepared for that global scalability. Our games are live operations that organically change and grow, and by relying on GCP we can anticipate our infrastructure needs to support players anywhere in the world throughout that journey, so we’re excited to see where we’ll go from here.Related ArticleHow a top gaming company transformed its approach to security with Splunk and Google CloudAristocrat overhauled its security and compliance processes using Splunk and Google Cloud technologies.Read Article
Quelle: Google Cloud Platform
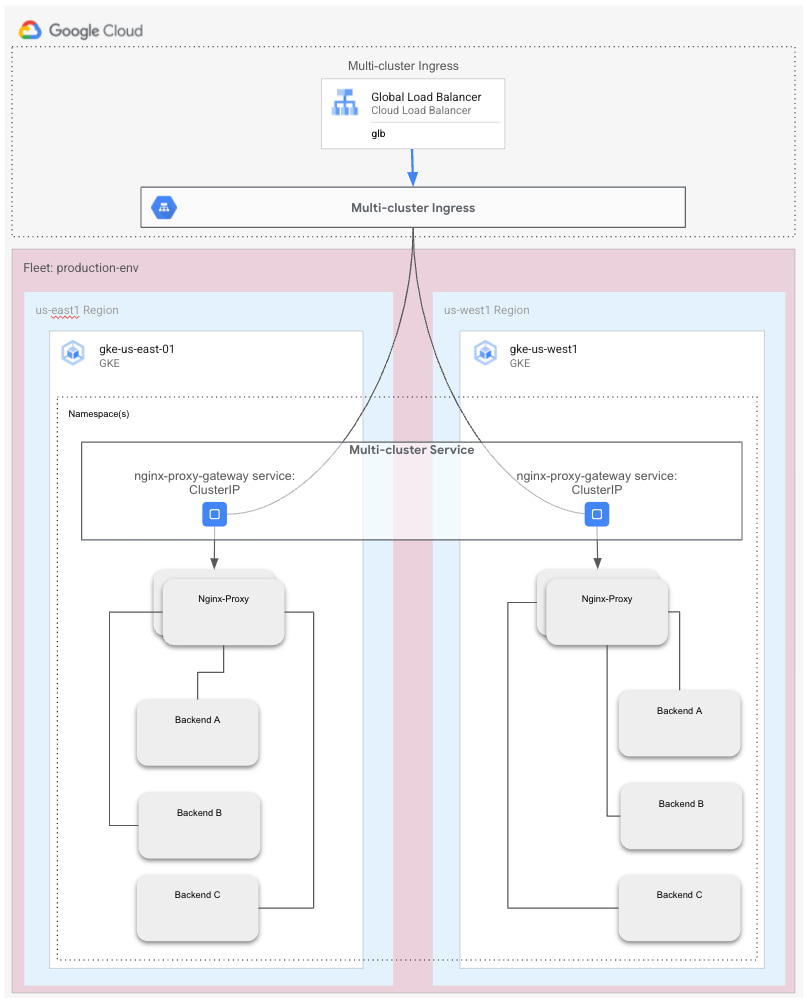
Americans are used to seeing movie-stuffed red kiosks at stores around the country. The company that offers these movie kiosks—along with On Demand entertainment—is Redbox. Redbox started their cloud-native journey by having microservices deployed across one region with another cloud provider and this was primarily on a single Compute cluster in the region. With business demand, they eventually saw the need to move towards a multi-region deployment (east and west) leveraging the same application architecture for their microservices but deploying the applications across the two regions. Most of the traffic originated from the east with a growing volume from the west and as such, a multi-region solution became increasingly important for the business to be able to serve their customer traffic efficiently. Lin Meyer at Redbox shares how they solved this problem.What were the challenges that traditional multi-cluster solutions couldn’t solve?Redbox was generally able to keep their applications running with a two 9s availability using the single region architecture and were looking to move to a three 9s availability using a multi regional approach. This was primarily driven by availability issues mostly in the evenings and weekends when there was an increased demand for streaming services. They started exploring multi-region/cluster solutions but they quickly noticed a couple of key challenges with the existing toolsets.Traffic management challenges. While there were approaches to shift traffic from one cluster to another, a lot of the ownership of implementing that was left to the individual operators. There was an expectation on operators of the environment to rely on telemetry to configure traffic management rules in the event of an application or infrastructure failure to route to the available cluster.Complexity. The options that were currently available with this cloud provider relied on a lot of custom scripting and engineering as well as configuration across various cloud subsystems (including networking, security and compute) In order to achieve the multi cluster topology that the business required.Why GKE, Anthos and multi-cluster ingress?Redbox started exploring managed Kubernetes services specifically to address the availability issue back in late 2019. Redbox turned to Kubernetes to see if there was a built-in solution that addressed this multi-region need. They started off by looking at other cloud managed services initially to determine if there was a more elegant way to achieve their multi cluster requirement. Based on their assessment they determined that the current solutions were not going to work for a couple of reasons.Platform to build other platforms. Through their research they determined that other managed Kubernetes services were a platform that organizations had to build other capabilities onto. An example is the node autoscaling feature. While they had ways to deal with it, it was an expectation of the cluster operator to configure the base cluster with these services. Redbox was looking for a managed service that had these infrastructure level add ons available or easily enabled.Lack of a dedicated multi cluster/region solution. They determined that they could leverage a DNS service to achieve this capability but it was a lot more DIY and not a dedicated multi-cluster solution which would have led to far more engineering efforts and a potentially more brittle solution. They were ideally looking for a more sophisticated multi-cluster solution.They started looking at GKE as a possibility and quickly came across the multi-cluster Service (MCS) and multi-cluster Ingress (MCI) services and saw that as a real potential for their multi-region requirements. They were definitely impressed with GKE but MCI and MCS were the key drivers that made them consider GKE.What did the multi-cluster Ingress and multi-cluster Service get you?There were several reasons why Redbox decided to go down the MCS path.Dedicated Service. Unlike the other approaches that required a lot of engineering effort this service was fully managed and removed a lot of complexity and engineering effort from the operator’s point of view. The DevOps team could focus on their service, which they wanted to enable this capability for and the MCS and MCI controller took care of all the underlying details from a networking and load balancing perspective. This level of abstraction was exactly what the Redbox team was looking for. Declarative Configuration. The fact that the MCS service supported the use of YAML worked very nicely with the rest of the Kubernetes based artifacts. There was no need to click around the console and make updates, which was Redbox’s preferred approach. This also fit very nicely with their CI/CD tool chain as well as they could version control the configuration very easily. The Redbox team was able to move forward with this service very quickly by enabling a few APIs at the project level and were subsequently able to get their MCS service stood up and accepting traffic in a matter of days. Within the next week, they were able to complete all their failover load tests and within 2 weeks, they had everything stood up and deployed in production.Figure 1: Redbox high-level architecture showing multi-region / multi-cluster topology with ingress controlled via an external multi-cluster Ingress and multi-cluster Services packed by nginx backendsWhat benefits are you seeing from this deployment?The Redbox team has currently been using this service for about two years in production. To date, here are some key benefits that they are seeing.Availability. This service has significantly improved application availability and uptime. They are now able to achieve a four 9s availability for their services by simply leveraging the MCS service. The MCI service has seamlessly handled the failover from one cluster to another in the event of an issue providing virtually no disruption for their end user applications.Simplified Deployment. By supporting MCS services as native Kubernetes objects, the DevOps team can now include the declarative configuration of services for multi-region deployment as part of their standard configuration deployment process. Regular Maintenance. An added benefit of the MCS service is that the DevOps team can now perform scheduled maintenance on the regional clusters without taking any downtime. For example they currently run Istio in each cluster and typically an upgrade of Istio requires a cluster upgrade and also application restarts. With MCS, they can now perform these maintenance activities without taking any downtime as MCS continues to guarantee application availability. This has contributed to a much higher uptime. Inter-service communication. MCS has also dramatically improved the data path for inter-service communication. Redbox currently runs multiple environments that are segregated by data category (PCI and non-PCI). By deploying a single GKE fleet for the PCI and non-PCI clusters and subsequently leveraging MCS to expose the services in a multi-regional manner, PCI services can now talk to non-PCI services through their MCS endpoints. This allows MCS to function as a Service Registry for multi-cluster services with the service endpoint discovery and invocation handled seamlessly. It also presents a more efficient data path by connecting from one service to another without having to traverse through an internal or external load balancer. SummaryAt Redbox we knew we needed to modernize our infrastructure and deployment platform to meet the needs of our DVD kiosk rental business and rapidly growing digital streaming services. When looking at options for faster, safer deployments we found Google Kubernetes Engine and opted to use Multi Cluster Ingress and Multi Cluster Services to host our customer facing applications across multiple GCP regions. With GKE and MCI we have been able to continue our digital transformation to the cloud, getting new features and products to our customer’s faster than ever. MCI has enabled us to do this with excellent reliability and response times by routing traffic to the closest available cluster at a moment’s notice.To learn more about Anthos and MCI, please visit https://cloud.google.com/anthosRelated ArticleStandardization, security, and governance across environments with Anthos Multi-CloudAnthos Configuration Management, Policy Controller, and Service Mesh help you to form a design for standardization, security, and governa…Read Article
Quelle: Google Cloud Platform