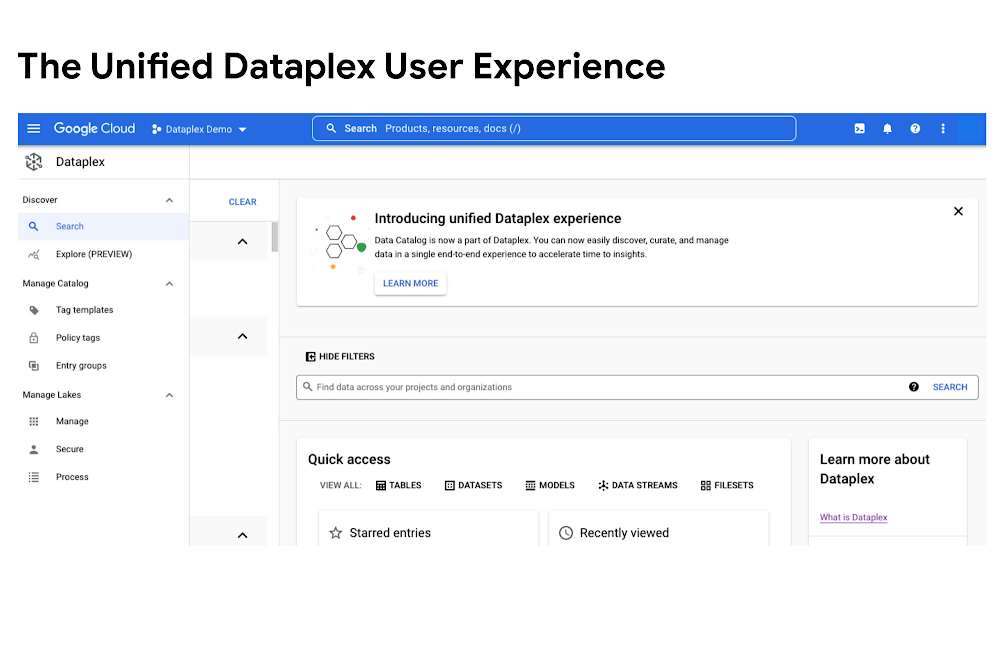
Streamline data management and governance with the unification of Data Catalog and Dataplex
Today, we are excited to announce that Google Cloud Data Catalog will be unified with Dataplex into a single user interface. With this unification, customers have a single experience to search and discover their data, enrich it with relevant business context, organize it by logical data domains, and centrally govern and monitor their distributed data with built-in data intelligence and automation capabilities. Customers now have access to an integrated metadata platform that connects technical and operational metadata with business metadata, and then uses this augmented and active metadata to drive intelligent data management and governance. The enterprise data landscape is becoming increasingly diverse and distributed with data across multiple storage systems, each having its own way of handling metadata, security, and governance. This creates a tremendous amount of operational complexity, and thus, generates strong market demand for a metadata platform that can power consistent operations across distributed data.Dataplex provides a data fabric to automate data management, governance, discovery, and exploration across distributed data at scale. With Dataplex, enterprises can easily organize their data into data domains, delegate ownership, usage, and sharing of data to data owners who have the right business context, while still maintaining a single pane of glass to consistently monitor and govern data across various data domains in their organization. Prior to this unification, data owners, stewards and governors had to use two different interfaces – Dataplex to organize, manage, and govern their data, and Data Catalog to discover, understand, and enrich their data. Now with this unification, we are creating a single coherent user experience where customers can now automatically discover and catalog all the data they own, understand data lineage, check for data quality, augment that metadata with relevant business context, organize data into business domains, and then use that combined metadata to power data management. Together we provide an integrated experience that serves the full spectrum of data governance needs in an organization, enabling data management at scale.“With Data Catalog now being part of Dataplex, we get a unified, simplified, and streamlined experience to effectively discover and govern our data, which enables team productivity and analytics agility for our organization. We can now use a single experience to search and discover data with relevant business context, organize and govern this data based on business domains, and enable access to trusted data for analytics and data science – all within the same platform.” saidElton Martins, Senior Director of Data Engineering at Loblaw Companies Limited.Getting startedExisting Data Catalog and Dataplex customers and new customers can now start using Dataplex for metadata discovery, management and governance. Please note that while the user experience interface is unified via this release, all existing APIs and feature functionalities of both products will continue to work as before. To learn more, please refer to technical documentations or contact the Google Cloud sales team.Related ArticleScalable Python on BigQuery using Dask and NVIDIA GPUsTo accelerate data analytics and machine learning workflows, we introduce the Dask BigQuery connector to read data through BigQuery stora…Read Article
Quelle: Google Cloud Platform