Solarmodule in der Wüste: Heiße Pole, trockene Tropen
Warum Solarmodule in der Sahara den erneuerbaren Energien Aufschwung geben, aber das globale Klima schädigen könnten. Von Zhengyao Lu und Benjamin Smith (Solarenergie, Internet)
Quelle: Golem

Warum Solarmodule in der Sahara den erneuerbaren Energien Aufschwung geben, aber das globale Klima schädigen könnten. Von Zhengyao Lu und Benjamin Smith (Solarenergie, Internet)
Quelle: Golem

Mini hat ein Einzelstück des Mini Electric als Cabrio vorgestellt. Das Elektroauto wird derzeit auf einem Kundenevent präsentiert. (BMW, Technologie)
Quelle: Golem

Zwar bleibt die Geheimniskrämerei um Fuchsia weiter bestehen. Aus dem Code von Google lassen sich dennoch Pläne ableiten. (Fuchsia, Google)
Quelle: Golem

Die FDP will Homeoffice-Regeln unterstützen, sollte es einen Gas-Lieferstopp geben. Dann würden Büro-Gebäude weniger geheizt. (Homeoffice, Bundesregierung)
Quelle: Golem

Der Bau zahlreicher Batteriezellwerke ist bereits angekündigt. Wenn das so weitergeht, könnte Deutschland ein Hauptstandort bei der Produktion werden. (Wissenschaft)
Quelle: Golem

Hasbro bietet Actionfiguren aus Star Wars, Marvel, Ghostbusters und GI Joe mit 3D-gedruckten Köpfen nach Kundenwunsch an. (Hasbro, Technologie)
Quelle: Golem

Ein LED-Smartphone und künstlerische Intelligenz: die Woche im Video. (Golem-Wochenrückblick, Elon Musk)
Quelle: Golem

Transformers und Lego sollten ein natürliches Match sein. Optimus Prime sieht auch cool aus und verwandelt sich, fällt aber fix auseinander. Von Oliver Nickel (Lego, Test)
Quelle: Golem
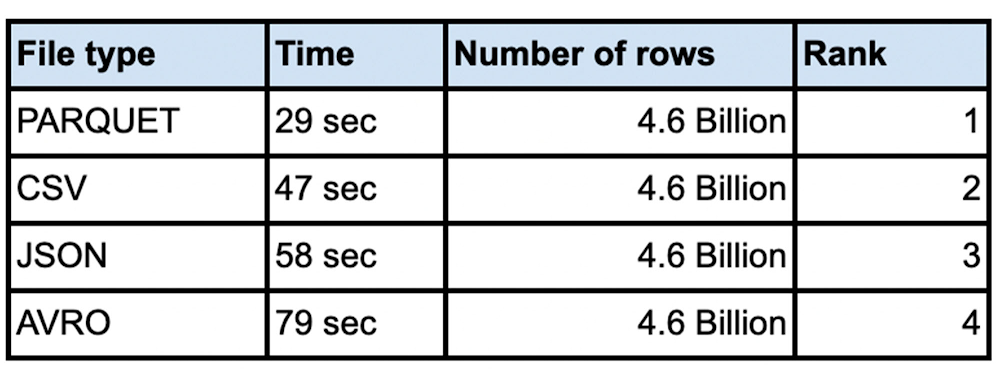
It is not unusual for customers to load very large data sets into their enterprise data warehouse. Whether you are doing an initial data ingestion with hundreds of TB of data or incrementally loading from your systems of record, performance of bulk inserts is key to quicker insights from the data. The most common architecture for batch data loads uses Google Cloud Storage(Object storage) as the staging area for all bulk loads. All the different file formats are converted into an optimized Columnar format called ‘Capacitor’ inside BigQuery.This blog will focus on various file types and data loading tools for best performance. Data files that are uploaded to BigQuery, typically come in Comma Separated Values(CSV), Avro, Parquet, JSON, ORC formats. We are going to use a large dataset to compare and contrast each of these file formats. We will explore loading efficiencies of compressed vs. uncompressed data for each of these file formats. Data can be loaded into BigQuery using multiple tools in the GCP ecosystem. You can use the Google Cloud console, bq load command, using the BigQuery API or using the client libraries. We will also compare and contrast each loading mechanism for the same dataset. This blog attempts to elucidate the various options for bulk data loading into BigQuery and also provides data on the performance for each file-type and loading mechanism.Introduction There are various factors you need to consider when loading data into BigQuery. Data file formatData compressionTool used to load dataLevel of parallelization of data loadSchema autodetect ‘ON’ or ‘OFF’Data file formatBulk insert into BigQuery is the fastest way to insert data for speed and cost efficiency. Streaming inserts are however more efficient when you need to report on the data immediately. Today data files come in many different file types including comma separated(CSV), json, parquet, avro to name a few. We are often asked how the file format matters and whether there are any advantages in choosing one file format over the other. CSV files (comma-separated values) contain tabular data with a header row naming the columns. When loading data one can parse the header for column names. When loading from csv files one can use the header row for schema autodetect to pick up the columns. With schema autodetect set to off, one can skip the header row and create a schema manually, using the column names in the header. CSV files can use other field separator/newline characters too as a separator, since many data outputs already have a comma in the data. You cannot store nested or repeated data in CSV file format.JSON (JavaScript object notation) data is stored as a key-value pair in a semi structured format. JSON is preferred as a file type because it can store data in a hierarchical format. The schemaless nature of json data rows gives the flexibility to evolve the schema and thus change the payload. JSON and XML formats are user-readable, but JSON documents are typically much smaller than XML. REST-based web services use json over other file types.Parquet is a column-oriented data file format designed for efficient storage and retrieval of data. Parquet compression and encoding is very efficient and provides improved performance to handle complex data in bulk.Avro: The data is stored in a binary format and the schema is stored in JSON format. This helps in minimizing the file size and maximizes efficiency. Avro has reliable support for schema evolution by managing added, missing, and changed fields. From a data loading perspective we did various tests with millions to hundreds of billions of rows with narrow to wide column data .We have done this test with a public dataset named `bigquery-public-data:worldpop.population_grid_1km`. We used 4000 flex slots for the test and the number of loading slots is limited to the number of slots you have allocated for your environment, though the load slots do not use all of the slots you throw at it.. Schema Autodetection was set to ‘NO’. For the parallelization of the data files each file should typically be less than 256MB for faster throughput and here is a summary of our findings:Do I compress the data? Sometimes batch files are compressed for faster network transfers to the cloud. Especially for large data files that are being transferred, it is faster to compress the data before sending over the cloud Interconnect or VPN connection. In such cases is it better to uncompress the data before loading into BigQuery? Here are the tests we did for various file types with different compression algorithms.Shown results are the average of five runs:How do I load the data?There are various ways to load the data into BigQuery. You can use the Google Cloud Console, command line, Client Library(shown python here) or use the Direct API call. We compared these data loading techniques and compared the efficacy of each method. Here is a comparison of the timings for each method. You can also see that Schema Autodetect works very well, where there are no datatype quality issues in the source data and you are consistently getting the same columns from a data sourceConclusionThere is no advantage in loading time when the source file is in compressed format. In fact for the most part uncompressed data loads in the same or faster time than compressed data. We noticed that for csv and avro file types you do not need to uncompress for faster load times. For other file types including parquet and json it takes longer to load the data when the file is compressed. Decompression is a CPU bound activity and your mileage varies based on the amount of load slots assigned to your load job. Data loading slots are different from the data querying slots. For compressed files, you should parallelize the load operation, so as to make sure that data loads are efficient. Split the data files to 256MB or less to avoid spilling over the uncompression task to disk.From a performance perspective avro, csv and parquet files have similar load times. Use the command line to load larger volumes of data for the most efficient data loading. Fixing your schema does load the data faster than schema autodetect set to ‘ON’. Regarding ETL jobs, it is faster and simpler to do your transformation inside BigQuery using SQL, but if you have complex transformation needs that cannot be done with SQL, use Dataflow for unified batch and streaming, Dataproc for open source based pipelines, or Cloud Data Fusion for no-code / low-code transformation needs.To learn more about how Google BigQuery can help your enterprise, try out Quickstarts page here.Disclaimer: These tests were done with limited resources for BigQuery in a test environment during different times of the day with noisy neighbors, so the actual timings and the number of rows might not be reflective of your test results. The numbers provided here are for comparison sake only, so that you can choose the right file types, compression and loading technique for your workload. Related ArticleLearn how BI Engine enhances BigQuery query performanceThis blog explains how BI Engine enhances BigQuery query performance, different modes in BI engine and its monitoring.Read Article
Quelle: Google Cloud Platform
IBM mainframes have been around since the 1950s and are still vital for many organizations. In recent years many companies that rely on mainframes have been working towards migrating to the cloud. This is motivated by the need to stay relevant, the increasing shortage of mainframe experts and the cost savings offered by cloud solutions. One of the main challenges in migrating from the mainframe has always been moving data to the cloud. The good thing is that Google has open sourced a bigquery-zos-mainframe connector that makes this task almost effortless.What is the Mainframe Connector for BigQuery and Cloud Storage?The Mainframe Connector enables Google Cloud users to upload data to Cloud Storage and submit BigQuery jobs from mainframe-based batch jobs defined by job control language (JCL). The included shell interpreter and JVM-based implementations of gsutil and bq command-line utilities make it possible to manage a complete ELT pipeline entirely from z/OS. This tool moves data located on a mainframe in and out of Cloud Storage and BigQuery; it also transcodes datasets directly to ORC (a BigQuery supported format). Furthermore, it allows users to execute BigQuery jobs from JCL, therefore enabling mainframe jobs to leverage some of Google Cloud’s most powerful services.The connector has been tested with flat files created by IBM DB2 EXPORT that contain binary-integer, packed-decimal and EBCDIC character fields that can be easily represented by a copybook. Customers with VSAM files may use IDCAMS REPRO to export to flat files, which can then be uploaded using this tool. Note that transcoding to ORC requires a copybook and all records must have the same layout. If there is a variable layout, transcoding won’t work, but it is still possible to upload a simple binary copy of the dataset.Using the bigquery-zos-mainframe-connectorA typical flow for Mainframe Connector involves the following steps:Reading the mainframe datasetTranscoding the dataset to ORCUploading ORC to Cloud StorageRegistering it as an external tableRunning a MERGE DML statement to load new incremental data into the target tableNote that if the dataset does not require further modifications after loading, then loading into a native table is a better option than loading into an external table.In regards to step 2, it is important to mention that DB2 exports are written to sequential datasets on the mainframe and the connector uses the dataset’s copybook to transcode it to an ORC.The following simplified example shows how to read a dataset on a mainframe, transcode it to ORC format, copy the ORC file to Cloud Storage, load it to a BigQuery-native table and run SQL that is executed against that table.1. Check out and compile:code_block[StructValue([(u’code’, u’git clone https://github.com/GoogleCloudPlatform/professional-servicesrncd ./professional-services/tools/bigquery-zos-mainframe-connector/rn rn# compile util library and publish to local maven/ivy cacherncd mainframe-utilrnsbt publishLocalrn rn# build jar with all dependencies includedrncd ../gszutilrnsbt assembly’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e7e135cd450>)])]2. Upload the assembly jar that was just created in target/scala-2.13 to a path on your mainframe’s unix filesystem.3. Install the BQSH JCL Procedure to any mainframe-partitioned data set you want to use as a PROCLIB. Edit the procedure to update the Java classpath with the unix filesystem path where you uploaded the assembly jar. You can edit the procedure to set any site-specific environment variables.4. Create a jobSTEP 1:code_block[StructValue([(u’code’, u’//STEP01 EXEC BQSHrn//INFILE DD DSN=PATH.TO.FILENAME,DISP=SHRrn//COPYBOOK DD DISP=SHR,DSN=PATH.TO.COPYBOOKrn//STDIN DD *rngsutil cp –replace gs://bucket/my_table.orcrn/*’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e7e115c0850>)])]This step reads the dataset from the INFILE DD and reads the record layout from the COPYBOOK DD. The input dataset could be a flat file exported from IBM DB2 or from a VSAM file. Records read from the input dataset are written to the ORC file at gs://bucket/my_table.orc with the number of partitions determined by the amount of data.STEP 2:code_block[StructValue([(u’code’, u’//STEP02 EXEC BQSHrn//STDIN DD *rnbq load –project_id=myproject \rn myproject:MY_DATASET.MY_TABLE \rn gs://bucket/my_table.orc/*rn/*’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e7e126e2850>)])]This step submits a BigQuery load job that will load ORC file partitions from my_table.orc into MY_DATASET.MY_TABLE. Note this is the path that was written to on the previous step. STEP 3:code_block[StructValue([(u’code’, u’//STEP03 EXEC BQSHrn//QUERY DD DSN=PATH.TO.QUERY,DISP=SHRrn//STDIN DD *rnbq query –project_id=myprojectrn/*’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e7e126e2690>)])]This step submits a BigQuery Query Job to execute SQL DML read from the QUERY DD (a format FB file with LRECL 80). Typically the query will be a MERGE or SELECT INTO DML statement that results in transformation of a BigQuery table. Note: the connector will log job metrics but will not write query results to a file.Running outside of the mainframe to save MIPSWhen scheduling production-level load with many large transfers, processor usage may become a concern. The Mainframe Connector executes within a JVM process and thus should utilize zIIP processors by default, but if capacity is exhausted, usage may spill over to general purpose processors. Because transcoding z/OS records and writing ORC file partitions requires a non-negligible amount of processing, the Mainframe Connector includes a gRPC server designed to handle compute-intensive operations on a cloud server; the process running on z/OS only needs to upload the dataset to Cloud Storage and make an RPC call. Transitioning between local and remote execution requires only an environment variable change. Detailed information on this functionality can be found here. AcknowledgementsThanks to those who tested, debugged, maintained and enhanced the tool: Timothy Manuel, Suresh Balakrishnan,Viktor Fedinchuk,Pavlo KravetsRelated Article30 ways to leave your data center: key migration guides, in one placeEssential guides for all the workloads your business is considering migrating to the public cloud.Read Article
Quelle: Google Cloud Platform