Südafrika: MTN will Telkom für 1,3 Milliarden US-Dollar kaufen
Damit würde der größte Mobilfunkbetreiber Südafrikas vor Vodacom entstehen. Doch es dürfte regulatorische Probleme geben. (Telekommunikation, Long Term Evolution)
Quelle: Golem

Damit würde der größte Mobilfunkbetreiber Südafrikas vor Vodacom entstehen. Doch es dürfte regulatorische Probleme geben. (Telekommunikation, Long Term Evolution)
Quelle: Golem

Microsoft gibt seinen Plan auf, jedes Jahr ein großes Update für Windows zu bringen. Neue Funktionen wird es aber dennoch öfter geben. (Windows, Microsoft)
Quelle: Golem

Beim Macbook Air mit M2-Chip spart sich Apple einen der SSD-Bausteine, weshalb das ältere Macbook Air (M1) bei gleicher Kapazität flotter ist. (Macbook Air, Solid State Drive)
Quelle: Golem

Nach einer Testphase startet Google die allgemeine Verfügbarkeit von Chrome OS Flex. Alte Hardware wird so schnell zum Chromebook. (Chrome OS, Google)
Quelle: Golem

Mit dem Ausbau unserer Redaktion und zusätzlichen, tiefgehenden, berufsrelevanten und serviceorientierten Texten erweitern wir unser Angebot. (Golem.de, Internet)
Quelle: Golem

Gibt es einen Master-Algorithmus im Gehirn und können wir ihn nachbauen? Von Helmut Linde (KI, Internet)
Quelle: Golem
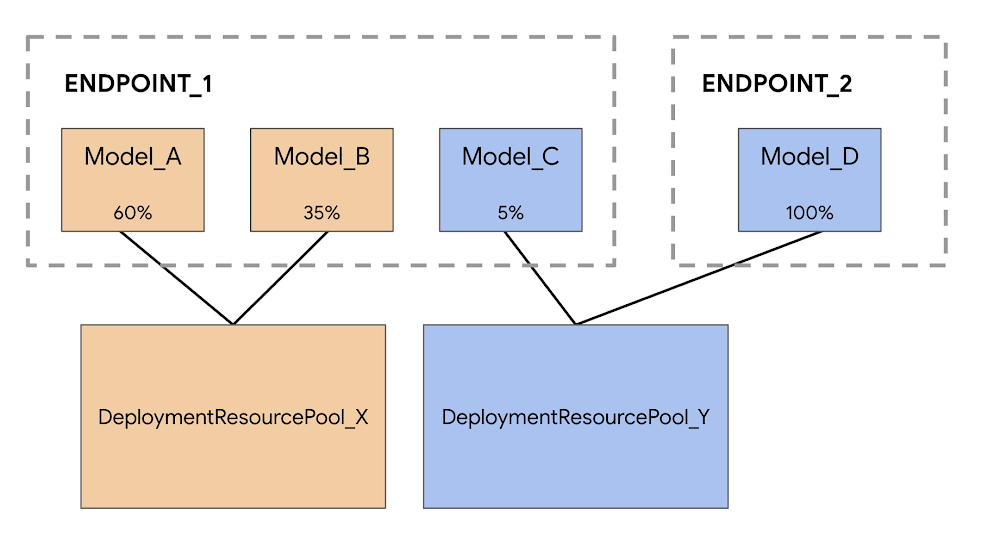
When deploying models to the Vertex AI prediction service, each model is by default deployed to its own VM. To make hosting more cost effective, we’re excited to introduce model co-hosting in public preview, which allows you to host multiple models on the same VM, resulting in better utilization of memory and computational resources. The number of models you choose to deploy to the same VM will depend on model sizes and traffic patterns, but this feature is particularly useful for scenarios where you have many deployed models with sparse traffic.Understanding the Deployment Resource PoolCo-hosting model support introduces the concept of a Deployment Resource Pool, which groups together models to share resources within a VM. Models can share a VM if they share an endpoint, but also if they are deployed to different endpoints. For example, let’s say you have four models and two endpoints, as shown in the image below.Model_A, Model_B, and Model_C are all deployed to Endpoint_1 with traffic split between them. And Model_D is deployed to Endpoint_2, receiving 100% of the traffic for that endpoint. Instead of having each model assigned to a separate VM, we can group Model_A and Model_B to share a VM, making them part of DeploymentResourcePool_X. We can also group models that are not on the same endpoint, so Model_C and Model_D can be hosted together in DeploymentResourcePool_Y. Note that for this first release, models in the same resource pool must also have the same container image and version of the Vertex AI pre-built TensorFlow prediction containers. Other model frameworks and custom containers are not yet supported.Co-hosting models with Vertex AI PredictionsYou can set up model co-hosting in a few steps. The main difference is that you’ll first create a DeploymentResourcePool, and then deploy your model within that pool. Step 1: Create a DeploymentResourcePoolYou can create a DeploymentResourcePool with the following command. There’s no cost associated with this resource until the first model is deployed.code_block[StructValue([(u’code’, u’PROJECT_ID={YOUR_PROJECT}rnREGION=”us-central1″rnVERTEX_API_URL=REGION + “-aiplatform.googleapis.com”rnVERTEX_PREDICTION_API_URL=REGION + “-prediction-aiplatform.googleapis.com”rnMULTI_MODEL_API_VERSION=”v1beta1″rn rn# Give the pool a namernDEPLOYMENT_RESOURCE_POOL_ID=”my-resource-pool”rn rnCREATE_RP_PAYLOAD = {rn “deployment_resource_pool”:{rn “dedicated_resources”:{rn “machine_spec”:{rn “machine_type”:”n1-standard-4″rn },rn “min_replica_count”:1,rn “max_replica_count”:2rn }rn },rn “deployment_resource_pool_id”:DEPLOYMENT_RESOURCE_POOL_IDrn}rnCREATE_RP_REQUEST=json.dumps(CREATE_RP_PAYLOAD)rn rn!curl \rn-X POST \rn-H “Authorization: Bearer $(gcloud auth print-access-token)” \rn-H “Content-Type: application/json” \rnhttps://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/deploymentResourcePools \rn-d ‘{CREATE_RP_REQUEST}”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e467adcff10>)])]Step 2: Create a modelModels can be imported to the Vertex AI Model Registry at the end of a custom training job, or you can upload them separately if the model artifacts are saved to a Cloud Storage bucket. You can upload a model through the UI or with the SDK using the following command:code_block[StructValue([(u’code’, u”# REPLACE artifact_uri with GCS path to your artifactsrnmy_model = aiplatform.Model.upload(display_name=’text-model-1′,rn artifact_uri=u2019gs://{YOUR_GCS_BUCKET}u2019,rn serving_container_image_uri=’us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-7:latest’)”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e464c9e0f90>)])]When the model is uploaded, you’ll see it in the model registry. Note that the deployment status is empty since the model hasn’t been deployed yet.Step 3: Create an endpointNext, create an endpoint via the SDK or the UI. Note that this is different from deploying a model to an endpoint.endpoint = aiplatform.Endpoint.create(‘cohost-endpoint’)When your endpoint is created, you’ll be able to see it in the console.Step 4: Deploy Model in a Deployment Resource PoolThe last step before getting predictions is to deploy the model within the DeploymentResourcePool you created.code_block[StructValue([(u’code’, u’MODEL_ID={MODEL_ID}rnENDPOINT_ID={ENDPOINT_ID}rn rnMODEL_NAME = “projects/{project_id}/locations/{region}/models/{model_id}”.format(project_id=PROJECT_ID, region=REGION, model_id=MODEL_ID)rnSHARED_RESOURCE = “projects/{project_id}/locations/{region}/deploymentResourcePools/{deployment_resource_pool_id}”.format(project_id=PROJECT_ID, region=REGION, deployment_resource_pool_id=DEPLOYMENT_RESOURCE_POOL_ID)rn rnDEPLOY_MODEL_PAYLOAD = {rn “deployedModel”: {rn “model”: MODEL_NAME,rn “shared_resources”: SHARED_RESOURCErn },rn “trafficSplit”: {rn “0”: 100rn }rn}rnDEPLOY_MODEL_REQUEST=json.dumps(DEPLOY_MODEL_PAYLOAD)rnpp.pprint(“DEPLOY_MODEL_REQUEST: ” + DEPLOY_MODEL_REQUEST)rn rn!curl -X POST \rn-H “Authorization: Bearer $(gcloud auth print-access-token)” \rn-H “Content-Type: application/json” \rnhttps://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/endpoints/{ENDPOINT_ID}:deployModel \rn-d ‘{DEPLOY_MODEL_REQUEST}”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e464c9e0c90>)])]When the model is deployed, you’ll see it ready in the console. You can deploy additional models to this same DeploymentResourcePool for co-hosting using the same endpoint we created already, or using a new endpoint.Step 5: Get a predictionOnce the model is deployed, you can call your endpoint in the same way you’re used to.x_test= [‘The movie was spectacular. Best acting I’ve seen in a long time and a great cast. I would definitely recommend this movie to my friends!’]endpoint.predict(instances=x_test)What’s nextYou now know the basics of how to co-host models on the same VM. For an end to end example, check out this codelab, or refer to the docs for more details. Now it’s time for you to start deploying some models of your own!Related ArticleSpeed up model inference with Vertex AI Predictions’ optimized TensorFlow runtimeThe Vertex AI optimized TensorFlow runtime can be incorporated into serving workflows for lower latency predictions.Read Article
Quelle: Google Cloud Platform

The following blog covers popular performance analysis tools and technologies database administrators can use to tune and optimize Cloud SQL for SQL Server. Common performance challenges are described in each section along with tools and strategies to analyze, address and remediate them. After reviewing this blog, consider applying the tools and processes detailed in each section to a non-production database in order to gain a deeper understanding of how they can help you to manage and optimize your databases. We will also publish a follow up blog that will walk you through common performance issues and how to troubleshoot and remediate those using the tools and processes described here.1. Getting Started: Connecting to your Cloud SQL for SQL Server instance.The most common use cases for connecting to Cloud SQL include connecting from a laptop over VPN and using a jump host in GCP. SQL Server DBAs who connect from a local laptop over VPN using SQL Server Management Studio (SSMS) should review this Quickstart document for connecting to a Cloud SQL instance that is configured with a private IP address. DBAs may also prefer to connect to a single jump host for centralized management of multiple Cloud SQL for SQL Server instances. In this scenario, a Google Compute Engine (GCE) VM is provisioned and DBAs use a Remote Desktop Protocol (RDP) tool to connect to the jump host and manage their Cloud SQL databases. For a comprehensive list of options on connecting to Cloud SQL, see connecting to Cloud SQL for SQL Server. 2. Activity Monitoring: What’s running right now? When responding to urgent support calls, DBAs have an immediate need to determine what is currently running on the instance. Historically, DBAs have relied on system stored procedures such as sp_Who and sp_Who2 to support triage and analysis. To determine what’s running right now, consider installing Adam Machanic’s sp_WhoIsActive stored procedure. To view currently running statements and to obtain details on the plans, use the statement below. Note that in the following example, the procedure sp_WhoIsActive has been installed on the dbo schema of the dbtools database. EXEC dbtools.dbo.sp_WhoIsActive @get_plans=1Also, see Brent Ozar’s sp_BlitzFirst stored procedure, which is included in the SQL-Server-First-Responder-Kit. Review the documentation for examples. 3. Optimizing queries using the SQL Server Query Store.Query optimization is best to be performed proactively as a weekly DBA checklist item. The SQL Server Query Store feature can help with this and provides DBAs with query plans, history and useful performance metrics. Before starting the SQL Server Query Store, it is a good idea to review the following Microsoft SQL Server Performance Monitoring article: Monitoring performance by using the Query Store . Query Store is enabled on a database level and must be enabled for each user database. See the example below for how to enable Query Store. ALTER DATABASE <<DBNAME>>SET QUERY_STORE = ON (WAIT_STATS_CAPTURE_MODE = ON);After enabling Query Store, review the Query Store configuration using SSMS. Right-click on the database and view Query Store properties. Review the Microsoft article Monitoring performance by using the Query Store for more information on properties and settings. Screenshot: Query Store has been enabled on the AdventureWorksDW2019 database.After enabling Query Store on a busy instance, query data will normally be available for review within a few minutes. Alternatively, run a few test queries to generate data for analysis. Next, expand the Query Store node to explore available reports.In the example below, I selected “Top Resource Consuming Queries”. I then sorted the table by total duration and reviewed the execution plan for the top resource consuming query. In reviewing the execution plan I noted that a table scan was occurring. I was then able to remediate the issue by asking the user to modify their query to select specific columns rather than selecting all the columns, and then added a non-clustered index to the underlying table to include the required columns.Example Index Change:code_block[StructValue([(u’code’, u’CREATE NONCLUSTERED INDEX NCIX_dbo_scenario1_LastName_INCLUDE_FirstName_BirthDatern ON [dbo].[scenario1] (LastName) INCLUDE (FirstName, BirthDate); rnGO’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3ec8a528d690>)])]To track a query over time, right-click the query and select “Track Query”.Note that the plans for before and after the index change are shown below.Select both plans, then choose “Compare Plans” to view pre and post plan changes.SQL Server Query Store is a helpful built-in performance tuning tool that is available for Cloud SQL DBAs to capture, analyze and tune T-SQL statements. It makes sense to spend time learning about how Query Store can help you manage and optimize your SQL Server databases.4. Analyzing instance and database health, configuration and performance.The SQL Server Community offers many free tools and scripts for reviewing and analyzing SQL Server instances and databases. A few popular script resources are noted below. Glen Berry’s SQL Server Diagnostic Queries are useful for assessing on-prem instances when planning for a migration, and analyzing configurations and performance once databases are running in GCP. For more information on how to use the SQL Server Diagnostic Queries, and for help interpreting the results, review Glen’s YouTube videos.Brent Ozar’s SQL-Server-First-Responder-Kit is another popular community tool used to quickly assess and analyze SQL Server instances. Note that Cloud SQL for SQL Server does not support installing objects in the master database, and it is recommended that a separate database is created for the scripts. Many DBAs create a tools database (for example: dbtools), and install scripts and procedures in that database. Review the documentation and Brent’s how-to videosfor tips on installing and using the kit. 5. Configuration and performance levers to reduce locking and blocking.Performance problems related to locking and blocking may be reduced by scaling up the instance and optimizing database objects like tables, queries and stored procedures. While increasing instance performance may provide quick wins in the short-term, optimizing SQL and application code results in better stability and performance over the long term.Instance Cores and Storage CapacityIncreasing cores and storage capacity, also known as scaling up, has an immediate effect on IO throughput and performance, and many workload performance issues may be mitigated by increasing CPU and Storage configuration settings. Disk performance is based on the disk size and the number of vCPUs. Add more storage space and vCPUs to increase IOPS and throughput.Read Committed Snapshot Isolation (RCSI) If you find yourself adding NO LOCK to your queries in an attempt to reduce contention and speed things up, it’s probably a good idea to take a look at Read Committed Snapshot Isolation. When READ_COMMITTED_SNAPSHOT is turned on, SQL Server Engine uses row versioning instead of locking. For more information, see Kendra Little’s blog post on How to Choose Between RCSI and Snapshot Isolation Levels to determine if RCSI is right for your database workloads.Forced ParameterizationIf you run across an application that generates a lot of dynamic SQL or executes SQL without parameters, you may see a lot of CPU time wasted on creating new plans for SQL queries. In some cases, Forced Parameterization can help your database performance when you are not able to change or influence application coding standards. For more on forced parameterization and how it can be applied, review the following link: SQL Server Database Parameterization option and its Query Performance effects 6. Managing Indexes and Statistics: SQL Server maintenanceOla Hallengren’s SQL Server Maintenance Solution is a SQL Server Community standard database maintenance solution. In an on-premises or GCE environment, a DBA may choose to install the entire maintenance solution, including backup scripts. Since backups are handled internally by Cloud SQL, a DBA may choose to install only the Statistics and Indexing procedures and supporting objects. Visit https://ola.hallengren.com/ to learn more about the solution, and take time to review the associated scripts, instructions, documentation and examples of how to install and use the SQL Server Maintenance Solution.ConclusionProactively managing and tuning your Cloud SQL SQL Server databases enables DBAs to spend less time on production support calls and increases the performance, efficiency and scalability of databases. Many of the tools and recommendations noted in this blog are also applicable to SQL Server databases running on GCE. Once you become familiar with the tools and processes featured in this blog, consider integrating them into your database workflows and management plans.Related ArticleCloud SQL for SQL Server: Database administration best practicesCloud SQL for SQL Server is a fully-managed relational database service that makes it easy to set up, maintain, manage, and administer SQ…Read Article
Quelle: Google Cloud Platform

Editor’s note: Wayne Kimball, Jr. is Principal for Google Cloud’s Mergers & Acquisitions business. He is also the founder of Black+TechAmplify, a corporate development initiative to accelerate the growth of traditionally untapped, diverse founders. In both cases, he says, it’s about creating empathy around people and processes to create greater value.You’re a “boomerang,” or returning Googler. How do you view your career?It’s been a fun journey, with a lot of excitement, work, and rewards. I studied engineering at North Carolina A&T State University, the nation’s largest HBCU. I was student body president, and one of my goals was to enhance the technology experience for fellow students by convincing the university to transition to Gmail. A friend of a friend helped put me in touch with Google, who then came to campus for strategic conversations with administrators and to meet with students. The school ended up adopting Gmail, and soon thereafter, I was offered a job at Google, becoming the first ever hire from North Carolina A&T.I started out doing technology operations as a PeopleOps rotational associate, but pretty soon I realized that I wanted to be on the sales side, as I like seeing the dynamic of people, technology, and business. Eventually I left Google, went to business school, then did strategy and M&A work at a couple of places before I came back to do it at Cloud.What drew you to M&A? Working in sales taught me all about growing organically. M&A is exciting because the work drives enterprise value through inorganic acquisitions. I find it truly rewarding to identify and merge the various points of view, and make them ultimately work seamlessly together more organically. We always have to start with customer focus, but that can mean a lot of things. Then, when it comes to the acquisition, Google Cloud is first a customer that needs to get the right acquisition, and subsequently the company we acquire is a customer that needs to be acclimated to being a part of Google.I always say, “Change should happen with people, not to people.”Is Black+TechAmplify a passion project, or an extension of what you do inside Cloud?It’s a bit of both. There are almost ten Google employees now supporting Black+TechAmplify, but the project started with me asking, “How many of our acquisitions have been Black-owned or women-owned?” It wasn’t a lot. So we set out to identify tech startups that were Black-owned, and develop more resources and exposure, including ways to partner and grow with Google. After two cohorts, the companies have raised over $20 million in additional funding. We feel like it’s a model we can extend to other founders from underrepresented groups.I also partner closely with Google for Startups to support their review and selection of startup applicants, and serve as an Advisor for Black and Latinx founders in their programs. It’s also encouraging to see a number of other companies, in addition to Google, now leaning into this kind of activity.Is there a common theme in what you’re doing at Cloud?I’d say it’s all focused on accelerating the growth of Google Cloud by accelerating the value capture for the customer, wherever they are. In every case, to accelerate value capture you have to look after people, making sure they are treated well. If you look after that, the profit will eventually come.Related Article“Take that leap of faith” Meet the Googler helping customers create financial inclusionCloud Googler shares how she has brought her purpose to her work, creating equity in the financial services space.Read Article
Quelle: Google Cloud Platform

We’re excited to announce that Microsoft has joined the Eclipse Foundation Jakarta EE and MicroProfile Working Groups as an Enterprise and Corporate member, respectively. Our goal is to help advance these technologies to deliver better outcomes for our Java customers and the broader community. We’re committed to the health and well-being of the vibrant Java ecosystem, including Spring (Spring utilizes several key Jakarta EE technologies). Joining the Jakarta EE and MicroProfile groups complements our participation in the Java Community Process (JCP) to help advance Java SE.
Over the past few years, Microsoft has made substantial investments in offerings for Java, Jakarta EE, MicroProfile, and Spring technologies on Azure in collaboration with our strategic partners. With Red Hat, we’ve built a managed service for JBoss EAP on Azure App Service. We’re also collaborating with Red Hat to enable robust solutions for JBoss EAP on Virtual Machines (VMs) and Azure Red Hat OpenShift (ARO). With VMware, we jointly develop and support Azure Spring Apps (formerly Azure Spring Cloud), a fully managed service for Spring Boot applications. And with Oracle and IBM, we’ve been building solutions for customers to run WebLogic and WebSphere Liberty/Open Liberty on VMs, Azure Kubernetes Service, and ARO (WebSphere). Other work includes a first-party managed service to run Tomcat and Java SE (App Service) and Jakarta Messaging support in Azure Service Bus. Learn more about these Java EE, Jakarta EE, and MicroProfile on Azure offerings.
Our strategic partners
Microsoft is actively improving our support for running Quarkus on Azure, including on emerging platforms such as Azure Container Apps. The expanded investment in Jakarta EE and MicroProfile is a natural progression of our work to enable Java on Azure. Our broad and deep partnerships with key Java ecosystem stakeholders such as Oracle, IBM, Red Hat, and VMware power our Java on Azure work. These strategic partners share our enthusiasm for the Jakarta EE and MicroProfile journeys that Microsoft has embarked upon.
"We're thrilled to have an organization with the influence and reach of Microsoft joining the Jakarta EE Working Group. Microsoft has warmly embraced all things Java across its product and service portfolio, particularly Azure. Its enterprise customers can be confident that they will be actively participating in the further evolution of the Jakarta EE specifications which are defining enterprise Java for today's cloud-native world."—Mike Milinkovich, Executive Director, Eclipse Foundation.
“We welcome Microsoft to the Jakarta EE and MicroProfile Working Groups. We are pleased with our collaboration with Microsoft in delivering Oracle WebLogic Server solutions in Azure, which are helping customers to use Jakarta EE in the cloud. We look forward to more collaboration in the Jakarta EE and MicroProfile Working Groups.”—Tom Snyder, Vice President, Oracle Enterprise Cloud Native Java.
“IBM’s collaboration with Microsoft has shown Jakarta EE and MicoProfile running well in a number of Azure environments on the Liberty runtime, so it’s exciting to see Microsoft now joining the Jakarta EE and MicroProfile Working Groups. I look forward to seeing Microsoft bringing another perspective to the Working Groups based on their experience and needs for Azure customers.”—Ian Robinson, Chief Technology Officer, IBM Application Platform.
"It is great to see Microsoft officially join both MicroProfile and Jakarta EE as they'd been informally involved in these efforts for a long time. I hope to see Microsoft's participation bring experience from their many users and partners who have developed and deployed enterprise Java applications on Azure for several years."—Mark Little, Vice President, Software Engineering, Red Hat.
"We are excited to see Microsoft supporting the Jakarta EE Working Group. Jakarta EE serves as a key integration point for Spring applications and we look forward to the future evolution of common specifications like Servlet, JPA, and others. Microsoft delights developers with their continued support of the Java ecosystem along with their work with VMware on bringing a fully managed Spring service to Azure.”—Ryan Morgan, Vice President, Software Engineering, VMware.
Looking to the future
As part of the Jakarta EE and MicroProfile working groups, we’ll continue to work closely with our long-standing partners. We believe our experience with running Java workloads in the cloud will be valuable to the working groups, and we look forward to building a strong future for Java together with our customers, partners, and the community.
Learn more about Java on Azure offerings for Jakarta EE and MicroProfile.
Quelle: Azure