Mobilfunk: Telefónica, Telekom und Vodafone planen Hologramm-Telefonate
Mehrere europäische Mobilfunknetzbetreiber kooperieren, um netzübergreifend holografische Telefonate anbieten zu können. (Mobilfunk, Telekom)
Quelle: Golem

Mehrere europäische Mobilfunknetzbetreiber kooperieren, um netzübergreifend holografische Telefonate anbieten zu können. (Mobilfunk, Telekom)
Quelle: Golem
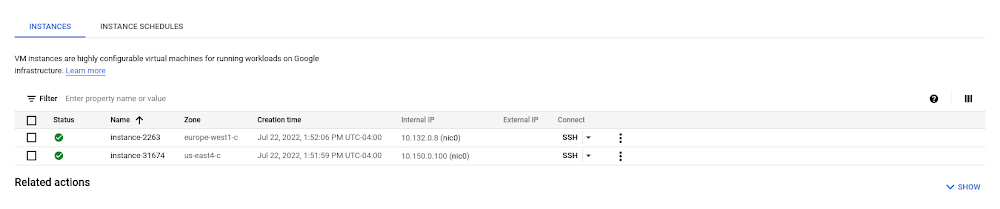
As the scope and size of your cloud deployments expand, the need for automation to quickly and consistently diagnose service-affecting issues increases in parallel. Connectivity Tests – part of the Network Intelligence Center capabilities focused on Google Cloud network observability, monitoring, and troubleshooting – help you quickly troubleshoot network connectivity issues by analyzing your configuration and, in some cases, validating the data plane by sending synthetic traffic. It’s common to start using Connectivity Tests in an ad hoc manner, for example, to determine whether an issue reported by your users is caused by a recent configuration change. Another popular use case for Connectivity Tests is to verify that applications and services are reachable post-migration, which helps verify that the cloud networking design is working as intended. Once workloads are migrated to Google Cloud, Connectivity Tests help prevent regressions caused by mis-configuration or maintenance issues. As you become more familiar with the power of Connectivity Tests, you may discover different use cases for running Connectivity Tests on a continuous basis. In this post, we’ll walk through a solution to continuously run Connectivity Tests.Scheduling Connectivity Tests leverages existing Google Cloud platform tools to continuously execute tests and surface failures through Cloud Monitoring alerts. We use the following products and tools as part of this solution:One or more Connectivity Tests to check connectivity between network endpoints by analyzing the cloud networking configuration and (when eligible) performing live data plane analysis between the endpoints.A single Cloud Function to programmatically run the Connectivity Tests using the Network Management API, and publish results to Cloud Logging.One or more Cloud Scheduler jobs that run the Connectivity Tests on a continuous schedule that you define.Operations Suite integrates logging, log-based metrics and alerting to surface test results that require your attention.Let’s get started.In this example there are two virtual machines running in different cloud regions of the same VPC.Connectivity TestsWe configure a connectivity test to verify that the VM instance in cloud region us-east4 can reach the VM instance in cloud region europe-west1 on port 443 using the TCP protocol. The following Connectivity Test UI example shows the complete configuration of the test.For more detailed information on the available test parameters, see the Connectivity Tests documentation.At this point you can verify that the test passes both the configuration and data plane analysis steps, which tells you that the cloud network is configured to allow the VM instances to communicate and the packets transmitted between the VM instances were successfully passed through the network.Before moving on to the next step, note the name of the connectivity test in URI format, which is visible in the equivalent REST response output:We’ll use this value as part of the Cloud Scheduler configuration in a later step.Create Cloud FunctionCloud Functions provide a way to interact with the Network Management API to run a connectivity test. While there are other approaches for interacting with the API, we take advantage of the flexibility in Cloud Functions to run the test and enrich the output we send to Cloud Logging. Cloud Functions also provide support for numerous programming languages, so you can adapt these instructions to the language of your choice. In this example, we use Python for interfacing with the Network Management API.Let’s walk through the high-level functionality of the code.First, the Cloud Function receives an HTTP request with the name of the connectivity test that you want to execute. By providing the name of the connectivity test as a variable, we can reuse the same Cloud Function for running any of your configured connectivity tests.code_block[StructValue([(u’code’, u’if http_request.method != ‘GET':rn return flask.abort(rn flask.Response(rn http_request.method +rn ‘ requests are not supported, use GET instead’,rn status=405))rn if ‘name’ not in http_request.args:rn return flask.abort(rn flask.Response(“Missing ‘name’ URL parameter”, status=400))rn test_name = http_request.args[‘name’]’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3ea6e88ebd90>)])]Next, the code runs the connectivity test specified using the Network Management API.code_block[StructValue([(u’code’, u’client = network_management_v1.ReachabilityServiceClient()rn rerun_request = network_management_v1.RerunConnectivityTestRequest(rn name=test_name)rn try:rn response = client.rerun_connectivity_test(request=rerun_request).result(rn timeout=60)’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3ea6dda3a250>)])]And finally, if the connectivity test fails for any reason, a log entry is created that we’ll later configure to generate an alert.code_block[StructValue([(u’code’, u”if (response.reachability_details.result !=rn types.ReachabilityDetails.Result.REACHABLE):rn entry = {rn ‘message':rn f’Reran connectivity test {test_name!r} and the result was ‘rn ‘unreachable’,rn ‘logging.googleapis.com/labels': {rn ‘test_resource_id': test_namern }rn }rn print(json.dumps(entry))”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3ea6f4a04dd0>)])]There are a couple of things to note about this last portion of sample code:We define a custom label (test_resource_id: test_name) used when a log entry is written. We’ll use this as part of the logs-based metric in a later step.We only write a log entry when the connectivity test fails. You can customize the logic for other use cases, for example logging when tests that you expect to fail succeed or writing logs for successful and unsuccessful test results to generate a ratio metric.The full example code for the Cloud Function is below.code_block[StructValue([(u’code’, u’import jsonrnimport flaskrnfrom google.api_core import exceptionsrnfrom google.cloud import network_management_v1rnfrom google.cloud.network_management_v1 import typesrnrnrndef rerun_test(http_request):rn “””Reruns a connectivity test and prints an error message if the test fails.”””rn if http_request.method != ‘GET':rn return flask.abort(rn flask.Response(rn http_request.method +rn ‘ requests are not supported, use GET instead’,rn status=405))rn if ‘name’ not in http_request.args:rn return flask.abort(rn flask.Response(“Missing ‘name’ URL parameter”, status=400))rn test_name = http_request.args[‘name’]rn client = network_management_v1.ReachabilityServiceClient()rn rerun_request = network_management_v1.RerunConnectivityTestRequest(rn name=test_name)rn try:rn response = client.rerun_connectivity_test(request=rerun_request).result(rn timeout=60)rn if (response.reachability_details.result !=rn types.ReachabilityDetails.Result.REACHABLE):rn entry = {rn ‘message':rn f’Reran connectivity test {test_name!r} and the result was ‘rn ‘unreachable’,rn ‘logging.googleapis.com/labels': {rn ‘test_resource_id': test_namern }rn }rn print(json.dumps(entry))rn return flask.Response(status=200)rn except exceptions.GoogleAPICallError as e:rn print(e)rn return flask.abort(500)’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3ea6dfe39b10>)])]We use the code above and create a Cloud Function named run_connectivity_test. Use the default trigger type of HTTP and make note of the trigger URL to use in a later stepcode_block[StructValue([(u’code’, u’https://us-east4-project6.cloudfunctions.net/run_connectivity_test’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3ea6df0fcf10>)])]Under Runtime, build, connections and security settings, increase the Runtime Timeout to 120 seconds.For the function code, select Python for the Runtime.For main.py, use the sample code provided above and configure the following dependencies for the Cloud Function in requirements.txt.code_block[StructValue([(u’code’, u’# Function dependencies, for example:rn# package>=versionrngoogle-cloud-network-management>=1.3.1rngoogle-api-core>=2.7.2′), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3ea6df0fc590>)])]Click Deploy and wait for the Cloud Function deployment to complete.Cloud SchedulerThe functionality to execute the Cloud Function on a periodic schedule is accomplished using Cloud Scheduler. A separate Cloud Scheduler job is created for each connectivity test you want to schedule.The following Cloud Console example shows the Cloud Scheduler configuration for our example.Note that the Frequency is specified in unix-cron format and in our example schedules the Cloud Function to run once an hour. Make sure you take the Connectivity Tests pricing into consideration when configuring the frequency of the tests.The URL parameter of the execution configuration in the example below is where we bring together the name of the connectivity test and the Cloud Function trigger from the previous steps. The format of the URL is{cloud_function_trigger}?name={connectivity-test-name}In our example, the URL is configured as:https://us-east4-project6.cloudfunctions.net/run_connectivity_test?name=projects/project6/locations/global/connectivityTests/inter-region-test-1The following configuration options complete the Cloud Scheduled configuration:Change the HTTP method to GET.Select Add OIDC token for the Auth header.Specify a service account that has the Cloud Function invoker permission for your Cloud Function.Set the Audience to the URL minus the query parameters, e.g.:https://us-east4-project6.cloudfunctions.net/run_connectivity_testLogs-based MetricThe Logs-based metric will convert unreachable log entries created by our Cloud Function into a Cloud Monitoring metric that we can use to create an alert. We start by configuring a Counter logs-based metric named unreachable_connectivity_tests. Next, configure a filter to match the `test_resource_id` label that is included in the unreachable log messages.The complete metric configuration is shown below.Alerting PolicyThe Alerting Policy is triggered any time the logs-based metric increments, indicating that one of the continuous connectivity tests has failed. The alert includes the name of the test that failed, allowing you to quickly focus your effort on the resources and traffic included in the test parameters.To create a new Alerting Policy, select the logging/user/unreachable_connectivity_test metric for the Cloud Function resource.Under Transform data, configure the following parameters:Within each time seriesRolling window = 2 minutesRolling window function = rateAcross time seriesTime series aggregation = sumTime series group by = test_resource_idNext, configure the alert trigger using the parameters shown in the figure below.Finally, configure the Documentation text field to include the name of the specific test that logged an unreachable result.Connectivity Tests provide critical insights into the configuration and operation of your cloud networking environment. By combining multiple Google Cloud services, you can transform your Connectivity Tests usage from an ad-hoc troubleshooting tool to a solution for ongoing service validation and issue detection.We hope you found this information useful. For a more in-depth look into Network Intelligence Center check out the What is Network Intelligence Center? post and our documentation.Related ArticleWhat is Network Intelligence Center?Network Intelligence Center provides a single console for managing Google Cloud network observability, monitoring, and troubleshooting.Read Article
Quelle: Google Cloud Platform
At Google, we are constantly looking to improve our products, services, and contracts so that we can better serve our customers. To this end, we are pleased to announce that we have updated and merged our data processing terms for Google Cloud, Google Workspace (including Workspace for Education), and Cloud Identity (when purchased separately) into one combined Cloud Data Processing Addendum (the “CDPA”).The CDPA maintains the benefits of the previously separate Data Processing and Security Terms for Google Cloud customers and Data Processing Amendment for Google Workspace and Cloud Identity customers, while streamlining and strengthening Google’s data processing commitments. A corresponding new CDPA (Partners) offers equivalent commitments to Google Cloud partners. As part of this update, we have also incorporated the new international data transfer addendum issued by the U.K. Information Commissioner (“U.K. Addendum”). The U.K. Addendum allows the EU Standard Contractual Clauses (“SCCs”) to be used for transfers of personal data under the U.K. GDPR, replacing the separate U.K. SCCs that previously formed part of our terms. For an overview of the European legal rules for data transfers and our approach to implementing the EU SCCs and U.K. Addendum, please see our updated whitepaper. You can view our SCCs here.While our data processing terms have been renamed, consolidated, and updated, our commitment to protecting the data of all Google Cloud, Workspace and Cloud Identity customers and all Google Cloud partners, and to enabling their compliance with data transfer and other regulatory requirements, remains unchanged.For more information about our privacy commitments for Google Cloud, Google Workspace, and Cloud Identity, please see our Privacy Resource Center.Related ArticleLeading towards more trustworthy compliance through EU Codes of ConductGoogle Cloud explains how its public commitment to supporting EU data protection requirements can help develop more trustworthy complianc…Read Article
Quelle: Google Cloud Platform

Many machine learning (ML) use cases, like fraud detection, ad targeting, and recommendation engines, require near real-time predictions. The performance of these predictions is heavily dependent on access to the most up-to-date data, with delays of even a few seconds making all the difference. But it’s difficult to set up the infrastructure needed to support high-throughput updates and low-latency retrieval of data. Starting this month, Vertex AI Matching Engine and Feature Store will support real-time Streaming Ingestion as Preview features. With Streaming Ingestion for Matching Engine, a fully managed vector database for vector similarity search, items in an index are updated continuously and reflected in similarity search results immediately. With Streaming Ingestion for Feature Store, you can retrieve the latest feature values with low latency for highly accurate predictions, and extract real-time datasets for training. For example, Digits is taking advantage of Vertex AI Matching Engine Streaming Ingestion to help power their product, Boost, a tool that saves accountants time by automating manual quality control work.“Vertex AI Matching Engine Streaming Ingestion has been key to Digits Boost being able to deliver features and analysis in real-time. Before Matching Engine, transactions were classified on a 24 hour batch schedule, but now with Matching Engine Streaming Ingestion, we can perform near real time incremental indexing – activities like inserting, updating or deleting embeddings on an existing index, which helped us speed up the process. Now feedback to customers is immediate, and we can handle more transactions, more quickly,” said Hannes Hapke, Machine Learning Engineer at Digits.This blog post covers how these new features can improve predictions and enable near real-time use cases, such as recommendations, content personalization, and cybersecurity monitoring.Streaming Ingestion enables you to serve valuable data to millions of users in real time.Streaming Ingestion enables real-time AIAs organizations recognize the potential business impact of better predictions based on up-to-date data, more real-time AI use cases are being implemented. Here are some examples:Real-time recommendations and a real-time marketplace: By adding Streaming Ingestion to their existing Matching Engine-based product recommendations, Mercari is creating a real-time marketplace where users can browse products based on their specific interests, and where results are updated instantly when sellers add new products. Once it’s fully implemented, the experience will be like visiting an early-morning farmer’s market, with fresh food being brought in as you shop. By combining Streaming Ingestion with Matching Engine’s filtering capability, Mercari can specify whether or not an item should be included in the search results, based on tags such as “online/offline” or “instock/nostock.”Mercari Shops: Streaming Ingestion enables real-time shopping experimenLarge-scale personalized content streaming: For any stream of content representable with feature vectors (including text, images, or documents), you can design pub-sub channels to pick up valuable content for each subscriber’s specific interests. Because Matching Engine is scalable (i.e., it can process millions of queries each second), you can support millions of online subscribers for content streaming, serving a wide variety of topics that are changing dynamically. With Matching Engine’s filtering capability, you also have real-time control over what content should be included, by assigning tags such as “explicit” or “spam” to each object. You can use Feature Store as a central repository for storing and serving the feature vectors of the contents in near real time.Monitoring: Content streaming can also be used for monitoring events or signals from IT infrastructure, IoT devices, manufacturing production lines, and security systems, among other commercial use cases. For example, you can extract signals from millions of sensors and devices and represent them as feature vectors. Matching Engine can be used to continuously update a list of “the top 100 devices with possible defective signals,” or “top 100 sensor events with outliers,” all in near real time.Threat/spam detection: If you are monitoring signals from security threat signatures or spam activity patterns, you can use Matching Engine to instantly identify possible attacks from millions of monitoring points. In contrast, security threat identification based on batch processing often involves potentially significant lag, leaving the company vulnerable. With real-time data, your models are better able to catch threats or spams as they happen in your enterprise network, web services, online games, etc.Implementing streaming use casesLet’s take a closer look at how you can implement some of these use cases. Real-time recommendations for retailMercari built a feature extraction pipeline with Streaming Ingestion.Mercari’s real-time feature extraction pipelineThe feature extraction pipeline is defined with Vertex AI Pipelines, and is periodically invoked by Cloud Scheduler and Cloud Functions to initiate the following process:Get item data: The pipeline issues a query to fetch the updated item data from BigQuery.Extract feature vector: The pipeline runs predictions on the data with the word2vec model to extract feature vectors.Update index: The pipeline calls Matching Engine APIs to add the feature vectors to the vector index. The vectors are also saved to Cloud Bigtable (and can be replaced with Feature Store in the future).”We have been evaluating the Matching Engine Streaming Ingestion and couldn’t believe the super short latency of the index update for the first time. We would like to introduce the functionality to our production service as soon as it becomes GA, ” said Nogami Wakana, Software Engineer at Souzoh (a Mercari group company).This architecture design can be also applied to any retail businesses that need real-time updates for product recommendations.Ad targetingAd recommender systems benefit significantly from real-time features and item matching with the most up-to-date information. Let’s see how Vertex AI can help build a real-time ad targeting system.Real-time ad recommendation systemThe first step is generating a set of candidates from the ad corpus. This is challenging because you must generate relevant candidates in milliseconds and ensure they are up to date. Here you can use Vertex AI Matching Engine to perform low-latency vector similarity matching, generate suitable candidates, and use Streaming Ingestion to ensure that your index is up-to-date with the latest ads. Next is reranking the candidate selection using a machine learning model to ensure that you have a relevant order of ad candidates. For the model to use the latest data, you can use Feature Store Streaming Ingestion to import the latest features and use online serving to serve feature values at low latency to improve accuracy. After reranking the ads candidates, you can apply final optimizations, such as applying the latest business logic. You can implement the optimization step using a Cloud Function or Cloud Run. What’s Next?Interested? The documents for Streaming Ingestion are available and you can try it out now. Using the new feature is easy: For example, when you create an index on Matching Engine with the REST API, you can specify the indexUpdateMethod attribute as STREAM_UPDATE.code_block[StructValue([(u’code’, u'{rn displayName: “‘${DISPLAY_NAME}'”, rn description: “‘${DISPLAY_NAME}'”,rn metadata: {rn contentsDeltaUri: “‘${INPUT_GCS_DIR}'”, rn config: {rn dimensions: “‘${DIMENSIONS}'”,rn approximateNeighborsCount: 150,rn distanceMeasureType: “DOT_PRODUCT_DISTANCE”,rn algorithmConfig: {treeAhConfig: {leafNodeEmbeddingCount: 10000, leafNodesToSearchPercent: 20}}rn },rn },rn indexUpdateMethod: “STREAM_UPDATE”rn}’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3ea55bfb7910>)])]After deploying the index, you can update or rebuild the index (feature vectors) with the following format. If the data point ID exists in the index, the data point is updated, otherwise, a new data point is inserted.code_block[StructValue([(u’code’, u'{rn datapoints: [rn {datapoint_id: “‘${DATAPOINT_ID_1}'”, feature_vector: […]}, rn {datapoint_id: “‘${DATAPOINT_ID_2}'”, feature_vector: […]}rn ]rn}’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3ea55bfa3d50>)])]It can handle the data point insertion/update at high throughput with low latency. The new data point values will be applied in any new queries within a few seconds or milliseconds (the latency varies depending on the various conditions). The Streaming Ingestion is a powerful functionality and very easy to use. No need to build and operate your own streaming data pipeline for real-time indexing and storage. Yet, it adds significant value to your business with its real-time responsiveness.To learn more, take a look at the following blog posts for learning Matching Engine and Feature Store concepts and use cases:Vertex Matching Engine: Blazing fast and massively scalable nearest neighbor searchFind anything blazingly fast with Google’s vector search technologyKickstart your organization’s ML application development flywheel with the Vertex Feature StoreMeet AI’s multitool: Vector embeddingsRelated ArticleHow Let’s Enhance uses NVIDIA AI and GKE to power AI-based photo editingLet’s Enhance uses AI to beautify images. GKE provides auto-provisioning, autoscaling and simplicity, while GPUs provide superior process…Read Article
Quelle: Google Cloud Platform

This blog post was co-authored by Paul Dejager, OSDU Practice Lead, Wipro.
Since its first customer-ready release, the OSDU™ Data Platform has been tested and piloted within the energy industry with great success. However, customers have been awaiting an enterprise-ready version of the OSDU Data Platform that is secure, resilient, and backed up by SLAs. The platform needs to provide connectivity with the legacy and cloud applications and be extensible and customizable for customer-specific scenarios. Partners like Wipro blend domain experience with the OSDU Data Platform to help accelerate the operationalization of Microsoft Energy Data Services.
Microsoft Energy Data Services is a fully managed, enterprise-grade data platform that enables efficient data management, standardization, liberation, and consumption in energy exploration. The solution is a hyperscale data ecosystem that leverages the capabilities of the OSDU Data Platform, and Microsoft's secure and trustworthy cloud services with our partners’ extensive domain expertise.
A significant constraint with today’s industry business platforms is the strong bias of first principles analysis with a domain value chain that strongly preconditions the way that data is used and when. Data is siloed within the stages of the value chain and locked up by the applications supporting the workflows in these stages. The growing need and demand for data-driven analysis to complement first principles analysis, and for business workflows to also leverage advanced analytics and machine learning (AI/ML) applications are largely unsatisfied.
The OSDU Forum is an open source consortium of energy operators, which has set out to design and develop a cloud-native data platform. Wipro is a key contributor and helps address the data issue by providing self-service consumption of analytics-ready data. This is a critical objective of Wipro’s participation in the OSDU Forum.
Current data management technologies creates substantial lock-in and require significant amounts of effort to run and maintain cost-effective infrastructure. A move to the cloud potentially reduces lockin and running costs and paves the way towards "pay-for-use" rather than "pay-to-own." The existing data foundation platforms are complex, dominated by service and technology providers, and do not readily maximize the benefit of emerging technologies, such as data interoperability and analytics, due to significant legacy content. Furthermore, to date within E&P there has only been limited acceptance of technologies arising from other industries, including the adoption of cloud and Open Source.
Wipro and Microsoft partner to provide new technologies to enterprise-level organizations
With Microsoft Energy Data Services, Wipro is offering to adopt an open architecture that provides accelerated access to new technologies through an open, modular cloud agnostic design. Based primarily on existing generic IT components, the solution provides a data foundation that decouples applications from their data source and further reduces operating costs through the adoption of a cloud hosting environment. Moving to a cloud-based data foundation provides considerable benefits to an enterprise including:
A centralized data landscape containing fewer database instances designed to meet the anticipated increase in storage capacity occasioned by the acquisition of real-time data and the introduction of fiber optics for drilling, downhole sensors, and the internet of things (IoT).
Higher consistency of data, simplified workflows, reduced complexity, and an analytical user interface result in increased automation that facilitates a switch to self-service operation.
Real-time data acquisition to cloud and centralized delivery to cloud for other sources of data (vendor, partner, release, and more).
Deliverable as a service (SaaS and PaaS), thereby significantly reducing support training costs and overall cost of ownership (TCO).
Reduced tie-in to products from traditional service contractors.
Provision of a long-term, low-cost digital archive for all drilling and well-logging data and analyses.
The benefits of the OSDU data as a service model
The OSDU Data Platform enabled and supported by Microsoft Energy Data Services provides many solutions to business challenges, including:
Faster deployment with automated service offerings
Easier deployment of OSDU Data Platform functionality
New insights with domain workflows and application integration with any data source
Data-driven decisions, performance improvement, and data ready to leverage HPC and AI/ML scenarios
Reduced cycle time, enabling developers to quickly develop and integrate new applications and scenarios
Legacy decommissioning
Open source
Scalable due to cloud
TCO reduction
Analytics, automation across datasets, and the entire value chain
Reduced vendor lock-in
Wipro and the OSDU Data Platform
Understanding the E&P domain and full comprehension of the various data types and data formats forms a key component of Wipro’s offering. Specifically, Wipro’s domain expertise is a clear differentiator that has been successfully leveraged in similar engagements for other operators. This domain knowledge in every part of the upstream value chain has been brought together in Wipro’s dedicated global OSDU Data Platform practice. When this E&P expertise is coupled with Wipro’s big data service capabilities, the combination of these two perspectives provides a truly 360-degree domain-driven service.
Wipro has been designated the Azure Cloud Service Provider (CSP)-preferred global OSDU systems integrator, and Wipro thus has a strategic partnership for OSDU activities that ensures Wipro and Azure CSP work together where it partners as a "one badge" team on all Microsoft Energy Data Services deployments. This optimizes the cooperation and coordination between cloud provider and systems integrator, which will be a significant benefit to clients aiming to implement the OSDU Data Platform as their standard system of record. This assured level of collaboration, together with the experience of both parties, ensures that Wipro is well positioned to quickly jump-start any OSDU Data Platform journey to liberate and integrate subsurface data.
Wipro is a member of, and a major contributor to, the OSDU Forum. Wipro has authored developing standards as put forward by the OSDU Forum, and its prominent participation in the OSDU activities enables it to assure seamless integration between data platform onboarding and data loading, and legacy data and application platforms. Wipro fully understands the strategic importance and value of data, and the OSDU Data Platform will be distinguished by its ability to provide a digital data portal. Wipro is, and has, made significant investments in people, solutions, and capabilities to build a dedicated OSDU Data Platform practice to provide a high level of service. Further, Wipro has invested in a sustainable staffing model going forward by leveraging its global footprint and strategic partnerships. Wipro regularly works remotely on OSDU Data Platform deployments and therefore does not foresee any impediment to working in a worldwide implementation environment.
Wipro has a templated deployment approach and can bring its own tools and utilities to enhance, where appropriate, the standard OSDU data platform. This enables Wipro to securely deploy and configure functional, information security–compliant Microsoft Energy Data Services in an Azure subscription.
Wipro’s standard deployment comprises three workstreams, as follows:
Deploy the OSDU Data Platform with Microsoft Energy Data Services in the client’s own or hosted Azure subscription so it can be securely operated.
Ingest existing client subsurface data that is aligned with the OSDU Technical Standard, provide knowledge transfer to business stakeholders, and provide insight on how to leverage the OSDU data platform to increase business value.
Develop a Microsoft Energy Data Services roadmap and evaluate operating model alternatives for optimal business value, and promote understanding of tools and workflows that promote integration and adoption of the OSDU Data Platform.
Wipro services and accelerators
Wipro has invested significantly in helping companies on their OSDU Data Platform adoption journey and as such has developed services that provide open source functionality over and above the standard OSDU Data Platform offering.
Platform onboarding
Dataset and user onboarding
Data migration
Data ingestion
WINS framework
External data access and publish scenarios
Application integration
Data discovery
The following screenshots provide an example of a Power BI business intelligence dashboard containing data sourced from an OSDU Data Platform using the native Power BI application connector.
Customized search and display functionality can be achieved via Bing search service APIs and/or OSDU-compliant third-party software vendors.
Wipro’s OSDU Data Platform practice uses the combined knowledge, skills, and operational delivery capabilities from the combination of Wipro’s domain and consulting, engineering, and cloud platform verticals to provide an innovative horizontal solution offering.
This enables our clients to:
Accelerate their end game to digital transformation.
Make their organizations data-centric via the OSDU data platform.
Enable the refactoring, integration, and deployment of workflow interoperability.
Prioritize their data and prepare for OSDU migration at scale.
Define and achieve inter-organizational collaboration and operational support model requirements.
How to work with Wipro Services and Accelerator on Microsoft Energy Data Services
Microsoft Energy Data Services is an enterprise-grade, fully managed, OSDU Data Platform for the energy industry that is efficient, standardized, easy to deploy, and scalable for data management—for ingesting, aggregating, storing, searching, and retrieving data. The platform can provide the scale, security, privacy, and compliance expected by enterprise customers. Wipro offers services and accelerators utilizing the WINS framework which accelerates time-to-market and the ability to run domain workflows with ease, with data contained in Microsoft Energy Data Services, and with minimal effort.
Learn More
Read additional information on Wipro OSDU services and accelerators for Oil and Gas Data Management.
For further information on how Wipro can assist your organization, please contact: Paul Dejager paul.dejager@wipro.com, Graham Cain graham.cain@wipro.com, and Kamal Jansen kamal.jansen@wipro.com.
Get started with Microsoft Energy Data Services today.
Quelle: Azure
Continuous Integration (CI) is a key element of cloud native application development. With containers forming the foundation of cloud-native architectures, developers need to integrate their version control system with a CI tool.
There’s a myth that continuous integration needs a cloud-based infrastructure. Even though CI makes sense for production releases, developers need to build and test the pipeline before they can share it with their team — or have the ability to perform the continuous integration (CI) on their laptop. Is that really possible today?
Introducing the Drone CI pipeline
An open-source project called Drone CI makes that a reality. With over 25,700 GitHub stars and 300-plus contributors, Drone is a cloud-native, self-service CI platform. Drone CI offers a mature, container-based system that leverages the scaling and fault-tolerance characteristics of cloud-native architectures. It helps you build container-friendly pipelines that are simple, decoupled, and declarative.
Drone is a container based pipeline engine that lets you run any existing containers as part of your pipeline or package your build logic into reusable containers called Drone Plugins.
Drone plugins are configurable based on the need and that allows distributing the container within your organization or to the community in general.
Running Drone CI pipelines from Docker Desktop
For a developer working with decentralized tools, the task of building and deploying microservice applications can be monumental. It’s tricky to install, manage, and use these apps in those environments. That’s where Docker Extensions come in. With Docker Extensions, developer tools are integrated right into Docker Desktop — giving you streamlined management workflows. It’s easier to optimize and transform your development processes.
The Drone CI extension for Docker Desktop brings CI to development machines. You can now import Drone CI pipelines into Docker Desktop and run them locally. You can also run specific steps of a pipeline, monitor execution results, and inspect logs.
Setting up a Drone CI pipeline
In this guide, you’ll learn how to set up a Drone CI pipeline from scratch on Docker Desktop.
First, you’ll install the Drone CI Extension within Docker Desktop. Second, you’ll learn how to discover Drone pipelines. Third, you’ll see how to open a Drone pipeline on Visual Studio Code. Lastly, you’ll discover how to run CI pipelines in trusted mode, which grants them elevated privileges on the host machine. Let’s jump in.
Prerequisites
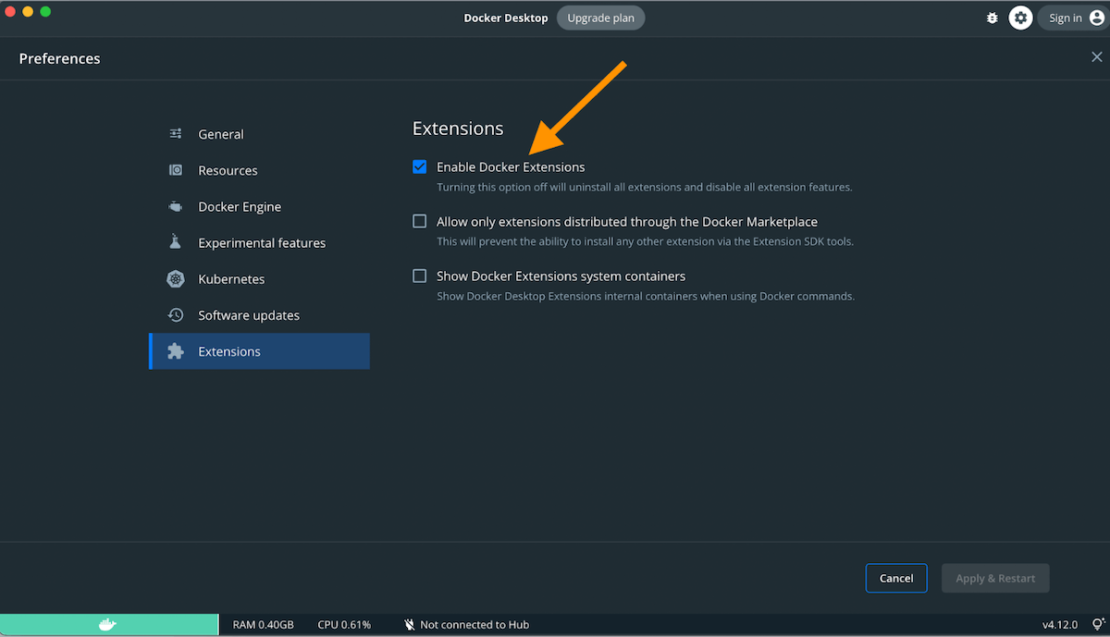
You’ll need to download Docker Desktop 4.8 or later before getting started. Make sure to choose the correct version for your OS and then install it.
Next, hop into Docker Desktop and confirm that the Docker Extensions feature is enabled. Click the Settings gear > Extensions tab > check the “Enable Docker Extensions” box.
Installing the Drone CI Docker extension
Drone CI isn’t currently available on the Extensions Marketplace, so you’ll have to download it via the CLI. Launch your terminal and run the following command to install the Drone CI Extension:
docker extension install drone/drone-ci-docker-extension:latest
The Drone CI extension will soon appear in the Docker Dashboard’s left sidebar, underneath the Extensions heading:
Import Drone pipelines
You can click the “Import Pipelines” option to specify the host filesystem path where your Drone CI pipelines (drone.yml files) are. If this is your first time with Drone CI pipelines, you can use the examples from our GitHub repo.
In the recording above, we’ve used the long-run-demo sample to run a local pipeline that executes a long running sleep command. This occurs within a Docker container.
kind: pipeline
type: docker
name: sleep-demos
steps:
– name: sleep5
image: busybox
pull: if-not-exists
commands:
– x=0;while [ $x -lt 5 ]; do echo "hello"; sleep 1; x=$((x+1)); done
– name: an error step
image: busybox
pull: if-not-exists
commands:
– yq –help
You can download this pipeline YAML file from the Drone CI GitHub page.
The file starts with a pipeline object that defines your CI pipeline. The type attribute defines your preferred runtime while executing that pipeline.
Drone supports numerous runners like docker, kubernetes, and more. The extension only supports docker pipelines currently.Each pipeline step spins up a Docker container with the corresponding image defined as part of the step image attribute.
Each step defines an attribute called commands. This is a list of shell commands that we want to execute as part of the build. The defined list of commands will be converted into shell script and set as Docker container’s ENTRYPOINT. If any command (for example, the missing yq command, in this case) returns a non-zero exit code, the pipeline fails and exits.
Edit your pipeline faster in VS Code via Drone CI
Visual Studio Code (VS Code) is a lightweight, highly-popular IDE. It supports JavaScript, TypeScript, and Node.js. VS Code also has a rich extensions ecosystem for numerous other languages and runtimes.
Opening your Drone pipeline project in VS Code takes just seconds from within Docker Desktop:
This feature helps you quickly view your pipeline and add, edit, or remove steps — then run them from Docker Desktop. It lets you iterate faster while testing new pipeline changes.
Running specific steps in the CI pipeline
The Drone CI Extension lets you run individual steps within the CI pipeline at any time. To better understand this functionality, let’s inspect the following Drone YAML file:
kind: pipeline
type: docker
name: sleep-demos
steps:
– name: sleep5
image: busybox
pull: if-not-exists
commands:
– x=0;while [ $x -lt 5 ]; do echo "hello"; sleep 1; x=$((x+1)); done
– name: an error step
image: busybox
pull: if-not-exists
commands:
– yq –help
In this example, the first pipeline step defined as sleep5 lets you execute a shell script (echo “hello”) for five seconds and then stop (ignoring an error step).The video below shows you how to run the specific sleep-demos stage within the pipeline:
Running steps in trusted mode
Sometimes, you’re required to run a CI pipeline with elevated privileges. These privileges enable a user to systematically do more than a standard user. This is similar to how we pass the –privileged=true parameter within a docker run command.
When you execute docker run –privileged, Docker will permit access to all host devices and set configurations in AppArmor or SELinux. These settings may grant the container nearly equal access to the host as processes running outside containers on the host.
Drone’s trusted mode tells your container runtime to run the pipeline containers with elevated privileges on the host machine. Among other things, trusted mode can help you:
Mount the Docker host socket onto the pipeline containerMount the host path to the Docker container
Run pipelines using environment variable files
The Drone CI Extension lets you define environment variables for individual build steps. You can set these within a pipeline step. Like docker run provides a way to pass environment variables to running containers, Drone lets you pass usable environment variables to your build. Consider the following Drone YAML file:
kind: pipeline
type: docker
name: default
steps:
– name: display environment variables
image: busybox
pull: if-not-exists
commands:
– printenv
The file starts with a pipeline object that defines your CI pipeline. The type attribute defines your preferred runtime (Docker, in our case) while executing that pipeline. The platform section helps configure the target OS and architecture (like arm64) and routes the pipeline to the appropriate runner. If unspecified, the system defaults to Linux amd64.
The steps section defines a series of shell commands. These commands run within a busybox Docker container as the ENTRYPOINT. As shown, the command prints the environment variables if you’ve declared the following environment variables in your my-env file:
DRONE_DESKTOP_FOO=foo
DRONE_DESKTOP_BAR=bar
You can choose your preferred environment file and run the CI pipeline (pictured below):
If you try importing the CI pipeline, you can print every environment variable.
Run pipelines with secrets files
We use repository secrets to store and manage sensitive information like passwords, tokens, and ssh keys. Storing this information as a secret is considered safer than storing it within a plain text configuration file.
Note: Drone masks all values used from secrets while printing them to standard output and error.
The Drone CI Extension lets you choose your preferred secrets file and use it within your CI pipeline as shown below:
Remove pipelines
You can remove a CI pipeline in just one step. Select one or more Drone pipelines and remove them by clicking the red minus (“-”) button on the right side of the Dashboard. This action will only remove the pipelines from Docker Desktop — without deleting them from your filesystem.
Bulk remove all pipelines
Remove a single pipeline
Conclusion
Drone is a modern, powerful, container-friendly CI that empowers busy development teams to automate their workflows. This dramatically shortens building, testing, and release cycles. With a Drone server, development teams can build and deploy cloud apps. These harness the scaling and fault-tolerance characteristics of cloud-native architectures like Kubernetes.
Check out Drone’s documentation to get started with CI on your machine. With the Drone CI extension, developers can now run their Drone CI pipelines locally as they would in their CI systems.
Want to dive deeper into Docker Extensions? Check out our intro documentation, or discover how to build your own extensions.
Quelle: https://blog.docker.com/feed/
Amazon QuickSight unterstützt jetzt „Fehlende Daten“-Kontrolle für sowohl Linien- als auch Flächendiagramme. Zuvor unterstützten Liniendiagramme die „Fehlende Daten“-Funktion nur für Datetime-Felder. Wir haben jetzt Unterstützung für kategorische Daten und sowohl für Linien- als auch Flächendiagramme hinzugefügt. Statt durchbrochene Linien anzuzeigen (Standardvorgehen), können Autoren auch entweder entscheiden, durchbrochene Linien als durchgehende Linien anzeigen zu lassen, indem mit dem nächsten verfügbaren Datenpunkt der Reihe verbunden wird, oder können die fehlenden Werte mit null benennen und so durchgehende Linien anzeigen. Weitere Details finden Sie hier.
Quelle: aws.amazon.com
Mit Amazon SageMaker können Kunden ML-Modelle bereitstellen, um für jeden Anwendungsfall Vorhersagen (auch Inferenz genannt) zu treffen. Sie können für die Echtzeit- und Asynchrone-Inferenz-Optionen von Amazon SageMaker jetzt große Modelle (bis zu 500 GB) bereitstellen, indem Sie die maximalen EBS-Volume-Größe und Timeout-Kontingente konfigurieren. Mit dieser Einführung können Kunden die vollständig verwalteten Echtzeit- und Asynchrone-Inferenz-Fähigkeiten von SageMaker nutzen, um große ML-Modelle, wie Varianten von GPT und OPT, bereitzustellen und zu verwalten.
Quelle: aws.amazon.com
Hosted UI von Amazon Cognito ermöglicht es Endbenutzern jetzt, ihre eigenen Authentifikator-Apps zu registrieren. Kunden können es Benutzern nun ermöglichen, über eine Authentifikator-App mit entweder SMS-gesteuerten Einmalpasswörtern (OTP) oder zeitgesteuerten Einmalpasswörtern (TOTP) die Selbstregistrierung vorzunehmen. Administratoren müssen keine Endbenutzerregistrierung mehr initiieren, wenn sie TOTP mit Hosted UI verwenden. Mit dieser neuen Erweiterung erhalten Entwickler, die Hosted UI nutzen, jetzt die gleiche Sicherheitsebene wie vorher, ohne dafür aber benutzerdefinierten Code entwickeln zu müssen; sie können sich auf Verbesserungen an der Anwendung konzentrieren. Administratoren müssen nun weniger Zeit dafür aufwenden, Endbenutzer auf eine höhere Ebene der Authentifizierungssicherheit einzugliedern. Endbenutzer der Anwendung können jetzt auch ihre eigenen Authentifikator-Apps hinzufügen und beim Zugriff auf Anwendungen, die Cognito hosted UI verwenden, Multi-Faktor-Authentifizierung (MFA) nutzen. Kunden erhalten ohne Zusatzkosten eine höhere Authentifizierungsebene für ihre Anwendungen.
Quelle: aws.amazon.com
Amazon Kinesis Data Analytics für Apache Flink veröffentlicht jetzt drei neue Metriken auf Container-Ebene für Amazon CloudWatch: CPU-Auslastung, Speicherauslastung und Festplattenauslastung für Flink Task Manager. Task Manager sind die Arbeiterknoten einer Flink-Anwendung, die die Datenverarbeitung durchführen. Diese neuen Metriken bieten einen besseren Überblick über die Task-Manager-Ressourcennutzung und können verwendet werden, um in Kinesis Data Analytics ausgeführte Anwendungen ganz einfach zu skalieren.
Quelle: aws.amazon.com