Integrating ML models into production pipelines with Dataflow
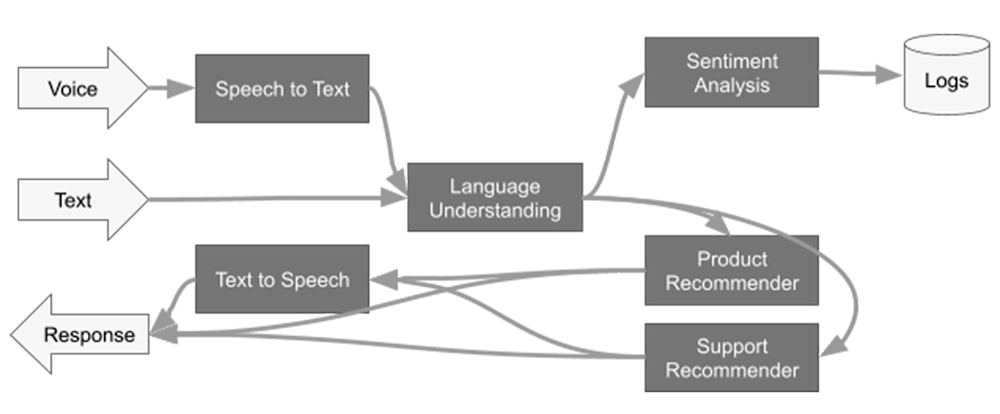
Google Cloud’s Dataflow recently announced the General Availability support for Apache Beam’s generic machine learning prediction and inference transform, RunInference. In this blog, we will take a deeper dive on the transform, including:Showing the RunInference transform used with a simple model as an example, in both batch and streaming mode.Using the transform with multiple models in an ensemble.Providing an end-to-end pipeline example that makes use of an open source model from Torchvision. In the past, Apache Beam developers who wanted to make use of a machine learning model locally, in a production pipeline, had to hand-code the call to the model within a user defined function (DoFn), taking on the technical debt for layers of boilerplate code. Let’s have a look at what would have been needed:Load the model from a common location using the framework’s load method.Ensure that the model is shared amongst the DoFns, either by hand or via the shared class utility in Beam.Batch the data before the model is invoked to improve the model efficiency. The developer would set this up, either by hand or via one of the groups into batches utilities.Provide a set of metrics from the transform.Provide production grade logging and exception handling with clean messages to help that SRE out at 2 in the morning! Pass specific parameters to the models, or start to build a generic transform that allows the configuration to determine information within the model. And of course these days, companies need to deploy many models, so the data engineer begins to do what all good data engineers do and builds out an abstraction for the models. Basically, each company is building out their own RunInference transform! Recognizing that all of this activity is mostly boilerplate regardless of the model, the RunInference API was created. The inspiration for this API comes from the tfx_bsl.RunInference transform that the good folks over at TensorFlow Extended built to help with exactly the issues described above. tfx_bsl.RunInference was built around TensorFlow models. The new Apache Beam RunInference transform is designed to be framework agnostic and easily composable in the Beam pipeline. The signature for RunInference takes the form of RunInference(model_handler), where the framework-specific configuration and implementation is dealt with in the model_handler configuration object. This creates a clean developer experience and allows for new frameworks to be easily supported within the production machine learning pipeline, without disrupting the developer workflow.. For example, NVIDIA is contributing to the Apache Beam project to integrateNVIDIA TensorRTTM, an SDK that can optimize trained models for deployment with the highest throughput and lowest latency on NVIDIA GPUs within Google Dataflow (PullRequest). Beam Inference also allows developers to make full use of the versatility of Apache Beam’s pipeline model, making it easier to build complex multi-model pipelines with minimum effort. Multi-model pipelines are useful for activities like A/B testing and building out ensembles. For example, doing natural language processing (NLP) analysis of text and then using the results within a domain specific model to drive a customer recommendation. In the next section, we start to explore the API using code from the public codelab with the notebook also available at github.com/apache/beam/examples/notebooks/beam-ml.Using the Beam Inference APIBefore we get into the API, for those who are unfamiliar with Apache Beam, let’s put together a small pipeline that reads data from some CSV files to get us warmed up on the syntax.code_block[StructValue([(u’code’, u”import apache_beam as beamrnrnwith beam.Pipeline() as p:rn data = p | beam.io.ReadFromText(‘./file.csv’) rn data | beam.Map(print)”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3eaaa26ab6d0>)])]In that pipeline, we used the ReadFromText source to consume the data from the CSV file into a Parallel Collection, referred to as a PCollection in Apache Beam. In Apache Beam syntax, the pipe ‘|’ operator essentially means “apply”, so the first line applies the ReadFromText transform. In the next line, we use a beam.Map() to do element-wise processing of the data; in this case, the data is just being sent to the print function.Next, we make use of a very simple model to show how we can configure RunInference with different frameworks. The model is a single-layer linear regression that has been trained on y = 5x data (yup, it’s learned its fives times table). To build this model, follow the steps in the codelab. The RunInference transform has the following signature: RunInference(ModelHandler). The ModelHandler is a configuration that informs RunInference about the model details and that provides type information for the output. In the codelab, the PyTorch saved model file is named ‘five_times_table_torch.pt’ and is output as a result of the call to torch.save() on the model’s state_dict. Let’s create a ModelHandler that we can pass to RunInference for this model:code_block[StructValue([(u’code’, u”my_handler = PytorchModelHandlerTensor(rn state_dict_path=./five_times_table_torch.pt,rn model_class=LinearRegression,rn model_params={‘input_dim': 1,rn ‘output_dim': 1}”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3eaa926196d0>)])]The model_class is the class of the PyTorch model that defines the model architecture as a subclass of torch.nn.Module. The model_params are the ones that are defined by the constructor of the model_class. In this example, they are used in the notebook LinearRegression class definition:code_block[StructValue([(u’code’, u’class LinearRegression(torch.nn.Module):rn def __init__(self, input_dim=1, output_dim=1):rn super().__init__()rn self.linear = torch.nn.Linear(input_dim, output_dim) rn def forward(self, x):rn out = self.linear(x)rn return out’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3eaaa25e92d0>)])]The ModelHandler that is used also provides the transform information about the input type to the model, with PytorchModelHandlerTensor expecting torch.Tensor elements.To make use of this configuration, we update our pipeline with the configuration. We will also do the pre-processing needed to get the data into the right shape and type for the model that has been created. The model expects a torch.Tensor of shape [-1,1] and the data in our CSV file is in the format 20,30,40.code_block[StructValue([(u’code’, u”with beam.Pipeline() as p:rn raw_data = p | beam.io.ReadFromText(‘./file.csv’)rn shaped_data = raw_data | beam.FlatMap(lambda x : rn [numpy.float32(y).reshape(-1,1) rn for y in x.split(‘,’)]))rn results = shaped_data | beam.Map(torch.Tensor) | RunInference(my_handler)rn results | beam.Map(print)”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3eaa91962f50>)])]This pipeline will read the CSV file, get the data into shape for the model, and run the inference for us. The result of the print statement can be seen here:PredictionResult(example=tensor([20.]), inference=tensor([100.0047], grad_fn=<UnbindBackward0>))The PredictionResult object contains both the example as well as the result, in this case 100.0047 given an input of 20. Next, we look at how composing multiple RunInference transforms within a single pipeline gives us the ability to build out complex ensembles with a few lines of code. After that, we will look at a real model example with TorchVision.Multi model pipelinesIn the previous example, we had one model, a source, and an output. That pattern will be used by many pipelines. However, business needs also require ensembles of models where models are used for pre-processing of the data and for the domain specific tasks. For example, conversion of speech to text before being passed to an NLP model. Though the diagram above is a complex flow, there are actually three primary patterns. 1- Data is flowing down the graph.2- Data can branch after a stage, for example after ‘Language Understanding’.3- Data can flow from one model into another.Item 1 means that this is a good fit for building into a single Beam pipeline because it’s acyclic. For items 2 and 3, the Beam SDK can express the code very simply. Let’s take a look at these.Branching Pattern:In this pattern, data is branched to two models. To send all the data to both models, the code is in the form:code_block[StructValue([(u’code’, u’model_a_predictions = shaped_data | RunInference(configuration_model_a)rn model_b_predictions = shaped_data | RunInference(configuration_model_b)’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3eaaa2307890>)])]Models in Sequence:In this pattern, the output of the first model is sent to the next model. Some form of post processing normally occurs between these stages. To get the data in the right shape for the next step, the code is in the form:code_block[StructValue([(u’code’, u’model_a_predictions = shaped_data | RunInference(configuration_model_a)rnmodel_b_predictions = (model_a_predictions | beam.Map(postprocess) rn | RunInference(configuration_model_b))’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3eaaa031ff50>)])]With those two simple patterns (branching and model in sequence) as building blocks, we see that it’s possible to build complex ensembles of models. You can also make use of other Apache Beam tools to enrich the data at various stages in these pipelines. For example, in a sequential model, you may want to join the output of model a with data from a database before passing it to model b, bread and butter work for Beam. Using an open source modelIn the first example, we used a toy model that was available in the codelab. In this section, we walk through how you could use an open source model and output the model data to a Data Warehouse (Google Cloud BigQuery) to show a more complete end-to-end pipeline.Note that the code in this section is self-contained and not part of the codelab used in the previous section. The PyTorch model we will use to demonstrate this is maskrcnn_resnet50_fpn, which comes with Torchvision v 0.12.0. This model attempts to solve the image segmentation task: given an image, it detects and delineates each distinct object appearing in that image with a bounding box.In general, libraries like Torchvision pretrained models download the pretrained model directly into memory. To run the model with RunInference, we need a different setup, because RunInference will load the model once per Python process to be shared amongst many threads. So if we want to use a pre-trained model from these types of libraries, we have a little bit of setup to do. For this PyTorch model we need to:1- Download the state dictionary and make it available independently of the library to Beam.2- Determine the model class file and provide it to our ModelHandler, ensuring that we disable the class’s ‘autoload’ features.When looking at the signature for this model with version 0.12.0, note that there are two parameters that initiate an auto-download: pretrained and pretrained_backbone. Ensure these are both set to False to make sure that the model class does not load the model files:model_params = {‘pretrained': False, ‘pretrained_backbone': False}Step 1 – Download the state dictionary. The location can be found in the maskrcnn_resnet50_fpn source code:code_block[StructValue([(u’code’, u’%pip install apache-beam[gcp] torch==1.11.0 torchvision==0.12.0′), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3eaaa2873c10>)])]code_block[StructValue([(u’code’, u’import os,iornfrom PIL import Imagernfrom typing import Tuple, Anyrnimport torch, torchvisionrnimport apache_beam as beamrnfrom apache_beam.io import fileiornfrom apache_beam.io.gcp.internal.clients import bigqueryrnfrom apache_beam.options.pipeline_options import PipelineOptionsrnfrom apache_beam.options.pipeline_options import SetupOptionsrnfrom apache_beam.ml.inference.base import KeyedModelHandlerrnfrom apache_beam.ml.inference.base import PredictionResultrnfrom apache_beam.ml.inference.pytorch_inference import PytorchModelHandlerTensor’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3eaaa2873d10>)])]code_block[StructValue([(u’code’, u”# Download the state_dict using the torch hub utility to a local models directoryrntorch.hub.load_state_dict_from_url(‘https://download.pytorch.org/models/maskrcnn_resnet50_fpn_coco-bf2d0c1e.pth’, ‘models/’)”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3eaa9371a9d0>)])]Next, push this model from the local directory where it was downloaded to a common area accessible to workers. You can use utilities like gsutil if using Google Cloud Storage (GCS) as your object store:code_block[StructValue([(u’code’, u”model_path = f’gs://{bucket}/models/maskrcnn_resnet50_fpn_coco-bf2d0c1e.pth'”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3eaa916f93d0>)])]Step 2 – For our Modelandler, we need to use the model_class, which in our case is torchvision.models.detection.maskrcnn_resnet50_fpn. We can now build our ModelHandler. Note that in this case, we are making a KeyedModelHandler, which is different from the simple example we used above. The KeyedModelHandler is used to indicate that the values coming into the RunInference API are a tuple, where the first value is a key and the second is the tensor that will be used by the model. This allows us to keep a reference of which image the inference is associated with, and it is used in our post processing step.code_block[StructValue([(u’code’, u”my_cloud_model_handler = PytorchModelHandlerTensor(rn state_dict_path=model_path,rn model_class=torchvision.models.detection.maskrcnn_resnet50_fpn,rn model_params={‘pretrained':False, ‘pretrained_backbone’ : False})rnrnmy_keyed_cloud_model_handler = KeyedModelHandler(my_cloud_model_handler)”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3eaa916f9990>)])]All models need some level of pre-processing. Here we create a preprocessing function ready for our pipeline. One important note: when batching, the PyTorch ModelHandler will need the size of the tensor to be the same across the batch, so here we set the image_size as part of the pre-processing step. Also note that this function accepts a tuple with the first element being a string. This will be the ‘key’, and in the pipeline code, we will use the filename as the key.code_block[StructValue([(u’code’, u’# In this function we can carry out any pre-processing steps that you need for the modelrnrndef preprocess_image(data: Tuple[str,Image.Image]) -> Tuple[str,torch.Tensor]:rn import torchrn import torchvision.transforms as transformsrn # Note RunInference will by default auto batch inputs for Torch modelsrn # Alternative to this is to create a wrapper class, and overriding the batch_elements_kwargsrn # function to return {max_batch_size=1}set max_batch_size=1rn image_size = (224, 224)rn transform = transforms.Compose([rn transforms.Resize(image_size),rn transforms.ToTensor(),rn ])rn return data[0], transform(data[1])’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3eaa916f9310>)])]The output of the model needs some post processing before being sent to BigQuery. Here we denormalise the label with the actual name, for example, person, and zip it up with the bounding box and score output:code_block[StructValue([(u’code’, u”# The inference result is a PredictionResult object, this has two components the example and the inferencerndef post_process(kv : Tuple[str, PredictionResult]):rn # We will need the coco labels to translate the output from the modelrn coco_names = [‘unlabeled’, ‘person’, ‘bicycle’, ‘car’, ‘motorcycle’,rn ‘airplane’, ‘bus’, ‘train’, ‘truck’, ‘boat’, ‘traffic light’,rn ‘fire hydrant’, ‘street sign’, ‘stop sign’, ‘parking meter’,rn ‘bench’, ‘bird’, ‘cat’, ‘dog’, ‘horse’, ‘sheep’, ‘cow’,rn ‘elephant’, ‘bear’, ‘zebra’, ‘giraffe’, ‘hat’, ‘backpack’,rn ‘umbrella’, ‘shoe’, ‘eye glasses’, ‘handbag’, ‘tie’, ‘suitcase’,rn ‘frisbee’, ‘skis’, ‘snowboard’, ‘sports ball’, ‘kite’,rn ‘baseball bat’, ‘baseball glove’, ‘skateboard’, ‘surfboard’,rn ‘tennis racket’, ‘bottle’, ‘plate’, ‘wine glass’, ‘cup’, ‘fork’,rn ‘knife’, ‘spoon’, ‘bowl’, ‘banana’, ‘apple’, ‘sandwich’,rn ‘orange’, ‘broccoli’, ‘carrot’, ‘hot dog’, ‘pizza’, ‘donut’,rn ‘cake’, ‘chair’, ‘couch’, ‘potted plant’, ‘bed’, ‘mirror’,rn ‘dining table’, ‘window’, ‘desk’, ‘toilet’, ‘door’, ‘tv’,rn ‘laptop’, ‘mouse’, ‘remote’, ‘keyboard’, ‘cell phone’,rn ‘microwave’, ‘oven’, ‘toaster’, ‘sink’, ‘refrigerator’,rn ‘blender’, ‘book’, ‘clock’, ‘vase’, ‘scissors’, ‘teddy bear’,rn ‘hair drier’, ‘toothbrush’]rn # Extract the outputrn output = kv[1].inferencern # The model outputs labels, boxes and scores, we pull these out and creatern # a tuple with the label mapped to the coco_names and convert the tensorsrn return {‘file’ : kv[0], ‘inference’ : [rn {‘label': coco_names[x],rn ‘box’ : y.detach().numpy().tolist(),rn ‘score’ : z.item()}rn for x,y,z in zip(output[‘labels’],rn output[‘boxes’],rn output[‘scores’])]}”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3eaaa424bb50>)])]Let’s now run this pipeline with the direct runner, which will read the image from GCS, run it through the model, and output the results to BigQuery. We will need to pass in the BigQuery schema that we want to use, which should match the dict that we created in our post-processing. The WriteToBigquery transform takes the schema information as the table_spec object, which represents the following schema:The schema has a file string, which is the key from our output tuple. Because each image’s prediction will have a List of (labels, score, and bounding box points), a RECORD type is used to represent the data in BigQuery.Next, let’s create the pipeline using pipeline options, which will use the local runner to process an image from the bucket and push it to BigQuery. Because we need access to a project for the BigQuery calls, we will pass in project information via the options:code_block[StructValue([(u’code’, u”pipeline_options = PipelineOptions().from_dictionary({rn ‘temp_location':f’gs://{bucket}/tmp’,rn ‘project': project})”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3eaaa2c25310>)])]Next, we will see the pipeline put together with pre- and post-processing steps. The Beam transform MatchFiles matches all of the files found with the glob pattern provided. These matches are sent to the ReadMatches transform, which outputs a PCollection of ReadableFile objects. These have the Metadata.path information and can have the read() function invoked to get the files bytes(). These are then sent to the preprocessing path.code_block[StructValue([(u’code’, u’pipeline_options = PipelineOptions().from_dictionary({rn ‘temp_location':f’gs://{bucket}/tmp’,rn ‘project': project})rnrn# This function is a workaround for a dependency issue caused by usage of PILrn# within a lambda from a notebookrndef open_image(readable_file):rn import iorn from PIL import Imagern return readable_file.metadata.path, Image.open(io.BytesIO(readable_file.read()))rnrnpipeline_options.view_as(SetupOptions).save_main_session = Truernrnwith beam.Pipeline(options=pipeline_options) as p:rn (prn | “ReadInputData” >> beam.io.fileio.MatchFiles(f’gs://{bucket}/images/*’)rn | “FileToBytes” >> beam.io.fileio.ReadMatches()rn | “ImageToTensor” >> beam.Map(open_image)rn | “PreProcess” >> beam.Map(preprocess_image)rn | “RunInferenceTorch” >> beam.ml.inference.RunInference(my_keyed_cloud_model_handler)rn | beam.Map(post_process)rn | beam.io.WriteToBigQuery(table_spec,rn schema=table_schema,rn write_disposition=beam.io.BigQueryDisposition.WRITE_TRUNCATE,rn create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED)rn )’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3eaaa2c25850>)])]After running this pipeline, the BigQuery table will be populated with the results of the prediction.In order to run this pipeline on the cloud, for example if we had a bucket of 10000’s of images, we simply need to update the pipeline options and provide Dataflow with dependency information.:Create requirements.txt file for the dependencies:code_block[StructValue([(u’code’, u’!echo -e “apache-beam[gcp]ntorch==1.11.0ntorchvision==0.12.0″ > requirements.txt’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3eaa939fff10>)])]Creating the right pipeline options:code_block[StructValue([(u’code’, u”pipeline_options = PipelineOptions().from_dictionary({rn ‘runner’ : ‘DataflowRunner’,rn ‘region’ : ‘us-central1′,rn ‘requirements_file’ : ‘./requirements.txt’,rn ‘temp_location':f’gs://{bucket}/tmp’,rn ‘project': project})”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3eaaa098e1d0>)])]Conclusion The use of the new Apache Beam apache_beam.ml.RunInference transform removes large chunks of boiler plate data pipelines that incorporate machine learning models. Pipelines that make use of these transforms will also be able to make full use of the expressiveness of Apache Beam to deal with the pre- and post-processing of the data, and build complex multi-model pipelines with minimal code.
Quelle: Google Cloud Platform



