Nach Monaten: Elon Musk kauft Twitter und entlässt Chefs
Der Tesla- und SpaceX-Besitzer übernimmt das soziale Netzwerk für 44 Milliarden US-Dollar. Twitter-CEO Parag Agrawal muss gehen. (Twitter, Soziales Netz)
Quelle: Golem

Der Tesla- und SpaceX-Besitzer übernimmt das soziale Netzwerk für 44 Milliarden US-Dollar. Twitter-CEO Parag Agrawal muss gehen. (Twitter, Soziales Netz)
Quelle: Golem

Unternehmen suchen händeringend nach IT-Spezialisten. Weil sie kaum welche finden, bieten sie ihren Mitarbeitern mehr Möglichkeiten, sich im Job zu entfalten. Ein Bericht von Andreas Schulte (Arbeit, Top-IT-Arbeitgeber 2023)
Quelle: Golem

Statt Abwärme sinnlos in die Atmosphäre zu entlassen, wird sie von der Dänischen Technischen Universität genutzt. (Supercomputer, Computer)
Quelle: Golem

Der alte Mailinglisten-Server auf Basis von Python 2 wird beim Gnome-Projekt zugunsten von Discourse eingemottet. (Gnome, RSS)
Quelle: Golem

Linus Akesson hat ein 8-Bit-Akkordeon aus zwei C64-Tastaturen, Disketten und Gaffer-Band gebaut – der Klang ist so, wie man ihn sich erhofft. (C64, Audio/Video)
Quelle: Golem

Quelle: <a href="The Deal Is Done: Elon Musk Finally Owns Twitter“>BuzzFeed
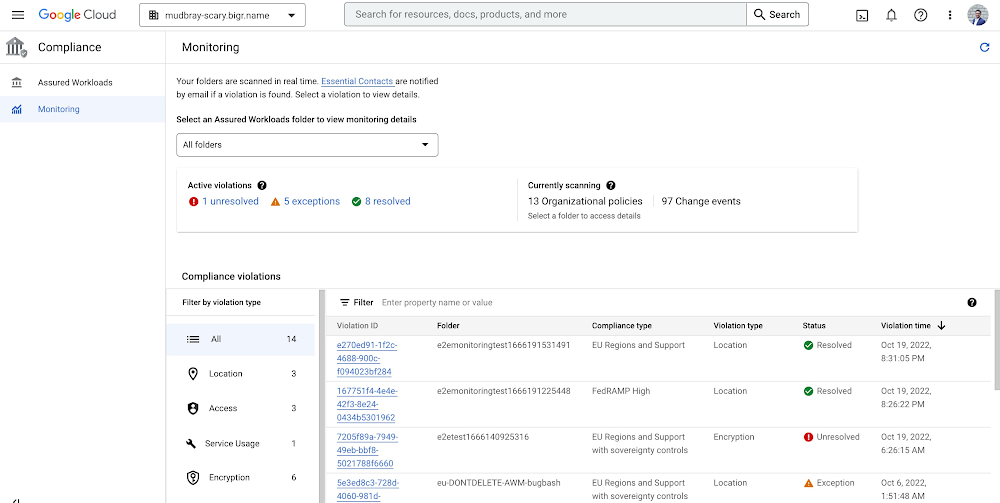
At Google Cloud, we continue to invest in our vision of invisible security where advanced capabilities are engineered into our platforms, operations are simplified, and stronger outcomes can be achieved. Assured Workloads is a Google Cloud service that helps customers create and maintain controlled environments that accelerate running more secure and compliant workloads, including enforcement of data residency, administrative and personnel controls, and managing encryption keys. Today, we are extending these capabilities to more regions. Assured Workloads for Canada is now generally available, and Assured Workloads for Australia is now available in preview. We are also making it easier for customers to get started with Assured Workloads by automating the onboarding process, and offering new tools to define specific compliance requirements and then validate the compliance posture of your Assured Workloads. These new capabilities can further speed deployment of regulated workloads on Google Cloud. Customers can get started today here.Assured Workloads for Canada Today, Assured Workloads for Canada is generally available to all customers with a premium Assured Workloads subscription, and existing customers can use it right away. Assured Workloads for Canada provides:Data residency in either a specific Canadian cloud region or across any of our Canadian cloud regions (currently Toronto and Montreal)Personnel access and technical support services restricted to personnel located in CanadaCryptographic control over data, including customer-managed encryption keys. Data encrypted with keys stored within a region can only be decrypted in that region. Service usage restrictions to centrally administer which Google Cloud products are available within the Assured Workloads environment Assured Workloads for AustraliaAssured Workloads for Australia is available in Preview today. This launch supports public sector customers in Australia following the certification of Google Cloud against the Hosting Certification Framework (HCF) by Australia’s Digital Transformation Agency. Assured Workloads for Australia provides:Data residency in either a specific Australian cloud region or across any of our Australian cloud regions (currently Sydney and Melbourne.)Personnel access and technical support services restricted to five countries (U.S., U.K., Australia, Canada, and New Zealand.) Initially launching with just U.S. persons, we plan on expanding to more support persons next year.Cryptographic control over data, including customer managed encryption keys. Data encrypted with keys stored within a region can only be decrypted in that region Service usage restrictions to centrally administer which Google Cloud products are available within the Assured Workloads environment Assured Workloads MonitoringWe are also excited to announce the general availability of Assured Workloads Monitoring. With Assured Workloads Monitoring, customers can get more visibility into organization policy changes that result in compliance violations. Assured Workloads Monitoring scans customer environments in real time and provides alerts whenever a change violates the defined compliance posture.Assured Workloads MonitoringAssured Workloads Monitoring can also help customers take corrective actions. The monitoring dashboard shows which policy is being violated and provides instructions on how to resolve the finding. Customers also have the ability to mark violations as exceptions and keep an audit trail of approved changes. Click here to learn more about Assured Workloads Monitoring and how you can use it to help keep your organization compliant.FedRAMP Moderate self-serve onboardingAssured Workloads provides the ability for customers to create U.S. FedRAMP Moderate environments at no charge. We’ve now made it even easier for customers to create these environments with just a few clicks. Click here to get started.ConclusionAssured Workloads helps accelerate running more secure and compliant workloads on Google Cloud. These announcements grow our global capabilities so customers can operate across markets with a consistent set of services and controls. To learn more about Assured Workloads, check out our customer session from this year’s Google Cloud Next and our Assured Workloads video walkthrough series on YouTube.
Quelle: Google Cloud Platform
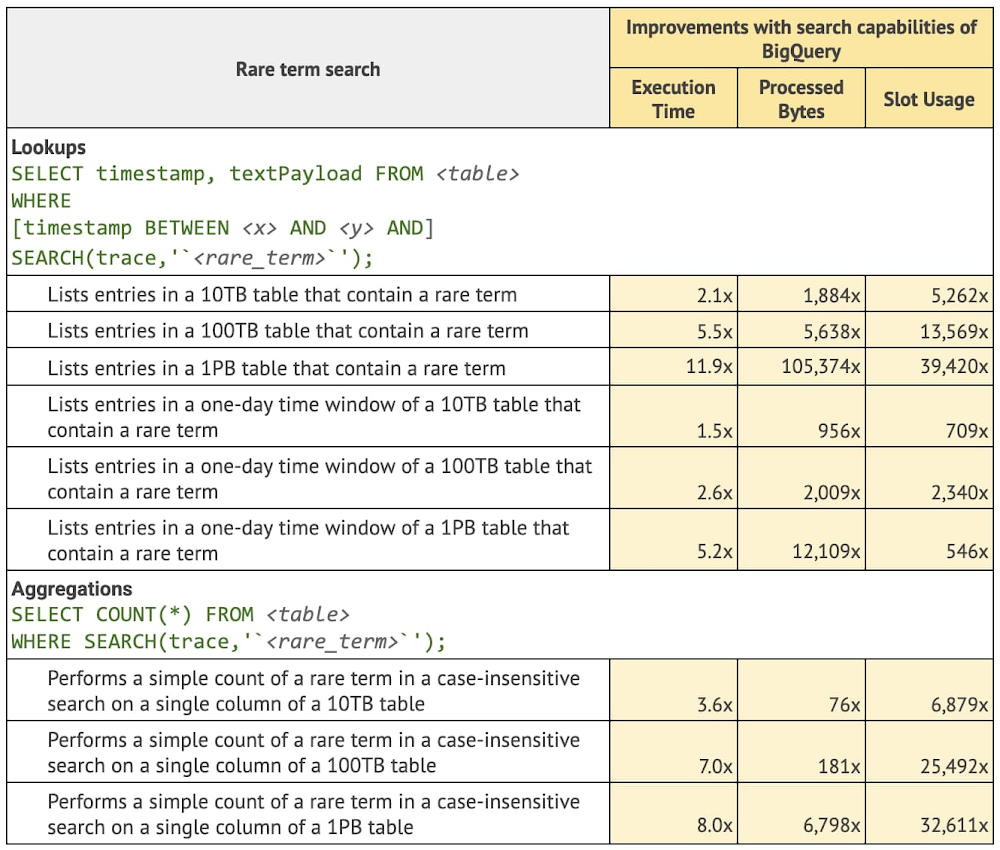
Google’s Data Cloud’s aim is to help customers close their data-to-value gap. BigQuery, Google Cloud Fully managed, serverless data platform lets customers combine all data — structured, semi-structured, and unstructured. Today, we are excited to announce the general availability of search indexes and search functions in BigQuery. This combination enables you to efficiently perform rich text analysis on data that may have been previously hard to explore due to the siloing of text information. With search indexes, you can reduce the need to export text data into standalone search engines and instead build data-driven applications or derive insights based on text data that is combined with the rest of your structured, semi-structured (JSON), unstructured (documents, images, audio), streaming, and geospatial data in BigQuery. Our previous post announcing the public preview of search indexesdescribed how search and indexing allow you to use standard BigQuery SQL to easily find unique data elements buried in unstructured text and semi-structured JSON, without having to know the table schemas in advance. The Google engineering team ran queries on Google Cloud Logging data of a Google internal test project (10TB, 100TB, and 1PB scales) using the SEARCH function with a search index. We then compared that to the equivalent logic with the REGEXP_CONTAINS function (no search index) and found that for the evaluated use cases, the new capabilities provided the following overall improvements (more specific details below): Execution time: 10x. On average, queries that use BigQuery SEARCH function backed by a search index are 10 times faster than the alternative queries for the common search use cases.Processed bytes: 2682x. On average, queries with BigQuery SEARCH function backed by a search index process 2682 times fewer bytes than the alternative queries for the common search use cases.Slot usage (BigQuery compute units): 1271x. On average, queries with BigQuery SEARCH function backed by a search index use 1271 times less slot time than the alternative queries for the common search use cases.Let’s put these numbers into perspective by discussing the common ways search indexes are used in BigQuery. Please note that all improvement numbers provided were derived from a Google engineering team analysis of common use cases and queries on a Google internal test project’s log data. The results may not map directly to customer queries and we would encourage you to test this on your own data set. Rare term search for analytics on logsLog analytics is a key industry use case enabled by Google’s Data Cloud. In a recent Google Cloud Next ‘22 talk on Operational Data Lakes, The Home Depot discussed how they were able to sunset their existing enterprise log analytics solution and instead use BigQuery and Looker as an alternative for 1,400+ active users in order to reduce costs and improve log retention. Goldman Sachs used BigQuery to solve their multi-cloud and scaling problems for logging data. Goldman Sachs moved from existing logging solutions to BigQuery to improve long term retention, detect PII in their logs with Google DLP, and implement new cost controls and allocations. A very common query pattern in analytics on logs is rare-term search or colloquially, “finding a needle in the haystack.” That means quickly searching through millions or billions of rows to identify an exact match to a specific network ID, error code, or user name to troubleshoot an issue or perform a security audit. This is also a quintessential use case for search indexes in a data warehouse. Using a search index on a table of text data allows the BigQuery optimizer to avoid large scanning operations and pinpoint exactly the relevant data required to answer the query. Let’s review what the Google engineering team found when they reviewed queries that looked for rare terms with and without a search index.IP address search in Cloud LoggingHome Depot and Goldman Sachs used BigQuery’s basic building blocks to develop their own customized log analytics applications. However, other customers may choose to use log analytics on Google’s Data Cloud as a pre-built integration within Cloud Logging. Log Analytics, powered by BigQuery (Preview) gives customers a managed Log Analytics as a service solution with a specialized interface for logs analysis. It leverages features of BigQuery’s search function which provides specialized ways to look up common logging data elements such as IP addresses, URLs, and e-mails. Let’s take a look at what the Google engineering team found when looking up IP addresses using a search function.Common term search on recent data for security operations Exabeam, an industry leader in security analytics and SIEM MQ, leverages BigQuery search functions and search indexes in their latest Security Operation Platform built on Google’s Data Cloud to search multi-year data in seconds [learn more data journey interview].Many security use cases are able to leverage a search optimization for queries on recent data that allows you to look up data with common terms using ORDER BY and LIMIT clauses. Let’s take a look at what the Google engineers found for queries on recent data that use an ORDER BY and LIMIT clauses.Search in JSON objects for Elasticsearch compatibility Google technical partner, Mach5 Software, offers its customers an Elasticsearch and OpenSearch-compatible platform powered by BigQuery’s search optimizations and JSON functionality. Using Mach5, customers can migrate familiar tools like Kibana, OpenSearch Dashboards, and pre-built applications, seamlessly to BigQuery, while enjoying a significant reduction in cost and management overhead. Mach5 takes advantage of BigQuery’s search index’s ability to comb through deeply nested data stored in a BigQuery’s native JSON data type. Mach5 Community Edition is freely available for you to deploy and use within your Google Cloud Platform environment.BigQuery’s SEARCH function operates directly on BigQuery’s native JSON type. Let’s look at some improvements the Google engineering team found when using search with indexing on JSON data.Learning moreAs you can see in the comparisons, there are already significant cost and performance improvements with BigQuery search functions and indexes, even at the petabyte level. Generally speaking, the larger the dataset, the more BigQuery can optimize. This means you can bring petabytes of data to BigQuery and still have it operate effectively. Many customers also combine BigQuery search features with large scale streaming pipelines built with BigQuery’s Storage Write API. This Write API has a default ingestion rate of 3GB per second with additional quota available upon request. It is also 50% lower per GB cost compared to previous streaming APIs offered by BigQuery. These streaming pipelines are fully managed by BigQuery and take care of all the operations from stream to index. Once data is available on the stream, any queries you run with a SEARCH function will have accurate and available data. To learn more about how BigQuery search features can help you build an operational data lake, check out this talk on Modern Security Analytics platforms. To see search in action, you can also watch this demo where a search index is built to improve simple searches of label and object data that is generated from running machine learning on vision data. You can get started with the BigQuery sandbox and explore these search capabilities at no cost to confirm whether BigQuery fits your needs. The sandbox lets you experience BigQuery and the Google Cloud console without providing a credit card, creating a billing account, or enabling billing for your project.
Quelle: Google Cloud Platform
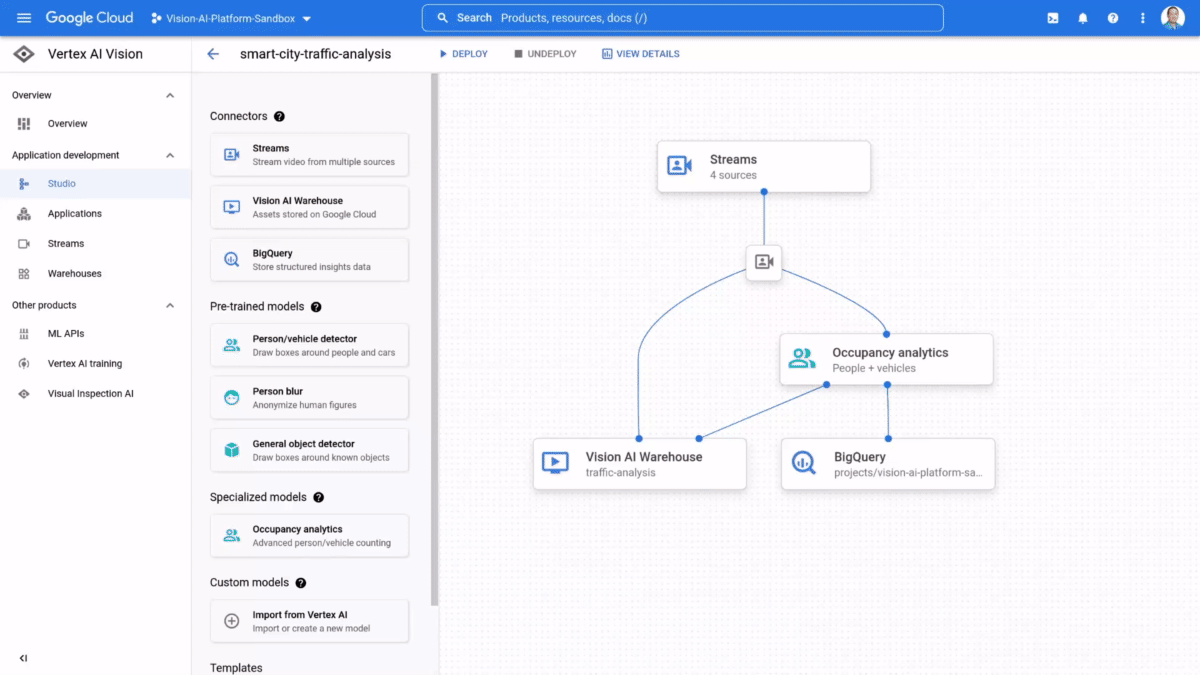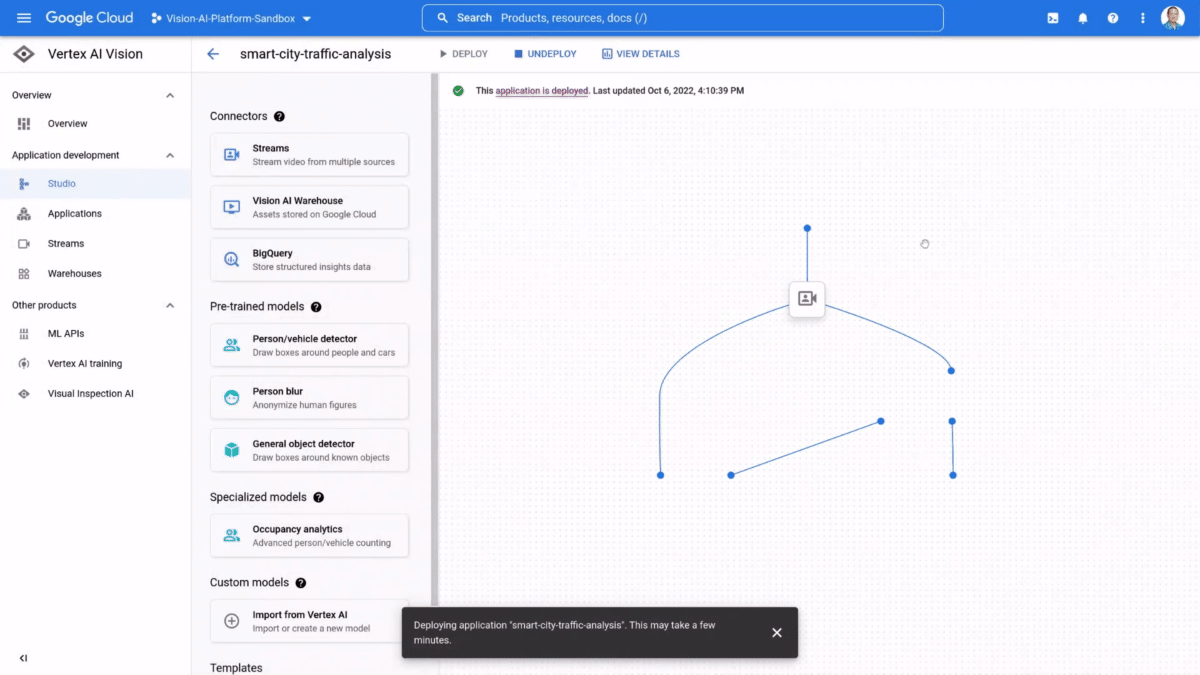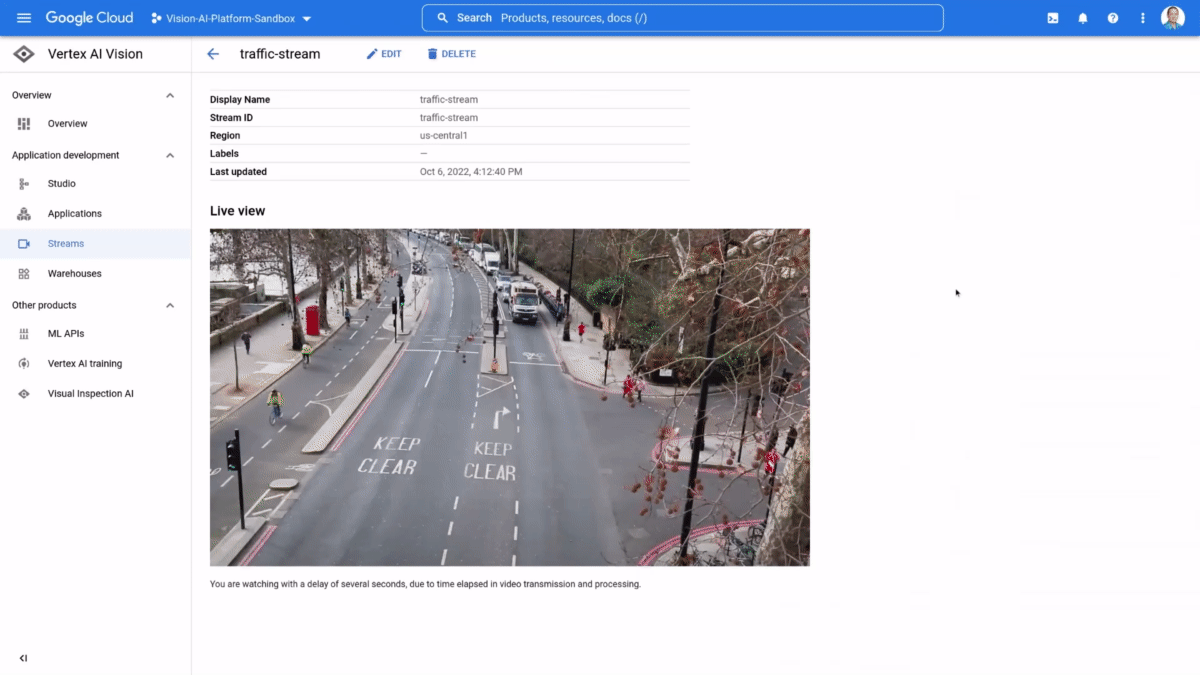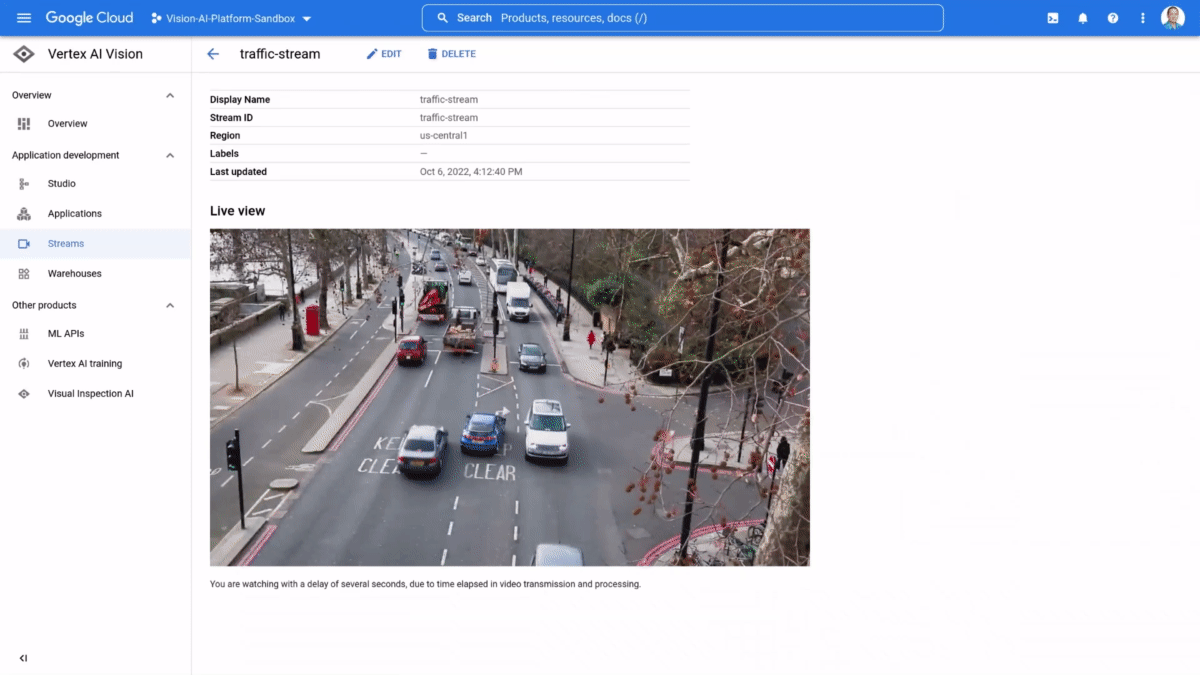
If organizations can easily analyze unstructured data streams, like live video and images, they can more effectively leverage information from the physical world to create intelligent business applications. Retailers can improve shelf management by instantly spotting what products are out of stock, manufacturers can reduce product defects by detecting production errors in real time, and in our communities, administrators could improve traffic management by analyzing vehicle patterns. The possibilities to create new experiences, efficiencies, and insights are endless. However, enterprises struggle to ingest, process, and analyze real-time video feeds at scale due to high infrastructure costs, development effort, longer lead times, and technology complexities.That’s why last week, at Google Cloud Next’ 22, we launched the preview of Vertex AI Vision, a fully managed end-to-end application development environment that lets enterprises easily build, deploy, and manage computer vision applications for their unique needs. Our internal research shows that Vertex AI Vision can help developers reduce time to build computer vision applications from weeks to hours, at a fraction of the cost of current offerings. As always, our new AI products also adhere to our AI Principles.One-stop environment for computer vision applications development Vertex AI Vision radically simplifies the process of cost-effectively creating and managing computer vision apps, from ingestion and analysis to deployment and storage. It does so by providing an integrated environment that includes all the tools needed to develop computer vision applications; developers can easily ingest live video streams (all they need is the IP address), add pre-trained models for common tasks such as “Occupancy Analytics,” “PPE Detection,” “Visual Inspection,” add custom models from Vertex AI for specialized tasks, and define a target location for output/ analytics. The application is ready to go.Vertex AI Vision comprises the following services:Vertex AI Vision Streams: a geo-distributed managed endpoint service for ingesting video streams & images. Easily connect cameras or devices from anywhere in the world and let Google handle ingestion and scalingVertex AI Vision Applications: a serverless orchestration platform for video models & services enabling developers to stitch together large, auto-scaled media processing and analytics pipelinesVertex AI Vision Models: a new portfolio of specialized pre-built vision models for common analytics tasks including occupancy counting, PPE detection, face-blurring, retail product recognition and more. Additionally, users can build and deploy their own custom models Vertex AI Vision Warehouse: a serverless rich-media storage that provides the best of Google search combined with managed video storage. Perfect for ingesting, storing, and searching PBs of video data. Customers are already seeing the future with Vertex AI Vision Customers are thrilled with the possibilities Vertex AI Vision opens. According to Elizabeth Spears, Co-Founder & CPO, Plainsight, a leading developer of computer vision applications, “Vertex AI Vision is changing the game for use cases that for us have previously been economically non-viable at scale. The ability to run computer vision models on streaming video with up to a 100X cost reduction for Plainsight is creating entirely new business opportunities for our customers.”Similarly, Brain Corp Vice President Botond Szatmáry said, “Vertex AI Vision is the backend solution that enables Brain Corp’s Shelf Analytics on all BrainOS powered robots, including a new commercial ready reference platform that’s purpose built for end to end inventory analytics. The Vertex AI Product Recognizer and Shelf Recognizer, combined with BigQuery, enable us to efficiently detect products, out of stock events, and low stock events while capturing products, prices, and location within stores and warehouses. Our retail customers can be more competitive in e-commerce, better manage their inventory, improve operational efficiencies, and improve the customer shopping experience with our highly accurate, actionable, and localized inventory shelf insights.” You can hear more from Plainsight and Brain Corp in our Next ’22 session. If you are a developer and want to get started on Vertex AI Vision I invite you to experience the magic for yourself here.
Quelle: Google Cloud Platform
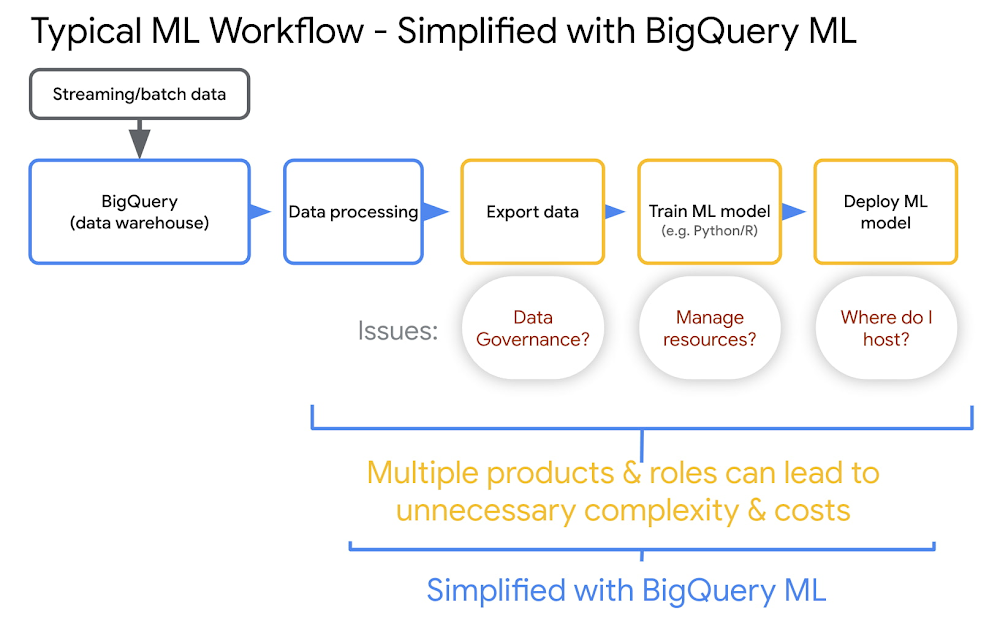
AI is at a tipping point. We are seeing the impact of AI across more and more industries and use cases. Organizations with varying levels of ML expertise are solving business-critical problems with AI — from creating compelling customer experiences, to optimizing operations, to automating routine tasks, these organizations learn to innovate faster and ultimately, get ahead in the marketplace. However, in many organizations, AI and machine learning systems are often separate and siloed from data warehouses and data lakes. This widens the data to AI gap, limiting data-powered innovation. At Google Cloud, we have harnessed our years of experience in AI development to make the data-to-AI journey as seamless as possible for our customers. Google’s data cloud simplifies the way teams work with data. Our built-in AI/ML capabilities are designed to meet users where they are, with their current skills. And our infrastructure, governance, and MLOps capabilities help organizations to leverage AI at scale. In this blog, we’ll share how you can simplify your ML workflows using BigQuery ML and Vertex AI and showcase the latest innovations in BigQuery ML.Simplify machine learning workflows with BigQuery ML and Vertex AIOrganizations that follow a siloed approach to managing databases, analytics and machine learning often need to move data from one system to another. This leads to data duplication with no single source of truth and makes it difficult to adhere to security and governance requirements. Additionally, when building ML pipelines, you need to train and deploy your models. Therefore you need to plan your infrastructure for scale. You also need to make sure that your ML models are tuned and optimized to run efficiently on your infrastructure. For example, you may need a large set of kubernetes clusters or access to GPU-based clusters so that you can train your models quickly. This forces organizations to hire highly skilled professionals with deep knowledge of Python, Java and other programming languages. Google’s data cloud provides a unified data and AI solution to help you overcome these challenges and simplify your machine learning workflows. BigQuery’s serverless, scalable architecture helps you create a powerful single source of truth for your data. BigQuery ML brings machine learning capabilities directly into your data warehouse through a familiar SQL interface. BigQuery ML’s native integration with Vertex AI allows you to leverage MLOps tooling to deploy, scale, and manage your models.BigQuery ML and Vertex AI help accelerate the adoption of AI across your organization.Easy data management: Manage ML workflows without moving data from BigQuery, eliminating security and governance problems. The ability to manage workflows within your datastore removes a big barrier to ML development and adoption.Reduce infrastructure management overhead: BigQuery takes advantage of the massive scale of Google’s compute and storage infrastructure. You don’t need to manage huge clusters or HPC infrastructure to do ML effectively.Remove skillset barrier: BigQuery ML is SQL based. This allows many model types to be directly available in SQL, such as regression, classification, recommender systems, deep learning, time series, anomaly detection, and more. Deploy models and operationalize ML workflows: Vertex AI Model Registry makes it easy to deploy BigQuery ML models to a Vertex AI REST endpoint for online or batch predictions. Further, Vertex AI Pipelines automate your ML workflows, helping you reliably go from data ingestion to deploying your model in a way that lets you monitor and understand your ML system.Get started with BigQuery ML in three stepsStep 1: Bring your data into BigQuery automatically via Pub/Sub in real time or in batch using BigQuery utilities or through one of our partner solutions. In addition, BigQuery can access data that may be residing in open source format such as Parquet/Hudi residing in object storage using BigLake. Learn more about loading data into BigQuery.Step 2: Train a model by running a simple SQL query (create model) in BigQuery and point to the dataset. BigQuery is highly scalable in terms of compute and storage, whether it is a dataset with 1000 rows or billions of rows. Learn more about model training in BigQuery ML.Step 3: Start running predictions. Use a simple SQL query to run predictions on the new data. There are a vast number of use cases supported through BigQuery ML such as demand forecasting, anomaly detection or even can be used for predicting new segments for your customer. Check out the list of supported models. Learn more about running predictions, detecting anomalies or predicting demand with forecasting.Increase impact with new capabilities in BigQuery MLAt Next ‘22, we announced several innovations in BigQuery ML that help you to quickly and easily operationalize ML at scale. To get early access and check out these new capabilities, submit this interest form. 1. Scale with MLOps and pipelinesWhen you are training a lot of models across your organization, managing models, comparing results, and creating repeatable training processes can be incredibly difficult. New capabilities make it easier to operationalize and scale BigQuery ML models with Vertex AI’s MLOps capabilities. Vertex AI Model Registry is now GA, providing a central place to manage and govern the deployment of all your models, including BigQuery ML models. You can use Vertex AI Model Registry for version control and ML metadata tracking, model evaluation and validation, deployment and model reporting. Learn more here. Another capability that further helps operationalize ML at scale is Vertex AI Pipelines, a serverless tool for orchestrating ML tasks so that they can be executed as a single pipeline, rather than manually triggered each task (e.g. train a model, evaluate the model, deploy to an endpoint) separately. We are introducing more than 20 BigQuery ML components to simplify orchestrating BigQuery ML operations. This eliminates the need for developers and ML engineers to write their own custom components to invoke BigQuery ML jobs. Additionally, if you are Data Scientist who prefers running code over SQL, you can now use these operators to train and predict in BigQuery ML.2. Derive insights from unstructured dataWe recently announced the preview of object tables, a new table type in BigQuery that enables you to directly run analytics on unstructured data including images, audio, documents and other file types. Using the same underlying framework, BigQuery ML will now help you to unlock that value from unstructured data. You can now execute SQL on image data and predict results from machine learning models using BigQuery ML. For example, you can import either state of the art TensorFlow vision models (e.g. ImageNet and ResNet 50) or your own models to detect objects, annotate photos, extract text from images.Learn more here and check out this demo of our customer Adswerve, a leading Google Marketing, Analytics and Cloud partner and their client Twiddy & Co, a vacation rental company in North Carolina, who combined structured and unstructured data using BigQuery ML to analyze images of rental listings and predict the click-through rate, enabling data-driven photo editorial decisions. In this work images attributed to 57% of the final prediction results.3. Inference EngineBigQuery ML acts an inference engine that works in a number of ways, including using existing models and can be extended to bring your own model:BigQuery ML trained modelsImported models of various formatsRemote modelsBigQuery ML supports several models out-of-the-box. However, some customers want to inference with models that are already trained in other platforms. Therefore, we are introducing new capabilities that allow users to import models beyond TensorFlow into BigQuery ML, starting with TFLite and XGBoost.Alternatively, if your model is too big to import (see current limitations here) or already deployed at an endpoint and you don’t have the ability to bring that model into BigQuery, BigQuery ML now allows you to do inference on remote models ( resources that you’ve trained outside of Vertex AI, or that you’ve trained using Vertex AI and exported). You can deploy a model on Vertex AI or Cloud Functions and then use BigQuery ML to do prediction.4. Faster, more powerful feature engineeringFeature preprocessing is one of the most important steps in developing a machine learning model. It consists of the creation of features and the cleaning of the data. Sometimes, the creation of features is also referred to as “feature engineering”. In other words, Feature engineering is all about taking data and representing it in ways that model training results in great models. BQML performs automatic feature preprocessing during training, based on the feature data types. This consists of missing value imputation and feature transformations. Besides these, all numerical and categorical features will be CASTed to double and string, respectively, for BQML training and inference. We are taking feature engineering to the next level by introducing several new numerical functions (such as MAX_ABS_SCALER, IMPUTER, ROBUST_SCALER, NORMALIZER) and categorical functions (such as ONE_HOT_ENCODER, LABEL_ENCODER, TARGET_ENCODER). BigQuery ML supports two types of feature preprocessing:Automatic preprocessing. BigQuery ML performs automatic preprocessing during training. For more information, see Automatic feature preprocessing.Manual preprocessing. BigQuery ML provides the TRANSFORM clause for you to define custom preprocessing using the manual preprocessing functions. You can also use these functions outside the TRANSFORM clause.Further, when you export BigQuery ML models by registering with Vertex AI Model Registry or manually, transform clauses will also be exported with it. This really simplifies online model deployment to Vertex.5. Multivariate time series forecastingMany BigQuery customers use the natively supported ARIMA PLUS model to forecast future demand and plan their business operations. Until now customers could forecast using only a single input variable. For example, to forecast ice cream sales, along with target metrics the past sales, customers could not forecast using external covariates such as weather. With this launch, users can now make more accurate forecasts by taking more than one variable into account through multivariate time series forecasting with ARIMA_PLUS_XREG (ARIMA_PLUS with external regressors (such as weather, location, etc).Getting StartedSubmit this form to try these new capabilities that help you accelerate your data to AI journey with BigQuery ML. Check out this video to learn more about these features and see a demo of how ML on structured and unstructured data can really transform marketing analytics.Acknowledgements: It was an honor and privilege to work on this with Amir Hormati, Polong Lin, Candice Chen, Mingge Deng, Yan Sun. We further acknowledge Manoj Gunti, Shana Matthews and Neama Dadkhahnikoo for support, work they have done and their inputs.
Quelle: Google Cloud Platform