T2-Sicherheitschip: Apples Aktivierungssperre schadet der Umwelt
Gebrauchte Macs müssen oft verschrottet werden, da Apples Sicherheitsfunktionen es Wiederverkäufern unmöglich machen, das Gerät zurückzusetzen. (Apple, Umweltschutz)
Quelle: Golem

Gebrauchte Macs müssen oft verschrottet werden, da Apples Sicherheitsfunktionen es Wiederverkäufern unmöglich machen, das Gerät zurückzusetzen. (Apple, Umweltschutz)
Quelle: Golem

Nur wenige Stunden waren die IT-Systeme der Stadt Potsdam nach einem dreiwöchigen Ausfall in Folge eines Cybercrime-Angriffs online. (Cybercrime, Cyberwar)
Quelle: Golem

Zwei neue Werke in Nevada sollen den elektrischen Semi Truck und Batterien für Tesla produzieren. (Tesla, Wirtschaft)
Quelle: Golem

Mit 52,7 Milliarden US-Dollar Umsatz und 16,4 Milliarden US-Dollar Gewinn blieb Microsoft hinter den Erwartungen zurück. Zuletzt baute der Konzern massiv Stellen ab. (Quartalsbericht, Microsoft)
Quelle: Golem
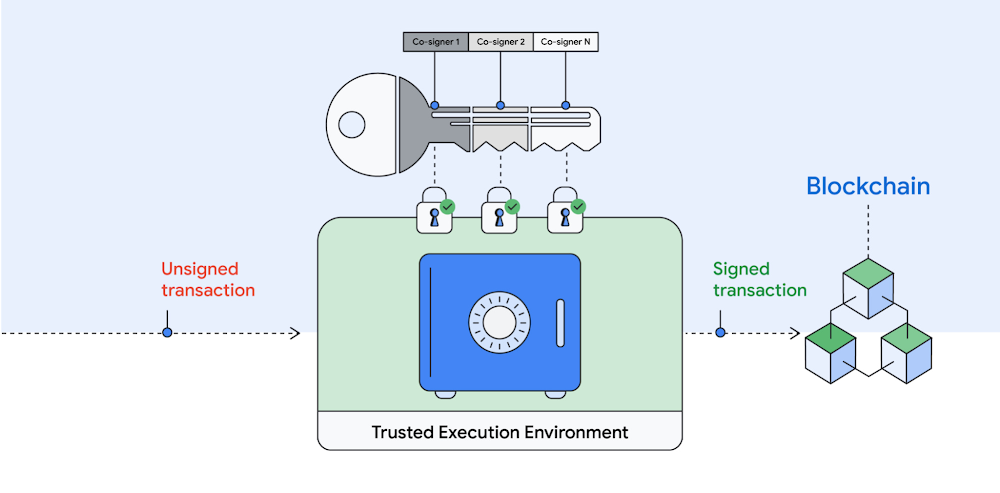
Managing digital asset transactions and their often-competing requirements to be secure and timely can be daunting. Human errors can lead to millions in assets being instantly lost, especially when managing your own encryption keys. This is where multi-party computation (MPC) can help reduce risk stemming from single points of compromise and facilitate instant, policy-compliant transactions. MPC has proven valuable to help secure digital asset transactions because it can simplify the user experience, and it can create operational efficiencies, while users retain control over their private keys. Google Cloud customers can implement MPC solutions with our new Confidential Space, which we introduced at Google Cloud Next in October. MPC enabled by Confidential Space can offer many benefits to safely manage and instantly transact digital assets:Digital assets can be held online without requiring cold storage.You can use an institutional-grade custody solution without having to give up control of your private keys. Distributed parties can participate in a signing process that is both auditable and policy-compliant.All parties can produce their signatures while not exposing secret material to other parties, including the MPC platform operator.An individual private key represents a single point of failure in the digital asset custody and signing process. In an MPC-compliant model, an individual private key is replaced with distributed key shares. Each key shareholder collaborates to sign a transaction, and all actions performed by all parties are logged for offline auditing. No key holder exposes their key share to another key holder or to the platform operator. Unlike multi-signature, a single private key is not assembled or stored anywhere.Figure 1 – Multi-Party Computation for transacting digital assets.An attacker coming from outside the organization would need to compromise multiple parties across multiple distributed operating environments in order to get access to a key that can sign a transaction. MPC is resistant to insider attacks against the platform operator or key holder because no single key can sign a transaction and the operator can not access the key. Since multiple parties must come together to approve and sign each transaction, MPC-based digital asset custody solutions can better facilitate governance. The solutions provide the ability to create and enforce policies that control who must approve transactions. This prevents a single malicious insider from stealing assets, including the party that owns the workload or a workload operator. Because Confidential Space is built on our Confidential Computing platform, it leverages remote attestation and AMD’s Secure Encrypted Virtualization (SEV). This allows us to offer a more secure environment, fast performance, and seamless workload portability. This foundation can enable the MPC operator and co-signer workloads to run in a Trusted Execution Environment (TEE). Co-signers can have control over how their keys are used and which workloads are authorized to act on them. Finally, with the hardened version of Container-Optimized OS (COS), Confidential Space blocks the workload operator from influencing the signing workload.Deploying MPC on Confidential Space provides the following differentiated benefits:Isolation: Ensures that external parties cannot interfere with the execution of the transaction signing process.Confidentiality: Ensures that the MPC platform operator has no ability to access the key material.Verifiable attestations: Allows co-signers to verify the identity and integrity of the MPC operator’s workload before providing a signature.“MPC solutions will become increasingly essential as blockchains continue to support more critical infrastructure within the global financial system,” said Jack Zampolin, CEO of Strangelove Labs.“As a core developer building and hosting critical infrastructure in the rapidly growing Cosmos ecosystem, MPC-compliant systems are an important focus area for Strangelove. We are excited to expand our relationship with Google Cloud by building out key management integrations with our highly available threshold signer, Horcrux.”In 2022 the Web3 community celebrated the Ethereum merge, one of several engineering advancements that can encourage applications of MPC. For example, MPC could be used for the efficient management of Ethereum validator keys. To learn more about MPC and Web3 with Google Cloud, please reach out to your account team. If you’d like to try Confidential Space, you can take it for a spin today.We’d like to thank Atul Luykx and Ross Nicoll, software engineers, and Nelly Porter and Rene Kolga, product managers, for their contributions to this post.
Quelle: Google Cloud Platform

Digital transformation across organizations has led to workloads shifting to multicloud and hybrid-cloud environments. Modern organizations are increasingly adopting cloud-native technologies including containers, microservices, serverless, and more.
With the growing complexity of distributed applications deployed on a cloud-native landscape, can organizations survive without the right observability in place?
It would be like flying an airplane blindfolded.
Businesses are in acute need of observability capabilities like Application Performance Management (APM), infrastructure monitoring, logs management, error tracing, and more to monitor, optimize, and troubleshoot their applications and infrastructure.
At the same time, organizations continue to prefer using software and services which they are familiar with and trust. To meet customers where they are, Microsoft partners closely with market-leading software as a service (SaaS) offerings and enables their use as part of the overall customer solution on our globally trusted cloud platform—Microsoft Azure.
Partnering with New Relic
New Relic, a leader in Gartner Magic Quadrant for 10 consecutive years in Application Performance Management and Observability, is one such partner on Azure.
"Observability is essential in today's modern, multicloud world. Whether our customers are running applications on data centers, embracing the public cloud, or running things at the edge, they need observability to take a look across all those systems. Today's news brings together more than a decade of innovation between New Relic and Microsoft, to bring the power of full stack observability to Microsoft developers, so they can accelerate enterprise cloud migration and multi-cloud initiatives.” —Bill Staples, New Relic CEO
Modern cloud-native environments warrant that organizations adopt a data-driven approach for their incident and threat response. When failures occur, identification, understanding, and resolution of the root cause of the issue is extremely time-critical for development teams.
Currently, to leverage New Relic for observability, you go through a complex multistep process to set up credentials, event hubs, and custom code, thus impacting your productivity and efficiency. To alleviate this challenge, we partnered with New Relic to create a seamlessly integrated solution on Azure that’s now available on the Azure marketplace.
Azure Native New Relic Service makes it effortless for developers and IT administrators to monitor their cloud applications. With this new offering, you can:
Create a New Relic account in the cloud with just a few clicks. Azure Native New Relic Service is a fully managed offering that enables easy onboarding and removes the need to set up and operate monitoring for your infrastructure.
Seamlessly ship logs and metrics to New Relic. Integrated right within the create experience, and also a part of the configuration, you can set up auto discovery of resources within an Azure subscription to monitor logs and metrics. You no longer need to go through the tedious process of setting up event hubs and writing custom code.
Bulk install New Relic Agent on virtual machines (VMs) and App Services through a single click. This then ships logs and metrics from your host infrastructure and processes to New Relic.
Get unified billing for all the resources you consume on Azure including New Relic, from the Azure marketplace.
"Application performance monitoring and full stack observability are mission critical for cloud transformation of enterprises of all sizes. With the Azure Native New Relic Service, Microsoft and New Relic have together, enabled a thoughtfully integrated, seamless, first-class experience for these enterprises everywhere. In just a few clicks, developers and admins can now effortlessly set up and monitor their cloud applications leveraging the power of New Relic on Azure.” —Balan Subramanian, Partner Director of Product Management, Azure Developer Experiences
Get started with Azure Native New Relic Service:
Let’s now look at how you can set up and configure Azure Native New Relic Service.
Subscribe to the Azure Native New Relic Service: You can easily find and subscribe to the offering in the Azure marketplace:
Create a New Relic resource on Azure: Once the New Relic offer is subscribed, you can easily create a New Relic resource in a few simple steps from the Azure portal. Using this, you can configure and manage your New Relic accounts within the Azure portal.
Configure Metrics and Logs Monitoring: Configure which Azure resources send metrics and logs to New Relic using simple include/exclude resource tag rules.
Install New Relic Agent on VMs: Once the New Relic resource is created, you can manage bulk install and uninstall of New Relic agent on multiple Linux or Windows VMs with a single click.
Install New Relic Agent on App Services: Similarly, you can install New Relic agent on multiple Windows App Services in one go.
Besides creating a New Relic resource, you can also link with existing New Relic accounts for monitoring resources across multiple Azure subscriptions. Not only that, you can also set up multiple resources under a single organization to unify billing and user management. To learn more, refer to the Azure Native New Relic Service documentation.
Learn more about Azure Native New Relic Service
Subscribe to the preview of Azure Native New Relic Service available in the Azure Marketplace.
Learn more about the New Relic integration with Azure.
Quelle: Azure
Persistent volatility in the retail market is forcing businesses to re-evaluate how they address key challenges. Prebuilt, edge-to-cloud, retail-specific technology solutions can help retailers increase the value of their data, empower store associates, elevate customer shopping experiences, and enable real-time sustainable supply chains.
Many retailers leverage Microsoft Cloud partners to get more insights out of their data using Microsoft Azure coupled with edge technologies, Internet of Things (IoT), and AI. Together these can not only help manage daily operations, but can also create more efficient, agile, and sustainable retail stores and supply chains.
Addressing key retail challenges with Azure-optimized solutions
Every retailer faces four main challenges:
Inventory and inventory optimization. From manufacturing to store, retailers need to have the right products on the shelves at the right time.
Modernized customer experience. Customers expect more from the in-store experience than they did just a few years ago. They expect easy, convenient, and seamless interactions.
Empowered frontline workers. Retailers need to empower frontline workers—the backbone of retail operations—with the right data and technology tools to help them make the best use of their time, be safe, and connect with customers.
Loss Prevention. Managing and reducing theft, as well as supply chain losses, are constant challenges.
Data provides the mechanism to solve these challenges. However, that data is often stuck in legacy systems with archaic deployment and authoring environments. Azure makes it possible for retailers to perform large-scale analytics on data pulled from all areas of the enterprise, and then use retail-specific data models to take action. Microsoft partners have leveraged these models to build a wide range of solutions.
Maximize the value of data
Microsoft partner Ombori integrates data from in-store touch screens and voice-activated kiosks, as well as IoT devices like barcode scanners. This solution also gathers data from a customer’s cell phone or a store associate’s smartwatch, then uses the data to streamline the customer shopping experience and fine-tune strategic planning up the chain.
Another Microsoft partner, SES-imagotag, transforms brick-and-mortar stores into high-value digital assets. Their digital price tags, which replace the traditional price tags that need to be changed by hand every time a price changes, have revolutionized how data captured on a store shelf drives decisions across the entire enterprise. Retailers like Walmart Canada use digital tags to build more responsive and precise pricing which reduces pricing errors and the time staff spends manually changing prices with paper labels.
Elevate the shopping experience
Today’s customers still want the physical store experience, but they have become accustomed to digital conveniences, instant fulfillment, and a modern in-store experience. That is why Cooler Screens came up with an innovative way to bring a more digital experience to brick-and-mortar locations by replacing traditional glass cooler doors with smart touch screens that showcase products and nutrition information and advertise promotions. An enterprise-scale merchandising and media platform on Azure handles the data, analytics, and IoT behind the scenes. The result? Over 90% of customers preferred Cooler Screen’s dynamic cooler doors over traditional coolers. And retailers are able to access real-time out-of-stock analytics and create in-store digital media capabilities to drive new revenue streams.
Another innovative solution that improves the customer experience while providing critical back-office data comes from AiFi. Its AI-powered Azure computer vision technology, which tracks a consumer’s product interest and purchase, provides a frictionless shopping experience for consumers. AiFi revolutionized the customer experience for Poland’s largest convenience store chain Żabka. In addition, the solution provides critical back-office data that the company can access, analyze, and act upon with just a few clicks.
Build a real-time sustainable supply chain
With ongoing production and supply chain disruptions, knowledge about product status and location is key to keeping the lights on and navigating the way to profitability. Retailers around the globe are using Azure technology to do just that. The Walgreens enterprise built a solution robust enough to handle the volumes of data generated by 8 million customers each day.
Other companies use Azure-based solutions to manage their manufacturing and transportation logistics. These companies get products on shelves more efficiently with fewer truck deliveries, which in turn reduces CO2 emissions. In addition, retailers are using edge technology to manage refrigeration and HVAC systems, further reducing CO2 emissions across the enterprise.
The retail conglomerate, Grupo Bimbo, relies on our cloud to collect, track, and analyze data across more than 200 facilities in 33 countries. The company has a worldwide distribution network serving more than 54,000 routes. In addition to massive supply chain efficiencies, the company is tracking emissions in Canada, Mexico, and the United States.
Empower store associates
There are many facets to using data to empower store associates. Retailers automate common in-store tasks such as stock replenishment and inventory management so employees can spend quality time with customers. They are also using other Microsoft technologies, such as Teams integration with headsets, to alert team members when a valuable customer is in a store.
One national hardware store analyzed product sales to optimize staffing levels based on foot traffic and increase their profits. They know contractors buy building materials early in the day, so employees are deployed to that part of the store in the mornings. In the evenings, when homeowners congregate in the home and garden aisles, those areas are staffed up.
Successful evolution with Microsoft
Today Microsoft supports a broad spectrum of Azure retail solutions, services, and platforms that would have been unimaginable in the retail tech market a few years ago. With Azure and edge technologies, customers and partners gain a flexible and resilient framework that they can build upon. They use these technologies to reshape customer experiences, improve operational efficiencies, gain visibility into inventory, optimize deliveries across channels, and make better, data-driven business decisions and predictions.
To learn more about how Cloud + Edge creates efficient, agile, and sustainable retail, see our IoT Retail Solutions.
Quelle: Azure

The latest release series of BuildKit, v0.11, introduces support for build-time attestations and SBOMs, allowing publishers to create images with records of how the image was built. This makes it easier for you to answer common questions, like which packages are in the image, where the image was built from, and whether you can reproduce the same results locally.
This new data helps you make informed decisions about the security of the images you consume — without needing to do all the manual work yourself.
In this blog post, we’ll discuss what attestations and SBOMs are, how to build images that contain SBOMs, and how to start analyzing the resulting data!
In this post:What are attestations?Getting the latest releaseAdding SBOMs to your imagesSupplementing SBOMsEven more SBOMs!Analyzing imagesGoing further
What are attestations?
An attestation is a declaration that a statement is true. With software, an attestation is a record that specifies a statement about a software artifact. For example, it could include who built it and when, what inputs it was built with, what outputs it produced, etc.
By writing these attestations, and distributing them alongside the artifacts themselves, you can see these details that might otherwise be tricky to find. To get this kind of information without attestations, you’d have to try and reverse-engineer how the image was built by trying to locate the source code and even attempting to reproduce the build yourself.
To provide this valuable information to the end-users of your images, BuildKit v0.11 lets you build these attestations as part of your normal build process. All it takes is adding a few options to your build step.
BuildKit supports attestations in the in-toto format (from the in-toto framework). Currently, the Dockerfile frontend produces two types of attestations that answer two different questions:
SBOM (Software Bill of Materials) – An SBOM contains a list of software components inside an image. This will include the names of various packages installed, their version numbers, and any other associated metadata. You can use this to see, at a glance, if an image contains a specific package or determine if an image is vulnerable to specific CVEs.
SLSA Provenance – The Provenance of the image describes details of the build process, such as what materials (like, images, URLs, files, etc.) were consumed, what build parameters were set, as well as source maps that allow mapping the resulting image back to the Dockerfile that created it. You can use this to analyze how an image was built, determine whether the sources consumed all appear legitimate, and even attempt to rebuild the image yourself.
Users can also define their own custom attestation types via a custom BuildKit frontend. In this post, we’ll focus on SBOMs and how to use them with Dockerfiles.
Getting the latest release
Building attestations into your images requires the latest releases of both Buildx and BuildKit – you can get the latest versions by updating Docker Desktop to the most recent version.
You can check your version number, and ensure it matches the buildx v0.10 release series:
$ docker buildx version
github.com/docker/buildx 0.10.0 …
To use the latest release of BuildKit, create a docker-container builder using buildx:
$ docker buildx create –use –name=buildkit-container –driver=docker-container
You can check that the new builder is configured correctly, and ensure it matches the buildkit v0.11 release series:
$ docker buildx inspect | grep -i buildkit
Buildkit: v0.11.1
If you’re using the docker/setup-buildx-action in GitHub Actions, then you’ll get this all automatically without needing to update.
With that out of the way, you can move on to building an image containing SBOMs!
Adding SBOMs to your images
You’re now ready to generate an SBOM for your image!
Let’s start with the following Dockerfile to create an nginx web server:
# syntax=docker/dockerfile:1.5
FROM nginx:latest
COPY ./static /usr/share/nginx/html
You can build and push this image, along with its SBOM, in one step:
$ docker buildx build –sbom=true -t <myorg>/<myimage> –push .
That’s all you need! In your build output, you should spot a message about generating the SBOM:
…
=> [linux/amd64] generating sbom using docker.io/docker/buildkit-syft-scanner:stable-1 0.2s
…
BuildKit generates SBOMs using scanner plugins. By default, it uses buildkit-syft-scanner, a scanner built on top of Anchore’s Syft open-source project, to do the heavy lifting. If you like, you can use another scanner by specifying the generator= option.
Here’s how you view the generated SBOM using buildx imagetools:
$ docker buildx imagetools inspect <myorg>/<myimage> –format "{{ json .SBOM.SPDX }}"
{
"spdxVersion": "SPDX-2.3",
"dataLicense": "CC0-1.0",
"SPDXID": "SPDXRef-DOCUMENT",
"name": "/run/src/core/sbom",
"documentNamespace": "https://anchore.com/syft/dir/run/src/core/sbom-a589a536-b5fb-49e8-9120-6a12ce988b67",
"creationInfo": {
"licenseListVersion": "3.18",
"creators": [
"Organization: Anchore, Inc",
"Tool: syft-v0.65.0",
"Tool: buildkit-v0.11.0"
],
"created": "2023-01-05T16:13:17.47415867Z"
},
…
SBOMs also work with the local and tar exporters. When you export with these exporters, instead of attaching the attestations directly to the output image, the attestations are exported as separate files into the output filesystem:
$ docker buildx build –sbom=true -o ./image .
$ ls -lh ./image
-rw——- 1 user user 6.5M Jan 17 14:36 sbom.spdx.json
…
Viewing the SBOM in this case is as simple as cat-ing the result:
$ cat ./image/sbom.spdx.json | jq .predicate
{
"spdxVersion": "SPDX-2.3",
"dataLicense": "CC0-1.0",
"SPDXID": "SPDXRef-DOCUMENT",
…
Supplementing SBOMs
Generating SBOMs using a scanner is a good first start! But some packages won’t be correctly detected because they’ve been installed in a slightly unconventional way.
If that’s the case, you can still get this information into your SBOMs with a bit of manual interaction.
Let’s suppose you’ve installed foo v1.2.3 into your image by downloading it using curl:
RUN curl https://example.com/releases/foo-v1.2.3-amd64.tar.gz | tar xzf – &&
mv foo /usr/local/bin/
Software installed this way likely won’t appear in your SBOM unless the SBOM generator you’re using has special support for this binary (for example, Syft has support for detecting certain known binaries).
You can manually generate an SBOM for this piece of software by writing an SPDX snippet to a location of your choice on the image filesystem using a Dockerfile heredoc:
COPY /usr/local/share/sbom/foo.spdx.json <<"EOT"
{
"spdxVersion": "SPDX-2.3",
"SPDXID": "SPDXRef-DOCUMENT",
"name": "foo-v1.2.3",
…
}
EOT
This SBOM should then be picked up by your SBOM generator and included in the final SBOM for the whole image. This behavior is included out-of-the-box in buildkit-syft-scanner, but may not be part of every generator’s toolkit.
Even more SBOMs!
While the above section is good for scanning a basic image, it might struggle to provide more detailed package and file information. BuildKit can help you scan additional components of your build, including intermediate stages and your build context using the BUILDKIT_SBOM_SCAN_STAGE and BUILDKIT_SBOM_SCAN_CONTEXT arguments respectively.
In the case of multi-stage builds, this allows you to track dependencies from previous stages, even though that software might not appear in your final image.
For example, for a demo C/C++ program, you might have the following Dockerfile:
# syntax=docker/dockerfile:1.5
FROM ubuntu:22.04 AS build
ARG BUILDKIT_SBOM_SCAN_STAGE=true
RUN apt-get update && apt-get install -y git build-essential
WORKDIR /src
RUN git clone https://example.com/myorg/myrepo.git .
RUN make build
FROM scratch
COPY –from=build /src/build/ /
If you just scanned the resulting image, it wouldn’t reveal that the build tools, like Git or GCC (included in the build-essential package), were ever used in the build process! By integrating SBOM scanning into your build using the BUILDKIT_SBOM_SCAN_STAGE build argument, you can get much richer information that would otherwise have been completely lost.
You can access these additionally generated SBOM documents in imagetools as well:
$ docker buildx imagetools inspect <myorg>/<myimage> –format "{{ range .SBOM.AdditionalSPDXs }}{{ json . }}{{ end }}"
{
"spdxVersion": "SPDX-2.3",
"SPDXID": "SPDXRef-DOCUMENT",
…
}
{
"spdxVersion": "SPDX-2.3",
"SPDXID": "SPDXRef-DOCUMENT",
…
}
…
For the local and tar exporters, these will appear as separate files in your output directory:
$ docker buildx build –sbom=true -o ./image .
$ ls -lh ./image
-rw——- 1 user user 4.3M Jan 17 14:40 sbom-build.spdx.json
-rw——- 1 user user 877 Jan 17 14:40 sbom.spdx.json
…
Analyzing images
Now that you’re publishing images containing SBOMs, it’s important to find a way to analyze them to take advantage of this additional data.
As mentioned above, you can extract the attached SBOM attestation using the imagetools subcommand:
$ docker buildx imagetools inspect <myorg>/<myimage> –format "{{json .SBOM.SPDX}}"
{
"spdxVersion": "SPDX-2.3",
"dataLicense": "CC0-1.0",
"SPDXID": "SPDXRef-DOCUMENT",
…
If your target image is built for multiple architectures using the –platform flag, then you’ll need a slightly different syntax to extract the SBOM attestation:
$ docker buildx imagetools inspect <myorg>/<myimage> –format "{{ json (index .SBOM "linux/amd64").SPDX}}"
{
"spdxVersion": "SPDX-2.3",
"dataLicense": "CC0-1.0",
"SPDXID": "SPDXRef-DOCUMENT",
…
Now suppose you want to list all of the packages, and their versions, inside an image. You can modify the value passed to the –format flag to be a go template that lists the packages:
$ docker buildx imagetools inspect <myorg>/<myimage> –format ‘{{ range .SBOM.SPDX.packages }}{{ println .name .versionInfo }}{{ end }}’ | sort
adduser 3.118
apt 2.2.4
base-files 11.1+deb11u6
base-passwd 3.5.51
bash 5.1-2+deb11u1
bsdutils 1:2.36.1-8+deb11u1
ca-certificates 20210119
coreutils 8.32-4+b1
curl 7.74.0-1.3+deb11u3
…
Alternatively, you might want to get the version information for a piece of software that you know is installed:
$ docker buildx imagetools inspect <myorg>/<myimage> –format ‘{{ range .SBOM.SPDX.packages }}{{ if eq .name "nginx" }}{{ println .versionInfo }}{{ end }}{{ end }}’
1.23.3-1~bullseye
You can even take the whole SBOM and use it to scan for CVEs using a tool that can use SBOMs to search for CVEs (like Anchore’s Grype):
$ docker buildx imagetools inspect <myorg>/<myimage> –format ‘{{ json .SBOM.SPDX }}’ | grype
NAME INSTALLED FIXED-IN TYPE VULNERABILITY SEVERITY
apt 2.2.4 deb CVE-2011-3374 Negligible
bash 5.1-2+deb11u1 (won’t fix) deb CVE-2022-3715
…
These operations should complete super quickly! Because the SBOM was already generated at build, you’re just querying already-existing data from Docker Hub instead of needing to generate it from scratch every time.
Going further
In this post, we’ve only covered the absolute basics to getting started with BuildKit and SBOMs — you can find out more about the things we’ve talked about on docs.docker.com:
Read more about build-time attestations
Learn about how to use buildx to create SBOMs
Implement your own SBOM scanner using the BuildKit SBOM protocol
Dive into how attestations are stored in the registry
And you can find out more about other features released in the latest BuildKit v0.11 release here.
Quelle: https://blog.docker.com/feed/

Grüße an Guybrush: Das Münchner Entwicklerstudio Mimimi Games setzt für sein nächstes Echtzeit-Taktikspiel Shadow Gambit auf Geisterpiraten. (Steam, Spiele)
Quelle: Golem

Der Autohersteller Ford will sein Werk in Saarlouis schließen. Es gibt aber eine ganze Reihe von Interessenten dafür. (Elektroauto, Auto)
Quelle: Golem