Massenentlassungen: Accenture streicht 19.000 Stellen
Das Beratungsunternehmen Accenture lässt sich seine Sparmaßnahmen rund 1,5 Milliarden US-Dollar kosten. (Arbeit, Wirtschaft)
Quelle: Golem

Das Beratungsunternehmen Accenture lässt sich seine Sparmaßnahmen rund 1,5 Milliarden US-Dollar kosten. (Arbeit, Wirtschaft)
Quelle: Golem

Die Nasa-Raumsonde Dart hat nach einem Einschlag die Umlaufbahn des Asteroiden Dimorphos verändert. Forschende zeigen nun, dass der Asteroid kein Wasser enthält. (Asteroid, Nasa)
Quelle: Golem

Sam Zeloof gründet ein Start-up und sammelt Millionen ein. Die Halbleiterfertigung soll einfacher werden, aber wie? Wir haben nachgeforscht. Eine Analyse von Johannes Hiltscher (Halbleiterfertigung, Wirtschaft)
Quelle: Golem

Google Bard hat Ergebnisse und Textstellen aus einem Testbericht einfach kopiert. Eine Quelle gab die KI nur auf Nachfrage an. (Google, KI)
Quelle: Golem

Quelle: <a href="TikTok’s CEO Got Blasted By Both Sides During An Intense Congressional Hearing“>BuzzFeed

AI has exploded in popularity in recent years, to the point where it’s no longer considered a luxury in the business world, but a necessity. A PricewaterhouseCoopers (PwC) study revealed that the adoption of AI will fuel a 14 percent increase in the global GDP by 2030, representing an additional $15.7 trillion surge to the global economy.1
Businesses using AI solutions are discovering new ways to tap into vast amounts of data to get clear insights and accelerate innovation. Thanks to advancements in graphics processing unit (GPU) computational power and the availability of tech services through cloud marketplaces, AI is now more accessible than ever.
As companies look to do more with less, AI will play an increasingly critical role—particularly generative AI, a category of AI algorithms that generate new outputs based on data. Unlike traditional AI systems that are designed to recognize patterns and make predictions, generative AI can analyze large data sets and create entirely new content in a variety of media formats—including text, images, audio, and data—based on what’s described in the input. Generative AI is used in systems like ChatGPT, the powerful natural and language model developed by OpenAI—a global leader in AI research and development.
At Microsoft, we’re committed to democratizing AI and giving you access to advanced generative AI models. As part of that commitment, in 2019, we started a long-term partnership with OpenAI. In January 2023, we announced the third phase of this partnership, including the general availability of Azure OpenAI Service.
With Azure OpenAI Service, businesses can access cutting-edge AI models, including GPT-3.5 and DALL•E 2. This service is backed by built-in responsible AI and enterprise-grade security. Azure OpenAI Service customers also will have access to ChatGPT—a fine-tuned version of GPT-3.5 that has been trained and runs inference on Azure AI infrastructure.
Add the power of generative AI to your apps—now available through the ISV Success program
We’re excited to announce that ISV Success program members will now be eligible to apply for access to Azure OpenAI Service. In today’s highly competitive market, ISVs are under intense pressure to differentiate and elevate their app offerings. To gain an edge, many software vendors are tapping into generative AI to modernize their applications.
With AI-optimized infrastructure and tools, Azure OpenAI Service empowers developers to build and modernize apps through direct access to OpenAI models. These generative AI models offer a deep understanding of language and code to enable apps with new reasoning and comprehension capabilities, which can be applied to a variety of use cases, such as code generation, content summarization, semantic search, and natural language-to-code translation.
As a participant in the program, you will also get access to advanced AI services like custom neural voice, speaker recognition, and content filters.
Drive application modernization with the ISV Success program
Learn more about the ISV Success program.
Join the ISV Success program to get access to best-in-class developer tools, cloud credits, one-to-one technical consultations, training resources, and now Azure OpenAI Service.
Apply to use Azure OpenAI service for your solutions.
1 PwC, Global Artificial Intelligence Study: Sizing the prize.
Quelle: Azure

I’ve been a long-time user and avid fan of both Docker and Kubernetes, and have many happy memories of attending the Docker Meetups in London in the early 2010s. I closely watched as Docker revolutionized the developers’ container-building toolchain and Kubernetes became the natural target to deploy and run these containers at scale.
Today we’re happy to announce Telepresence for Docker, simplifying how teams develop and test on Kubernetes for faster app delivery. Docker and Ambassador Labs both help cloud-native developers to be super-productive, and we’re excited about this partnership to accelerate the developer experience on Kubernetes.
What exactly does this mean?
When building with Kubernetes, you can now use Telepresence alongside the Docker toolchain you know and love.
You can buy Telepresence directly from Docker, and log in to Ambassador Cloud using your Docker ID and credentials.
You can get installation and product support from your current Docker support and services team.
Kubernetes development: Flexibility, scale, complexity
Kubernetes revolutionized the platform world, providing operational flexibility and scale for most organizations that have adopted it. But Kubernetes also introduces complexity when configuring local development environments.
We know you like building applications using your own local tools, where the feedback is instant, you can iterate quickly, and the environment you’re working in mirrors production. This combination increases velocity and reduces the time to successful deployment. But, you can face slow and painful development and troubleshooting obstacles when trying to integrate and test code into a real-world application running on Kubernetes. You end up having to replicate all of the services locally or remotely to test changes, which requires you to know about Kubernetes and the services built by others. The result, which we’ve seen at many organizations, is siloed teams, deferred deploying changes, and delayed organizational time to value.
Bridging remote environments with local development toolchains
Telepresence for Docker seamlessly bridges local dev machines to remote dev and staging Kubernetes clusters, so you don’t have to manage the complexity of Kubernetes, be a Kubernetes expert, or worry about consuming laptop resources when deploying large services locally.
The remote-to-local approach helps your teams to quickly collaborate and iterate on code locally while testing the effects of those code changes interactively within the full context of your distributed application. This way, you can work locally on services using the tools you know and love while also being connected to a remote Kubernetes cluster.
How does Telepresence for Docker work?
Telepresence for Docker works by running a traffic manager pod in Kubernetes and Telepresence client daemons on developer workstations. As shown in the following diagram, the traffic manager acts as a two-way network proxy that can intercept connections and route traffic between the cluster and containers running on developer machines.
Once you have connected your development machine to a remote Kubernetes cluster, you have several options for how the local containers can integrate with the cluster. These options are based on the concepts of intercepts, where Telepresence for Docker can re-route — or intercept — traffic destined to and from a remote service to your local machine. Intercepts enable you to interact with an application in a remote cluster and see the results from the local changes you made on an intercepted service.
Here’s how you can use intercepts:
No intercepts: The most basic integration involves no intercepts at all, simply establishing a connection between the container and the cluster. This enables the container to access cluster resources, such as APIs and databases.
Global intercepts: You can set up global intercepts for a service. This means all traffic for a service will be re-routed from Kubernetes to your local container.
Personal intercepts: The more advanced alternative to global intercepts is personal intercepts. Personal intercepts let you define conditions for when a request should be routed to your local container. The conditions could be anything from only routing requests that include a specific HTTP header, to requests targeting a specific route of an API.
Benefits for platform teams: Reduce maintenance and cloud costs
On top of increasing the velocity of individual developers and development teams, Telepresence for Docker also enables platform engineers to maintain a separation of concerns (and provide appropriate guardrails). Platform engineers can define, configure, and manage shared remote clusters that multiple Telepresence for Docker users can interact within during their day-to-day development and testing workflows. Developers can easily intercept or selectively reroute remote traffic to the service on their local machine, and test (and share with stakeholders) how their current changes look and interact with remote dependencies.
Compared to static staging environments, this offers a simple way to connect local code into a shared dev environment and fuels easy, secure collaboration with your team or other stakeholders. Instead of provisioning cloud virtual machines for every developer, this approach offers a more cost-effective way to have a shared cloud development environment.
Get started with Telepresence for Docker today
We’re excited that the Docker and Ambassador Labs partnership brings Telepresence for Docker to the 12-million-strong (and growing) community of registered Docker developers. Telepresence for Docker is available now. Keep using the local tools and development workflow you know and love, but with faster feedback, easier collaboration, and reduced cloud environment costs.
You can quickly get started with your Docker ID, or contact us to learn more.
Quelle: https://blog.docker.com/feed/
Today, Hugging Face and Docker are announcing a new partnership to democratize AI and make it accessible to all software engineers. Hugging Face is the most used open platform for AI, where the machine learning (ML) community has shared more than 150,000 models; 25,000 datasets; and 30,000 ML apps, including Stable Diffusion, Bloom, GPT-J, and open source ChatGPT alternatives. These apps enable the community to explore models, replicate results, and lower the barrier of entry for ML — anyone with a browser can interact with the models.
Docker is the leading toolset for easy software deployment, from infrastructure to applications. Docker is also the leading platform for software teams’ collaboration.
Docker and Hugging Face partner so you can launch and deploy complex ML apps in minutes. With the recent support for Docker on Hugging Face Spaces, folks can create any custom app they want by simply writing a Dockerfile. What’s great about Spaces is that once you’ve got your app running, you can easily share it with anyone worldwide! 🌍 Spaces provides an unparalleled level of flexibility and enables users to build ML demos with their preferred tools — from MLOps tools and FastAPI to Go endpoints and Phoenix apps.
Spaces also come with pre-defined templates of popular open source projects for members that want to get their end-to-end project in production in a matter of seconds with just a few clicks.
Spaces enable easy deployment of ML apps in all environments, not just on Hugging Face. With “Run with Docker,” millions of software engineers can access more than 30,000 machine learning apps and run them locally or in their preferred environment.
“At Hugging Face, we’ve worked on making AI more accessible and more reproducible for the past six years,” says Clem Delangue, CEO of Hugging Face. “Step 1 was to let people share models and datasets, which are the basic building blocks of AI. Step 2 was to let people build online demos for new ML techniques. Through our partnership with Docker Inc., we make great progress towards Step 3, which is to let anyone run those state-of-the-art AI models locally in a matter of minutes.”
You can also discover popular Spaces in the Docker Hub and run them locally with just a couple of commands.
To get started, read Effortlessly Build Machine Learning Apps with Hugging Face’s Docker Spaces. Or try Hugging Face Spaces now.
Quelle: https://blog.docker.com/feed/

The Hugging Face Hub is a platform that enables collaborative open source machine learning (ML). The hub works as a central place where users can explore, experiment, collaborate, and build technology with machine learning. On the hub, you can find more than 140,000 models, 50,000 ML apps (called Spaces), and 20,000 datasets shared by the community.
Using Spaces makes it easy to create and deploy ML-powered applications and demos in minutes. Recently, the Hugging Face team added support for Docker Spaces, enabling users to create any custom app they want by simply writing a Dockerfile.
Another great thing about Spaces is that once you have your app running, you can easily share it with anyone around the world. 🌍
This guide will step through the basics of creating a Docker Space, configuring it, and deploying code to it. We’ll show how to build a basic FastAPI app for text generation that will be used to demo the google/flan-t5-small model, which can generate text given input text. Models like this are used to power text completion in all sorts of apps. (You can check out a completed version of the app at Hugging Face.)
Prerequisites
To follow along with the steps presented in this article, you’ll need to be signed in to the Hugging Face Hub — you can sign up for free if you don’t have an account already.
Create a new Docker Space 🐳
To get started, create a new Space as shown in Figure 1.
Figure 1: Create a new Space.
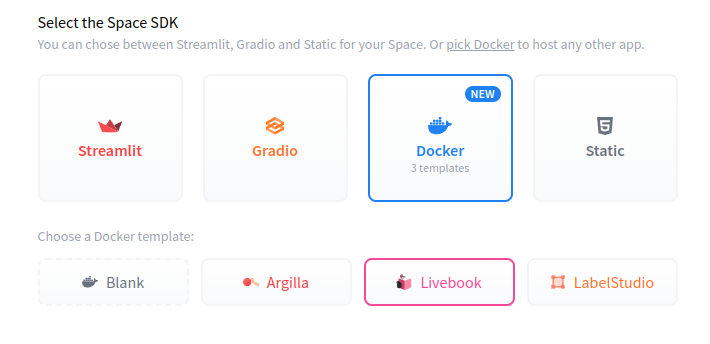
Next, you can choose any name you prefer for your project, select a license, and use Docker as the software development kit (SDK) as shown in Figure 2.
Spaces provides pre-built Docker templates like Argilla and Livebook that let you quickly start your ML projects using open source tools. If you choose the “Blank” option, that means you want to create your Dockerfile manually. Don’t worry, though; we’ll provide a Dockerfile to copy and paste later. 😅
Figure 2: Adding details for the new Space.
When you finish filling out the form and click on the Create Space button, a new repository will be created in your Spaces account. This repository will be associated with the new space that you have created.
Note: If you’re new to the Hugging Face Hub 🤗, check out Getting Started with Repositories for a nice primer on repositories on the hub.
Writing the app
Ok, now that you have an empty space repository, it’s time to write some code. 😎
The sample app will consist of the following three files:
requirements.txt — Lists the dependencies of a Python project or application
app.py — A Python script where we will write our FastAPI app
Dockerfile — Sets up our environment, installs requirements.txt, then launches app.py
To follow along, create each file shown below via the web interface. To do that, navigate to your Space’s Files and versions tab, then choose Add file → Create a new file (Figure 3). Note that, if you prefer, you can also utilize Git.
Figure 3: Creating new files.
Make sure that you name each file exactly as we have done here. Then, copy the contents of each file from here and paste them into the corresponding file in the editor. After you have created and populated all the necessary files, commit each new file to your repository by clicking on the Commit new file to main button.
Listing the Python dependencies
It’s time to list all the Python packages and their specific versions that are required for the project to function properly. The contents of the requirements.txt file typically include the name of the package and its version number, which can be specified in a variety of formats such as exact version numbers, version ranges, or compatible versions. The file lists FastAPI, requests, and uvicorn for the API along with sentencepiece, torch, and transformers for the text-generation model.
fastapi==0.74.*
requests==2.27.*
uvicorn[standard]==0.17.*
sentencepiece==0.1.*
torch==1.11.*
transformers==4.*
Defining the FastAPI web application
The following code defines a FastAPI web application that uses the transformers library to generate text based on user input. The app itself is a simple single-endpoint API. The /generate endpoint takes in text and uses a transformers pipeline to generate a completion, which it then returns as a response.
To give folks something to see, we reroute FastAPI’s interactive Swagger docs from the default /docs endpoint to the root of the app. This way, when someone visits your Space, they can play with it without having to write any code.
from fastapi import FastAPI
from transformers import pipeline
# Create a new FastAPI app instance
app = FastAPI()
# Initialize the text generation pipeline
# This function will be able to generate text
# given an input.
pipe = pipeline("text2text-generation",
model="google/flan-t5-small")
# Define a function to handle the GET request at `/generate`
# The generate() function is defined as a FastAPI route that takes a
# string parameter called text. The function generates text based on the # input using the pipeline() object, and returns a JSON response
# containing the generated text under the key "output"
@app.get("/generate")
def generate(text: str):
"""
Using the text2text-generation pipeline from `transformers`, generate text
from the given input text. The model used is `google/flan-t5-small`, which
can be found [here](<https://huggingface.co/google/flan-t5-small>).
"""
# Use the pipeline to generate text from the given input text
output = pipe(text)
# Return the generated text in a JSON response
return {"output": output[0]["generated_text"]}
Writing the Dockerfile
In this section, we will write a Dockerfile that sets up a Python 3.9 environment, installs the packages listed in requirements.txt, and starts a FastAPI app on port 7860.
Let’s go through this process step by step:
FROM python:3.9
The preceding line specifies that we’re going to use the official Python 3.9 Docker image as the base image for our container. This image is provided by Docker Hub, and it contains all the necessary files to run Python 3.9.
WORKDIR /code
This line sets the working directory inside the container to /code. This is where we’ll copy our application code and dependencies later on.
COPY ./requirements.txt /code/requirements.txt
The preceding line copies the requirements.txt file from our local directory to the /code directory inside the container. This file lists the Python packages that our application depends on
RUN pip install –no-cache-dir –upgrade -r /code/requirements.txt
This line uses pip to install the packages listed in requirements.txt. The –no-cache-dir flag tells pip to not use any cached packages, the –upgrade flag tells pip to upgrade any already-installed packages if newer versions are available, and the -r flag specifies the requirements file to use.
RUN useradd -m -u 1000 user
USER user
ENV HOME=/home/user
PATH=/home/user/.local/bin:$PATH
These lines create a new user named user with a user ID of 1000, switch to that user, and then set the home directory to /home/user. The ENV command sets the HOME and PATH environment variables. PATH is modified to include the .local/bin directory in the user’s home directory so that any binaries installed by pip will be available on the command line. Refer the documentation to learn more about the user permission.
WORKDIR $HOME/app
This line sets the working directory inside the container to $HOME/app, which is /home/user/app.
COPY –chown=user . $HOME/app
The preceding line copies the contents of our local directory into the /home/user/app directory inside the container, setting the owner of the files to the user that we created earlier.
CMD ["uvicorn", "app:app", "–host", "0.0.0.0", "–port", "7860"]
This line specifies the command to run when the container starts. It starts the FastAPI app using uvicorn and listens on port 7860. The –host flag specifies that the app should listen on all available network interfaces, and the app:app argument tells uvicorn to look for the app object in the app module in our code.
Here’s the complete Dockerfile:
# Use the official Python 3.9 image
FROM python:3.9
# Set the working directory to /code
WORKDIR /code
# Copy the current directory contents into the container at /code
COPY ./requirements.txt /code/requirements.txt
# Install requirements.txt
RUN pip install –no-cache-dir –upgrade -r /code/requirements.txt
# Set up a new user named "user" with user ID 1000
RUN useradd -m -u 1000 user
# Switch to the "user" user
USER user
# Set home to the user’s home directory
ENV HOME=/home/user
PATH=/home/user/.local/bin:$PATH
# Set the working directory to the user’s home directory
WORKDIR $HOME/app
# Copy the current directory contents into the container at $HOME/app setting the owner to the user
COPY –chown=user . $HOME/app
# Start the FastAPI app on port 7860, the default port expected by Spaces
CMD ["uvicorn", "app:app", "–host", "0.0.0.0", "–port", "7860"]
Once you commit this file, your space will switch to Building, and you should see the container’s build logs pop up so you can monitor its status. 👀
If you want to double-check the files, you can find all the files at our app Space.
Note: For a more basic introduction on using Docker with FastAPI, you can refer to the official guide from the FastAPI docs.
Using the app 🚀
If all goes well, your space should switch to Running once it’s done building, and the Swagger docs generated by FastAPI should appear in the App tab. Because these docs are interactive, you can try out the endpoint by expanding the details of the /generate endpoint and clicking Try it out! (Figure 4).
Figure 4: Trying out the app.
Conclusion
This article covered the basics of creating a Docker Space, building and configuring a basic FastAPI app for text generation that uses the google/flan-t5-small model. You can use this guide as a starting point to build more complex and exciting applications that leverage the power of machine learning.
If you’re interested in learning more about Docker templates and seeing curated examples, check out the Docker Examples page. There you’ll find a variety of templates to use as a starting point for your own projects, as well as tips and tricks for getting the most out of Docker templates. Happy coding!
Quelle: https://blog.docker.com/feed/
Amazon S3 on Outposts unterstützt jetzt S3 Replication on Outposts. Dadurch wird der vollständig verwaltete Replikationsansatz von S3 auf die Outposts-Buckets erweitert, sodass Sie die Anforderungen an Datenresidenz und Datenredundanz erfüllen können. Mit der lokalen S3 Replication on Outposts können Sie Replikationsregeln erstellen und konfigurieren, um Ihre S3-Objekte automatisch in einen anderen Outpost oder in einen anderen Bucket auf demselben Outpost zu replizieren. Während der Replikation werden Ihre S3 on Outposts-Objekte immer über Ihr lokales Gateway (LGW) gesendet, und Objekte werden nicht zurück in die AWS-Region übertragen. S3 Replication on Outposts bietet eine einfache und flexible Möglichkeit, Daten innerhalb eines bestimmten Datenperimeters automatisch zu replizieren, um Ihre Datenredundanz- und Compliance-Anforderungen zu erfüllen.
Quelle: aws.amazon.com