Höhere Rendite: VW-Spitze schließt deutsche Werksschließung wohl nicht aus
Konzernchef Blume will angeblich den Beschäftigungspakt bei VW kündigen. Auch ein größeres deutsches Werk könnte geschlossen werden. (VW, Elektroauto)
Quelle: Golem

Konzernchef Blume will angeblich den Beschäftigungspakt bei VW kündigen. Auch ein größeres deutsches Werk könnte geschlossen werden. (VW, Elektroauto)
Quelle: Golem

Probleme nach dem 117. Sitz: Trotz intensiver Tests hat eine Wahlsoftware die Sitzverteilung in Sachsen falsch ausgegeben. (Wahlcomputer, CCC)
Quelle: Golem

Qualcomm will zusammen mit europäischen Unternehmen Fernsehempfang auf dem Smartphone vorantreiben. Media Broadcast von Freenet ist dabei. (Fernsehen, Technologie)
Quelle: Golem

Auf dem Youtube-Kanal Der8auer ist ein ungewöhnlich gut gefälschter AMD Ryzen 7 7800X3D untersucht worden. (AMD, Prozessor)
Quelle: Golem

Schwimmen macht mit Musik gleich viel mehr Freude. Das beweisen die Openswim Pro von Shokz, die auch tolle Bluetooth-Kopfhörer sind. Es gibt aber auch Kritik. Ein Test von Ingo Pakalski (Kopfhörer, Test)
Quelle: Golem

Intel arbeitet an weiteren Sparmaßnahmen. Im Raum stehen der Verkauf der FPGA-Abteilung und der Baustopp der Foundry in Sachsen-Anhalt. (Intel, Pat Gelsinger)
Quelle: Golem

Der Interessenverband für Leih-Tretroller berichtet von mehr Fahrten 2023 verglichen mit dem Vorjahr. In den Städten mehrt sich aber die Kritik. (E-Scooter, Verkehr)
Quelle: Golem

Ein neues Problem ist am Wochenende beim Starliner von Boeing aufgetreten. Einer der Astronauten meldete der Nasa ein Geräusch aus den Lautsprechern. (Boeing, Nasa)
Quelle: Golem
GitHub is the home of the world’s software developers, with more than 100 million developers and 420 million total repositories across the platform. To keep everything running smoothly and securely, GitHub collects a tremendous amount of data through an in-house pipeline made up of several components. But even though it was built for fault tolerance and scalability, the ongoing growth of GitHub led the company to reevaluate the pipeline to ensure it meets both current and future demands.
“We had a scalability problem, currently, we collect about 700 terabytes a day of data, which is heavily used for detecting malicious behavior against our infrastructure and for troubleshooting. This internal system was limiting our growth.”
—Stephan Miehe, GitHub Senior Director of Platform Security
GitHub worked with its parent company, Microsoft, to find a solution. To process the event stream at scale, the GitHub team built a function app that runs in Azure Functions Flex Consumption, a plan recently released for public preview. Flex Consumption delivers fast and large scale-out features on a serverless model and supports long function execution times, private networking, instance size selection, and concurrency control.
Azure Functions Flex Consumption
Find out how can scale fast with Azure Functions Flex Consumption Plan
Learn more
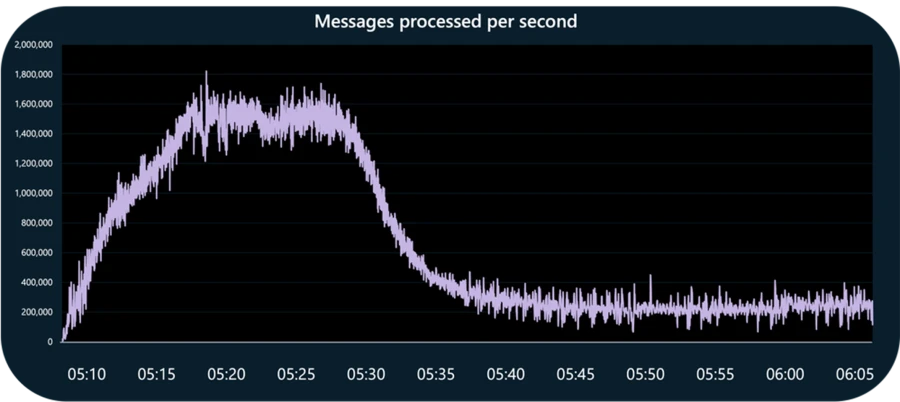
In a recent test, GitHub sustained 1.6 million events per second using one Flex Consumption app triggered from a network-restricted event hub.
“What really matters to us is that the app scales up and down based on demand. Azure Functions Flex Consumption is very appealing to us because of how it dynamically scales based on the number of messages that are queued up in Azure Event Hubs.”
—Stephan Miehe, GitHub Senior Director of Platform Security
In a recent test, GitHub’s new function app processed 1.6 million messages per second in the Azure Functions Flex Consumption plan.
A look back
GitHub’s problem lay in an internal messaging app orchestrating the flow between the telemetry producers and consumers. The app was originally deployed using Java-based binaries and Azure Event Hubs. But as it began handling up to 460 gigabytes (GB) of events per day, the app was reaching its design limits, and its availability began to degrade.
For best performance, each consumer of the old platform required its own environment and time-consuming manual tuning. In addition, the Java codebase was prone to breakage and hard to troubleshoot, and those environments were getting expensive to maintain as the compute overhead grew.
“We couldn’t accept the risk and scalability challenges of the current solution,“ Miehe says. He and his team began to weigh the alternatives. “We were already using Azure Event Hubs, so it made sense to explore other Azure services. Given the simple nature of our need—HTTP POST request—we wanted something serverless that carries minimal overhead.”
Familiar with serverless code development, the team focused on similar Azure-native solutions and arrived at Azure Functions.
“Both platforms are well known for being good for simple data crunching at large scale, but we don’t want to migrate to another product in six months because we’ve reached a ceiling.”
—Stephan Miehe, GitHub Senior Director of Platform Security
A function app can automatically scale the queue based on the amount of logging traffic. The question was how much it could scale. At the time GitHub began working with the Azure Functions team, the Flex Consumption plan had just entered private preview. Based on a new underlying architecture, Flex Consumption supports up to 1,000 partitions and provides a faster target-based scaling experience. The product team built a proof of concept that scaled to more than double the legacy platform’s largest topic at the time, showing that Flex Consumption could handle the pipeline.
“Azure Functions Flex Consumption gives us a serverless solution with 100% of the capacity we need now, plus all the headroom we need as we grow.”
—Stephan Miehe, GitHub Senior Director of Platform Security
Making a good solution great
GitHub joined the private preview and worked closely with the Azure Functions product team to see what else Flex Consumption could do. The new function app is written in Python to consume events from Event Hubs. It consolidates large batches of messages into one large message and sends it on to the consumers for processing.
Finding the right number for each batch took some experimentation, as every function execution has at least a small percentage of overhead. At peak usage times, the platform will process more than 1 million events per second. Knowing this, the GitHub team needed to find the sweet spot in function execution. Too high a number and there’s not enough memory to process the batch. Too small a number and it takes too many executions to process the batch and slows performance.
The right number proved to be 5,000 messages per batch. “Our execution times are already incredibly low—in the 100–200 millisecond range,” Miehe reports.
This solution has built-in flexibility. The team can vary the number of messages per batch for different use cases and can trust that the target-based scaling capabilities will scale out to the ideal number of instances. In this scaling model, Azure Functions determines the number of unprocessed messages on the event hub and then immediately scales to an appropriate instance count based on the batch size and partition count. At the upper bound, the function app scales up to one instance per event hub partition, which can work out to be 1,000 instances for very large event hub deployments.
“If other customers want to do something similar and trigger a function app from Event Hubs, they need to be very deliberate in the number of partitions to use based on the size of their workload, if you don’t have enough, you’ll constrain consumption.”
—Stephan Miehe, GitHub Senior Director of Platform Security
Azure Functions supports several event sources in addition to Event Hubs, including Apache Kafka, Azure Cosmos DB, Azure Service Bus queues and topics, and Azure Queue Storage.
Reaching behind the virtual network
The function as a service model frees developers from the overhead of managing many infrastructure-related tasks. But even serverless code can be constrained by the limitations of the networks where it runs. Flex Consumption addresses the issue with improved virtual network (VNet) support. Function apps can be secured behind a VNet and can reach other services secured behind a VNet—without degrading performance.
As an early adopter of Flex Consumption, GitHub benefited from improvements being made behind the scenes to the Azure Functions platform. Flex Consumption runs on Legion, a newly architected, internal platform as a service (PaaS) backbone that improves network capabilities and performance for high-demand scenarios. For example, Legion is capable of injecting compute into an existing VNet in milliseconds—when a function app scales up, each new compute instance that is allocated starts up and is ready for execution, including outbound VNet connectivity, within 624 milliseconds (ms) at the 50 percentile and 1,022 ms at the 90 percentile. That’s how GitHub’s messaging processing app can reach Event Hubs secured behind a virtual network without incurring significant delays. In the past 18 months, the Azure Functions platform has reduced cold start latency by approximately 53% across all regions and for all supported languages and platforms.
Working through challenges
This project pushed the boundaries for both the GitHub and Azure Functions engineering teams. Together, they worked through several challenges to achieve this level of throughput:
In the first test run, GitHub had so many messages pending for processing that it caused an integer overflow in the Azure Functions scaling logic, which was immediately fixed.
In the second run, throughput was severely limited due to a lack of connection pooling. The team rewrote the function code to correctly reuse connections from one execution to the next.
At about 800,000 events per second, the system appeared to be throttled at the network level, but the cause was unclear. After weeks of investigation, the Azure Functions team found a bug in the receive buffer configuration in the Azure SDK Advanced Message Queuing Protocol (AMQP) transport implementation. This was promptly fixed by the Azure SDK team and allowed GitHub to push beyond 1 million events per second.
Best practices in meeting a throughput milestone
With more power comes more responsibility, and Miehe acknowledges that Flex Consumption gave his team “a lot of knobs to turn,” as he put it. “There’s a balance between flexibility and the effort you have to put in to set it up right.”
To that end, he recommends testing early and often, a familiar part of the GitHub pull request culture. The following best practices helped GitHub meet its milestones:
Batch it if you can: Receiving messages in batches boosts performance. Processing thousands of event hub messages in a single function execution significantly improves the system throughput.
Experiment with batch size: Miehe’s team tested batches as large as 100,000 events and as small as 100 before landing on 5,000 as the max batch size for fastest execution.
Automate your pipelines: GitHub uses Terraform to build the function app and the Event Hubs instances. Provisioning both components together reduces the amount of manual intervention needed to manage the ingestion pipeline. Plus, Miehe’s team could iterate incredibly quickly in response to feedback from the product team.
The GitHub team continues to run the new platform in parallel with the legacy solution while it monitors performance and determines a cutover date.
“We’ve been running them side by side deliberately to find where the ceiling is,” Miehe explains.
The team was delighted. As Miehe says, “We’re pleased with the results and will soon be sunsetting all the operational overhead of the old solution.“
Explore solutions with Azure Functions
Azure Functions Flex Consumption
Azure Functions
The post GitHub scales on demand with Azure Functions appeared first on Azure Blog.
Quelle: Azure
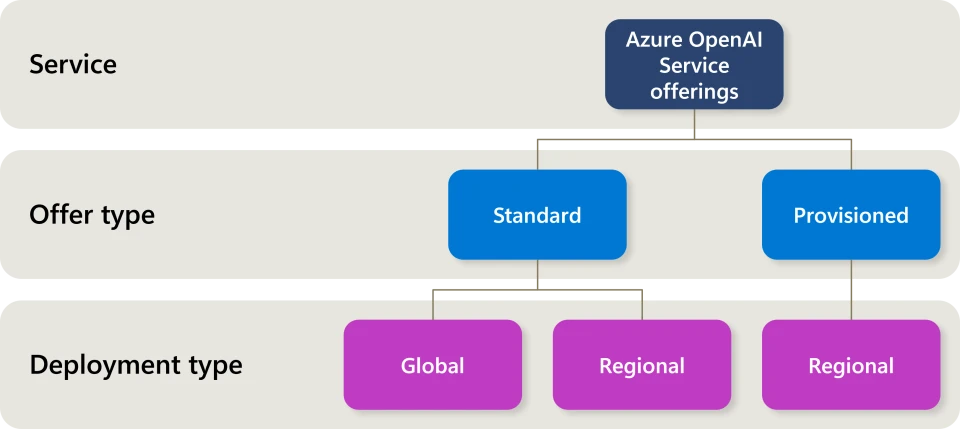
We’re excited to announce significant updates for Azure OpenAI Service, designed to help our 60,000 plus customers manage AI deployments more efficiently and cost-effectively beyond current pricing. With the introduction of self-service Provisioned deployments, we aim to help make your quota and deployment processes more agile, faster to market, and more economical. The technical value proposition remains unchanged—Provisioned deployments continue to be the best option for latency-sensitive and high-throughput applications. Today’s announcement includes self-service provisioning, visibility to service capacity and availability, and the introduction of Provisioned (PTU) hourly pricing and reservations to help with cost management and savings.
Azure OpenAI Service deployment and cost management solutions walkthrough
What’s new?
Self-Service Provisioning and Model Independent Quota Requests
We are introducing self-service provisioning alongside standard tokens, allowing you to request Provisioned Throughput Units (PTUs) more flexibly and efficiently. This new feature empowers you to manage your Azure OpenAI Service quata deployments independently without relying on support from your account team. By decoupling quota requests from specific models, you can now allocate resources based on your immediate needs and adjust as your requirements evolve. This change simplifies the process and accelerates your ability to deploy and scale your applications.
Visibility to service capacity and availability
Gain better visibility into service capacity and availability, helping you make informed decisions about your deployments. With this new feature, you can access real-time information about service capacity in different regions, ensuring that you can plan and manage your deployments more effectively. This transparency allows you to avoid potential capacity issues and optimize the distribution of your workloads across available resources, leading to improved performance and reliability for your applications.
Provisioned hourly pricing and reservations
We are excited to introduce two new self-service purchasing options for PTUs:
Hourly no-commitment purchasing
You can now create a Provisioned deployment for as little as an hour, with a flat hourly rate of $2 per unit per hour. This model-independent pricing makes it easy to deploy and tear down deployments as needed, offering maximum flexibility. This is ideal for testing scenarios or transitional periods without any long-term commitment.
Monthly and yearly Azure reservations for Provisioned deployments
For production environments with steady request volumes, Azure OpenAI Service Provisioned Reservations offer significant cost savings. By committing to a monthly or yearly reservation, you can save up to 82% or 85%, respectively, over hourly rates. Reservations are now decoupled from specific models and deployments, providing unmatched flexibility. This approach allows enterprises to optimize costs while maintaining the ability to switch models and adjust deployments as needed. Read our technical blog on Reservations here.
Azure OpenAI Service
Build your own copilot and generative AI applications
Try today
Benefits for decision makers
These updates are designed to provide flexibility, cost efficiency, and ease of use, making it simpler for decision-makers to manage AI deployments.
Flexibility: With self-service provisioning and hourly pricing, you can scale your deployments up or down based on immediate needs without long-term commitments.
Cost efficiency: Azure Reservations offer substantial savings for long-term use, enabling better budget planning and cost management.
Ease of use: Enhanced visibility and simplified provisioning processes reduce administrative burdens, allowing your team to focus on strategic initiatives rather than operational details.
Customer success stories
Before we made self-service available, select customers started achieving benefits of these options.
Visier Solutions: By leveraging Provisioned Throughput Units (PTUs) with Azure OpenAI Service, Visier Solutions has significantly enhanced their AI-powered people analytics tool, Vee. With PTUs, Visier guarantees rapid, consistent response times, crucial for handling the high volume of queries from their extensive customer base. This powerful synergy between Visier’s innovative solutions and Azure’s robust infrastructure not only boosts customer satisfaction by delivering swift and accurate insights but also underscores Visier’s commitment to using cutting-edge technology to drive transformational change in workforce analytics. Read the case study on Microsoft.
An analytics and insights company: Switched from Standard Deployments to GPT-4 Turbo PTUs and experienced a significant reduction in response times, from 10–20 seconds to just 2–3 seconds.
A Chatbot Services company: Reported improved stability and lower latency with Azure PTUs, enhancing the performance of their services.
A visual entertainment company: Noted a drastic latency improvement, from 12–13 seconds down to 2–3 seconds, enhancing user engagement.
Empowering all customers to build with Azure OpenAI Service
These new updates do not alter the technical excellence of Provisioned deployments, which continue to deliver low and predictable latency. Instead, they introduce a more flexible and cost-effective procurement model, making Azure OpenAI Service more accessible than ever. With self-service Provisioned, model-independent units, and both hourly and reserved pricing options, the barriers to entry have been drastically lowered.
To learn more about enhancing the reliability, security, and performance of your cloud and AI investments, explore the additional resources below.
Additional Resources
Azure Pricing Provisioned Reservations
Azure OpenAI Service Pricing
More details about Provisioned
Documentation for On-Boarding
PTU Calculator in Azure AI Studio
Unveiling Azure OpenAI Service Provisioned reservations blog
The post Elevate your AI deployments more efficiently with new deployment and cost management solutions for Azure OpenAI Service including self-service Provisioned appeared first on Azure Blog.
Quelle: Azure