Last December, #Docker acquired a company called Infinit. Using their technology, we will provide secure distributed storage out of the box, making it much easier to deploy stateful services and legacy enterprise applications on Docker.
During the last Docker Online Meetup, Julien Quintard, member of Docker’s technical staff and former CEO at Infinit, went through the design principles behind their product and demonstrated how the platform can be used to deploy a storage infrastructure through Docker containers in a few command lines.
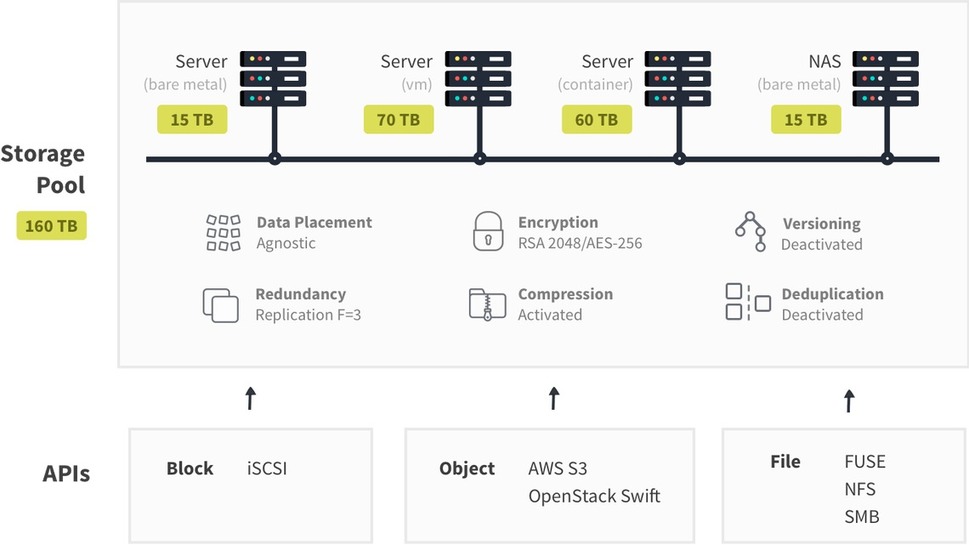
Providing state to applications in Docker requires a backend storage component that is both scalable and resilient in order to cope with a variety of use cases and failure scenarios. The Infinit Storage Platform has been designed to provide Docker applications with a set of interfaces (block, file and object) allowing for different tradeoffs.
Check out the following slidedeck to learn more about the internals of their platform:
Unfortunately, the video recording from the meetup is not available this time around but you can watch the following presentation and demo of Infinit from its CTO Quentin Hocquet at the Docker Distributed Systems Summit:
Docker and Infinit FAQ
1. Do you consider NFS/GPFS and other HPC cluster distributed storage as traditional? So far volume is working well for our evaluations, why would we need Infinit in an HPC use case?
Infinit has not been designed for HPC use cases. More specifically, it has been designed with scalability and resilience in mind. As such, if you are looking for high performance, there are a number of HPC-specific solutions. But those are likely to be limited one way or another when it comes tosecurity, scalability, flexibility, programmability etc.
Infinit may end up being an OK solution for HPC deployments but those are not the scenarios we have been targeting so far.
2. Does it work like P2P torrent?
Infinit and Bittorrent (and more generally torrent solutions) share a number of concepts such as the way data is retrieved by leveraging the upload bandwidth of a number of nodes to fill up a client’s bandwidth, also know as multi sourcing. Both solutions also rely on a distributed hash table (DHT).
However, Bittorrent is all about retrieval speed while Infinit is about scalability, resilience and security. In other words, Bittorrent’s algorithms are based on the popularity of a piece of data. The more nodes have that piece, the faster it will be for many concurrent clients to retrieve it. The drawback is that if a piece of information is unpopular, it will eventually be forgotten. Infinit, providing a storage solution to enterprises, cannot allow that and must therefore favor reliability and durability.
3. Does Infinit honor sync writes and what is the performance impact? Is there a reliability trade-off? (eventually consistent)
Yes indeed, there is always a tradeoff between reliability and performance. There is no magic, reliability can only be achieved through redundancy, be it through replication, erasure coding or else. And since such algorithms “enhance” the original information to make it unlikely to be forgotten should part of it be lost, it takes longer to write and to read.
Now I couldn’t possibly quantify the performance impact because it depends on many factors from your computing and networking resources to the redundancy algorithm and the factor you use to the data flow that will be generated and read from the storage layer.
In terms of consistency, Infinit has been designed to be strongly consistent, meaning that a system call completing indicates that the data has been redundantly written. However, given that we provide several logics on top of our key-value store (block, object and file) along with a set of interfaces (NFS, iSCSI, Amazon S3 etc.), we could emulate eventual consistency on top of our strongly consistent consensus algorithm.
4. For existing storage plugin owners, is this a replacement, or does it mean we can adapt our plugins to work with the Infinit architecture?
It is not Docker’s philosophy to impose on its community or customers a single solution. Docker has always described itself as a plumbing platform for mass innovation. Even though Infinit will very likely solve storage-related challenges in Docker’s products, it will always be possible to switch from the default for another storage solution per our batteries included but swappable philosophy.
As such, Docker’s objective with the acquisition of Infinit is not to replace all the other storage solution but rather to provide a reasonable default to the community. Also keep in mind that a storage solution solving all the use cases will likely never exist. The user must be able to pick the solution that best fits her needs.
5. Can you run the Infinit tools in a #container or does it require being a part of the host OS?
You can definitely run Infinit within a container if you want. Just note that if you intend to access the Infinit storage platform through an interface that relies on a kernel module, your container will need super-privileges to install/use this kernel module e.g FUSE.
6. Can you share the commands used during the demo?
The demo is very similar to what the Get Started demonstrates. I therefore invite you to follow this guide.
7. Would Infinit provide object & block storage?
Yes that is absolutely the plan. We’ve started with a file system logic and FUSE interface but we already have an object store logic in the pipeline as well as an Amazon S3 interface. However, the likely next logic you will see Infinit providing is a block storage with a network block device (NBD) interface.
8. It seems like this technology has use cases beyond Docker and containers, such as a modern storage infrastructure to use in place of RAID style systems. How do you expect that to play out with the Docker acquisition?
You are right, Infinit can be used in many use cases. Unfortunately it is a bit early to say how Infinit and Docker will integrate. As you are all aware, Docker is moving extremely fast. We are still working on figuring out where, when and how Infinit is going to contribute to Docker’s ecosystem.
So far, Infinit remains a standalone software-defined storage solution. As such, anyone can use it outside of Docker. It may remain like that in the future or it may become completely integrated in Docker. In any case, note that should Infinit be fully embedded in Docker, the reason would be to further simplify its deployment.
9. What are the next steps for Infinit now?
The next steps are quite simple. At the Docker level, we need to ease the process of deploying Infinit on a cluster of nodes so that developers and operators alike can benefit from a storage platform that is as easy to set up as an application cluster.
At the Infinit level, we are working on improving the scalability and resilience of the key-value store. Even though Infinit has been conceived with this properties in mind, we have not had enough time so far to stress Infinit through various scenarios.
We have also started working on more logics/interfaces: object storage with Amazon S3 and block storage with NBD. You can follow Infinit’s Roadmap on the website.
Finally, we’ve been working on open sourcing the three main Infinit components, namely the core libraries, key-value store and storage platform. For more information, you can check our Open Source webpage.
10. Good stuff how to get hold of bits to play with?
Everything is available on Infinit’s website, from tutorials, example deployments, documentation on the underlying technology, FAQ, roadmap, change log and soon, the sources.
Still hungry for more info?
Check this play with Docker and Infinit blog post
Join the docker-storage slack channel
[Tweet “Docker and @Infinit: A New Data Layer For Distributed Apps and container environments”]
The post Docker Storage and Infinit FAQ appeared first on Docker Blog.
Quelle: https://blog.docker.com/feed/
Published by