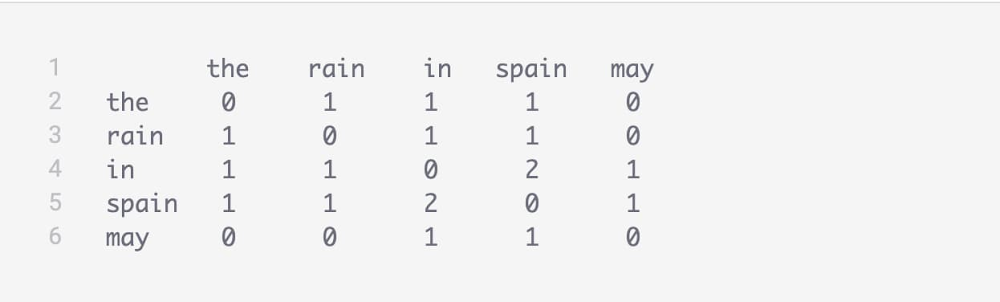
The goal of machine learning (ML) is to extract patterns from existing data to make predictions on new data. Embeddings are an important tool for creating useful representations for input features in ML, and are fundamental to search and retrieval, recommendation systems, and other use cases. In this blog, we’ll demonstrate a composable, extensible, and reusable implementation of Kubeflow Pipelines to prepare and learn item embeddings for structured data (item2hub pipeline), as well as custom word embeddings from a specialized text corpus (text2hub pipeline). These pipelines export the embeddings as TensorFlow Hub (TF-Hub) models, to be used as representations in various machine learning downstream tasks. The end-to-end KFP pipelines we’ll show here, and their individual components are available in Google Cloud AI Hub. You can go through this tutorial that executes the text2hub pipeline using Manual of the Operations of Surgery by Joseph Bell text corpus to learn specialized word embedding in the medical domain.Before we go into detail on these pipelines, let’s step back and get some background on the goals of ML, the types of data we can use, what exactly embeddings are, and how they are utilized in various ML tasks.Machine learning fundamentalsAs mentioned above, we use ML to discover patterns in existing data and use them to make predictions on new data. The patterns an ML algorithm discovers represent the relationships between the features of the input data and the output target that will be predicted. Typically, you expect that instances with similar feature values will lead to similar predicted output. Therefore, the representation of these input features and the objective against which the model is trained directly affect the nature and quality of the learned patterns. Input features are typically represented as real (numeric) values and models are typically trained against a label—or set of existing output data. For some datasets, it may be straightforward to determine how to represent the input features and train the model. For example, if you’re estimating the price of a house, property size in square meters, age of the building in years, and number of rooms might be useful features, while historical housing prices could make good labels to train the model from.Other cases are more complicated. How do you represent text data as vectors—or lists—of numbers? And what if you don’t have labeled data? For example, can you learn anything useful about how similar two songs are if you only have data about playlists that users create? There are two ideas that can help us use more complex types of data for ML tasks:Embeddings, which map discrete values (such as words or product IDs) to vectors of numbersSelf-supervised training, where we define a made-up objective instead of using a label. For example, we may not have any data that says that song_1 and song_2 are similar, but we can say that two songs are similar if they appear together in many users’ playlists.What is an embedding?As mentioned above, an embedding is a way to represent discrete items (such as words, song titles, etc.) as vectors of floating point numbers. Embeddings usually capture the semantics of an item by placing similar items close together in the embedding space. Take the following two pieces of text, for example: “The squad is ready to win the football match,” and, “The team is prepared to achieve victory in the soccer game.” They share almost none of the same words, but they should be close to one another in the embedding space because their meaning is very similar.Embeddings can be generated for items such as words, sentences, images, or entities like song_ids, product_ids, customer_ids, and URLs, among others. Generally, we understand that two items are similar if they share the same context, i.e., if they occur with similar items. For example, words that occur in the same textual context seem to be similar, movies watched by the same users are assumed to be similar, and products appearing in shopping baskets tend to be similar. Therefore, a sensible way to learn item embeddings is based on how frequently two items co-occur in a dataset.Because item similarity from co-occurrence is independent of a given learning task (such as classifying the songs into categories, or tagging words with POS), embeddings can be learned in a self-supervised fashion: directly from a text corpus or song playlists without needing any special labelling. Then, the learned embedding can be re-used in downstream tasks (classification, regression, recommendation, generation, forecasting, etc.) through transfer learning. A typical use of an item embedding is to search and retrieve the items that are the most similar to a given query item. For example, This can be used to recommend similar and relevant products, services, games, songs, movies, and so on. Pre-trained vs. custom embeddings TensorFlow Hub is a library for reusable ML and a repository of reusable, pre-trained models. These reusable models can be text embeddings trained from the web or image feature extractors trained from image classification tasks.More precisely, a pre-trained model shared on TensorFlow Hub is a self-contained piece of a TensorFlow graph, along with its weights and assets, that can be reused across different tasks. By reusing a pre-trained model, you can train a downstream model using a smaller amount of data, improve generalization, or simply speed up training. Each model from TF-Hub provides an interface to the underlying TensorFlow graph so it can be used with little or no knowledge of its internals. Models sharing the same interface can be switched very easily, speeding up experimentation. For example, you can use the Universal Sentence Encoder model to produce the embedding for a given input text as follows:Although pre-trained TF-Hub models are a great tool for building ML models with rich embeddings, there are cases where you want to train your own custom embeddings. For example, many TF-Hub text embeddings were trained on vast but generic text corpora like Wikipedia or Google News. This means that they are usually very good at representing generic text, but may not do a great job embedding text in a very specialized domain with a unique vocabulary, such as in the medical field.One problem in particular that arises when applying a generic model that was pre-trained on a generic corpus to a specialized corpus is that all the unique, domain-specific words will be mapped to the same “out-of-vocabulary” (OOV) vector. This means we lose a very valuable part of the text information, because for specialized texts the most informative words are often the words that are specific to that domain. In this blog post, we’ll take a detailed look at how to create custom embedding models, for text and structured data, using ready-to-use and easy-to-configure KFP pipelines hosted on AI Hub.Learning embeddings from co-occurrence dataMany algorithms have been introduced in the literature to learn custom embeddings for items given their co-occurrence data. Submatrix-wise Vector Embedding Learner (Swivel), introduced by Google AI, is a method for generating low dimensional feature embeddings from a feature co-occurrence matrix. For structured data, let’s say purchase orders, the co-occurrence matrix of different items can be computed by counting the number of purchase orders which contain both product A and product B. In summary, the Swivel algorithm works as follows:It performs approximate factorization of the Pointwise Mutual Information (PMI) matrix. It uses Stochastic Gradient Descent, or any of its variations, as an optimizer to minimize the cost function described below (the original implementation of the algorithm uses AdaGrad as an optimizer).It uses all the information in the matrix—observed and unobserved co-occurrences—which results in creating good embeddings for both common and rare items in the dataset.It utilizes a weighted piecewise loss with special handling for unobserved co-occurrences. It runs efficiently by grouping embedding vectors into blocks, each of which defines a submatrix, then performing submatrix-wise factorization. Each block includes a mix of embeddings for common and rare items.You can find the original TensorFlow implementation of the Swivel algorithm along with utilities for text preparation and embedding nearest neighbours matching, in the TensorFlow Research Models repository.Training your own embeddings Training embeddings for your items—whether they’re products, songs, movies, webpages or domain-specific text—involves more than just running an algorithm like Swivel. You also need to extract the data from its source, compute the co-occurrence matrix from the data, and export the embeddings produced by the algorithm as a TF-Hub model that can be used in downstream ML tasks. Then, to operationalize this process, you need to orchestrate these steps in a pipeline that can be automatically executed end-to-end.Kubeflow Pipelines is a platform for composing, orchestrating, and automating components of ML workflows where each of the components can run on a Kubeflow cluster, deployed either on Google Cloud, on other cloud platforms, or on-premise.A pipeline is a description of an ML workflow, that details the components of the workflow and the order in which they should be executed. A component is self-contained user code for an ML task that is packaged as a Docker container. A pipeline accepts a set of input parameters, whose values are passed to its components. You can share and discover KFP components and entire ready-to-use pipelines in Cloud AI Hub. For more information, see the KFP documentation, and Architecture for MLOps using TFX, Kubeflow Pipelines, and Cloud Build.The following four Kubeflow Pipelines components can help you build a custom embedding training pipeline for items in tabular data and words in specialised text corpora. These components can be found in AI Hub:text2cooc prepares the co-occurrence data from text files in the format expected by the Swivel algorithm. It accepts the location of the text corpus as an input, and outputs the co-occurrence counts as TFRecord files. tabular2cooc prepares the co-occurrence data from tabular and comma-separated data files in the format expected by the Swivel algorithm. It accepts the location of CSV files, including context ID and item ID as inputs, and outputs the co-occurrence counts as TFRecord files.cooc2emb runs the Swivel algorithm, which trains embeddings for items given their co-occurrence counts. The component accepts the location of the co-occurrence data, and produces embeddings for (row and column) items as TSV files. emb2hub creates a TensorFlow Hub model for the trained embedding, so that it can be used in ML tasks. The component accepts the location of the TSV embedding files as input, and outputs a TF-Hub model.The following is a high-level example of how these components can work together to learn word embeddings from a text corpus. Let’s say that you have a text file including the following sentences:The first step is to use the text2cooc component to generate co-occurrence data from the unstructured text data. The co-occurrence matrix looks like this:The second step is to use the cooc2emb component to generate embeddings using Swivel. If the specified embedding dimensions is two, the generated embeddings would look like this:The last step is to use emb2hub to export the embeddings as a Hub model. Then you can use this model to lookup embeddings for input text:These components can be integrated together to compose complete pipelines, and can be reused individually in other pipelines. Next, let’s look at text2hub and item2hub, two end-to-end pipelines that compose these components to train text and structured data embeddings. These pipelines can also be found in AI Hub.Text2Hub: A pipeline for custom text embeddingstext2hub is an end-to-end pipeline that uses the text2cooc, cooc2emb, and emb2hub components to train custom text embeddings and generate a TF-Hub model for using the embeddings downstream. To run the pipeline on your text data and train your custom text embeddings, you need only to set the gcs-path-to-the-text-corpus parameter to point to your text files in GCS.The text2cooc component of the pipeline lets you visualize the embedding space using TensorBoard, allowing for a quick inspection of the embedding quality. For example, in this tutorial, we fed the pipeline with the Manual of the Operations of Surgery by Joseph Bell from Project Gutenberg and produced the word embedding visualization below.Looking at the domain-specific word “ilium” (the superior and largest part of the hip bone) in the embedding space, we see that its closest neighbors (“spine”, “symphysis”, etc.) are very similar in meaning.Item2Hub: A pipeline for custom embeddings from tabular dataitem2hub is another end-to-end KFP pipeline that learns embeddings for song IDs given playlist data. To train embeddings from tabular data, you can just swap out the text2cooc component for tabular2cooc, which creates the co-occurrence data from tabular CSV files rather than from text. For example, we can use a publicly-available playlist dataset in BigQuery to generate embeddings for song tracks based on their co-occurrences in the playlists.The generated embeddings for songs allows you to find similar songs for search and recommendation. You can learn about how you can build an Approximate Nearest Neighbor (ANN) Index for efficient embedding similarity matching using this Colab. You can even try to extend this pipeline by creating a component that extracts the embeddings from the TF-Hub model (created in emb2hub) and builds an ANN index to be used for efficient matching.Getting startedTo learn more about how to get started, check out our page on setting up a Kubeflow Cluster on Google Cloud. For quick reference, here are some of the links included in the text above:Tutorial on text2hubhttps://github.com/GoogleCloudPlatform/training-data-analyst/blob/master/courses/machine_learning/deepdive2/text_classification/solutions/custom_tf_hub_word_embedding.ipynbAI Hub product pagePipelines pages: text2hub, item2hub Reusable components pages: text2cooc, abular2cooc, ooc2emb, emb2hubAcknowledgmentsKhalid Salama, Machine Learning Solutions Architect, Google Cloud
Quelle: Google Cloud Platform
Published by