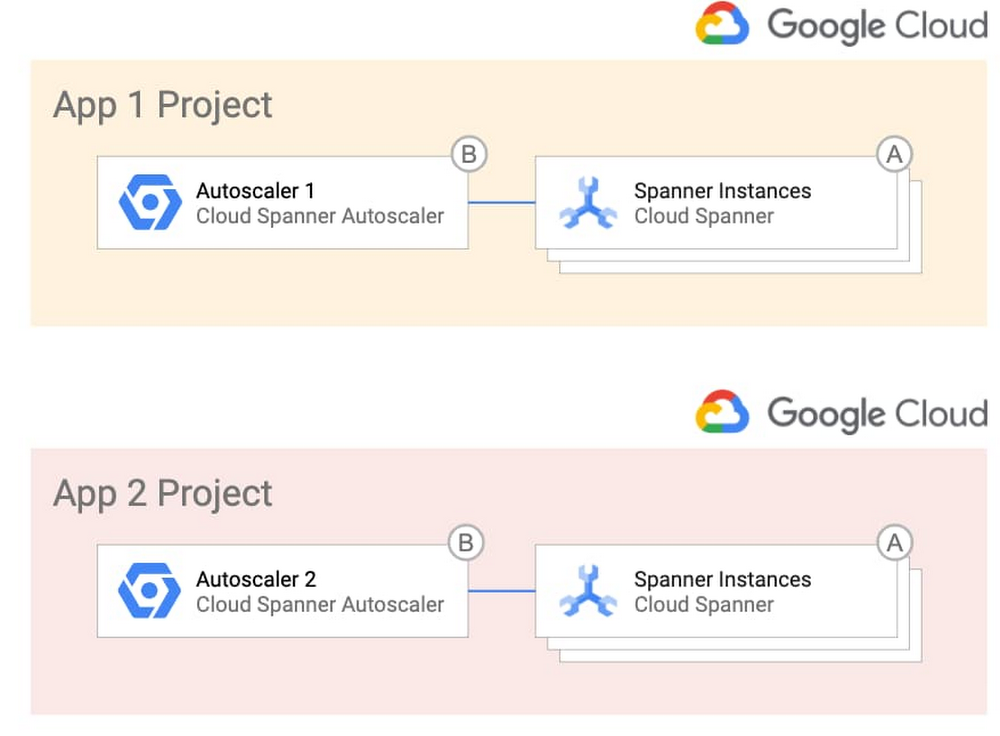
With Cloud Spanner, you can easily get a highly available, massively scalable relational database. This has enabled Google Cloud customers to innovate on applications without worrying about whether the database back end will scale to meet their needs. Spanner also lets you optimize costs based on usage. To make it even easier to build with Spanner, we’re announcing the release of the Autoscaler tool. Autoscaler is an open source tool for Spanner that watches key utilization metrics and adds or removes nodes as needed based on those metrics.To quickly jump in, clone this GitHub repository and set the Autoscaler up with the provided Terraform configuration files. What can the Autoscaler do for me?Autoscaler was built to make it easier to meet your operational needs while maximizing the efficiency of your cloud spend by adjusting the number of nodes based on your user demand. The Autoscaler supports three different scaling methods: linear, stepwise, and direct. With these scaling methods, you can configure the Autoscaler to match your workload. You can mix and match the methods to adjust to your load pattern throughout the day, and if you have batch processes, you can scale up on a schedule and then back down once the job has finished.While most load patterns can be managed using the default scaling methods, in the event you need further customization, you can easily add new metrics and scaling methods to the Autoscaler, extending it to support your particular workload. Many times you will have more than one Spanner instance to support your applications, so the Autoscaler can manage multiple Spanner instances from a single deployment. Autoscaler configuration is done through simple JSON objects, so different Spanner instances can have their own configurations and use a shared Autoscaler.Lastly, since development and operations teams have different working models and relationships, the Autoscaler supports a variety of different deployment models. Using these models, you can choose to deploy the Autoscaler alongside your Spanner instances or use one centralized Autoscaler to manage Spanner in different projects. The different deployment models allow you to find the right balance between empowering developers and minimizing support of the Autoscaler.Related Article3 reasons to consider Cloud Spanner for your next projectLearn about the cloud database Spanner, which brings massive scale and strong consistency to your applications. Here’s why to consider al…Read ArticleHow do I deploy the Autoscaler in my environment?If you want the simplest design, you can deploy the Autoscaler in a per-project topology, where each team that owns one or more Spanner instances becomes responsible for the Autoscaler infrastructure and configuration. Here’s what that looks like:Alternatively, if you want more control over the Autoscaler infrastructure and configuration, you can opt to centralize them and give the responsibility to a single operations team. This topology could be desirable in highly regulated industries. Here’s a look at that topology:If you want the best of both worlds, you can centralize the Autoscaler infrastructure so that a single team is in charge of it, which offers your application teams the freedom to manage the configuration of the Autoscaler for their individual Spanner deployments. This diagram shows this deployment option.To get you up and running quickly, the GitHub repository includes the Terraform configuration files and step-by-step instructions for each of the different environments.How does Autoscaler work?In a nutshell, the Autoscaler retrieves metrics from the Cloud Monitoring API, compares them to recommended thresholds, and requests Spanner to add or remove nodes. This diagram shows the internal components of the distributed deployment.You define how often the Autoscaler gets the metrics by configuring one or more Cloud Scheduler Jobs (1). When these jobs trigger, Cloud Scheduler publishes a message with per-instance configuration parameters that you define into a Pub/Sub queue (2). A Cloud Function (“Poller”) reads the message (3), calls the Cloud Monitoring API to get the Cloud Spanner instance metrics (4), and publishes them into another Pub/Sub queue (5).A separate Cloud Function (“Scaler”) reads the new message (6), verifies that a safe period has passed since the last scaling event (7), calculates the number of recommended nodes, and requests Cloud Spanner to add or remove nodes to a particular instance (8).Throughout the flow, the Autoscaler writes a step-by-step summary of its recommendations and actions to Cloud Logging for tracking and auditing.Get startedWith Autoscaler, you now have an easy way to automatically right-size your Spanner instances while continuing to deliver best performance and high availability for your database. Its deployment flexibility and configuration options mean that it can adapt to your particular use case, environments, and team structure. To learn more or contribute, check out the GitHub repository, experiment with the Autoscaler in a Qwiklab, or check out the free trial to get started.Related ArticleOpening the door to more dev tools for Cloud SpannerLearn how to integrate a graphical database development tool with cloud databases like Cloud Spanner with the JDBC driver.Read Article
Quelle: Google Cloud Platform

Published by