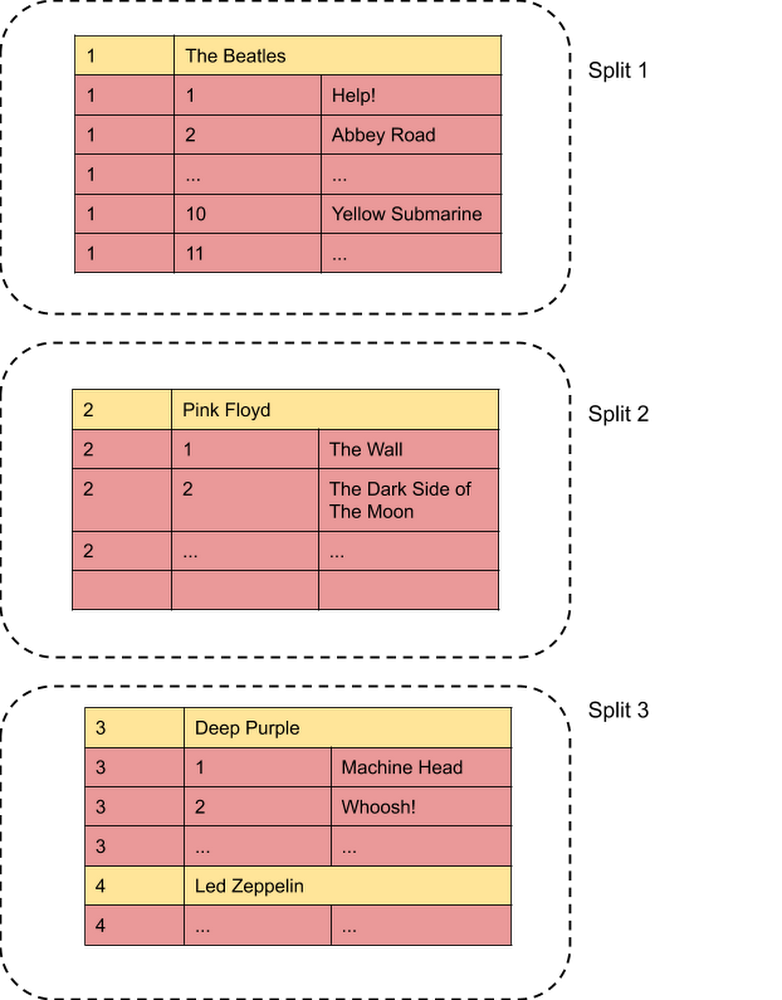
This post is going to shed some light on the magic that happens when an application executes a query against Cloud Spanner. How does Spanner take an arbitrary SQL statement, locate the data, and return the response in milliseconds? We will take some of the concepts described inSIGMOD’17 paper and explain, step by step, how the execution occurs.Spanner data location primerThe requisite background for understanding the rest of this post is understanding data layout in Spanner. The data is organized into tables which can be root level or interleaved in another table. Interleaving instructs Spanner to store rows of “child” tables sharing a primary key prefix close to their “parent” rows (see Parent-child table relationships section in Schema and Data model doc). For example, using the Spanner sample schema with Singers and Albums tables:The data is stored into splits, where the primary key of the top level table determines the split point. The key ranges of the resulting splits are [Singers(-∞), Singers(1)) – not shown, [Singers(1), Singers(2)), [Singers(2), Singers(3)) and [Singers(3), Singer(+∞)) respectively. Each split is placed independently and may or may not be co-located with another split on a server. A split has multiple replicas to maintain distributed consensus and ensure quorum for transactions. Spanner coprocessor frameworkSpanner uses a coprocessor framework. This component allows Spanner to direct RPCs to a data location rather than a specific server, providing an abstraction between the data model and data placement.For example, a call would specify Singers(2) as its destination and not an IP address of the server. The coprocessor framework would then resolve the split that owns this data and route the request to the nearest replica by network latency from the client. This way, if the data moves, the client application doesn’t need to be aware of it and can rely on the coprocessor framework to route the request. PrepareQueryWhen the client calls executeQuery() in Java (or ReadOnlyTransaction.Query in Go), the first coprocessor call that is executed is PrepareQuery. Since the query optimizer logic is not hosted in the client, the call is routed to a random server which parses and analyzes the query, returning the Location Hint to the client. The location hint specifies the key of the top level table to send the query to. For example, if your query is “SELECT SingerId, AlbumId, AlbumTitle from Albums WHERE SingerId=2”, the Location Hint will be “Singers(2)”.The location hint computationThe location hint is computed by analyzing the compiled query representation and finding predicates on the top level table’s key columns. The location hint can contain parameters, so that it can be cached for parameterized queries. For example, for a query “SELECT * FROM Albums WHERE (SingerId = 1 AND AlbumId >= 10) OR (SingerId IN (2,3) AND AlbumId != 0)”, the location hint extraction logic will determine that the query addresses a table under the top level table Singers, thus it will attempt to extract the first predicate for the SingerID column from the WHERE clause. Upon discovering SingerId = 1 it will generate the location hint Singers(1). If the query contained SingerId = @id, the location hint would be Singers(@id). This parameterized form is then resolved for the actual value of @id query parameter to yield the data location (so id=1 would give Singers(1)).The location hint is cached using a hash of the SQL text as key. This means that if your application executes the same query for different end users, it’s better to create a parametrized query to increase the cache hit rate. If this cache is hit, the call to PrepareQuery is completely avoided, thus improving the overall performance and query latency. This can be very significant for “simple” queries where the processing time is smaller than the round trip time; skipping a PrepareQuery call saves about half the latency. ExecuteQueryOnce the location hint is available, the next coprocessor call is ExecuteQuery. This call is routed based on the location hint, and the receiving server becomes the root server for the query. The server then compiles the query, creates the execution plan, and starts executing the required operations. The compiled query plan and execution plan are cached (so, again, parameterizing the queries is important to save this step on repeated queries).The execution plan will contain the Distributed Union operator to handle data access across one or more splits. In particular, there will be a Distributed Union on top of any execution tree. Additional Distributed Union operators might be inserted for other scans in the query (e.g. when joining two top level tables). The Distributed Union performs range extraction (described below), dispatches subqueries to the other splits, and streams results from the remote servers executing these subqueries to the caller. Distributed Union Range ExtractionSpanner compiles the predicates and builds a Filter Tree for efficient key predicate evaluation and range computation. For example, for the query from the above example “SELECT * FROM Albums WHERE (SingerId = 1 AND AlbumId >= 10) OR (SingerId IN (2,3) AND AlbumId != 0)”, the FilterTree might look like this (the red text is described below) :The computation for the distribution range tries to extract keys for the top level table (SingerID). The FilterTree considers ranges as shown in red. For example, the node “SingerId = 1” produces the range of [1]. The node “AlbumID>=10” is not relevant to this key, so its range is (-∞, ∞). The AND node above intersects the two ranges, ending with [1]. It proceeds in a similar fashion, ending with the overall SingerId range of [1,3]. When the distribution keys cannot be extracted from the query (e.g., “SELECT * FROM T” without any key predicates), the query will be dispatched to every split containing a portion of the table. Sending ExecuteInternalQuerySince the distribution range [1,3] is enumerable (contains a small number of discrete keys), the Distributed Union can iterate over each value of SingerID and dispatch a subquery to that location. If several top level rows are on the same split, a single ExecuteInternalQuery RPC will be sent to that split. Note how the internal query also uses the coprocessor framework to locate the data. This allows flexibility to move portions of the data to ensure even distribution of the load on each server, and the coprocessor framework can route the new requests to the updated location without the need for the query processing component to worry about it.The Distributed Union operator is responsible for getting the results from the remote splits, stitching them together and returning the combined results to the caller. If the number of splits is large, the query can reduce its wall clock time by specifying the USE_ADDITIONAL_PARALLELISM query hint at the expense of higher resource consumption.ConclusionExecuting a query against Spanner requires taking into account data placement and movement, which is dynamically managed. Spanner’s coprocessor framework insulates the rest of Spanner’s components from the details of the data’s physical location and adaptively routes requests based on the logical data description.Distribution key extraction in the PrepareQuery call allows Spanner to start the execution on the first server that needs to process the query. Additional subqueries are sent by it, if needed, to other servers containing the rest of the data splits. This mechanism allows arbitrarily complex queries that can gather the required data from the distributed splits and presents a simple executeQuery API to the end user. This post has only scratched the surface of the complexity in executing the query. The paper also describes restarts mechanism, storage improvements,transactions and much more… brought to you by the Spanner team. Learn moreTo get started with Spanner, create an instanceor try it out with a Spanner Qwiklab.Related Article3 reasons to consider Cloud Spanner for your next projectLearn about the cloud database Spanner, which brings massive scale and strong consistency to your applications. Here’s why to consider al…Read Article
Quelle: Google Cloud Platform
Published by