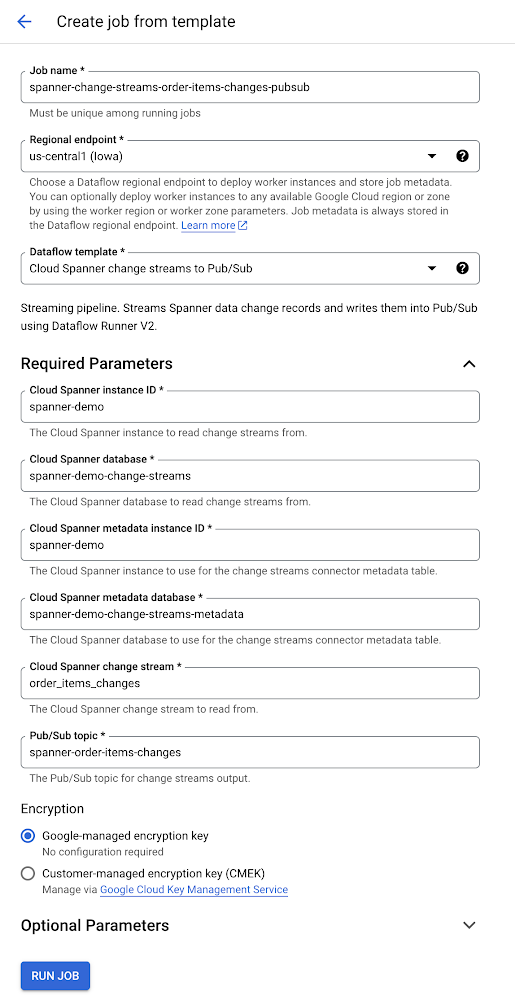
Since its launch, Cloud Spanner change streams has seen broad adoption by Spanner customers in healthcare, retail, financial services, and other industries. This blog post provides an overview of the latest updates to Cloud Spanner change streams and how they can be used to build event-driven applications.A change stream watches for changes to your Spanner database (inserts, updates, and deletes) and streams out these changes in near real-time. One of the most common uses of change streams is replicating Spanner data to BigQuery for analytics. With change streams, it’s as easy as writing Data definition language (DDL) to create a change stream on the desired tables and configuring Dataflow to replicate these changes to BigQuery so that you can take advantage of BigQuery’s advanced analytic capabilities.Yet analytics is just the start of what change streams can enable. Pub/Sub and Apache Kafka are asynchronous and scalable messaging services that decouple the services that produce messages from the services that process those messages. With support for Pub/Sub and Apache Kafka, Spanner change streams now lets you use Spanner transactional data to build event-driven applications.An example of an event-driven architecture is an order system that triggers inventory updates to an inventory management system whenever orders are placed. In this example, orders are saved in a table called order_items. Consequently, changes on this table will trigger events in the inventory system. To create a change stream that tracks all changes made order_items, run the following DDL statement:code_block[StructValue([(u’code’, u’CREATE CHANGE STREAM order_items_changes FOR order_items’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3ef9f6d0c6d0>)])]Once the order_items_changes change stream is created, you can create event streaming pipelines to Pub/Sub and Kafka.Creating an event streaming pipeline to Pub/SubThe change streams Pub/Sub Dataflow template lets you create Dataflow jobs that send change events from Spanner to Pub/Sub and build these kinds of event streaming pipelines.Once the Dataflow job is running, we can simulate inventory changes by inserting and updating order items in the Spanner database:code_block[StructValue([(u’code’, u”INSERT INTO order_items (order_item_id, order_id, article_id, quantity)rnVALUES (rn ‘5fb2dcaa-2513-1337-9b50-cc4c56a06fda’,rn ‘b79a2147-bf9a-4b66-9c7f-ab8bc6c38953′, rn ‘f1d7f2f4-1337-4d08-a65e-525ec79a1417′, rn 5rn);”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3efa0d3d6450>)])]code_block[StructValue([(u’code’, u”UPDATE order_items rnSET quantity = 10 rnWHERE order_item_id = ‘5fb2dcaa-2513-1337-9b50-cc4c56a06fda';”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3efa0d3d6b90>)])]This causes two change records to be streamed out through Dataflow and published as messages to the given Pub/Sub topic, as shown below:The first Pub/Sub message contains the inventory insert, and the second message contains inventory update.From here, the data can be consumed using any of the many integration options Pub/Sub offers.Creating an event streaming pipeline to Apache KafkaIn many event-driven architectures, Apache Kafka is the central event store and stream-processing platform. With our newly added Debezium-based Kafka connector, you can build event streaming pipelines with Spanner change streams and Apache Kafka. The Kafka connector produces a change event for every insert, update, and delete. It sends groups change event records for each Spanner table into a separate Kafka topic. Client applications then read the Kafka topics that correspond to the database tables of interest, and can react to every row-level event they receive from those topics.The connector has built-in fault-tolerance. As the connector reads changes and produces events, it records the last commit timestamp processed for each change stream partition. If the connector stops for any reason (e.g. communication failures, network problems, or crashes), it simply continues streaming records where it last left off once it restarts.To learn more about the change streams connector for Kafka, see Build change streams connections to Kafka. You can download the change streams connector for Kafka from Debezium.Fine-tuning your event messages with new value capture typesIn the example above, the stream order_items_changed that uses the default value capture type OLD_AND_NEW_VALUES. This means that the Change streams change record includes both the old and new values of a row’s modified columns, along with the primary key of the row. Sometimes, however, you don’t need to capture all that change data. For this reason, we added two new value capture types: NEW_VALUES and NEW_ROW, described below:To continue with our existing example, let’s create another change stream that contains only the new values of changed columns. This is the value capture type with the lowest memory and storage footprint.code_block[StructValue([(u’code’, u”CREATE CHANGE STREAM order_items_changed_values rnFOR order_itemsrnWITH ( value_capture_type = ‘NEW_VALUES’ )”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3ef9f6e7bf90>)])]The DDL above creates a change stream using the PostgreSQL interface syntax. Read Create and manage change streams to learn more about the DDL for creating change streams for both PostgreSQL and GoogleSQL Spanner databases.SummaryWith change streams, your Spanner data follows you wherever you need it, whether that’s for analytics with BigQuery, for triggering events in downstream applications, or for compliance and archiving. And because change streams are built into Spanner, there’s no software to install, and you get external consistency, high scale, and up to 99.999% availability.With support for Pub/Sub and Kafka, Spanner change streams makes it easier than ever to build event-driven pipelines with whatever flexibility you need for your business.To get started with Spanner, create an instance or try it out for free, or take a Spanner QwiklabTo learn more about Spanner change streams, check out About change streams To learn more about the change streams Dataflow template for Pub/Sub, go to Cloud Spanner change streams to Pub/Sub template To learn more about the change streams connector for Kafka, go to Build change streams connections to Kafka
Quelle: Google Cloud Platform
Published by