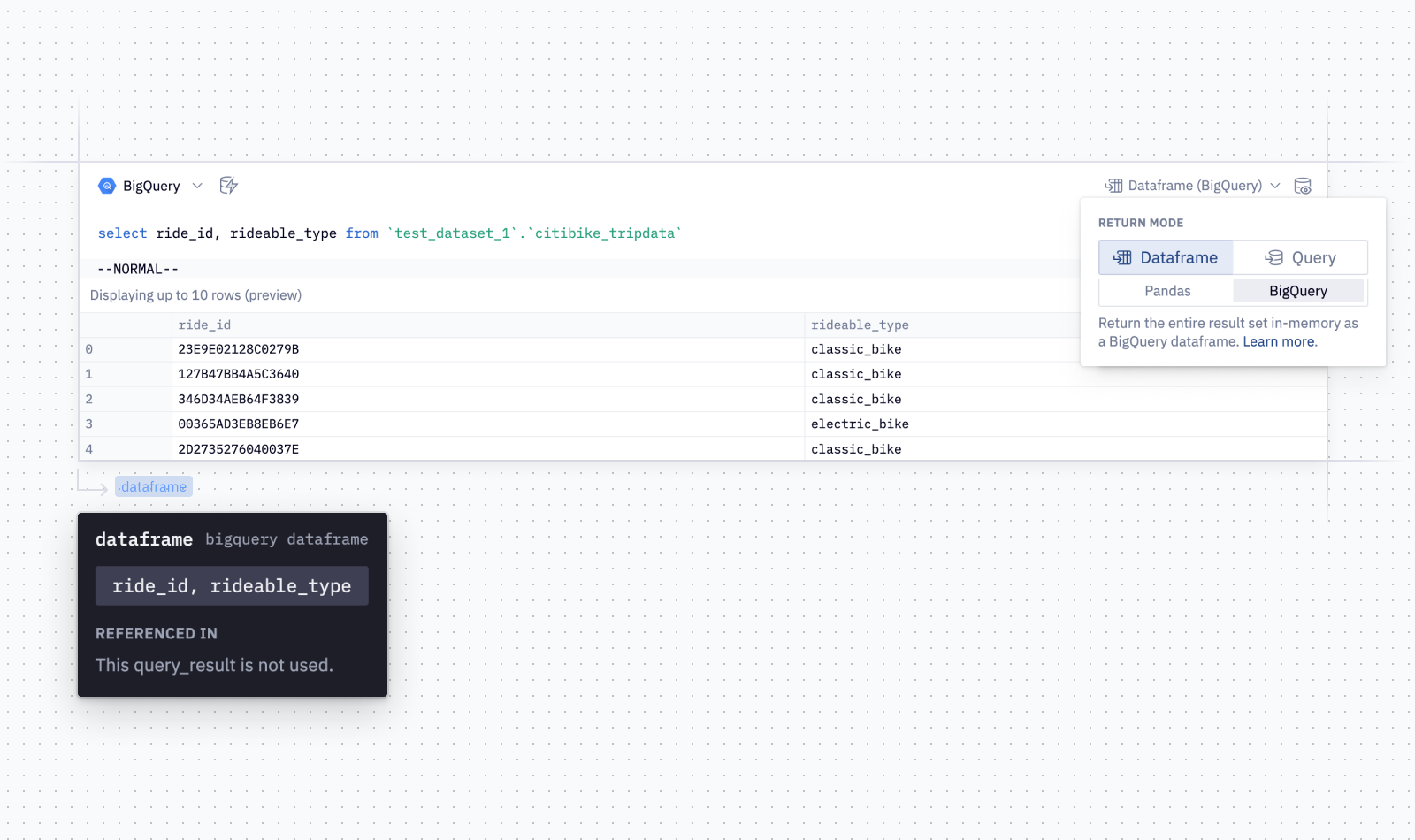
Want to know the latest from Google Cloud? Find it here in one handy location. Check back regularly for our newest updates, announcements, resources, events, learning opportunities, and more. Tip: Not sure where to find what you’re looking for on the Google Cloud blog? Start here: Google Cloud blog 101: Full list of topics, links, and resources.Week of Sep 18 – Sep 22Meet the inaugural cohort of the Google for Startups Accelerator: AI First program featuring groundbreaking businesses from eight countries across Europe and Israel using AI and ML to solve complex problems. Learn how Google Cloud empowers these startups and check out the selected ventures here.BigQuery is introducing new SQL capabilities for improved analytics flexibility, data quality and security. Some examples include schema support for Flexible column name, Authorized store proceduces, ANY_VALUE (HAVING) also known as MAX_BY and MIN_BY and many more. Check out full details here.Cloud Logging is introducing to Preview the ability to save charts from Cloud Logging’s Log Analytics to a custom dashboard in Cloud Monitoring. Viewing, copying and sharing the dashboards are supported in Preview. For more information, see Save a chart to a custom dashboard.Cloud Logging now supports customizable dashboards in its Logs Dashboard. Now you, can add your own charts to see what’s most valuable to you on the Logs Dashboard. Learn more here.Cloud Logging launches several usability features for effective troubleshooting. Learn more in this blog post.Search your logs by service name with the new option in Cloud Logging. Now you can use the Log fields to select by service which makes it easier to quickly find your Kubernetes container logs. Check out the details here.Community Security Analytics (CSA) can now be deployed via Dataform to help you analyze your Google Cloud security logs. Dataform simplifies deploying and operating CSA on BigQuery, with significant performance gains and cost savings. Learn more why and how to deploy CSA with Dataform in this blog post.Dataplex data profiling and AutoDQ are powerful new features that can help organizations to improve their data quality and build more accurate and reliable insights and models. These features and now Generally Available. Read more in this blog post. Week of Sep 4 – Sep 8Introducing Looker’s Machine Learning Accelerator. This easy to install extension allows business users to train, evaluate, and predict with machine learning models right in the Looker interface.Learn about how Freestar has built a super low latency, globally distributed application powered by Memorystore and the Envoy proxy. This reference walks users through the finer details of architecture and configuration, that they can easily replicate for their own needs.Week of Aug 28 – Sep 1You can access comprehensive and up-to-date environmental information to develop sustainability solutions and help people adapt to the impacts of climate change through Google Maps Platform’s environment APIs. The Air Quality, and Solar APIs are generally available today. Get startedor learn more in this blog post.Google Cloud’s Global Partner Ecosystems & Channels team launched the Industry Value Networks (IVN) initiative at Google Cloud Next ’23. IVNs combine expertise and offerings from systems integrators (SIs), independent software vendors (ISVs) and content partners to create comprehensive, differentiated, repeatable, and high-value solutions that accelerate time-to-value and reduce risk for customers. To learn more about the IVN initiative, please see this blog postWeek of Aug 21 – Aug 25You can now easily export data from Earth Engine into BigQuery with our new connector. This feature allows for improved workflows and new analyses that combine geospatial raster and tabular data. This is the first step in toward deeper interoperability between the two platforms, supporting innovations in geospatial sustainability analytics. Learn more in this blog post or join our session at Cloud Next.Week of Aug 14 – Aug 18You can now view your log query results as a chart in the Log Analytics page in Cloud Logging. With this new capability available in Preview, users can write a SQL filter and then use the charting configuration to build a chart. For more information, see Chart query results with Log Analytics.Week of Aug 7 – Aug 11You can now use Network Analyzer and Recommender API to query the IP address utilization of your GCP subnets, to identify subnets that might be full or oversized. Learn more in a dedicated blog post here.Memorystore has introduced version support for Redis 7.0. Learn more about the included features and upgrade your instance today!Week of July 31 – August 4Attack Path Simulation is now generally available in Security Command Center Premium. This new threat prevention capability automatically analyzes a customer’s Google Cloud environment to discover attack pathways and generate attack exposure scores to prioritize security findings. Learn more or get started now.Week of July 24-28Cloud Deploy has updated the UI with the ability to Create a Pipeline along with a Release. The feature is now GA. Read moreOur newly published Data & Analytics decision tree helps you select the services on Google Cloud that best match your data workloads needs, and the accompanying blog provides an overview of the services offered for data ingestion, processing, storage, governance, and orchestration.Customer expectations from the ecommerce platforms are at all time high and they now demand a seamless shopping experience across platforms, channels and devices. Establishing a secure and user-friendly login platform can make it easier for users to self-identify and help retailers gain valuable insights into customer’s buying habits. Learn more about how they can better manage customer identities to support an engaging ecommerce user experience using Google Cloud Identity Platform. Our latest Cloud Economics post just dropped, exploring how customers can benchmark their IT spending against peers to optimize investments. Comparing metrics like tech spend as a percentage of revenue and OpEx uncovers opportunities to increase efficiency and business impact. This data-driven approach is especially powerful for customers undergoing transformation.Week of July 17-21Cloud Deploy now supports deploy parameters. With deploy parameters you can pass parameters for your release, and those values are provided to the manifest or manifests before those manifests are applied to their respective target. A typical use for this would be to apply different values to manifests for different targets in a parallel deployment. Read moreCloud Deploy is now listed among other Google Cloud services which can be configured to meet Data Residency Requirements. Read moreLog Analytics in Cloud Logging now supports most regions. Users can now upgrade buckets to use Log Analytics in Singapore, Montréal, London, Tel Aviv and Mumbai. Read more for the full list of support regions.Week of July 10-14Cloud CDN now supports private origin authentication in GA. This capability improves security by allowing only trusted connections to access the content on your private origins and preventing users from directly accessing it.Workload Manager – Guided Deployment Automation is now available in Public Preview, with initial support for SAP solutions. Learn how to configure and deploy SAP workloads directly from a guided user interface, leveraging end-to-end automation built on Terraform and Ansible.Artifact Registry – Artifact registry now supports clean up policies now in Preview. Cleanup policies help you manage artifacts by automatically deleting artifacts that you no longer need, while keeping artifacts that you want to store. Read moreWeek of July 3-7Cloud Run jobs now supports long-running jobs. A single Cloud Run jobs task can now run for up to 24 hours. Read More.How Google Cloud NAT helped strengthen Macy’s security. Read moreWeek of June 26-30Cloud Deploy parallel deployment is now generally available. You can deploy to a target that’s configured to represent multiple targets, and your application is deployed to those targets concurrently. Read More.Cloud Deploy canary deployment strategy is now generally available. A canary deployment is a progressive rollout of an application that splits traffic between an already-deployed version and a new version. Read MoreWeek of June 19 – June 23Google Cloud’s Managed Service for Prometheus now supports Prometheus exemplars. Exemplars provide cross-signals correlation between your metrics and your traces so you can more easily pinpoint root cause issues surfaced in your monitoring operations.Managing logs across your organization is now easier with the general availability of user-managed service accounts. You can now choose your own service account when sending logs to a log bucket in a different project.Data Engineering and Analytics Day – Join Google Cloud experts on June 29th to learn about the latest data engineering trends and innovations, participate in hands-on labs, and learn best practices of Google Cloud’s data analytics tools. You will gain a deeper understanding of how to centralize, govern, secure, streamline, analyze, and use data for advanced use cases like ML processing and generative AI.Week of June 5 – June 9TMI: Shifting Down, Not Left- The first post in our new modernization series, The Modernization Imperative. Here, Richard Seroter talks about the strategy of ‘shifting down’ and relying on managed services to relieve burdens on developers. Cloud Econ 101: The first in a new series on optimizing cloud tools to achieve greater return on your cloud investments. Join us biweekly as we explore ways to streamline workloads, and explore successful cases of aligning technology goals to drive business value.Global External HTTP(S) Load Balancer and Cloud CDN’s advanced traffic management using flexible pattern matching is now GA. This allows you to use wildcards anywhere in your path matcher. You can use this to customize origin routing for different types of traffic, request and response behaviors, and caching policies. In addition, you can now use results from your pattern matching to rewrite the path that is sent to the origin.Dataform is Generally Available. Dataform offers an end-to-end experience to develop, version control, and deploy SQL pipelines in BigQuery. Using a single web interface, data engineers and data analysts of all skill levels can build production-grade SQL pipelines in BigQuery while following software engineering best practices such as version control with Git, CI/CD, and code lifecycle management. Learn more.The Public Preview of Frontend Mutual TLS Support on Global External HTTPS Load Balancing is now available. Now you can use Global External HTTPS Load Balancing to offload Mutual TLS authentication for your workloads. This includes client mTLS for Apigee X Northbound Traffic using Global HTTPS Load Balancer.FinOps from the field: How to build a FinOps Roadmap – In a world where cloud services have become increasingly complex, how do you take advantage of the features, but without the nasty bill shock at the end? Learn how to build your own FinOps roadmap step by step, with helpful tips and tricks from FinOps workshops Google has completed with customers.Security Command Center (SCC) Premium, our built-in security and risk management solution for Google Cloud, is now generally available for self-service activation for full customer organizations. Customers can get started with SCC in just a few clicks in the Google Cloud console. There is no commitment requirement, and pricing is based on a flexible pay-as-you-go model. Dataform is Generally Available. Dataform offers an end-to-end experience to develop, version control, and deploy SQL pipelines in BigQuery. Using a single web interface, data engineers and data analysts of all skill levels can build production-grade SQL pipelines in BigQuery while following software engineering best practices such as version control with Git, CI/CD, and code lifecycle management. Learn more.Week of May 29 – June 2Google Cloud Deploy. The price of an active delivery pipeline is reduced. Also, single-target delivery pipelines no longer incur a charge. Underlying service charges continue to apply. See Pricing Page for more details.Week of May 22 – 26Security Command Center (SCC) Premium pricing for project-level activation is now 25% lower for customers who use SCC to secure Compute Engine, GKE-Autopilot, App Engine and Cloud SQL. Please see our updated rate card. Also, we have expanded the number of finding types available for project-level Premium activations to help make your environment more secure. Learn more.Vertex AI Embeddings for Text: Grounding LLMs made easy: Many people are now starting to think about how to bring Gen AI and large language models (LLMs) to production services. You may be wondering “How to integrate LLMs or AI chatbots with existing IT systems, databases and business data?”, “We have thousands of products. How can I let LLM memorize them all precisely?”, or “How to handle the hallucination issues in AI chatbots to build a reliable service?”. Here is a quick solution: grounding with embeddings and vector search. What is grounding? What are embedding and vector search? In this post, we will learn these crucial concepts to build reliable Gen AI services for enterprise use with live demos and source code. Week of May 15 – 19Introducing the date/time selector in Log Analytics in Cloud Logging. You can now easily customize the date and time range of your queries in the Log Analytics page by using the same date/time-range selector used in Logs Explorer, Metrics Explorer and other Cloud Ops products. There are several time range options, such as preset times, custom start and end times, and relative time ranges. For more information, see Filter by time in the Log Analytics docs.Cloud Workstations is now GA. We are thrilled to announce the general availability of Cloud Workstations with a list of new enhanced features, providing fully managed integrated development environments (IDEs) on Google Cloud. Cloud Workstations enables faster developer onboarding and increased developer productivity while helping support your compliance requirements with an enhanced security posture. Learn MoreWeek of May 8 – 14Google is partnering with regional carriers Chunghwa Telecom, Innove (subsidiary of Globe Group) and AT&T to deliver the TPU (Taiwan-Philippines-U.S.) cable system — connecting Taiwan, Philippines, Guam, and California — to support growing demand in the APAC region. We are committed to providing Google Cloud customers with a resilient, high-performing global network. NEC is the supplier, and the system is expected to be ready for service in 2025. Introducing BigQuery differential privacy, SQL building blocks that analysts and data scientists can use to anonymize their data. We are also partnering with Tumult Labs to help Google Cloud customers with their differential privacy implementations.Scalable electronic trading on Google Cloud: A business case with BidFX: Working with Google Cloud, BidFX has been able to develop and deploy a new product called Liquidity Provision Analytics (“LPA”), launching to production within roughly six months, to solve the transaction cost analysis challenge in an innovative way. LPA will be offering features such as skew detection for liquidity providers, execution time optimization, pricing comparison, top of book analysis and feedback to counterparties. Read more here.AWS EC2 VMs discovery and assessment – mFit can discover EC2 VMs inventory in your AWS region and collect guest level information from multiple VMs to provide technical fit assessment for modernization. See demo video.Generate assessment report in Microsoft Excel file – mFit can generate detailed assessment report in Microsoft Excel (XLSX) format which can handle large amounts of VMs in a single report (few 1000’s) which an HTML report might not be able to handle.Regulatory Reporting Platform: Regulatory reporting remains a challenge for financial services firms. We share our point of view on the main challenges and opportunities in our latest blog, accompanied by an infographic and a customer case study from ANZ Bank. We also wrote a white paper for anyone looking for a deeper dive into our Regulatory Reporting Platform.Week of May 1-5Microservices observability is now generally available for C++, Go and Java. This release includes a number of new features and improvements, making it easier than ever to monitor and troubleshoot your microservices applications. Learn more on our user guide.Google Cloud Deploy Google Cloud Deploy now supports Skaffold 2.3 as the default Skaffold version for all target types. Release Notes.Cloud Build: You can now configure Cloud Build to continue executing a build even if specified steps fail. This feature is generally available. Learn more hereWeek of April 24-28General Availability: Custom Modules for Security Health Analytics is now generally available. Author custom detective controls in Security Command Center using the new custom module capability.Next generation Confidential VM is now available in Private Preview with a Confidential Computing technology called AMD Secure Encrypted Virtualization-Secure Nested Paging (AMD SEV-SNP) on general purpose N2D machines. Confidential VMs with AMD SEV-SNP enabled builds upon memory encryption and adds new hardware-based security protections such as strong memory integrity, encrypted register state (thanks to AMD SEV-Encrypted State, SEV-ES), and hardware-rooted remote attestation. Sign up here!Selecting Tier_1 networking for your Compute Engine VM can give you the bandwidth you need for demanding workloads. Check out this blog on Increasing bandwidth to Compute Engine VMs with TIER_1 networking.Week of April 17-21Use Terraform to manage Log Analytics in Cloud Logging: You can now configure Log Analytics on Cloud Logging buckets and BigQuery linked datasets by using the following Terraform modules:Google_logging_project_bucket_configgoogle_logging_linked_datasetWeek of April 10-14Assured Open Source Software is generally available for Java and Python ecosystems. Assured OSS is offered at no charge and provides an opportunity for any organization that utilizes open source software to take advantage of Google’s expertise in securing open source dependencies.BigQuery change data capture (CDC) is now in public preview. BigQuery CDC provides a fully-managed method of processing and applying streamed UPSERT and DELETE operations directly into BigQuery tables in real time through the BigQuery Storage Write API. This further enables the real-time replication of more classically transactional systems into BigQuery, which empowers cross functional analytics between OLTP and OLAP systems. Learn more here.Week of April 3 – 7Now Available: Google Cloud Deploy now supports canary release as a deployment strategy. This feature is supported in Preview. Learn moreGeneral Availability: Cloud Run services as backends to Internal HTTP(S) Load Balancers and Regional External HTTP(S) Load Balancers. Internal load balancers allow you to establish private connectivity between Cloud Run services and other services and clients on Google Cloud, on-premises, or on other clouds. In addition you get custom domains, tools to migrate traffic from legacy services, Identity-aware proxy support, and more. Regional external load balancer, as the name suggests, is designed to reside in a single region and connect with workloads only in the same region, thus helps you meet your regionalization requirements. Learn more.New Visualization tools for Compute Engine Fleets: TheObservability tab in the Compute Engine console VM List page has reached General Availability. The new Observability tab is an easy way to monitor and troubleshoot the health of your fleet of VMs Datastream for BigQuery is Generally Available: Datastream for BigQuery is generally available, offering a unique, truly seamless and easy-to-use experience that enables near-real time insights in BigQuery with just a few steps. Using BigQuery’s newly developed change data capture (CDC) and Storage Write API’s UPSERT functionality, Datastream efficiently replicates updates directly from source systems into BigQuery tables in real-time. You no longer have to waste valuable resources building and managing complex data pipelines, self-managed staging tables, tricky DML merge logic, or manual conversion from database-specific data types into BigQuery data types. Just configure your source database, connection type, and destination in BigQuery and you’re all set. Datastream for BigQuery will backfill historical data and continuously replicate new changes as they happen.Now available: Build an analytics lakehouse on Google Cloud whitepaper. The analytics lakehouse combines the benefits of data lakes and data warehouses without the overhead of each. In this paper, we discuss the end-to-end architecture which enable organizations to extract data in real-time regardless of which cloud or datastore the data reside in, use the data in aggregate for greater insight and artificial intelligence (AI) – all with governance and unified access across teams. Download now. Week of March 27 – 31Faced with strong data growth, Squarespace made the decision to move away from on-premises Hadoop to a cloud-managed solution for its data platform. Learn how they reduced the number of escalations by 87% with the analytics lakehouse on Google Cloud. Read nowLast chance: Register to attend Google Data Cloud & AI Summit: Join us on Wednesday, March 29, at 9 AM PDT/12 PM EDT to discover how you can use data and AI to reveal opportunities to transform your business and make your data work smarter. Find out how organizations are using Google Cloud data and AI solutions to transform customer experiences, boost revenue, and reduce costs. Register today for this no cost digital event.New BigQuery editions: flexibility and predictability for your data cloud: At the Data Cloud & AI Summit, we announced BigQuery pricing editions—Standard, Enterprise and Enterprise Plus—that allow you to choose the right price-performance for individual workloads. Along with editions, we also announced autoscaling capabilities that ensure you only pay for the compute capacity you use, and a new compressed storage billing model that is designed to reduce your storage costs. Learn more about latest BigQuery innovations and register for the upcoming BigQuery roadmap session on April 5, 2023.Introducing Looker Modeler: A single source of truth for BI metrics: At the Data Cloud & AI Summit, we introduced a standalone metrics layer we call Looker Modeler, available in preview in Q2. With Looker Modeler, organizations can benefit from consistent governed metrics that define data relationships and progress against business priorities, and consume them in BI tools such as Connected Sheets, Looker Studio, Looker Studio Pro, Microsoft Power BI, Tableau, and ThoughtSpot.Bucket based log based metrics — now generally available — allow you to track, visualize and alert on important logs in your cloud environment from many different projects or across the entire organization based on what logs are stored in a log bucket.Week of March 20 – 24Chronicle Security Operations Feature Roundup – Bringing a modern and unified security operations experience to our customers is and has been a top priority with the Google Chronicle team. We’re happy to show continuing innovation and even more valuable functionality. In our latest release roundup we’ll highlight a host of new capabilities focused on delivering improved context, collaboration, and speed to handle alerts faster and more effectively. Learn how our newest capabilities enable security teams to do more with less here.Announcing Google’s Data Cloud & AI Summit, March 29th! Can your data work smarter? How can you use AI to unlock new opportunities? Join us on Wednesday, March 29, to gain expert insights, new solutions, and strategies to reveal opportunities hiding in your company’s data. Find out how organizations are using Google Cloud data and AI solutions to transform customer experiences, boost revenue, and reduce costs. Register today for this no cost digital event.Artifact Registry Feature Preview – Artifact Registry now supports immutable tags for Docker repositories. If you enable this setting, an image tag always points to the same image digest, including the default latest tag. This feature is in Preview. Learn moreWeek of March 13 – 17A new era for AI and Google Workspace- Google Workspace is using AI to become even more helpful, starting with new capabilities in Docs and Gmail to write and refine content. Learn more.Building the most open and innovative AI ecosystem – In addition to the news this week on AI products, Google Cloud has also announced new partnerships, programs, and resources. This includes bringing bringing the best of Google’s infrastructure, AI products, and foundation models to partners at every layer of the AI stack: chipmakers, companies building foundation models and AI platforms, technology partners enabling companies to develop and deploy machine learning (ML) models, app-builders solving customer use-cases with generative AI, and global services and consulting firms that help enterprise customers implement all of this technology at scale. Learn more.From Microbrows to Microservices – Ulta Beauty is building their digital store of the future, but to maintain control over their new modernized application they turned to Anthos and GKE – Google Cloud’s managed container services, to provide an eCommerce experience as beautiful as their guests. Read our blog to see how a newly-minted Cloud Architect learnt Kubernetes and Google Cloud to provide the best possible architecture for his developers. Learn more.Now generally available, understand and trust your data with Dataplex data lineage – a fully managed Dataplex capability that helps you understand how data is sourced and transformed within the organization. Dataplex data lineage automatically tracks data movement across BigQuery, BigLake, Cloud Data Fusion (Preview), and Cloud Composer (Preview), eliminating operational hassles around manual curation of lineage metadata. Learn more here.Rapidly expand the reach of Spanner databases with read-only replicas and zero-downtime moves. Configurable read-only replicas let you add read-only replicas to any Spanner instance to deliver low latency reads to clients in any geography. Alongside Spanner’s zero-downtime instance move service, you have the freedom to move your production Spanner instances from any configuration to another on the fly, with zero downtime, whether it’s regional, multi-regional, or a custom configuration with configurable read-only replicas. Learn more here.To prepare for the busiest shopping season of the year, Black Friday and Cyber Monday, Lowe’s relies heavily on Google’s agile SRE Framework to ensure business and technical alignment, manage bots, and create an always-available shopping experience. Read more. Week of March 6 – 10Automatically blocking project SSH keys in Dataflow is now GA.This service option allows Dataflow users to prevent their Dataflow worker VMs from accepting SSH keys that are stored in project metadata, and results in improved security. Getting started is easy: enable the block-project-ssh-keys service option while submitting your Dataflow job.Celebrate International Women’s Day: Learn about the leaders driving impact at Google Cloud and creating pathways for other women in their industries. Read more.Google Cloud Deploy now supports Parallel Deployment to GKE and Cloud Run workloads. This feature is in Preview. Read more.Sumitovant doubles medical research output in one year using LookerSumitovant is a leading biopharma research company that has doubled their research output in one year alone. By leveraging modern cloud data technologies, Sumitovant supports their globally distributed workforce of scientists to develop next generation therapies using Google Cloud’s Looker for trusted self-service data research. To learn more about Looker check out https://cloud.google.com/lookerWeek of Feb 27 – Mar 3, 2023Accelerate Queries on your BigLake Tables with Cached Metadata (Preview!) Make your queries on BigLake Tables go faster by enabling metadata caching. Your queries will avoid expensive LIST operation for discovering files in the table and experience faster file and hive partition pruning. Follow the documentation here.Add geospatial intelligence to your Retail use cases by leveraging the CARTO platform on top of your data in BigQueryLocation data will add a new dimension to your Retail use cases, like site selection, geomarketing, and logistics and supply chain optimization. Read more about the solution and various customer implementations in the CARTO for Retail Reference Guide, and see a demonstration in this blog.Google Cloud Deploy support for deployment verification is now GA! Read more or Try the DemoWeek of Feb 20 – Feb 24, 2023Logs for Network Load Balancing and logs for Internal TCP/UDP Load Balancingare now GA!Logs are aggregated per-connection and exported in near real-time, providing useful information, such as 5-tuples of the connection, received bytes, and sent bytes, for troubleshooting and monitoring the pass-through Google Cloud Load Balancers. Further, customers can include additional optional fields, such as annotations for client-side and server-side GCE and GKE resources, to obtain richer telemetry.The newly published Anthos hybrid cloud architecture reference design guideprovides opinionated guidance to deploy Anthos in a hybrid environment to address some common challenges that you might encounter. Check out the architecture reference design guidehere to accelerate your journey to hybrid cloud and containerization.Week of Feb 13- Feb 17, 2023Deploy PyTorch models on Vertex AI in a few clicks with prebuilt PyTorch serving containers – which means less code, no need to write Dockerfiles, and faster time to production.Confidential GKE Nodes on Compute-Optimized C2D VMs are now GA. Confidential GKE Nodes help to increase the security of your GKE clusters by leveraging hardware to ensure your data is encrypted in memory, helping to defend against accidental data leakage, malicious administrators and “curious neighbors”. Getting started is easy, as your existing GKE workloads can run confidentially with no code changes required.Announcing Google’s Data Cloud & AI Summit, March 29th!Can your data work smarter? How can you use AI to unlock new opportunities? Register for Google Data Cloud & AI Summit, a digital event for data and IT leaders, data professionals, developers, and more to explore the latest breakthroughs. Join us on Wednesday, March 29, to gain expert insights, new solutions, and strategies to reveal opportunities hiding in your company’s data. Find out how organizations are using Google Cloud data and AI solutions to transform customer experiences, boost revenue, and reduce costs. Register today for this no cost digital event.Running SAP workloads on Google Cloud? Upgrade to our newly released Agent for SAP to gain increased visibility into your infrastructure and application performance. The new agent consolidates several of our existing agents for SAP workloads, which means less time spent on installation and updates, and more time for making data-driven decisions. In addition, there is new optional functionality that powers exciting products like Workload Manager, a way to automatically scan your SAP workloads against best-practices. Learn how to install or upgrade the agent here.Leverege uses BigQuery as a key component of its data and analytics pipeline to deliver innovative IoT solutions at scale. As part of the Built with BigQuery program, this blog post goes into detail about Leverege IoT Stack that runs on Google Cloud to power business-critical enterprise IoT solutions at scale. Download white paper Three Actions Enterprise IT Leaders Can Take to Improve Software Supply Chain Security to learn how and why high-profile software supply chain attacks like SolarWinds and Log4j happened, the key lessons learned from these attacks, as well as actions you can take today to prevent similar attacks from happening to your organization.Week of Feb 3 – Feb 10, 2023Immersive Stream for XRleverages Google Cloud GPUs to host, render, and stream high-quality photorealistic experiences to millions of mobile devices around the world, and is now generally available. Read more here.Reliable and consistent data presents an invaluable opportunity for organizations to innovate, make critical business decisions, and create differentiated customer experiences. But poor data quality can lead to inefficient processes and possible financial losses. Today we announce new Dataplex features: automatic data quality (AutoDQ) and data profiling, available in public preview. AutoDQ offers automated rule recommendations, built-in reporting, and serveless execution to construct high-quality data. Data profiling delivers richer insight into the data by identifying its common statistical characteristics. Learn more.Cloud Workstations now supports Customer Managed Encryption Keys (CMEK), which provides user encryption control over Cloud Workstation Persistent Disks. Read more.Google Cloud Deploy now supports Cloud Run targets in General Availability. Read more.Learn how to use NetApp Cloud Volumes Service as datastores for Google Cloud VMware Engine for expanding storage capacity. Read moreWeek of Jan 30 – Feb 3, 2023Oden Technologies uses BigQuery to provide real-time visibility, efficiency recommendations and resiliency in the face of network disruptions in manufacturing systems. As part of the Built with BigQuery program, this blog post describes the use cases, challenges, solution and solution architecture in great detail.Manage table and column-level access permissions using attribute-based policies in Dataplex. Dataplex attribute store provides a unified place where you can create and organize a Data Class hierarchy to classify your distributed data and assign behaviors such as Table-ACLs and Column-ACLs to the classified data classes. Dataplex will propagate IAM-Roles to tables, across multiple Google Cloud projects, according to the attribute(s) assigned to them and a single, merged policy tag to columns according to the attribute(s) attached to them. Read more. Lytics is a next generation composableCDP that enables companies to deploy a scalable CDP around their existing data warehouse/lakes. As part of the Built with BigQuery program for ISVs, Lytics leverages Analytics Hub to launch secure data sharing and enrichment solution for media and advertisers. This blog post goes over Lytics Conductor on Google Cloud and its architecture in great detail. Now available in public preview, Dataplex business glossary offers users a cloud-native way to maintain and manage business terms and definitions for data governance, establishing consistent business language, improving trust in data, and enabling self-serve use of data. Learn more here.Security Command Center (SCC), Google Cloud’s native security and risk management solution, is now available via self-service to protect individual projects from cyber attacks. It’s never been easier to secure your Google Cloud resources with SCC. Read our blog to learn more. To get started today, go to Security Command Center in the Google Cloud console for your projects.Global External HTTP(S) Load Balancer and Cloud CDN now support advanced traffic management using flexible pattern matching in public preview. This allows you to use wildcards anywhere in your path matcher. You can use this to customize origin routing for different types of traffic, request and response behaviors, and caching policies. In addition, you can now use results from your pattern matching to rewrite the path that is sent to the origin.Run large pods on GKE Autopilot with the Balanced compute class. When you need computing resources on the larger end of the spectrum, we’re excited that the Balanced compute class, which supports Pod resource sizes up to 222vCPU and 851GiB, is now GA.Week of Jan 23 – Jan 27, 2023Starting with Anthos version 1.14, Google supports each Anthos minor version for 12 months after the initial release of the minor version, or until the release of the third subsequent minor version, whichever is longer. We plan to have Anthos minor release three times a year around the months of April, August, and December in 2023, with a monthly patch release (for example, z in version x.y.z) for supported minor versions. For more information, read here.Anthos Policy Controller enables the enforcement of fully programmable policies for your clusters across the environments. We are thrilled to announce the launch of our new built-in Policy Controller Dashboard, a powerful tool that makes it easy to manage and monitor the policy guardrails applied to your Fleet of clusters. New policy bundles are available to help audit your cluster resources against kubernetes standards, industry standards, or Google recommended best practices. The easiest way to get started with Anthos Policy Controller is to just install Policy controller and try applying a policy bundle to audit your fleet of clusters against a standard such as CIS benchmark.Dataproc is an important service in any data lake modernization effort. Many customers begin their journey to the cloud by migrating their Hadoop workloads to Dataproc and continue to modernize their solutions by incorporating the full suite of Google Cloud’s data offerings. Check out this guide that demonstrates how you can optimize Dataproc job stability, performance, and cost-effectiveness. Eventarc adds support for 85+ new direct events from the following Google services in Preview: API Gateway, Apigee Registry, BeyondCorp, Certificate Manager, Cloud Data Fusion, Cloud Functions, Cloud Memorystore for Memcached, Database Migration, Datastream, Eventarc, Workflows. This brings the total pre-integrated events offered in Eventarc to over 4000 events from 140+ Google services and third-party SaaS vendors. mFit 1.14.0 release adds support for JBoss and Apache workloads by including fit analysis and framework analytics for these workload types in the assessment report. See the release notes for important bug fixes and enhancements.Google Cloud Deploy – Google Cloud Deploy now supports Skaffold version 2.0. Release notesCloud Workstations – Labels can now be applied to Cloud Workstations resources. Release notes Cloud Build- Cloud Build repositories (2nd gen) lets you easily create and manage repository connections, not only through Cloud Console but also through gcloud and the Cloud Build API. Release notesWeek of Jan 17 – Jan 20, 2023Cloud CDN now supports private origin authentication for Amazon Simple Storage Service (Amazon S3) buckets and compatible object stores in Preview. This capability improves security by allowing only trusted connections to access the content on your private origins and preventing users from directly accessing it.Week of Jan 9 – Jan 13, 2023Revionics partnered with Google Cloud to build a data-driven pricing platform for speed, scale and automation with BigQuery, Looker and more. As part of the Built with BigQuery program, this blog post describes the use cases, problems solved, solution architecture and key outcomes of hosting Revionics product, Platform Built for Change on Google Cloud. Comprehensive guide for designing reliable infrastructure for your workloads in Google Cloud. The guide combines industry-leading reliability best practices with the knowledge and deep expertise of reliability engineers across Google. Understand the platform-level reliability capabilities of Google Cloud, the building blocks of reliability in Google Cloud and how these building blocks affect the availability of your cloud resources. Review guidelines for assessing the reliability requirements of your cloud workloads. Compare architectural options for deploying distributed and redundant resources across Google Cloud locations, and learn how to manage traffic and load for distributed deployments. Read the full blog here.GPU Pods on GKE Autopilot are now generally available. Customers can now run ML training, inference, video encoding and all other workloads that need a GPU, with the convenience of GKE Autopilot’s fully-managed Kubernetes environment.Kubernetes v1.26 is now generally available on GKE. GKE customers can now take advantage of the many new features in this exciting release. This release continues Google Cloud’s goal of making Kubernetes releases available to Google customers within 30 days of the Kubernetes OSS release.Event-driven transfer for Cloud Storage:Customers have told us they need asynchronous, scalable service to replicate data between Cloud Storage buckets for a variety of use cases including aggregating data in a single bucket for data processing and analysis, keeping buckets across projects/regions/continents in sync, etc. Google Cloud now offers Preview support for event-driven transfer – serverless, real-time replication capability to move data from AWS S3 to Cloud Storage and copy data between multiple Cloud Storage buckets. Read the full blog here. Pub/Sub Lite now offers export subscriptions to Pub/Sub. This new subscription type writes Lite messages directly to Pub/Sub – no code development or Dataflow jobs needed. Great for connecting disparate data pipelines and migration from Lite to Pub/Sub. See here for documentation.
Quelle: Google Cloud Platform