The emergence of containerization has brought about a significant transformation in software development and deployment by providing a consistent and scalable environment on many platforms. For developers trying to optimize their operations, Docker in particular has emerged as the preferred technology. By using containers as the foundation, developers gain the same key benefits — portability, scalability, efficiency, and security — that they rely on for other workloads, seamlessly extending them to ML and AI applications. Using a real-world example involving a Snake AI game, we’ll examine in this article how TensorFlow.js can be used with Docker to run AI/ML in a web browser.
Why Docker for TensorFlow.js conversion?
With the help of TensorFlow.js, a robust toolkit, machine learning models can be executed in a web browser, opening up a plethora of possibilities for applications such as interactive demonstrations and real-time inference. Docker offers a sophisticated solution by guaranteeing consistency and user-friendliness throughout the conversion process by enclosing it inside a container.
The Snake AI neural network game
The Snake AI game brings a modern twist to the classic Snake game by integrating artificial intelligence that learns and improves its gameplay over time. In this version, you can either play manually using arrow keys or let the AI take control.
The AI running with TensorFlow continuously improves by making strategic movements to maximize the score while avoiding collisions. The game runs in a browser using TensorFlow.js, allowing you to test different trained models and observe how the AI adapts to various challenges.
Whether you’re playing for fun or experimenting with AI models, this game is a great way to explore the intersection of gaming and machine learning. In our approach, we’ve used the neural network to play the traditional Snake game.
Before we dive into the AI in this Snake game, let’s understand the basics of a neural network.
What is a neural network?
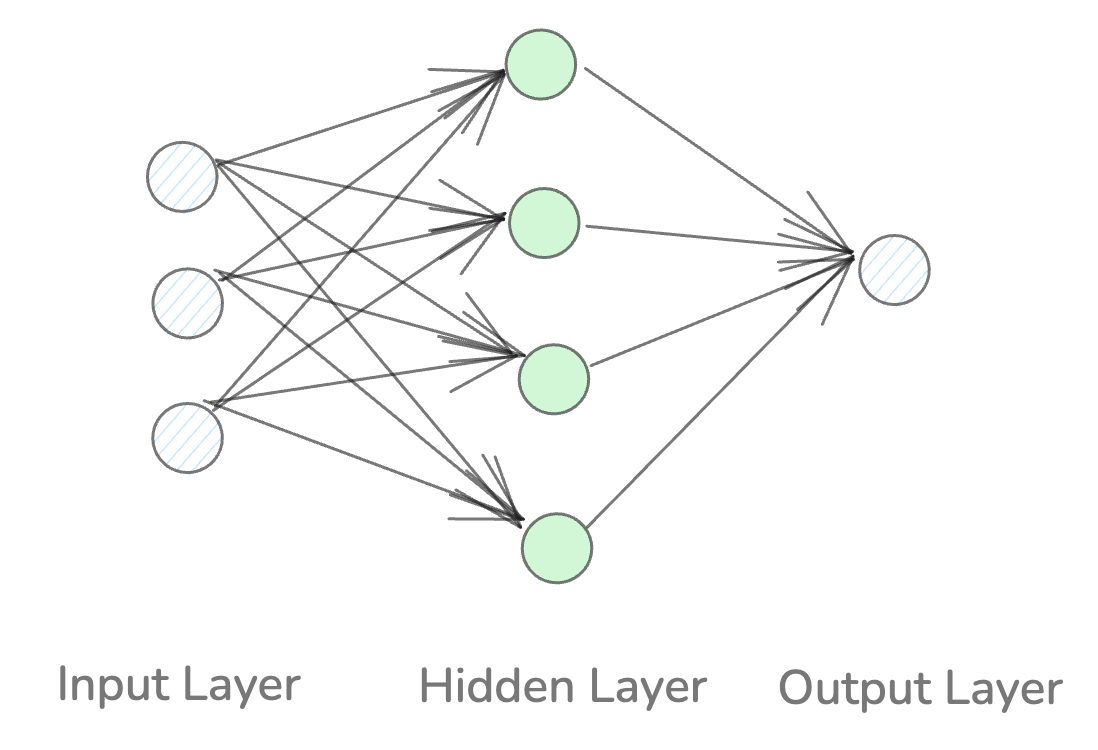
A neural network is a type of machine learning model inspired by the way the human brain works. It’s made up of layers of nodes (or “neurons”), where each node takes some inputs, processes them, and passes an output to the next layer.
Key components of a neural network:
Input layer: Receives the raw data (in our game, the snake’s surroundings).
Hidden layers: Process the input and extract patterns.
Output layer: Gives the final prediction
Figure 1: Key components of a neural network
Imagine each neuron as a small decision-maker. The more neurons and layers, the better the network can recognize patterns.
Types of neural networks
There are several types of neural networks, each suited for different tasks!
Feedforward Neural Networks (FNNs):
The simplest type, where data flows in one direction, from input to output.
Great for tasks like classification, regression, and pattern recognition.
Convolutional Neural Networks (CNNs):
Designed to work with image data.
Uses filters to detect spatial patterns, like edges or textures.
Recurrent Neural Networks (RNNs)
Good for sequence prediction (e.g., stock prices, text generation).
Remembers previous inputs, allowing it to handle time-series data.
Long Short-Term Memory Networks (LSTMs)
A specialized type of RNN that can learn long-term dependencies.
Generative Adversarial Networks (GANs)
Used for generating new data, such as creating images or deepfakes.
When to use each type:
CNNs: Image classification, object detection, facial recognition.
RNNs/LSTMs: Language models, stock market prediction, time-series data.
FNNs: Games like Snake, where the task is to predict the next action based on the current state.
How does the game work?
The snake game offers two ways to play:
Manual mode:
You control the snake using your keyboard’s arrow keys.
The goal is to eat the fruit (red square) without hitting the walls or yourself.
Every time you eat a fruit, the snake grows longer, and your score increases.
If the snake crashes, the game ends, and you can restart to try again.
AI mode:
The game plays itself using a neural network (a type of AI brain) built with TensorFlow.js.
The AI looks at the snake’s surroundings (walls, fruit location, and snake body) and predicts the best move: left, forward, or right.
After each game, the AI learns from its mistakes and becomes smarter over time.
With enough training, the AI can avoid crashing and improve its score.
Figure 2: The classic Nokia snake game with an AI twist
Getting started
Let’s go through how this game is built step by step. You’ll first need to install Docker to run the game in a web browser. Here’s a summary of the steps.
Clone the repository
Install Docker Desktop
Create a Dockerfile
Build the Docker image
Run the container
Access the game using the web browser
Cloning the repository
git clone https://github.com/dockersamples/snake-game-tensorflow-docker
Install Docker Desktop
Prerequisites:
A supported version of Mac, Linux, or Windows
At least 4 GB RAM
Click here to download Docker Desktop. Select the version appropriate for your system (Apple Silicon or Intel chip for Mac users, Windows, or Linux distribution)
Figure 3: Download Docker Desktop from the Docker website for your machine
Quick run
After installing Docker Desktop, run the pre-built Docker image and execute the following command in your command prompt. It’ll pull the image and start a new container running the snake-game:v1 Docker image and expose port 8080 on the host machine.
Run the following command to bring up the application:
docker compose up
Next, open the browser and go to http://localhost:8080 to see the output of the snake game and start your first game.
Why use Docker to run the snake game?
No need to install Nginx on your machine — Docker handles it.
The game runs the same way on any system that supports Docker.
You can easily share your game as a Docker image, and others can run it with a single command.
The game logic
The index.html file acts as the foundation of the game, defining the layout and structure of the webpage. It fetches the library TensorFlow.js, which powers the AI, along with script.js for handling gameplay logic and ai.js for AI-based movements. The game UI is simple yet functional, featuring a mode selector that lets players switch between manual control (using arrow keys) and AI mode. The scoreboard dynamically updates the score, high score, and generation count when the AI is training. Also, the game itself runs on an HTML <canvas> element, making it highly interactive. As we move forward, we’ll explore how the JavaScript files bring this game to life!
File : index.html
The HTML file sets up the structure of the game, like the game canvas and control buttons. It also fetches the library from Tensorflow which will be further used by the code to train the snake.
Canvas: Where the game is drawn.
Mode Selector: Lets you switch between manual and AI gameplay.
TensorFlow.js: The library that powers the AI brain!
File : script.js
This file handles everything in the game—drawing the board, moving the snake, placing the fruit, and keeping score.
const canvas = document.getElementById('gameCanvas');
const ctx = canvas.getContext('2d');
let snake = [{ x: 5, y: 5 }];
let fruit = { x: 10, y: 10 };
let direction = { x: 1, y: 0 };
let score = 0;
Snake Position: Where the snake starts.
Fruit Position: Where the apple is.
Direction: Which way the snake is moving.
The game loop
The game loop keeps the game running, updating the snake’s position, checking for collisions, and handling the score.
function gameLoopManual() {
const head = { x: snake[0].x + direction.x, y: snake[0].y + direction.y };
if (head.x === fruit.x && head.y === fruit.y) {
score++;
fruit = placeFruit();
} else {
snake.pop();
}
snake.unshift(head);
}
Moving the Snake: Adds a new head to the snake and removes the tail (unless it eats an apple).
Collision: If the head hits the wall or its own body, the game ends.
Switching between modes
document.getElementById('mode').addEventListener('change', function() {
gameMode = this.value;
});
Manual Mode: Use arrow keys to control the snake.
AI Mode: The neural network predicts the next move.
Game over and restart
function gameOver() {
clearInterval(gameInterval);
alert('Game Over');
}
function resetGame() {
score = 0;
snake = [{ x: 5, y: 5 }];
fruit = placeFruit();
}
Game Over: Stops the game when the snake crashes.
Reset: Resets the game back to the beginning.
Training the AI
File : ai.js
This file creates and trains the neural network — the AI brain that learns how to play Snake!
var movementOptions = ['left', 'forward', 'right'];
const neuralNet = tf.sequential();
neuralNet.add(tf.layers.dense({units: 256, inputShape: [5]}));
neuralNet.add(tf.layers.dense({units: 512}));
neuralNet.add(tf.layers.dense({units: 256}));
neuralNet.add(tf.layers.dense({units: 3}));
Neural Network: This is a simulated brain with four layers of neurons.
Input: Information about the game state (walls, fruit position, snake body).
Output: One of three choices: turn left, go forward, or turn right.
const optAdam = tf.train.adam(.001);
neuralNet.compile({
optimizer: optAdam,
loss: 'meanSquaredError'
});
Optimizer: Helps the brain learn efficiently by adjusting its weights.
Loss Function: Measures how wrong the AI’s predictions are, helping it improve.
Every time the snake plays a game, it remembers its moves and trains itself.
async function trainNeuralNet(moveRecord) {
for (var i = 0; i < moveRecord.length; i++) {
const expected = tf.oneHot(tf.tensor1d([deriveExpectedMove(moveRecord[i])], 'int32'), 3).cast('float32');
posArr = tf.tensor2d([moveRecord[i]]);
await neuralNet.fit(posArr, expected, { batchSize: 3, epochs: 1 });
expected.dispose();
posArr.dispose();
}
}
After each game, the AI looks at what happened, adjusts its internal connections, and tries to improve for the next game.
The movementOptions array defines the possible movement directions for the snake: ‘left’, ‘forward’, and ‘right’.
An Adam optimizer with a learning rate of 0.001 compiles the model, and a mean squared error loss function is specified. The trainNeuralNet function is defined to train the neural network using a given moveRecord array. It iterates over the moveRecord array, creates one-hot encoded tensors for the expected movement, and trains the model using the TensorFlow.js fit method.
Predicting the next move
When playing, the AI predicts what the best move should be.
function computePrediction(input) {
let inputs = tf.tensor2d([input]);
const outputs = neuralNet.predict(inputs);
return movementOptions[outputs.argMax(1).dataSync()[0]];
}
The computePrediction function makes predictions using the trained neural network. It takes an input array, creates a tensor from the input, predicts the movement using the neural network, and returns the movement option based on the predicted output.
The code demonstrates the creation of a neural network model, training it with a given move record, and making predictions using the trained model. This approach can enhance the snake AI game’s performance and intelligence by learning from its history and making informed decisions.
File : Dockerfile
FROM nginx:latest
COPY . /usr/share/nginx/html
FROM nginx:latest
This tells Docker to use the latest version of Nginx as the base image.
Nginx is a web server that’s great for serving static files like HTML, CSS, and JavaScript ( (which is what the Snake game is made of).
Instead of creating a server from scratch, the following line saves time by using an existing, reliable Nginx setup.
COPY . /usr/share/nginx/html
This line copies everything from your current project directory (the one with the Snake game files: index.html, script.js, ai.js, etc.) into the Nginx web server’s default folder for serving web content.
/usr/share/nginx/html is the default folder where Nginx looks for web files to display.
Development setup
Here’s how you can set up the development environment for the Snake game using Docker!
To make the development smoother, you can use Docker Volumes to avoid rebuilding the Docker image every time you change the game files.
Run the command from the folder where Snake-AI-TensorFlow-Docker code exists:
docker run -it –rm -d -p 8080:80 –name web -v ./:/usr/share/nginx/html nginx
If you hit an error like
docker: Error response from daemon: Mounts denied:
The path /Users/harsh/Downloads/Snake-AI-TensorFlow-Docker is not shared from the host and is not known to Docker.
You can configure shared paths from Docker -> Preferences… -> Resources -> File Sharing.
See https://docs.docker.com/desktop/settings/mac/#file-sharing for more info.
Open Docker Desktop, go to Settings -> Resources -> File Sharing -> Select the location where you cloned the repository code, and click on Apply & restart.
Figure 4: Using Docker Desktop to set up a development environment for the AI snake game
Run the command again, you won’t face any errors now
docker run -it –rm -d -p 8080:80 –name web -v ./:/usr/share/nginx/html nginx
Check if the container is running with the following command
harsh@Harshs-MacBook-Air snake-game-tensorflow-docker % docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c47e2711b2db nginx "/docker-entrypoint.…" 3 seconds ago Up 2 seconds 0.0.0.0:8080->80/tcp web
Open the browser and go to the URL http://localhost:8080, you’ll see the snake game output. This setup is perfect for development because it keeps everything fast and dynamic.
Figure 5: Accessing the snake game via a web browser.
Changes in the code will be reflected right away in the browser without rebuilding the container-v ~/.:/usr/share/nginx/html — This is the magic part! It mounts your local directory (Snake-AI-TensorFlow-Docker) into the Nginx HTML directory (/usr/share/nginx/html) inside the container.
Any changes you make to HTML, CSS, or JavaScript files in code ~/Snake-AI-TensorFlow-Docker immediately reflect in the running app without needing to rebuild the container.
Conclusion
In conclusion, building a Snake AI game using TensorFlow.js and Docker demonstrates how seamlessly ML and AI can be integrated into interactive web applications. Through this project, we’ve not only explored the fundamentals of reinforcement learning but also seen firsthand how Docker can simplify the development and deployment process.
By containerizing, Docker ensures a consistent environment across different systems, eliminating the common “it works on my machine” problem. This consistency makes it easier to collaborate with others, deploy to production, and manage dependencies without worrying about version mismatches or local configuration issues for web applications, machine learning projects, or AI applications.
Quelle: https://blog.docker.com/feed/