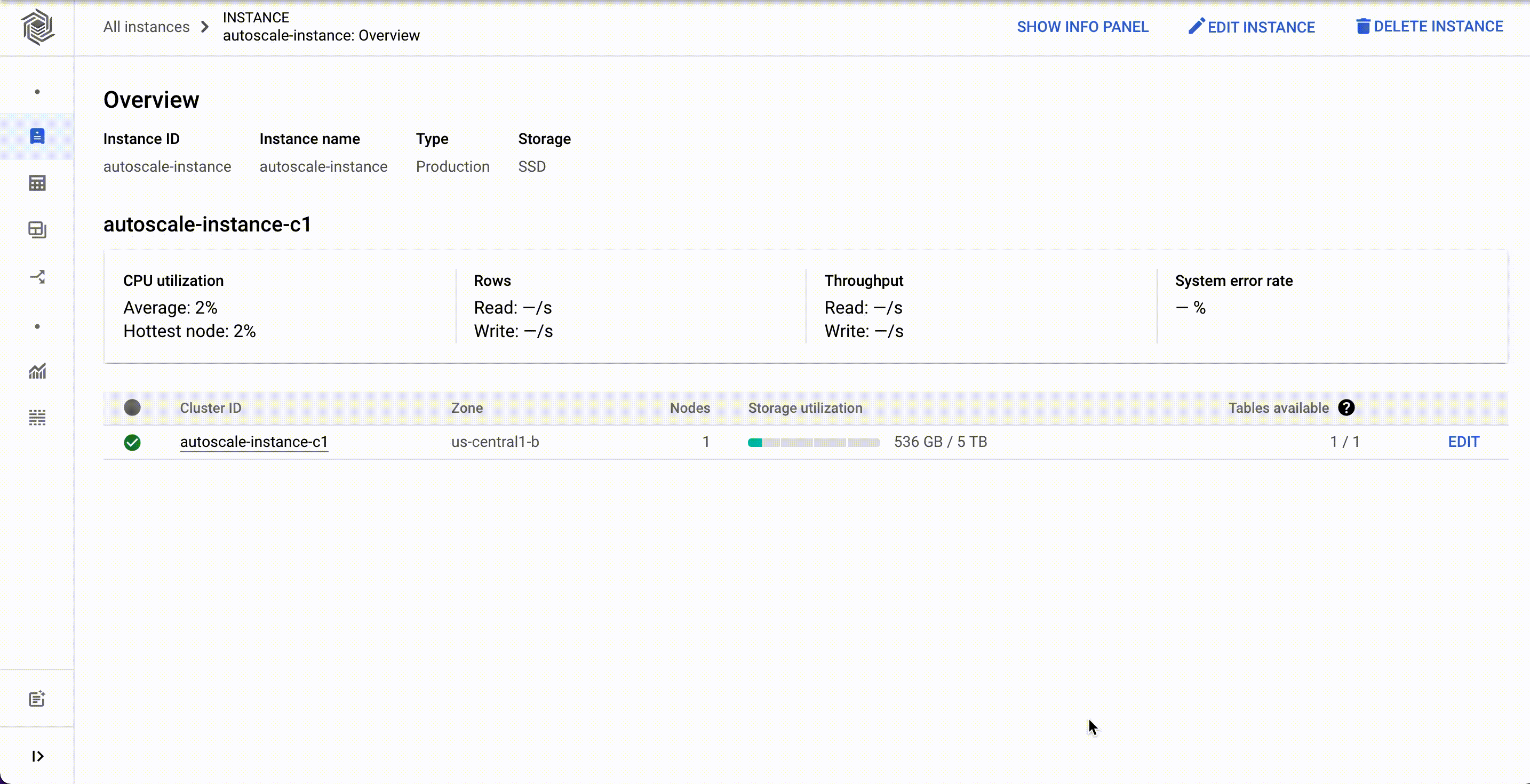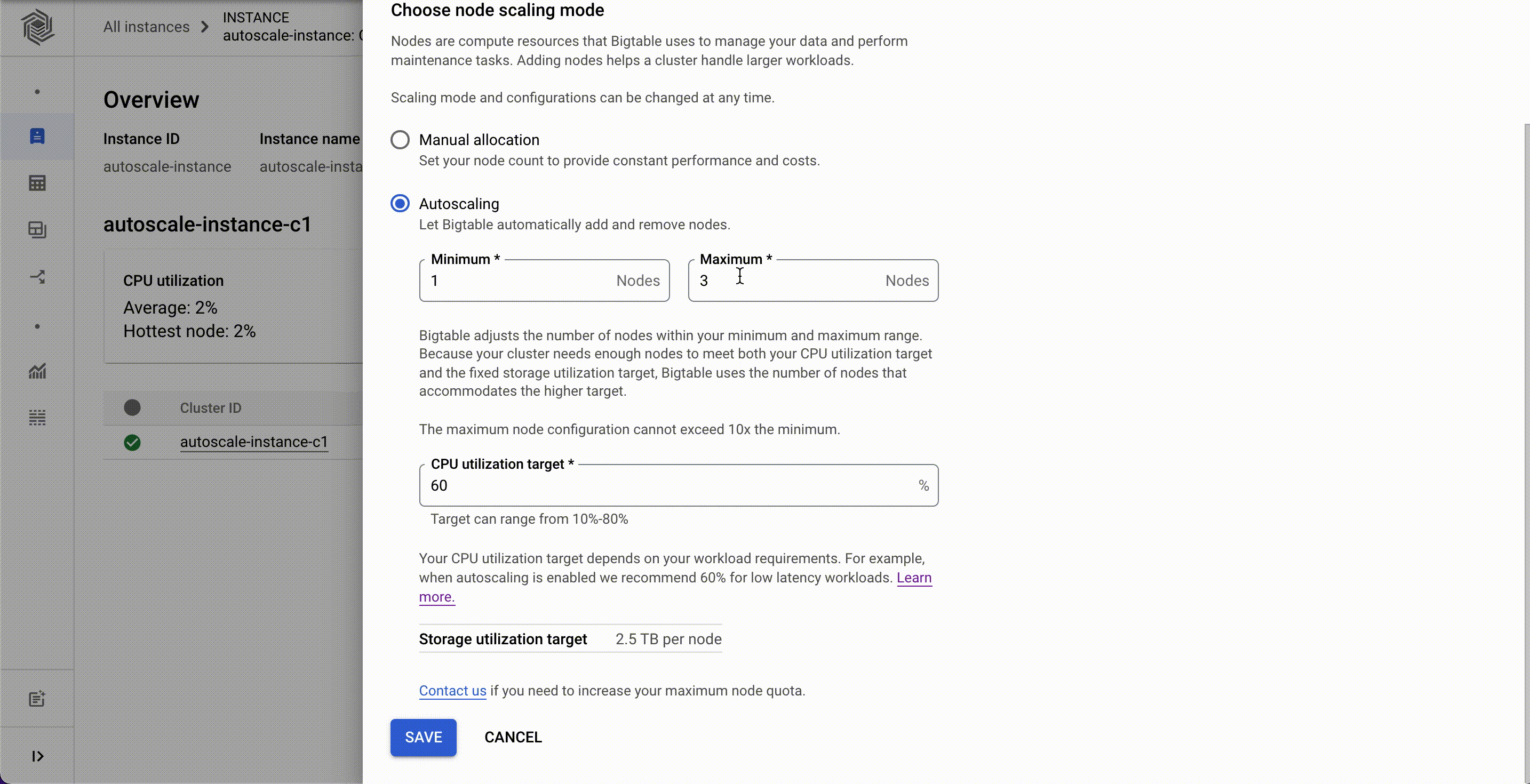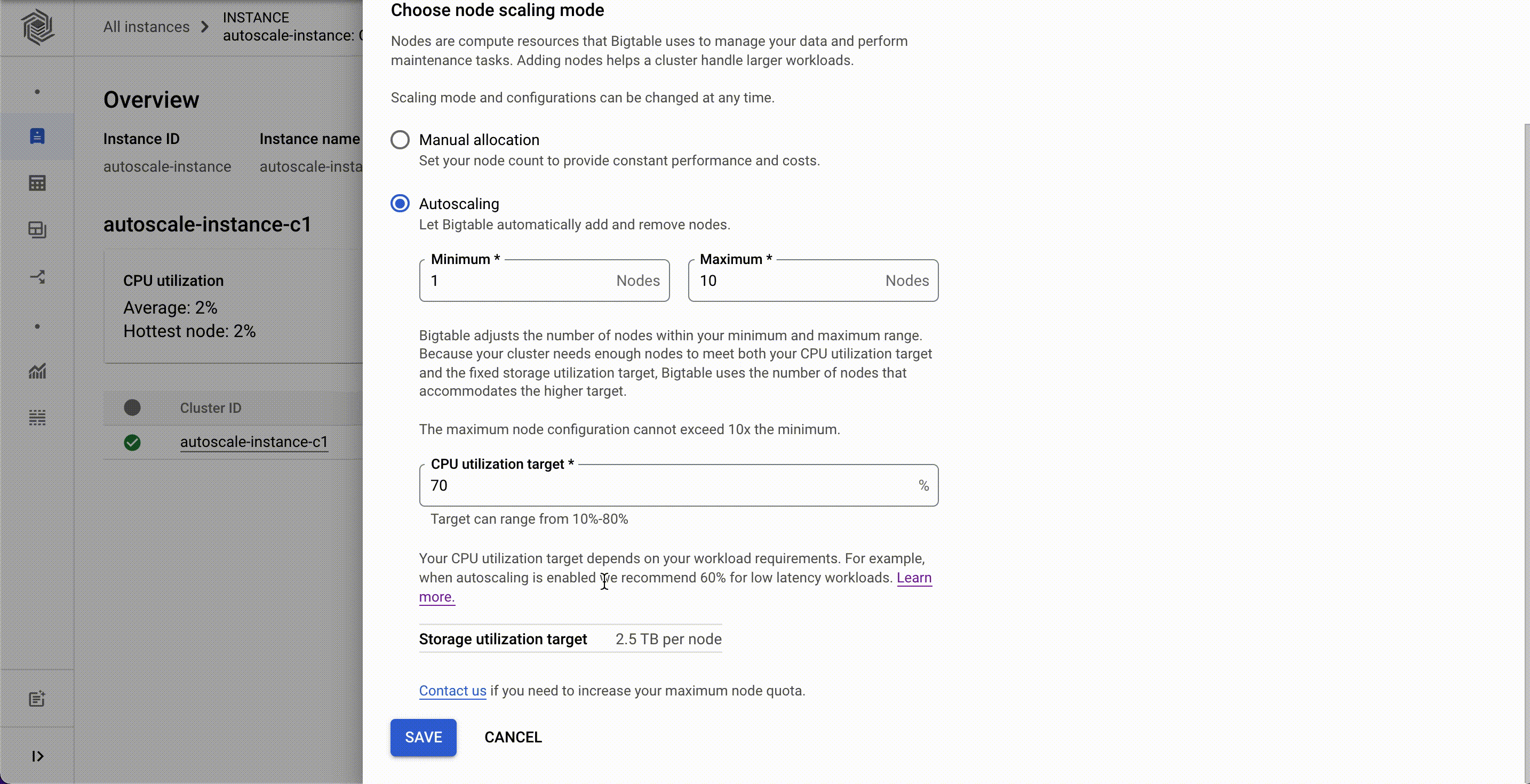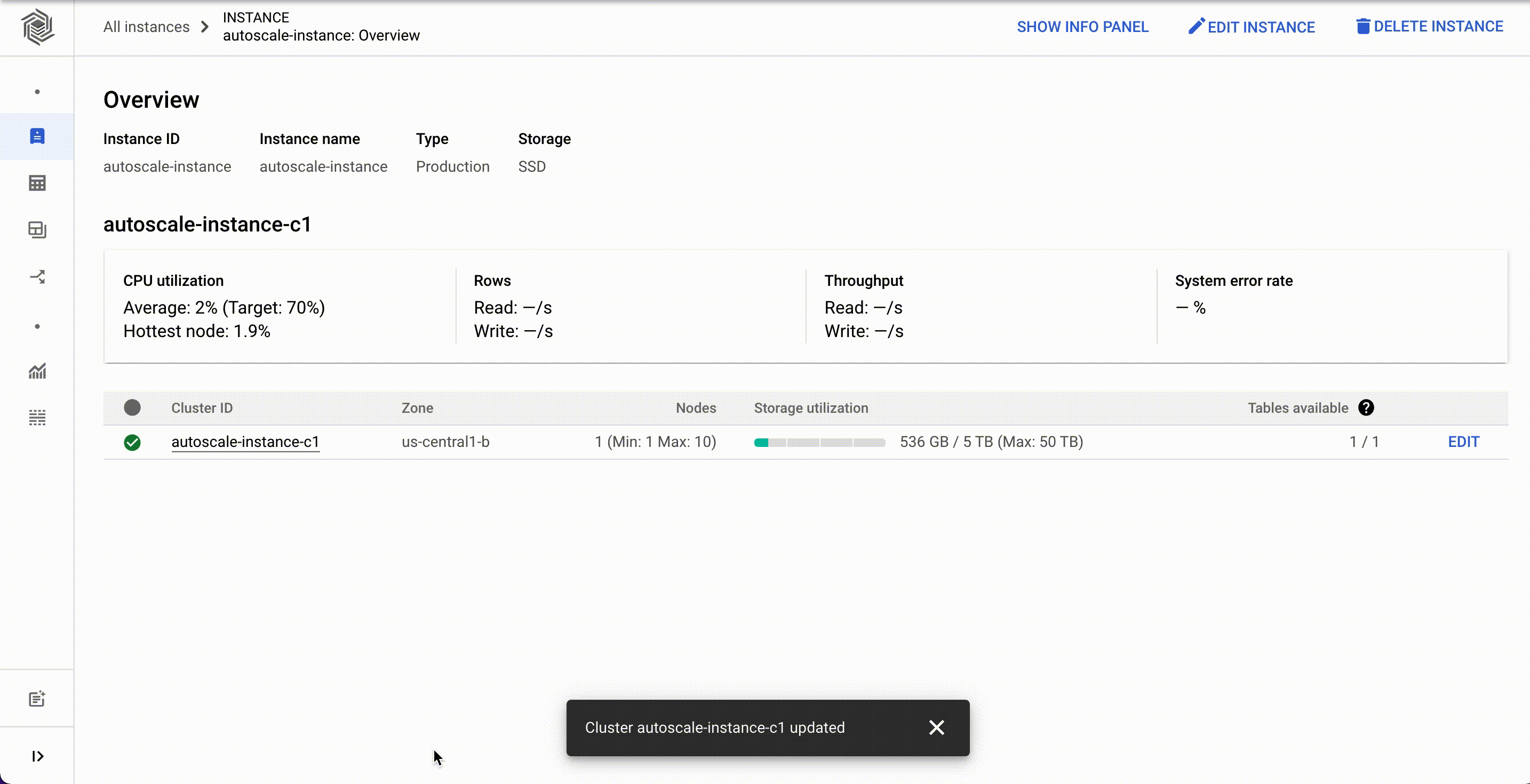
Cloud Bigtable is a fully managed, scalable NoSQL database service for large operational and analytical workloads used by leading businesses across industries, such as The Home Depot, Equifax, and Twitter. Bigtable has more than 10 Exabytes of data under management and processes more than 5 billion requests per second at peak. Today, we’re announcing the general availability of autoscaling for Bigtable that automatically adds or removes capacity in response to the changing demand for your applications. With autoscaling, you only pay for what you need and you can spend more time on your business instead of managing infrastructure. In addition to autoscaling, we recently launched new capabilities for Bigtable that reduce cost and management overhead:2X storage limit that lets you store more data for less, particularly valuable for storage optimized workloads.Cluster groups provide flexibility for determining how you route your application traffic to ensure a great experience for your customers. More granular utilization metrics improve observability, faster troubleshooting and workload management. Let’s discuss these capabilities in more detail. Optimize costs and improve manageability with autoscalingThe speed of digitization has increased in most aspects of life driving up consumption of digital experiences. The ability to scale up and scale down applications to quickly respond to shifts in customer demand is now more critical for businesses than ever before. Autoscaling for Bigtable automatically scales the number of nodes in a cluster up or down according to the changing demands of usage. It significantly lowers your risk of over-provisioning and incurring unnecessary costs, and under-provisioning which can lead to missed business opportunities. Bigtable now natively supports autoscaling with direct access to the Bigtable servers to provide a highly responsive autoscaling solution.Customers are able to set up an autoscaling configuration for their Bigtable clusters using the Cloud Console, gcloud, the Bigtable admin API, or our client libraries. It works on both HDD and SSD clusters, and is available in all Bigtable regions. You can set the minimum and maximum number of nodes for your Bigtable autoscaling configuration in Cloud Console as shown below.Once you have set up autoscaling, it is helpful to understand what autoscaling is doing, when and why to reconcile against billing and performance expectations. We have invested significantly in comprehensive monitoring and audit logging to provide developers with granular metrics and pre-built charts that explain how autoscaling makes decisions.Related ArticleBigtable Autoscaling: Deep dive and cost saving analysisBigtable now supports autoscaling. In this post we’ll look at when and how to use it, analyze autoscaling in action, and see its impact o…Read Article2X the storage limit Data is being generated at a tremendous pace and numerous applications need access to that data to deliver superior customer experiences.Many data pipelines supporting these applications require high throughput, and low latency access to vast amounts of data while maintaining the cost of compute resources. In order to meet the needs of storage driven workloads, Bigtable has doubled the storage capacity per node so that you can store more data for less, and don’t have to compromise on your data needs. Bigtable nodes now support 5TB per node (up from 2.5TB) for SSD and 16TB per node (up from 8TB) for HDD. This is especially cost-effective for batch workloads that operate on large amounts of data. Manageability at scale with cluster groupsBusinesses today need to serve users across regions and continents and ensure they provide the best experience to every user no matter the location. We recently launched the capability to deploy a Bigtable instance in up to 8 regions so that you can place the data as close to the end user as possible. A greater number of regions helps ensure your applications are performant for a consistent customer experience, where your customers are located. Previously, an instance was limited to four regions.With a global presence, there are typically multiple applications that require access to the replicated data. Each application needs to ensure that its serving path traffic does not see increased latency or reduced throughput because of a potential ‘noisy neighbor’ when additional workloads need access to the data. To provide improved workload management, we recently launched App Profile Cluster Group routing. Cluster group routing provides finer grained workload isolation management, allowing you to configure where to route your application traffic. This will allow you to allocate Bigtable clusters to handle certain traffic like batch workloads while not directly impacting the clusters being used to serve your customers.Greater observabilityHaving detailed insight and understanding of how your Bigtable resources are being utilized to support your business is crucial for troubleshooting and optimizing resource allocation. The recently launched CPU utilization by app profile metric includes method and table dimensions. These additional dimensions provide more granular observability into the Bigtable cluster’s CPU usage and how your Bigtable instance resources are being used. These observability metrics tell you what applications are accessing what tables with what API method, making it much easier to quickly troubleshoot and resolve issues.Learn moreTo get started with Bigtable, create an instanceor try it out with a Bigtable Qwiklab.Check out Youtube videos for step by step introduction to how Bigtable can be used in real world applications like Personalisation and Fraud detection.Learn how you can migrate data from HBase to Bigtable
Quelle: Google Cloud Platform
Published by