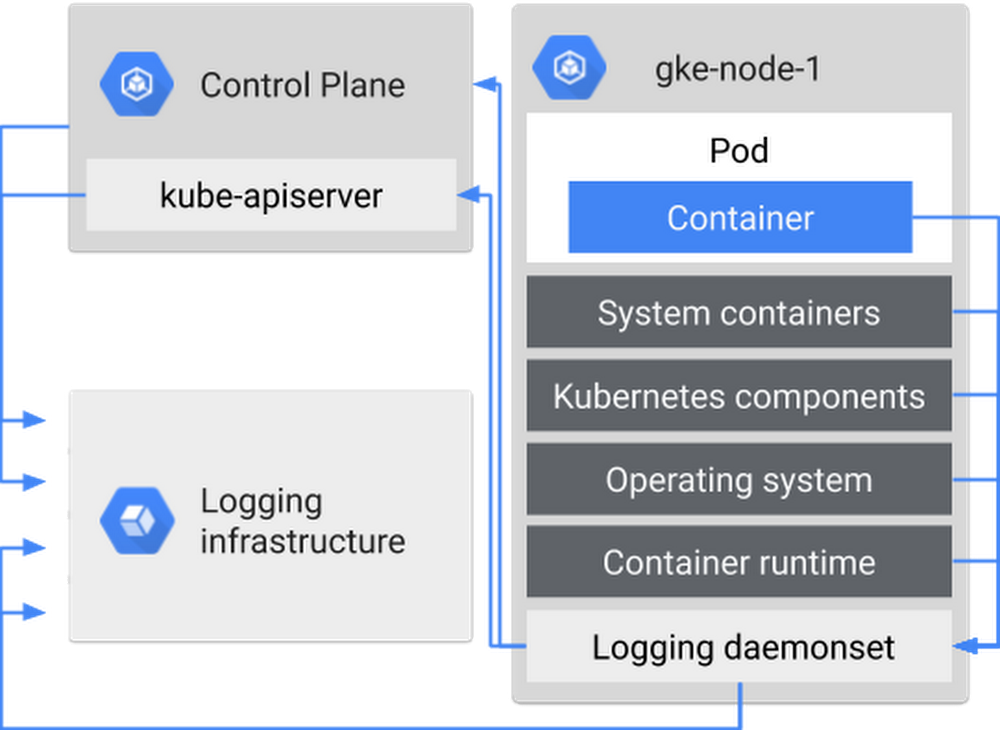
Running workloads in containers can be much easier to manage and more flexible for developers than running them in VMs, but what happens if a container gets attacked? It can be bad news. We recently published some guidance for how to collect and analyze forensic data in Google Kubernetes Engine (GKE), and how best to investigate and respond to an incident.When performing forensics on your workload, you need to perform a structured investigation, and keep a documented chain of evidence to know exactly what happened in your environment, and who was responsible for it. In that respect, performing forensics and mounting an incident response is the same for containers as it is for other environments—have an incident response plan, collect data ahead of time, and know when to call in the experts. What’s different with containers is (1) what data you can collect and how, and (2) how to react.Get planningEven before an incident occurs, make the time to put together an incident response plan. This typically includes: who to contact, what actions to take, how to start collecting information and how to communicate what’s going on, both internally and externally. Incident response plans are critical, so if panic does start to set in you’ll know what steps to follow.Other information that’s helpful to decide ahead of time, and list in your response plan, is external contacts or resources, and how your response changes based on severity of the incident. Severity levels and planned actions should be business-specific and dependent on your risks—for example, a data leak is likely more severe than an abuse of resources, and you may have different parties that need to be involved. This way, you’re not hunting around for—or debating—this information during an incident. If you don’t get the severity levels right the first time, in terms of categorization, speed of response, speed of communications, or something else, surface this in an incident post-mortem, and adjust as needed.Collect logs now, you’ll be thankful laterTo put yourself in the best possible position for responding to an incident, you want data! Artifacts such as logs, disks, and live recorded info are how you’re going to figure out what’s happening in your environment. Most of these you can get in the heat of the moment, but you need to set up logs ahead of time.There are several kinds of logs in a containerized environment that you can set up to capture: Cloud Audit Logs for GKE and Compute Engine nodes, including Kubernetes audit logs; OS specific logs; and your own application logs.There are several kinds of logs you can collect from a containerized environment.You should begin by collecting logs as soon as you deploy an app or set up a GCP project, to ensure they’re available if you need them for analysis in case of an incident. For more guidance on which logs to collect for further analysis for your containers, see our new solution Security controls and forensic analysis for GKE apps.Stay coolWhat should you do if you suspect an incident in your environment? Don’t panic! You may be tempted to terminate your pods, or restart the nodes, but try to resist the urge. Sure, that will stop the problem at hand, but it also alerts a potential attacker that you know that they’re there, depriving you of the ability to do forensics!So, what should you do? Put your incident response plan into action. Of course, what this means depends on the severity of the incident, and your certainty that you have correctly identified the issue. Your first step might be to ask your security team to further investigate the incident. The next step might be to snapshot the disk of the node that was running the container. You might then move other workloads off and quarantine the node to run additional analysis. For more ideas, check out the new documentation on mitigation options for container incidents next time you’re in such a situation (hopefully never!).To learn more about container forensics and incident response, check out our talk from KubeCon EU 2019, Container forensics: what to do when your cluster is a cluster (slides). But as always, the most important thing you can do is prevention and preparation—be sure to follow the GKE hardening guide, and set up those logs for later!
Quelle: Google Cloud Platform
Published by