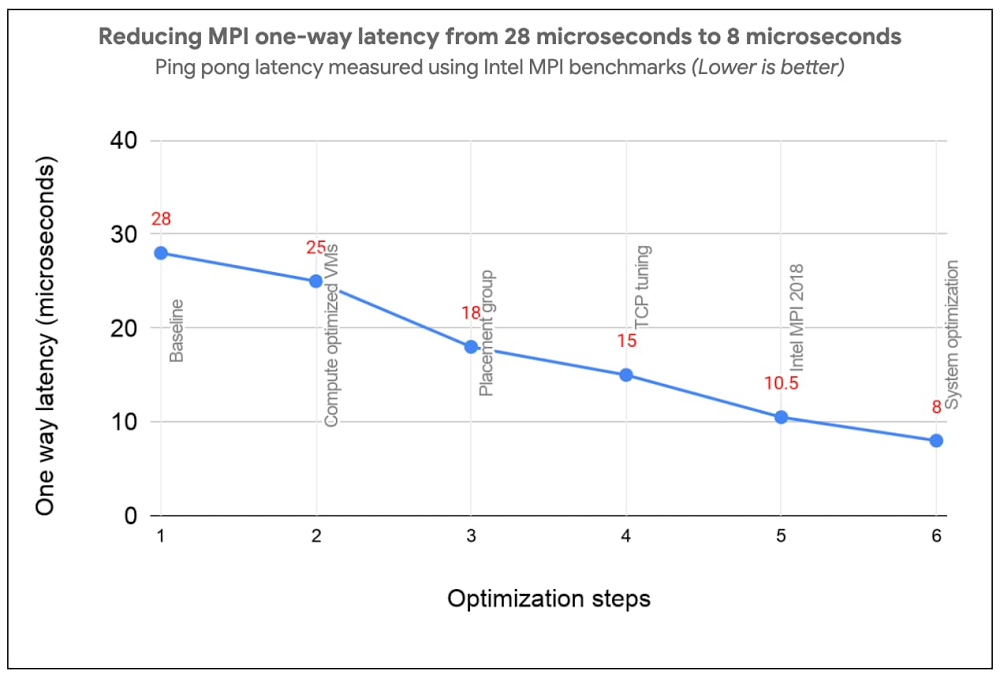
Most High Performance Computing (HPC) applications such as large-scale engineering simulations, molecular dynamics, and genomics, run on supercomputers or HPC clusters on-premises. Cloud is emerging as a great option for these workloads due to its elasticity, pay per use, and the lower associated maintenance cost.Reducing Message Passing Interface (MPI) latency is one critical element of delivering HPC application performance and scalability. We recently introduced several features and tunings that make it easy to run MPI workloads and achieve optimal performance on Google Cloud. These best practices reduce MPI latency, especially for applications that depend on small messages and collective operations. These best practices help optimize Google Cloud systems and networking infrastructure to improve MPI communication over TCP without requiring major software changes or new hardware support. With these best practices, MPI ping-pong latency falls into single-digits of microseconds (μs), and small MPI messages are delivered in 10μs or less. In the figure below, we show how progressive optimizations lowered one-way latency from 28 to 8μs with a test setup on Google Cloud.Improved MPI performance translates directly to improved application scaling, expanding the set of workloads that run efficiently on Google Cloud. If you plan to run MPI workloads on Google Cloud, use these practices to get the best possible performance. Soon, you will be able to use the upcoming HPC VM Image to easily apply these best practices and get the best out-of-the-box performance for your MPI workloads on Google Cloud.1. Use Compute-optimized VMsCompute-optimized (C2) instances have a fixed virtual-to-physical core mapping and expose NUMA architecture to the guest OS. These features are critical for performance of MPI workloads. They also leverage second Generation Intel Xeon Scalable Processors (Cascade Lake), which can provide up to a 40% improvement in performance compared to previous generation instance types due to their support for a higher clock speed of 3.8 GHz, and higher memory bandwidth. C2 VMs also support vector instructions (AVX2, AVX512). We have noticed significant performance improvement for many HPC applications when they are compiled with AVX instructions. 2. Use compact placement policy A placement policy gives you more control over the placement of your virtual machines within a data center. A compact placement policy ensures instances are hosted in nodes nearby on the network, providing lower latency topologies for virtual machines within a single availability zone. Placement policy APIs currently allow creation of up to 22 C2 VMs.3. Use Intel MPI and collective communication tuningsFor the best MPI application performance on Google Cloud, we recommend the use of Intel MPI 2018. The choice of MPI collective algorithms can have a significant impact on MPI application performance and Intel MPI allows you to manually specify the algorithms and configuration parameters for collective communication. This tuning is done using mpitune and needs to be done for each combination of the number of VMs and the number of processes per VM on C2-Standard-60 VMs with compact placement policies. Since this takes a considerable amount of time, we provide the recommended Intel MPI collective algorithms to use in the most common MPI job configurations.For better performance of scientific computations, we also recommend use of Intel Math Kernel Library (MKL).4. Adjust Linux TCP settingsMPI networking performance is critical for tightly coupled applications in which MPI processes on different nodes communicate frequently or with large data volume. You can tune these network settings for optimal MPI performance.Increase tcp_mem settings for better network performanceUse network-latency profile on CentOS to enable busy polling5. System optimizationsDisable Hyper-ThreadingFor compute-bound jobs in which both virtual cores are compute bound, Intel Hyper-Threading can hinder overall application performance and can add nondeterministic variance to jobs. Turning off Hyper-Threading allows more predictable performance and can decrease job times. Review security settingsYou can further improve MPI performance by disabling some built-in Linux security features. If you are confident that your systems are well protected, you can evaluate disabling the following security features as described in Security settings section of the best practices guide:Disable Linux firewallsDisable SELinuxTurn off Spectre and Meltdown MitigationNow let’s measure the impact In this section we demonstrate the impact of applying these best practices through application-level benchmarks by comparing the runtime with select customers’ on-prem setups: (i) National Oceanic and Atmospheric Administration (NOAA) FV3GFS benchmarksWe measured the impact of the best practices by running the NOAA FV3GFS benchmarks with the C768 model and 104 C2-Standard-60 Instances (3,120 physical cores). The expected runtime target, based on on-premise supercomputers, was 600 seconds. Applying these best practices provided a 57% improvement compared to baseline measurements—we were able to run the benchmark in 569 seconds on Google Cloud (faster than the on-prem supercomputer).(ii) ANSYS LS-DYNA engineering simulation softwareWe ran the LS-DYNA 3 cars benchmark using C2-Standard-60 instances, AVX512 instructions and a compact placement policy. We measured scaling from 30 to 120 MPI ranks (1-4 VMs) . By implementing these best practices, we achieved on-par or better runtime performance on Google Cloud in many cases when compared with the customer’s on-prem setup with specialized hardware.There is more: easy and efficient application of best practices To simplify deployment of these best practices, we created an HPC VM Image based on CentOS 7 and that makes it easy to apply these best practices and get the best out-of-the-box performance for your MPI workloads on Google Cloud. You can also apply the tunings to your own image, using the bash and Ansible scripts published in the Google HPC-Tools Github repository or by following the best practice guide.To request access to HPC VM Image, please sign up via this form. We recommend benchmarking your applications to find the most efficient or cost-effective configuration.Applying these best practices can improve application performance and reduce cost. To further reduce and manage costs, we also offer automatic sustained use discounts, transparent pricing with per-second billing, and preemptible VMs that are discounted up to 80% versus regular instance types.Visit our website to get started with HPC on Google Cloud today.
Quelle: Google Cloud Platform
Published by