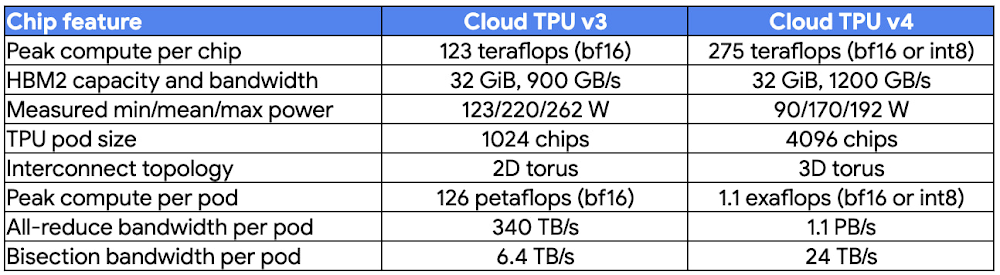
At Google, the state-of-the-art capabilities you see in our products such as Search and YouTube are made possible by Tensor Processing Units (TPUs), our custom machine learning (ML) accelerators. We offer these accelerators to Google Cloud customers as Cloud TPUs. Customer demand for ML capacity, performance, and scale continues to increase at an unprecedented rate. To support the next generation of fundamental advances in artificial intelligence (AI), today we announced Google Cloud’s machine learning cluster with Cloud TPU v4 Pods in Preview — one of the fastest, most efficient, and most sustainable ML infrastructure hubs in the world.Powered by Cloud TPU v4 Pods, Google Cloud’s ML cluster enables researchers and developers to make breakthroughs at the forefront of AI, allowing them to train increasingly sophisticated models to power workloads such as large-scale natural language processing (NLP), recommendation systems, and computer vision algorithms. At 9 exaflops of peak aggregate performance, we believe our cluster of Cloud TPU v4 Pods is the world’s largest publicly available ML hub in terms of cumulative computing power, while operating at 90% carbon-free energy. “Based on our recent survey of 2000 IT decision makers, we found that inadequate infrastructure capabilities are often the underlying cause of AI projects failing. To address the growing importance for purpose-built AI infrastructure for enterprises, Google launched its new machine learning cluster in Oklahoma with nine exaflops of aggregated compute. We believe that this is the largest publicly available ML hub with 90% of the operation reported to be powered by carbon free energy. This demonstrates Google’s ongoing commitment to innovating in AI infrastructure with sustainability in mind.” —Matt Eastwood, Senior Vice President, Research, IDCPushing the boundaries of what’s possibleBuilding on the announcement of Cloud TPU v4 at Google I/O 2021, we granted early access to Cloud TPU v4 Pods to several top AI research teams, including Cohere, LG AI Research, Meta AI, and Salesforce Research. Researchers liked the performance and scalability that TPU v4 provides with its fast interconnect and optimized software stack, the ability to set up their own interactive development environment with our new TPU VM architecture, and the flexibility to use their preferred frameworks, including JAX, PyTorch, or TensorFlow. These characteristics allow researchers to push the boundaries of AI, training large-scale, state-of-the-art ML models with high price-performance and carbon efficiency.co-here.jpglg ai research.jpgmeta.jpgsalesforce.jpgIn addition, TPU v4 has enabled breakthroughs at Google Research in the areas of language understanding, computer vision, speech recognition, and much more, including the recently announced Pathways Language Model (PaLM) trained across two TPU v4 Pods.“In order to make advanced AI hardware more accessible, a few years ago we launched theTPU Research Cloud (TRC) program that has provided access at no charge to TPUs to thousands of ML enthusiasts around the world. They have published hundreds of papers and open-source github libraries on topics ranging from ‘Writing Persian poetry with AI’ to ‘Discriminating between sleep and exercise-induced fatigue using computer vision and behavioral genetics’. The Cloud TPU v4 launch is a major milestone for both Google Research and our TRC program, and we are very excited about our long-term collaboration with ML developers around the world to use AI for good.”—Jeff Dean, SVP, Google Research and AISustainable ML breakthroughsThe fact that this research is powered predominantly by carbon-free energy makes the Google Cloud ML cluster all the more remarkable. As part of Google’s commitment to sustainability, we’ve been matching 100% of our data centers’ and cloud regions’ annual energy consumption with renewable energy purchases since 2017. By 2030, our goal is to run our entire business on carbon-free energy (CFE) every hour of every day. Google’s Oklahoma data center, where the ML cluster is located, is well on its way to achieving this goal, operating at 90% carbon-free energy on an hourly basis within the same grid. In addition to the direct clean energy supply, the data center has a Power Usage Efficiency (PUE)1 rating of 1.10, making it one of the most energy-efficient data centers in the world. Finally, the TPU v4 chip itself is highly energy efficient, with about 3x the peak FLOPs per watt of max power of TPU v3. With energy-efficient ML-specific hardware, in a highly efficient data center, supplied by exceptionally clean power, Cloud TPU v4 provides three key best practices that can help significantly reduce energy use and carbon emissions.Breathtaking scale and price-performanceIn addition to sustainability, in our work with leading ML teams we have observed two other pain points: scale and price-performance. Our ML cluster in Oklahoma offers the capacity that researchers need to train their models, at compelling price-performance, on the cleanest cloud in the industry. Cloud TPU v4 is central to solving these challenges. Scale: Each Cloud TPU v4 Pod consists of 4096 chips connected together via an ultra-fast interconnect network with the equivalent of an industry-leading 6 terabits per second (Tbps) of bandwidth per host, enabling rapid training for the largest models.Price-performance: Each Cloud TPU v4 chip has ~2.2x more peak FLOPs than Cloud TPU v3, for ~1.4x more peak FLOPs per dollar. Cloud TPU v4 also achieves exceptionally high utilization of these FLOPs for training ML models at scale up through thousands of chips. While many quote peak FLOPs as the basis for comparing systems, it is actually sustained FLOPs at scale that determines model training efficiency, and Cloud TPU v4’s high FLOPs utilization (significantly better than other systems due to high network bandwidth and compiler optimizations) helps yield shorter training time and better cost efficiency.Table 1: Cloud TPU v4 pods deliver state-of-the-art performance through significant advancements in FLOPs, interconnect, and energy efficiency.Cloud TPU v4 Pod slices are available in configurations ranging from four chips (one TPU VM) to thousands of chips. While slices of previous-generation TPUs smaller than a full Pod lacked torus links (“wraparound connections”), all Cloud TPU v4 Pod slices of at least 64 chips have torus links on all three dimensions, providing higher bandwidth for collective communication operations.Cloud TPU v4 also enables accessing a full 32 GiB of memory from a single device, up from 16 GiB in TPU v3, and offers two times faster embedding acceleration, helping to improve performance for training large-scale recommendation models. PricingAccess to Cloud TPU v4 Pods comes in evaluation (on-demand), preemptible, and committed use discount (CUD) options. Please refer to this page for more details.Get started todayWe are excited to offer the state-of-the-art ML infrastructure that powers Google services to all of our users, and look forward to seeing how the community leverages Cloud TPU v4’s combination of industry-leading scale, performance, sustainability, and cost efficiency to deliver the next wave of ML-powered breakthroughs. Ready to start using Cloud TPU v4 Pods for your AI workloads? Reach out to your Google Cloud account manager or fill in this form. Interested in access to Cloud TPU for open-source ML research? Check out our TPU Research Cloud program.AcknowledgementsThe authors would like to thank the Cloud TPU engineering and product teams for making this launch possible. We also want to thank James Bradbury, Software Engineer, Vaibhav Singh, Outbound Product Manager and Aarush Selvan, Product Manager, for their contributions to this blog post.1. We report a comprehensive trailing twelve-month (TTM) PUE in all seasons, including all sources of overhead.Related ArticleCloud TPU VMs are generally availableCloud TPU VMs with Ranking & Recommendation acceleration are generally available on Google Cloud. Customers will have direct access to TP…Read Article
Quelle: Google Cloud Platform
Published by