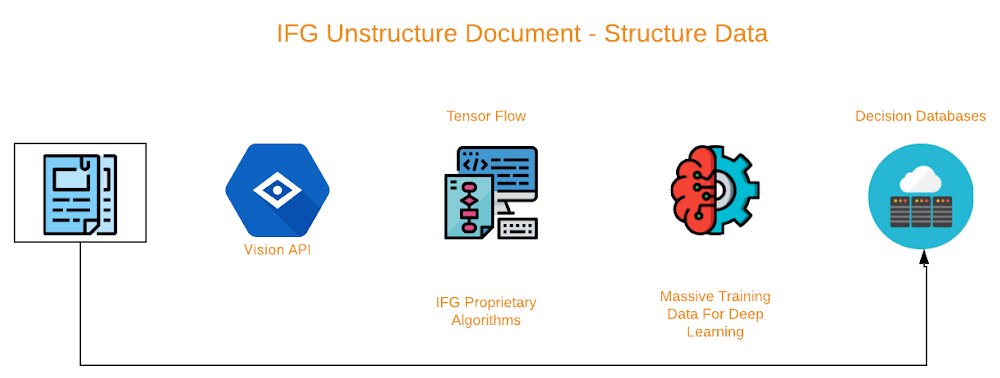
In the world of banking, commercial lenders often struggle to integrate the accounting systems of financial institutions with those of their clients. This integration allows financial service providers to instantly capture information regarding banking activity, balance sheets, income statements, accounts receivable, and accounts payable reports. Based on these, financial institutions can perform instant analysis, using decision engines to provide qualitative and quantitative provisions for credit limits and approval.Today’s commercial and consumer-lending solutions depend on third-party data in order to offer funding opportunities to businesses. These new integrations can facilitate tasks like originations, on-boarding, underwriting, structuring, servicing, collection, and compliance.However, borrowers are reluctant to grant third parties access to internal data, which creates a barrier for adoption. Hence, clients must often submit unstructured financial documents such as bank statements and audited or interim financial statements via drag-and-drop interfaces on a client portal. Many lenders use OCR or virtual printer technology in the background to extract data, but the results are still far from consistent. These processes still require manual intervention to achieve acceptable accuracy, which may cause additional inconsistency and provide an unsatisfactory outcome.To address these challenges, the data science team at Interface Financial Group (IFG) turned to Google Cloud. IFG partnered with Google Cloud to develop a better solution, using Document Understanding AI, which has become an increasingly invaluable tool to process unstructured invoices. It lets the data science team at IFG build classification tools that capture layout and textual properties for each field of significance, and identify specific fields on an invoice. With Google’s tools they can tune feature selection, threshold tuning, and model comparison, yielding 99% accuracy in early trials.Extracting invoices will benefit the fast growing e-invoicing industry and financiers such as trade finance, asset based lending and supply chain finance platforms, connecting buyers and suppliers in a synchronized ecosystem. This environment creates transparency, which is essential for regulators and tax authorities. Ecosystems would benefit from suppliers who submit financial documents in various formats via supplier’s portals—once the documents are converted and analyzed, the structured output can contribute to the organization’s data feed almost instantly. This blog post explains the high level approach for the document understanding project, and you can find more details in the whitepaper.What the project set out to achieveIFG’s invoice recognition project aims to build a tool that extracts all useful information from invoice scans regardless of their format. Most commercially available invoice recognition tools rely on invoices that have been directly rendered to PDF by software and that match one of a set of predefined templates. In contrast, the IFG project starts with images of invoices that could originate from scans or photographs of paper invoices or be directly generated from software. The machine learning models built into IFG’s invoice recognition system recognize, identify, and extract 26 fields of interest.How IFG built its invoice classification solutionThe first step in any invoice recognition project is to collect or acquire images. Many companies consider their supply chains—their suppliers’ resulting invoices—to be confidential. And others simply do not see a benefit to maintaining scans of their invoices, IFG found it challenging to locate a large publicly available repository of invoice images. However, they were able to identify a robust, public dataset of line-item data from invoices. With this data, they were able to synthetically generate a set of 25,011 invoices with different styles, formats, logos, and address formats. From there, they used 20% of the invoices to train its models and then validate the models on the remaining 80%.The synthetic dataset only covers a subset of the standard invoices that businesses use today, but because the core of the IFG system uses machine learning instead of templates, it was able to classify new types invoices, regardless of format. IFG restricted the numbers in its sample set to U.S. standards for grouping, and restricted the addresses in its dataset to portions of the U.S.The invoice recognition process IFG built consists of several distinct steps and relies on several third-party tools. The first step in processing an invoice is to translate the image into text using optical character recognition (OCR). IFG chose Cloud Document Understanding AI for this step. The APIs output text grouped into phrases and their bounding boxes as well as individual words and numbers and their bounding box.IFG’s collaboration with the Google machine learning APIs team helped contribute to a few essential features in Document Understanding AI, most of which involve processing tabular data. IFG’s invoice database thus became a source of data for the API, and should assist other customers in achieving reliable classification results as well. The ability to identify tables has the potential to solve a variety of issues identifying data in the details table included in most invoices.After preprocessing, the data is fed into several different neural networks that were designed and trained using TensorFlow—and IFG also used other, more traditional models in its pipeline using scikit-learn. The machine learning systems used are sequence to sequence, naive Bayes, and a decision tree algorithms. Each system has its own strengths and weaknesses, and each system is used to extract different subsets of the data IFG was interested in. Using this ensemble model allowed them to achieve higher accuracy than any individual model.Next, sequence to sequence (Seq2Seq) models use a recurrent neural network to map input sequences to output sequences of possibly different lengths. IFG implemented a character-level sequence to sequence model for invoice ID parsing, electing to parse the document at the character level because invoice numbers can be numeric, alphanumeric, or even include punctuation.IFG found that Seq2Seq performs very well at identifying invoice numbers. Because invoice numbers can consist of virtually arbitrary sequences of characters, IFG abandoned the tokenized input and focused on the text as a character string. When applied to the character stream, the Seq2Seq model matched invoice numbers with approximately 99% accuracy.Because the Seq2Seq model was unable to distinguish street abbreviations from state abbreviations, IFG added a naive Bayes model to its pipeline. This hybrid model is now able to distinguish state abbreviations from street abbreviations with approximately 97% accuracy.IFG used naive Bayes integrates n-grams to reconstruct the document and place the appropriate features in their appropriate fields at the end of the process. Even though an address is identified, it must be associated with either the payor or payee in the case of invoice recognition. What precedes the actual address is of utmost importance in this instance.Neither Seq2Seq nor naive Bayes models were able to use the bounding box information to distinguish nearly identical fields such as payor address and payee address, so IFG added a decision tree model to its pipeline in order to distinguish these two address types.Lastly, IFG used a Pandas data frame to compare the output to the test data, using cross-entropy as a loss function for both accuracy and validity. Accuracy was correlated to the number of epochs used in training. An optimum number of epochs was discovered during testing to reach 99% accuracy or higher element recognition in most invoices.ConclusionDocument Understanding AI performs exceptionally well when capturing raw data from an image. The collaboration between IFG and Google Cloud allowed the team to focus on training a high-accuracy machine learning model that processes a variety of business documents. Additionally, the team leaned on several industry-standard NLP libraries to help parse and clean the output of the APIs for use in the trained models. In the process, IFG found the sequence to sequence techniques provided it with enough flexibility to solve the document classification problem for a number of different markets. The full technical details are available in this whitepaper.Going forward, IFG plans to take advantage of the growing number of capabilities in Document Understanding AI—as well as its growing training set—to properly process tabular data. Once all necessary fields are recognized and captured to an acceptable level of accuracy, IFG will extend the invoice recognition project to other types of financial documents. IFG ultimately expects to be able to process any sort of structured or unstructured financial document from an image into a data feed with enough accuracy to eliminate the need for consistent human intervention in the process. You can find more details about Document Understanding AI here.AcknowledgementsRoss Biro, Chief Technology Officer; Michael Cave, Senior Data Scientist, The Interface Financial Group drove implementation for IFG. Shengyang Dai, Engineering Manager, Vision API, Google Cloud, provided guidance throughout the project.
Quelle: Google Cloud Platform
Published by