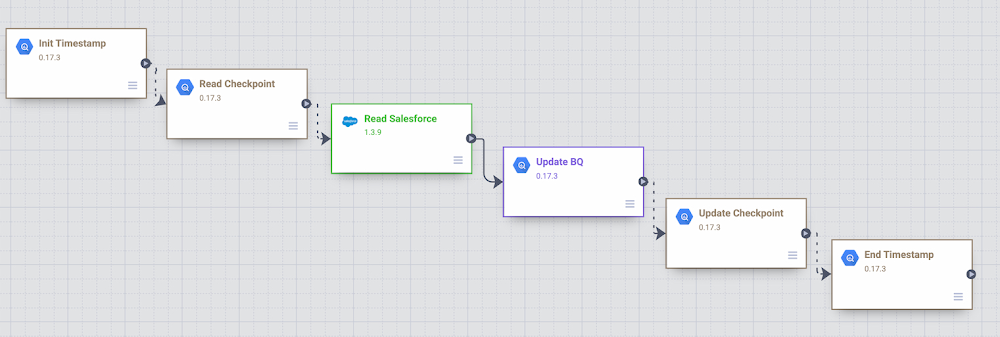
Organizations are increasingly investing in modern cloud warehouses and data lake solutions to augment analytics environments and improve business decisions. The business value of such repositories increases as customer relationship data is loaded and additional insights are generated.In this post, we’ll cover different ways to incrementally move Salesforce data into BigQuery using the scalability and reliability of Google services, an intuitive drag-and-drop solution based on pre-built connectors, and the self-service model of a code-free data integration service. A Common Data Ingestion Pattern:To provide a little bit more context, here is an illustrative (and common) use case:Account, Lead and Contact Salesforce objects are frequently manipulated by call center agents when using the SalesForce application.Changes to these objects need to be identified and incrementally loaded into a data warehouse solution using either a batch or streaming approach.A fully managed and cloud-native enterprise data integration service is preferred for quickly building and managing code-free data pipelines. Business performance dashboards are created by joining Salesforce and other related data available in the data warehouse.Cloud Data Fusion to the rescue To address the Salesforce ETL (extract, transform and load) scenario above, we will be demonstrating the usage of Cloud Data Fusion as the data integration tool. Data Fusion is a fully managed, cloud-native, enterprise data integration service for quickly building and managing code-free data pipelines. Data Fusion’s web UI allows organizations to build scalable data integration solutions to clean, prepare, blend, transfer, and transform data without having to manage the underlying infrastructure. Its integration with Google Cloud ensures data is immediately available for analysis. Data Fusion offers numerous pre-built plugins for both batch and real-time processing. These customizable modules can be used to extend Data Fusion’s native capabilities and are easily installed though the Data Fusion Hub component.For Salesforce source objects, the following pre-built plugins are generally available:Batch Single Source – Reads one sObject from Salesforce. The data can be read using SOQL queries (Salesforce Object Query Language queries) or using sObject names. You can pass incremental/range date filters and also specify primary key chunking parameters. Examples of sObjects are opportunities, contacts, accounts, leads, any custom object, etc. Batch Multi Source – Reads multiple sObjects from Salesforce. It should be used in conjunction with multi-sinks.Streaming Source – Tracks updates in Salesforce sObjects. Examples of sObjects are opportunities, contacts, accounts, leads, any custom object, etc.If none of these pre-built plugins fit your needs, you can always build your own by using Cloud Data Fusion’s plugin APIs. For this blog, we will leverage the out of the box Data Fusion plugins to demonstrate both batch and streaming Salesforce pipeline options.Batch incremental pipelineThere are many different ways to implement a batch incremental logic. The Salesforce batch multi source plugin has parameters such as “Last Modified After”, “Last Modified Before”, “Duration” and “Offset” which can be used to control the incremental loads.Here’s a look at a sample Data Fusion batch incremental pipeline for Salesforce objects Lead, Contact and Account. The pipeline uses the previous’ start/end time as the guide for incremental loads.Batch Incremental Pipeline – From Salesforce to BigQueryThe main steps of this sample pipeline are:For this custom pipeline, we decided to store start/end time in BigQuery and demonstrate different BigQuery plugins. When the pipeline starts, timestamps are stored on a user checkpoint table in BigQuery. This information is used to guide the subsequent runs and incremental logic.Using the BigQuery Argument Setter plugin, the pipeline reads from the BigQuery checkpoint table, fetching the minimum timestamp to read from.With the Batch Multi Source plugin, the objects lead, contact and account are read from Salesforce, using the minimum timestamp as a parameter passed to the plugin.BigQuery tables lead, contact and account are updated using the BigQuery Multi Table sink pluginThe checkpoint table is updated with the execution end time followed by an update to current_time column.Adventurous?You can exercise this sample Data Fusion pipeline in your development environment by downloading its definition file from GitHub and importing it through the Cloud Data Fusion Studio. After completing the import, adjust the plugin properties to reflect your own Salesforce environment. You will also need to: Create a BigQuery dataset named from_salesforce_cdf_stagingCreate the sf_checkpoint BigQuery table on dataset from_salesforce_cdf_staging as described below:3. Insert the following record into the sf_checkpoint table:Attention: The initial last_completion date = “1900-01-01T23:01:01Z” indicates the first pipeline execution will read all Salesforce records with LastModifedDate column greater than 1900-01-01. This is a sample value targeted for initial loads. Adjust the last_completion column as needed to reflect your environment and requirements for the initial run.After executing this sample pipeline a few times, observe how sf_checkpoint.last_completion column evolves as executions finish. You can also validate that changes are being loaded incrementally into BigQuery tables as shown below:BigQuery output – Salesforce incremental pipelineStreaming pipeline When using the Streaming Source plugin with Data Fusion, changes in Salesforce sObjects are tracked using PushTopic events. The Data Fusion streaming source plugin can either create a Salesforce PushTopic for you, or use an existing one you defined previously using Salesforce tools. The PushTopic configuration defines the type of events (insert, update, delete) to trigger notifications, and the objects columns in scope. To learn more about Salesforce PushTopics, click here. When streaming data, there is no need to create a checkpoint table in BigQuery as data gets replicated near real time, automatically capturing only changes, as soon as they occur. The Data Fusion pipeline becomes super simple as demonstrated in the sample below:Salesforce streaming pipeline with Cloud Data FusionThe main steps of this sample pipeline are:1. Add a Salesforce streaming source and provide its configuration details. For this exercise, only inserts and updates are being captured from CDFLeadUpdates PushTopic. As a reference, here is the code we used to pre-create the CDFLeadUpdates PushTopic in Salesforce. The Data Fusion plugin can also pre-create the PushTopic for you if preferred.Hint: In order to run this code block, login to Salesforce with the appropriate credentials and privileges, open the Developer Console and click on Debug | Open Execute Anonymous Window.2. Add a BigQuery sink to your pipeline in order to receive the streaming events. Notice the BigQuery table gets created automatically once the pipeline executes and the first change record is generated.After starting the pipeline, make some modifications to the Lead object in Salesforce and observe the changes flowing into BigQuery as exemplified below:BigQuery output – Salesforce streaming pipeline with Cloud Data FusionAdventurous?You can exercise this sample Data Fusion pipeline in your development environment by downloading its definition file from GitHub and importing it through the Cloud Data Fusion Studio. After completing the import, adjust the plugin properties to reflect your own Salesforce environment.Got deletes? If your Salesforce implementation allows “hard deletes” and you must capture them, here is a non-exhaustive list of ideas to consider:An audit table to track the deletes. A database trigger, for example, can be used to populate a custom audit table. You can then use Data Fusion to load the delete records from the audit table and compare/update the final destination table in BigQuery.An additional Data Fusion job that reads the primary keys from the source and compare/merge with the data in BigQuery.A Salesforce PushTopic configured to capture delete/undelete events and a Data Fusion Streaming Source added to capture from the PushTopic.Salesforce Change Data Capture.Conclusion:If your enterprise is using Salesforce and If it’s your job to replicate data into a data warehouse then Cloud Data Fusion has what you need. And if you already use Google Cloud tools for curating a data lake with Cloud Storage, Dataproc, BigQuery and many others, then Data Fusion integrations make development and iteration fast and easy. Have a similar challenge? Try Google Cloud and this Cloud Data Fusion quickstart next. For a more in-depth look into Data Fusion check out the documentation.Have fun exploring!
Quelle: Google Cloud Platform
Published by