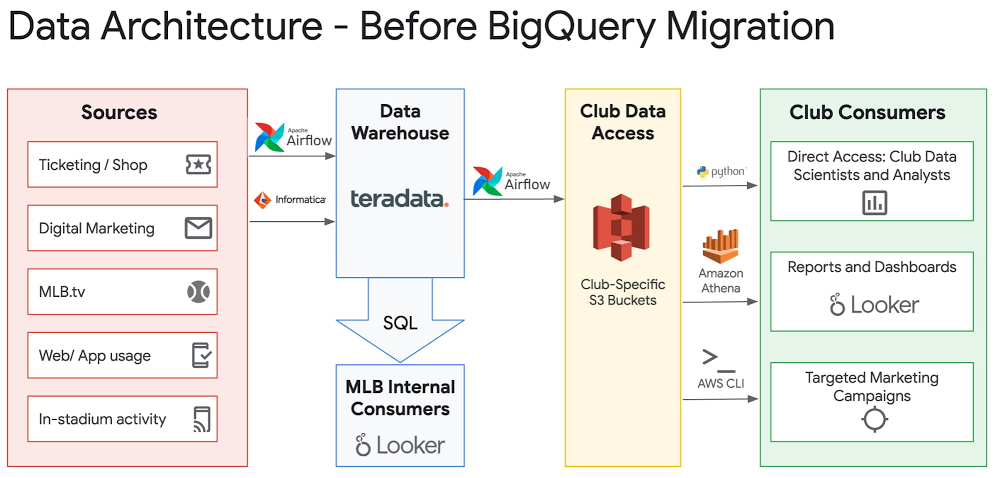
Editor’s note: In this blog post, VP of Data Engineering at MLB Robert Goretsky provides a deeper dive on MLB’s data warehouse modernization journey. Check out the full Next OnAir session: MLB’s Data Warehouse Modernization.At Major League Baseball (MLB), the data generated by our fans’ digital and in-stadium transactions and interactions allows us to quickly iterate on product features, personalize content and offers, and ensure that fans are connected with our sport. The fan data engineering team at MLB is responsible for managing 350+ data pipelines to ingest data from third-party and internal sources and centralize it in an enterprise data warehouse (EDW). Our EDW is central to driving data-related initiatives across the internal product, marketing, finance, ticketing, shop, analytics, and data science departments, and from all 30 MLB Clubs. Examples of these initiatives include:Personalizing the news articles shown to fans on MLB.com based on their favorite teams.Communicating pertinent information to fans prior to games they’ll be attending. Generating revenue projections and churn rate analyses for our MLB.tv subscribers. Building ML models to predict future fan purchase behavior.Sharing fan transaction and engagement data from central MLB to the 30 MLB Clubs to allow the Clubs to make informed local decisions. After a technical evaluation in 2018, we decided to migrate our EDW from Teradata to Google Cloud’s BigQuery. We successfully completed a proof of concept in early 2019, and ran a project to fully migrate from Teradata to BigQuery from May 2019 through November 2019. (Yes, we completed the migration in seven months!) With the migration complete, MLB has realized numerous benefits in migrating to a modern, cloud-first data warehouse platform. Here’s how we did it.How MLB migrated to BigQueryWe ran several workstreams in parallel to migrate from Teradata to BigQuery:Replication: For each of the ~1,000 regularly updated tables in Teradata, we deployed a data replication job using Apache Airflow to copy data from Teradata to BigQuery. Each job was configured to trigger replication only after the data was populated from the corresponding upstream source into Teradata. This meant that data was always as fresh in BigQuery as it was in Teradata. Having fresh data in BigQuery allowed all downstream consumers of the data (including members of the business intelligence, analytics, data science, and marketing teams) to start building all new processes/analyses/reports on BigQuery early on in the project, before most ETL conversion was completed. ETL conversion: We had over 350 ETL jobs running in Airflow and Informatica, each populating data to Teradata or extracting data from Teradata, each of which needed to be converted to interact with BigQuery. To determine the order in which to convert and migrate these jobs, we built a dependency map to determine which tables and ETL jobs were upstream and downstream from others. Jobs that were less entangled, with fewer downstream dependencies, could be migrated first. A SQL Transpiler tool from CompilerWorks was helpful, as it dealt with the rote translation of SQL from one dialect to another. Data engineers needed to individually examine output from this tool, validate results, and, if necessary, adjust query logic accordingly. To assist with validation, we built a table comparison tool that ran on BigQuery and compared output data from ETL jobs. Report conversion: We use two tools to produce reporting for end users—Business Objects and Looker. For each of the Business Objects reports and Looker Dashboards, our business intelligence team converted SQL logic and reviewed report output to ensure accuracy. This workstream was able to run independently of the ETL translation workstream, since the BI team could rely on the data replicated directly from Teradata into BigQuery.End-user training: Users within the marketing, data science, and analytics teams were onboarded to BigQuery early in the project, leveraging the data being replicated from Teradata. This allowed ample time for teams to learn BigQuery syntax and connect their tools to BigQuery. Security configuration: Leveraging MLB’s existing SSO setup via Okta and G Suite, users were provisioned with access to BigQuery using the same credentials they used for access to their desktop/email. There was no need to set up separate sets of credentials, and users who left the organization were immediately disconnected from data access. The benefits that migration brought MLB Pricing: With BigQuery’s on-demand pricing model, we were able to run side-by-side performance tests with minimal cost and no commitment. These tests involved taking copies of some of our largest and most diverse datasets and running real-world SQL queries to compare execution time. As MLB underwent the migration effort, BigQuery cost increased linearly with the number of workloads migrated. By switching from on-demand to flat-rate pricing using BigQuery Reservations, we are able to fix our costs and avoid surprise overages (there’s always that one user who accidentally runs a ‘SELECT * FROM’ the largest table), and share unused capacity with other departments in our organization, including our data science and analytics teams.Data democratization: Providing direct user access to Teradata was often cumbersome, if not impossible, due to network connectivity restrictions and client software setup issues. By contrast, BigQuery made it trivial to securely share datasets with any G Suite user or group with the click of a button. Users can access BigQuery’s web console to immediately review and run SQL queries on data that is shared with them. They can also use Connected Sheets to analyze large data sets with pivot tables in a familiar interface. In addition, they can import data from files and other databases, and join those private datasets with data shared centrally by the data engineering team.MLB’s central office handles the ingestion and processing of data from a variety of data sources and shares club-specific data with each Club in the initiative known internally as “Wheelhouse.” The previous Wheelhouse data-share infrastructure involved daily data dumps from Teradata to S3, one per Club per dataset, which introduced latency and synchronization issues. The new Wheelhouse infrastructure leverages BigQuery’s authorized views to provide Clubs with real-time access to the specific rows of data relevant to them. For example, MLB receives StubHub sales data for all 30 Clubs, and has set up an authorized view per Club so that each Club can view only the sales for their own team. Due to BigQuery’s serverless infrastructure, there is no concern about one user inadvertently affecting performance for all other users. This simplification in architecture can be seen in the diagrams below:Seeing the IT results from migrating to BigQueryImproved performance: Queries generally complete 50% faster on BigQuery compared with Teradata. In many cases, queries that would simply time out or fail on Teradata (and impact the entire system in the process), or that were not feasible to even consider loading into Teradata, run without issue on BigQuery. This was especially true for our largest data set, which is 150TB+ in size per year and consists of hit-level clickstream data from our websites and apps. This data set previously needed to be stored outside our data warehouse and processed with separate tools from the Hadoop ecosystem, which led to friction for analysts who often wanted to join this data with other transactional data sets.Richer insights via integrations: The BigQuery Data Transfer Service makes it easy to set up integrations with several services MLB currently uses, including Google Ads, Google Campaign Manager, and Firebase. Previously, setting up these kinds of integrations involved hand-coded, time-consuming ETL processes. Looker, our BI tool, seamlessly integrates with BigQuery and provides a clean and highly performing interface for business users to access and drill into data. Third-party vendor support for BigQuery is strong as well. As an example, our marketing analytics team is able to use the data ingested from Google Ads to inform advertising spend and placement decisions. Reduced operational overhead: With Teradata, MLB needed a full-time DBA team on staff to handle 24×7 operational support for database issues, including bad queries, backup issues, space allocation, and user permissioning. With BigQuery, MLB has found no need for this role. Google Cloud’s support covers any major service issues, and former administrative tasks such as restoring a table backup can now be done easily by end users, letting our IT teams focus on more strategic work.Increased developer happiness: Our data engineering, data science, and analytics staff were often frustrated by the lack of documentation and subtle gotchas present within Teradata. Given that Teradata was mainly used within larger enterprise deployments, online documentation on sites such as Stack Overflow was limited. In contrast, BigQuery is well-documented, and given the lack of barriers to entry (any Google Cloud user can try it for free), there already seem to be more resources available online to troubleshoot issues, get answers to questions, and learn about product features.Accelerated time to value: No downtime or upgrade planning is needed to immediately take advantage of new useful features that are added on a regular basis by the BigQuery engineering team.Seeing the business impact from BigQueryWith our migration to BigQuery complete, we’re now able to take a more comprehensive and frictionless approach to leveraging our fan data to serve our fans and the league. A few projects that have already been facilitated by our move to BigQuery are:OneView: This is a new initiative launched by our data platform product team to compile over 30 pertinent data sources into a single table, with one row per fan, to facilitate downstream personalization and segmentation initiatives. Previously, we would have spent a long time developing and troubleshooting an incremental load process to populate this table. Instead, with the power of BigQuery, we’re able to run full rebuilds of this table on a regular basis that complete quickly and do not adversely affect performance of other data workloads. We’re also able to leverage BigQuery’s Array and Struct data types to nest repeated data elements within single columns in this table to allow users to drill into more specific data without needing any lookups or joins. This OneView table is already being used to power news article personalization.Real-time form submission reporting: By using the Google-provided Dataflow template to stream data from Pub/Sub in real time to BigQuery, we are able to create Looker dashboards with real-time reporting on form submissions for initiatives such as our “Opening Day Pick ‘Em” contest. This allows our editorial team to create up-to-the-minute analyses of results.With our modern data warehouse up and running, we’re able to serve data stakeholders better than ever before. We’re excited about the data-driven capabilities we’ve unlocked to continue creating a better online and in-person experience for our fans.
Quelle: Google Cloud Platform
Published by