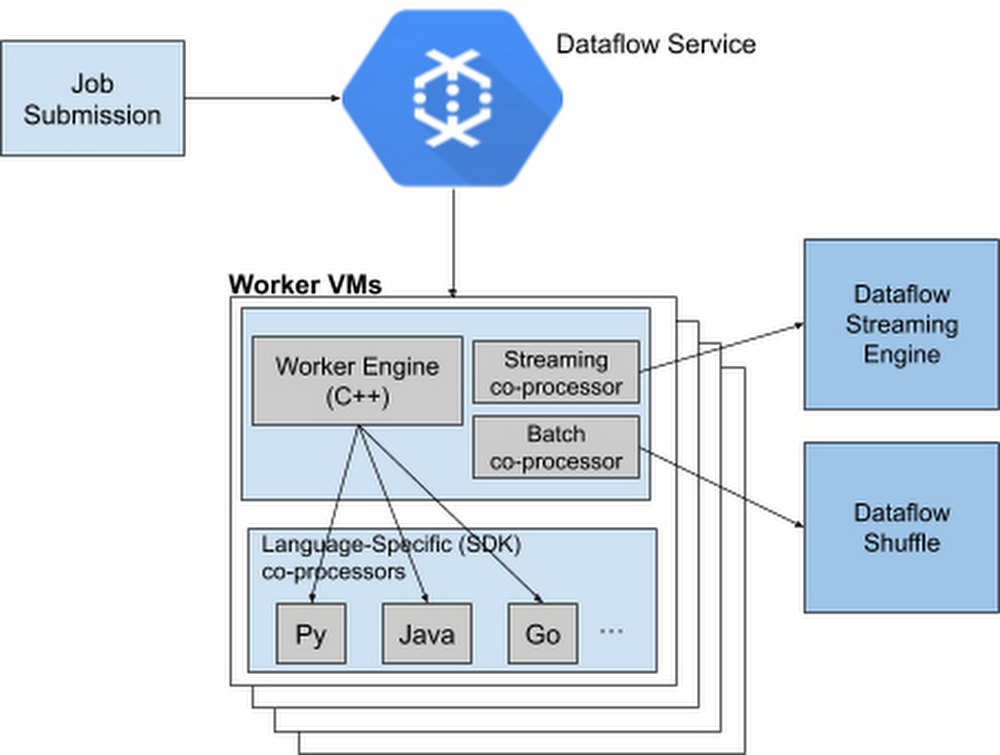
What do you do when your development and data science teams work in different language SDKs or if there are features available in one programming language, but not available in your preferred language? Traditionally, you’d either need to create workarounds that bridge the various languages, or else your team would have to go back and recode. Not only does this cost time and money, it puts real strain on your team’s ability to collaborate. Introducing Dataflow Runner v2To overcome this, Google Cloud has added a new, more services-based architecture called Runner v2 (available to anyone building a pipeline) to Dataflow that includes multi-language support for all of its language SDKs. This addition of what the Apache Beam community calls “multi-language pipelines” lets development teams within your organization share components written in their prefered language and weave them into a single, high-performance, distributed processing pipeline.This architecture solves the current problem where language-specific worker VMs (called Workers) are required to run entire customer pipelines. If features or transforms are missing for a given language, they must be duplicated across various SDKs to ensure parity; otherwise, there will be gaps in feature coverage and newer SDKs like Apache Beam Go SDK will support fewer features and exhibit inferior performance characteristics for some scenarios.Runner v2 includes a more efficient and portable worker architecture rewritten in C++, which is based on Apache Beam’s new portability framework, packaged together with Dataflow Shuffle for batch jobs and Streaming Engine for streaming jobs. This allows us to provide a common feature set going forward across all language-specific SDKs, as well as share bug fixes and performance improvements.Dataflow Runner v2 is available today with Python streaming pipelines. We encourage you to test out Dataflow Runner v2 with your current (non-production) workloads before it is enabled by default on all new pipelines. You do not have to make any changes to your pipeline code to take advantage of this new architecture.Dataflow Runner v2 comes with support for many new features that are not available in the previous Dataflow runner. In addition to support for multi-language pipelines, Dataflow Runner v2 also provides full native support for Apache Beam’s powerful data source framework named Splittable DoFn, and support for using custom containers for Dataflow jobs. Also, Dataflow Runner v2 enables new capabilities for Python streaming pipelines, including Timers, State, and expanded support for Windowing and Triggers. Using Java implementations in PythonApache Beam’s multi-language capabilities are unique among modern-day data processing frameworks, letting Runner v2 make it easy to provide new features simultaneously in multiple Beam SDKs by writing a single language-specific implementation. For example, we have made the Apache Kafka connector and SQL transform from the Apache Beam Java SDK available for use in Python streaming pipelines starting with Apache Beam 2.23. To see it for yourself, check out the Python Kafka connector and the Python SQL transform that utilizes corresponding Java implementations. To use newly supported Python transforms with Dataflow Runner v2, simply install the latest Java Development Kit (JDK) supported by Apache Beam on your computer and use Python transforms in your Dataflow Python streaming pipeline. For example:For more details regarding pipeline setup and usage of the newly supported transforms, see the Apache Beam Python examples for Kafka and SQL transform.How cross-language transforms workUnder the hood, to make Java transforms available to a Dataflow Python pipeline, the Apache Beam Python SDK starts up a local Java service on your computer to create and inject the appropriate Java pipeline fragments into your Python pipeline. The SDK then downloads and stages the necessary Java dependencies needed to execute these transforms.At runtime, the Dataflow Workers will execute the Python and Java code side by side to run your pipeline. And we’re working on making more Java transforms available to Beam Python through the multi-language pipelines framework.Next stepsEnable Runner v2 to realize the benefits of multi-language pipelines and performance improvements in Python pipelinesTry accessing Kafka topics from Dataflow Python pipelines by following this tutorialTry embedding SQL statements in your Dataflow Python pipelines by using this example
Quelle: Google Cloud Platform
Published by