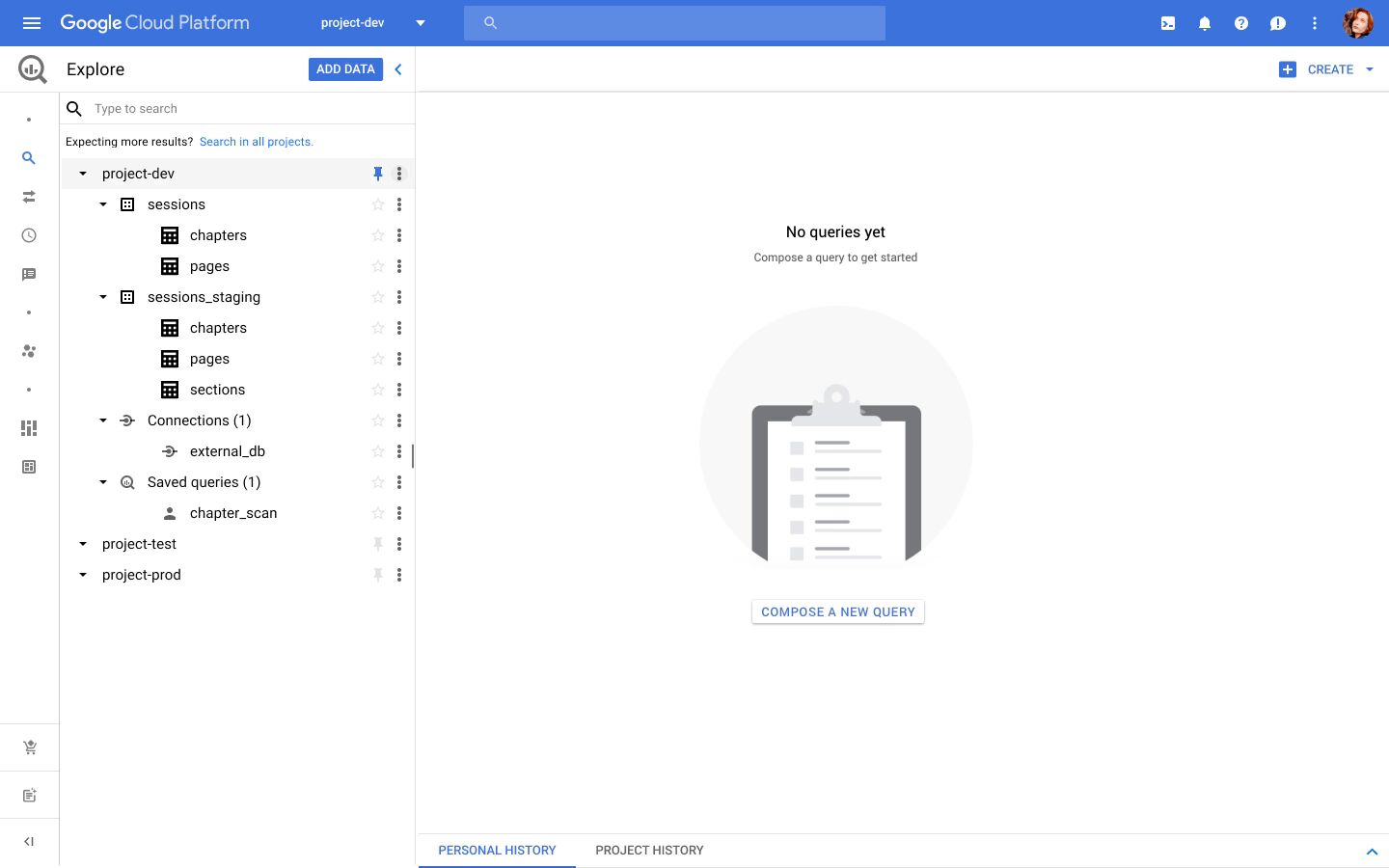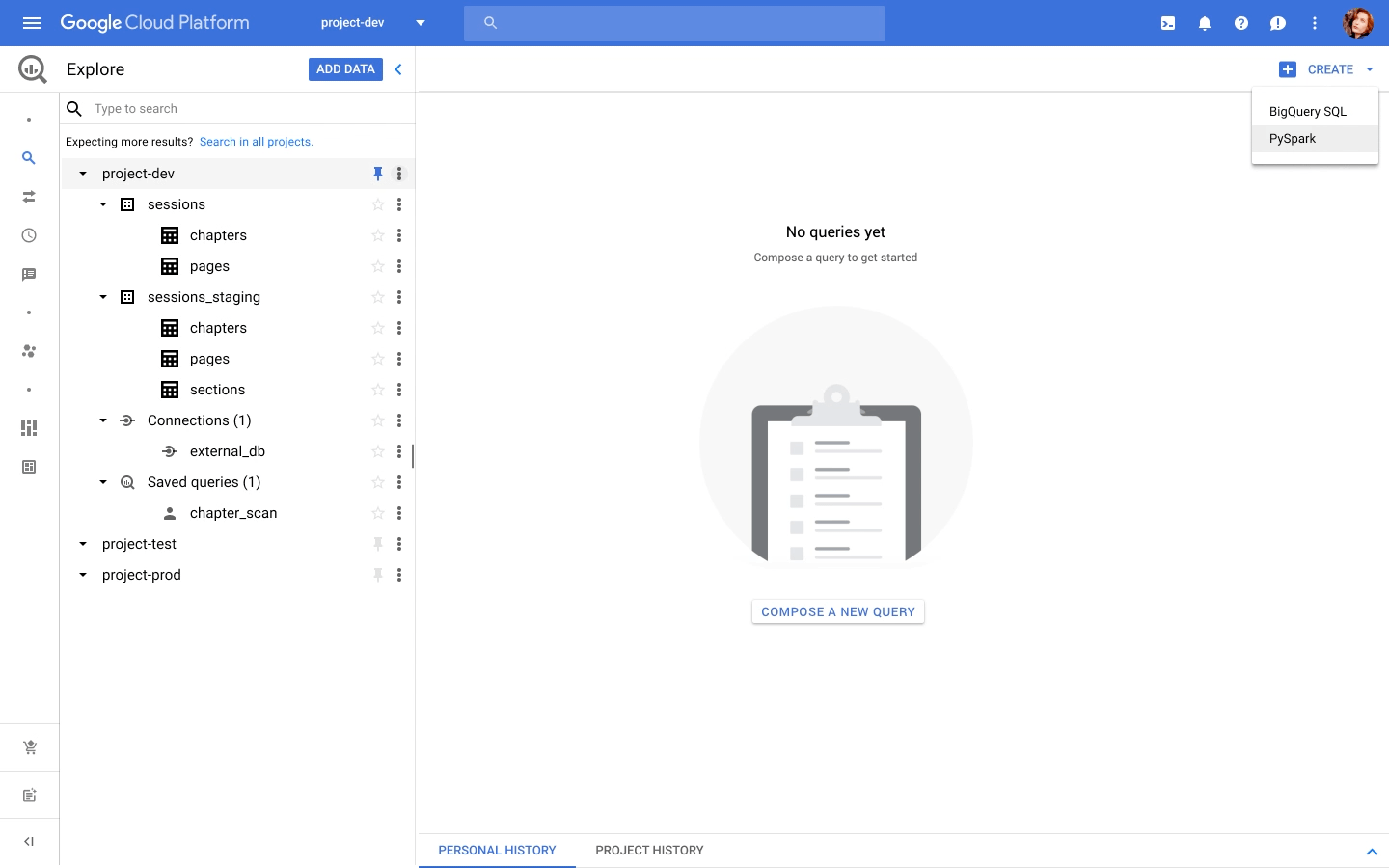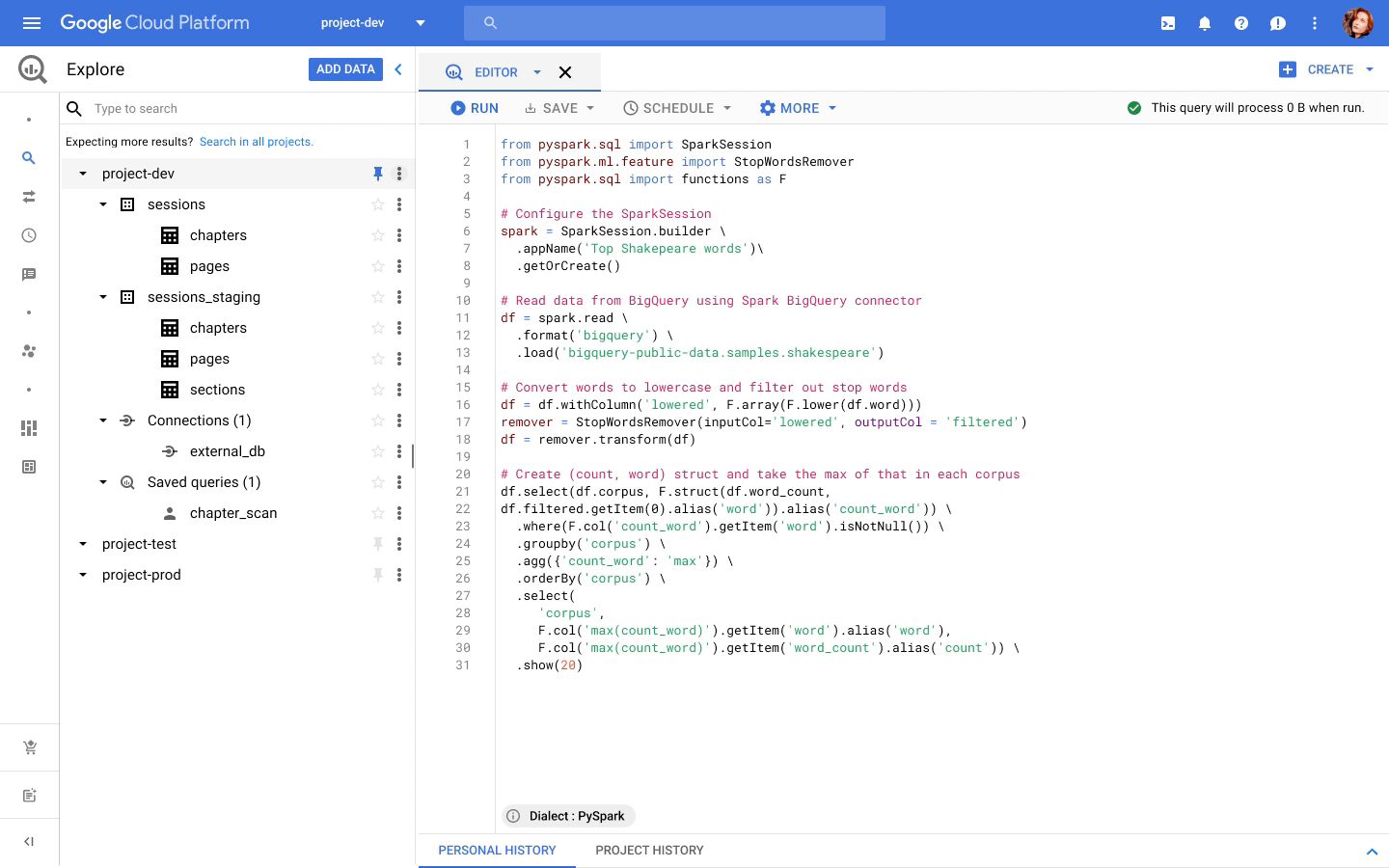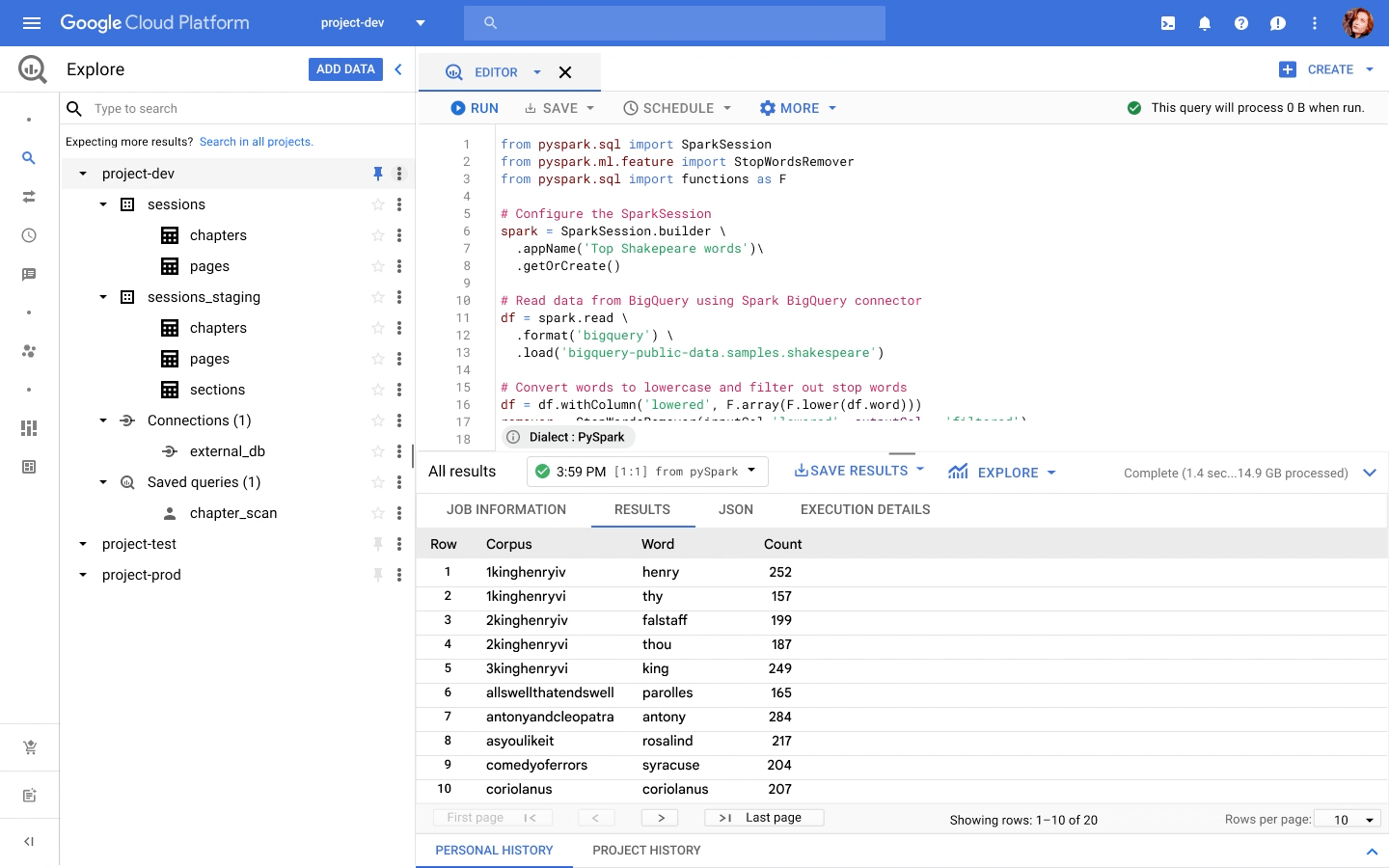
Apache Spark has become a popular platform as it can serve all of data engineering, data exploration, and machine learning use cases. However, Spark still requires the on-premises way of managing clusters and tuning infrastructure for each job. Also, end to end use cases require Spark to be used along with technologies like TensorFlow, and programming languages like SQL and Python. Today, these operate in silos, with Spark on unstructured data lakes, SQL on data warehouses, and TensorFlow in completely separate machine learning platforms. This increases costs, reduces agility, and makes governance extremely hard; prohibiting enterprises from making insights available to the right users at the right time.Announcing Spark on Google Cloud, now serverless and integratedWe are excited to announce Spark on Google Cloud, bringing industry’s first autoscaling serverless Spark, seamlessly integrated with the best of Google Cloud and open source tools, so you can effortlessly power ETL, data science, and data analytics use cases at scale. Google Cloud has been running large scale business critical Spark workloads for enterprise customers for 6+ years, using open source Spark in Dataproc. Today, we are furthering our commitment by enabling customers to:Eliminate time spent managing Spark clusters: With serverless Spark, users submit their Spark jobs, and let them do auto-provision, and autoscale to finish.Enable data users of all levels: Connect, analyze, and execute Spark jobs from the interface of users’ choice including BigQuery, Vertex AI or Dataplex, in 2 clicks, without any custom integrations.Retain flexibility of consumption: No one size fits all. Use Spark as serverless, deploy on Google Kubernetes Engine (GKE), or on compute clusters based on the requirements.With Spark on Google Cloud, we are providing a way for customers to use Spark in a cloud native manner (serverless), and seamlessly with tools used by data engineers, data analysts, and data scientists for their use cases. These tools will help customers on their way to realize the data platform redesign they have embarked on.”Deutsche Bank is using Spark for a variety of different use cases. Migrating to GCP and adopting Serverless Spark for Dataproc allows us to optimize our resource utilization and reduce manual effort so our engineering teams can focus on delivering data products for our business instead of managing infrastructure. At the same time we can retain the existing code base and knowhow of our engineers, thus boosting adoption and making the migration a seamless experience.”—Balaji Maragalla, Director Big Data Platform, Deutsche Bank“We see serverless Spark playing a central role in our data strategy. Serverless Spark will provide an efficient, seamless solution for teams that aren’t familiar with big data technology or don’t need to bother with idiosyncrasies of Spark to solve their own processing needs. We’re excited about the serverless aspect of the offering, as well as the seamless integration with BigQuery, Vertex AI, Dataplex and other data services.” —Saral Jain, Director of Engineering, Infrastructure and Data, Snap Inc.Dataproc Serverless for SparkPer IDC, developers spend 40% time writing code, and 60% of the time tuning infrastructure and managing clusters. Furthermore, not all Spark developers are infrastructure experts, resulting in higher costs and productivity impact. With serverless Spark, developers can spend all their time on the code and logic. They do not need to manage clusters or tune infrastructure. They submit Spark jobs from their interface of choice, and processing is auto-scaled to match the needs of the job. Furthermore, while Spark users today pay for the time the infrastructure is running, with serverless Spark they only pay for the job duration.Spark through BigQueryBigQuery, the leading data warehouse, now provides a unified interface for data analysts to write SQL or PySpark. The code is executed using serverless Spark seamlessly, without the need for infrastructure provisioning. BigQuery has been the pioneer for serverless data warehousing, and now supports serverless Spark for Spark-based analytics.Spark through Vertex AIData scientists no longer need to go through custom integrations to use Spark with their notebooks. Through Vertex AI Workbench, they can connect to Spark with a single click, and do interactive development. With Vertex AI, Spark can easily be used together with other ML frameworks like TensorFlow, Pytorch, Sci-kit learn, and BigQuery ML. All the Google Cloud security, compliance, and IAM are automatically applied across Vertex AI and Spark. Once you are ready to deploy the ML models, the notebook can be executed as a Spark job in Dataproc, and scheduled as part of Vertex AI Pipelines.Spark through DataplexDataplex is an intelligent data fabric that enables organizations to centrally manage, monitor, and govern their data across data lakes, data warehouses, and data marts with consistent controls, providing access to trusted data and powering analytics at scale. Now, you can use Spark on distributed data natively through Dataplex. Dataplex provides a collaborative analytics interface, with 1-click access to SparkSQL, Notebooks, or PySpark, and the ability to save, share, search notebooks and scripts alongside data.Flexibility of consumptionWe understand one size does not fit all. Spark is available for consumption in 3 different ways based on your specific needs. For customers standardizing on Kubernetes for infrastructure management, run Spark on Google Kubernetes Engine (GKE) to improve resource utilization and simplify infrastructure management. For customers looking for Hadoop style infrastructure management, run Spark on Google Compute Engine (GCE). For customers, who’re looking for no-ops Spark deployment, use serverless Spark! ESG Senior Analyst Mike Leone commented, “Google Cloud is making Spark easier to use and more accessible to a wide range of users through a single, integrated platform. The ability to run Spark in a serverless manner, and through BigQuery and Vertex AI will create significant productivity improvement for customers. Further, Google’s focus on security and governance makes this Spark portfolio useful to all enterprises as they continue migrating to the Cloud.”Getting startedDataproc Serverless for Spark will be Generally Available within a few weeks. BigQuery and Dataplex integration is in Private Preview. Vertex AI workbench is available in Public Preview, you can get started here. For all capabilities, you can request for Preview access through this form.You can work with Google Cloud partners to get started as well.“We are excited to partner with Google Cloud as we look to provide our joint customers with the latest innovations on Spark. We see Spark being used for a variety of analytics and ML use cases. Google is taking Spark a step further by making it serverless, and available through BigQuery, Vertex AI and Dataplex for a wide spectrum of users.” —Sharad Kumar, Cloud First data and AI Lead at AccentureFor more information, visit our website or the watch announcement video and our conversation with Snap at Next 2021.
Quelle: Google Cloud Platform
Published by