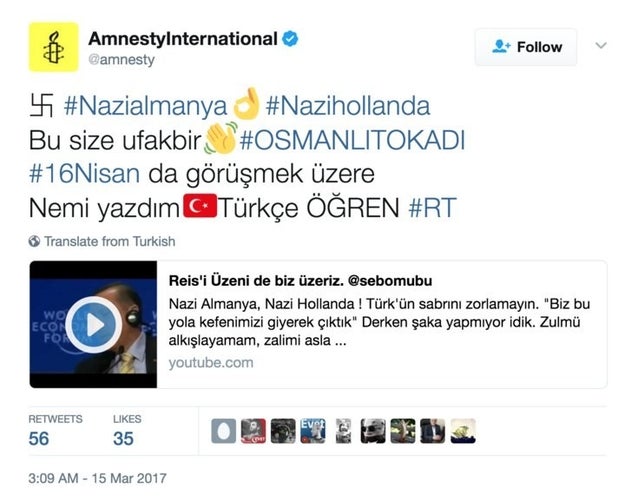
Users of the R language often require more compute capacity than their local machines can handle. However, scaling up their work to take advantage of cloud capacity can be complex, troublesome, and can often distract R users from focusing on their algorithms.
We are excited to announce doAzureParallel – a lightweight R package built on top of Azure Batch, that allows you to easily use Azure’s flexible compute resources right from your R session.
At its core, the doAzureParallel package is a parallel backend, for the widely popular foreach package, that lets you execute multiple processes across a cluster of Azure virtual machines. In just a few lines of code, the package helps you create and manage a cluster in Azure, and register it as a parallel backend to be used with the foreach package.
With doAzureParallel, there’s no need to manually create, configure, and manage a cluster of individual virtual machines. Instead, this package makes running your jobs at scale no more complex than running your algorithms on your local machine. With Azure Batch’s autoscaling capabilities, you can also increase or decrease the size of your cluster to fit your workloads, helping you to save time and/or money.
doAzureParallel also uses the Azure Data Science Virtual Machine (DSVM), allowing Azure Batch to easily and quickly configure the appropriate environment in as little time as possible.
There is no additional cost for these capabilities – you only pay for the Azure VMs you use.
doAzureParallel is ideal for running embarrassingly parallel work such as parametric sweeps or Monte Carlo simulations, making it a great fit for many financial modelling algorithms (back-testing, portfolio scenario modelling, etc).
Installation / Pre-requisites
To use doAzureParallel, you need to have a Batch account and a Storage account set up in Azure. More information on setting up your Azure accounts.
You can install the package directly from Github. More information on install instructions and dependencies.
Getting Started
Once you install the package, getting started is as simple as few lines of code:
Load the package:
library(doAzureParallel)
Set up your parallel backend (which is your pool of virtual machines) with Azure:
# 1. Generate a pool configuration json file.
generateClusterConfig(“pool_config.json”)
# 2. Edit your pool configuration file.
# Enter your Batch account & Storage account information and configure your pool settings
# 3. Create your pool. This will create a new pool if your pool hasn’t already been provisioned.
pool <- makeCluster(“pool_config.json”)
# 4. Register the pool as your parallel backend
registerDoAzureParallel(pool)
# 5. Check that your parallel backend has been registered
getDoParWorkers()
Run your parallel foreach loop with the %dopar% keyword. The foreach function will return the results of your parallel code.
number_of_iterations <- 10
results <- foreach(i = 1:number_of_iterations) %dopar% {
# This code is executed, in parallel, across your Azure pool.
myAlgorithm(…)
}
When developing at scale, it is always recommended that you test and debug your code locally first. Switch between %dopar% and %do% to toggle between running in parallel on Azure and running in sequence on your local machine.
# run your code sequentially on your local machine
results <- foreach(i = 1:number_of_iterations) %do% { … }
# use the doAzureParallel backend to run your code in parallel across your Azure pool
results <- foreach(i = 1:number_of_iterations) %dopar% {…}
After you finish running your R code at scale, you may want to shut down your pool of VMs to make sure that you aren’t being charged anymore:
# shut down your pool
stopCluster(pool)
Monte Carlo Pricing Simulation Demo
The following demo will show you a simplified version of predicting a stock price after 5 years by simulating 5 million different outcomes of a single stock.
Let's imagine Contoso&039;s stock price gains on average 1.001 times its opening price each day, but has a volatility of 0.01. Given a starting price of $100, we can use a Monte Carlo pricing simulation to figure out what price Contoso&039;s stock will be after 5 years.
First, define the assumptions:
mean_change = 1.001
volatility = 0.01
opening_price = 100
Create a function to simulate the movement of the stock price for one possible outcome over 5 years by taking the cumulative product from a normal distribution using the variables defined above.
simulateMovement <- function() {
days <- 1825 # ~ 5 years
movement <- rnorm(days, mean=mean_change, sd=volatility)
path <- cumprod(c(opening_price, movement))
return(path)
}
On our local machine, simulate 30 possible outcomes and graph the results:
simulations <- replicate(30, simulateMovement())
matplot(simulations, type=&039;l&039;) # plots all 30 simulations on a graph
To understand where Contoso&039;s stock price will be in 5 years, we need to understand the distribution of the closing price for each simulation (as represented by the lines). But instead of looking at the distribution of just 30 possible outcomes, lets simulate 5 million outcomes to get a massive sample for the distribution.
Create a function to simulate the movement of the stock price for one possible outcome, but only return the closing price.
getClosingPrice <- function() {
days <- 1825 # ~ 5 years
movement <- rnorm(days, mean=mean_change, sd=volatility)
path <- cumprod(c(opening_price, movement))
closingPrice <- path[days]
return(closingPrice)
}
Using the foreach package and doAzureParallel, we can simulate 5 million outcomes in Azure. To parallelize this, lets run 50 iterations of 100,000 outcomes:
closingPrices <- foreach(i = 1:50, .combine=&039;c&039;) %dopar% {
replicate(100000, getClosingPrice())
}
After running the foreach package against the doAzureParallel backend, you can look at your Azure Batch account in the Azure Portal to see your pool of VMs running the simulation.
As the nodes in the heat map changes color, we can see it busy working on the pricing simulation.
When the simulation finishes, the package will automatically merge the results of each simulation and pull it down from the nodes so that you are ready to use the results in your R session.
Finally, we&039;ll plot the results to get a sense of the distribution of closing prices over the 5 million possible outcomes.
# plot the 5 million closing prices in a histogram
hist(closingPrices)
Based on the distribution above, Contoso&039;s stock price will most likely move from the opening price of $100 to a closing price of roughly $500, after a 5 year period.
We look forward to you using these capabilities and hearing your feedback. Please contact us at razurebatch@microsoft.com for feedback or feel free to contribute to our Github repository.
Additional information:
Download and get started with doAzureParallel
For questions related to using the doAzureParallel package, please see our docs, or feel free to reach out to razurebatch@microsoft.com
Please submit issues via Github
Additional Resources:
See Azure Batch, the underlying Azure service used by the doAzureParallel package
More general purpose HPC on Azure
Quelle: Azure