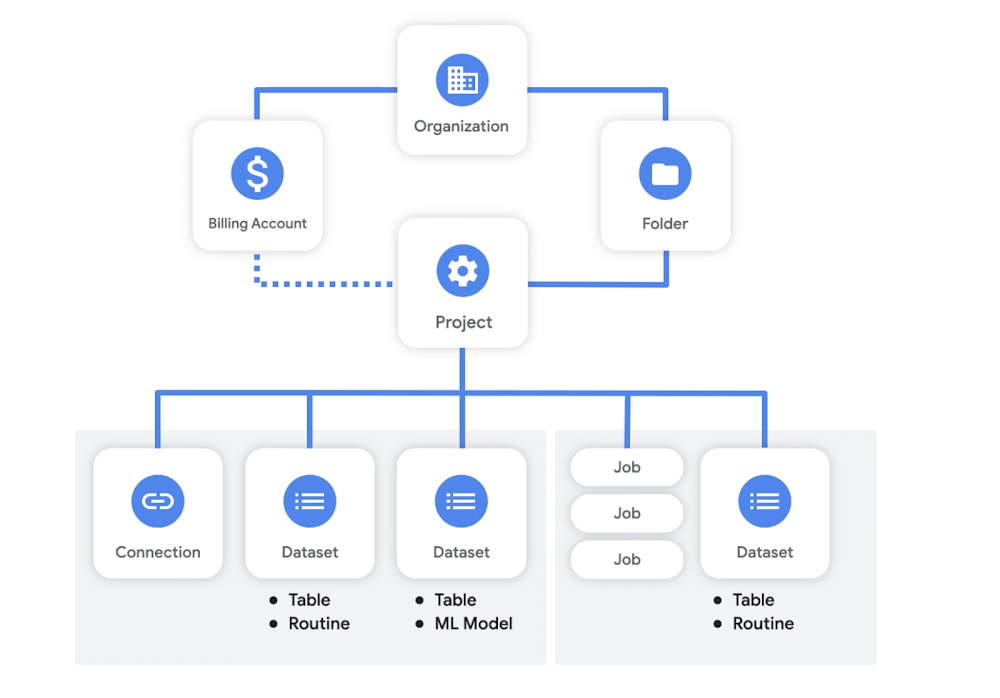
Starting this week, we’re adding new content to the BigQuery Spotlight Youtube series. Throughout the summer we’ll be adding new videos and blog posts focused on helping new BigQuery architects and administrators master the fundamentals. You can find complimentary material for the topics discussed in the official BigQuery documentation, which is linked below. First up, the BigQuery Resource Model!BigQuery, like other Google Cloud resources, is organized hierarchically where the Organization node is the root node, the Projects are the children of the Organization, and Datasets are descendants of Projects. In this post, we will look closer at the BigQuery resource model and discuss key considerations for architecting your deployment based on business needs. BigQuery core Resource Model Organizations, folders & billing accountsThe Organization resource is the root node of the Google Cloud resource hierarchy. It represents a company and is closely associated with your organization’s domain by being linked to one Google Workspace or Cloud Identity account. While an Organization is not required to get started using BigQuery, it is recommended. With an Organization resource, projects belong to your organization instead of the employee who created the project. Furthermore, organization administrators have central control of all resources. Folders are an additional grouping mechanism on top of Projects. They can be seen as sub-organizations within the Organization. Folders can be used to model different legal entities, departments, and teams within a company. Folders act as apolicy inheritance point – IAM roles granted on a folder are automatically inherited by all Projects and folders included in that folder. For BigQuery flat-rate customers, slots (units of CPU) can be assigned to Organizations, Folders or Projects where they are distributed fairly among projects to handle job workloadsA Billing Account is required to use BigQuery, unless you are using the BigQuery sandbox. Many times, different teams will want to be billed individually for consuming resources in Google Cloud. Therefore, each billing group will have its own billing account, which results in a single invoice and is tied to a Google Payments profile. ProjectsA Project is required to use BigQuery and forms the basis for using all Google Cloud services. Projects are analogous to databases in other systems.A project is used both for storing data and for running jobs on, or querying, data. And because storage and compute are separate, these don’t need to be the same project. You can store your data in one project and query it from another, this includes combining data stored in multiple projects in a single query. A project can have only one billing account, the project will be billed for data stored in the project and jobs run in the project. Watch out for per-project limitations and quotas. DatasetsDatasets are top-level containers, within a project, that are used to organize and control access to tables, views, routines and machine learning models. A table must belong to a dataset, so you need to create at least one dataset before loading data into BigQuery.Your data will be stored in the geographic location that you chose at the dataset’s creation time. After a dataset has been created, the location can’t be changed. One important consideration is that you will not be able to query across multiple locations, you can read details on location considerations here. Many users chose to store their data in a multi-region location, however some chose to set a specific region that is close to on-premise databases or ETL jobs.Access controlsAccess to data within BigQuery can be controlled at different levels in the resource model, including the Project, Dataset, Table or even column. However, it’s often easier to control access higher in the hierarchy for simpler management. Examples of common BigQuery project structures:By now you probably realize that deciding on a Project structure can have a big influence on data governance, billing and even query efficiency. Many customers chose to deploy some notion of data lakes and data marts by leveraging different Project hierarchies. This is mainly a result of cheap data storage, more advanced SQL offerings which allow for ELT workloads and in-database transformations, plus the separation of storage and compute inside of BigQueryCentral data lake, department data martsWith this structure, there is a common project that stores raw data in BigQuery (Unified Storage project), also referred to as a Data Lake. It’s common for a centralized data platform team to create a pipeline that actually ingest data from various sources into BigQuery within this project. Each department or team would then have their own datamart projects (e.g. Department A Compute) where they can query the data, save results and create aggregate views.How it works:Central data engineering team is granted permission to ingest and edit data in the storage projectDepartment analysts are granted BigQuery Data Viewer role for specific datasets in the Unified Storage projectDepartment analysts are also granted BigQuery Data Editor role and BigQuery Job User role for their department’s compute projectEach compute project would be connected to the team’s billing accountThis is especially useful for when:Each business unit wants to be billed individually for their queriesThere is a centralized platform or data engineering team that ingests data into BigQuery across business unitsDifferent business units access their data in their own tools or directly in the consoleYou need to avoid too many concurrent queries running in the same project (due to per-project quotas)Department data lakes, one common data warehouse projectWith this option, data for each department is ingested into separate projects – essentially giving each department their own data lake. Analysts are then able to query these datasets or create aggregate views in a central data warehouse project, which can also easily be connected to a business intelligence tool.How it works:Data engineers who are responsible for ingesting specific data sources are granted BQ Data Editor and BQ Job User roles in their department’s storage projectAnalysts are granted BQ Data Viewer role to underlying data at the project level, for example an HR analyst might be granted data viewer access to the entire HR storage projectService accounts that are used to connect BigQuery to external business intelligence tools can be also be granted data viewer access to specific projects that contain datasets to be used in visualizationsAnalysts and Service Account are then granted BQ Job User and BQ Data Editor roles in the Central Data Warehouse projectThis is especially useful for when:It’s easier to manage raw data access at the project / department levelCentral analytics team would rather have a single project for compute, which could make monitoring queries simpler Users are accessing data from a centralized business intelligence toolSlots can be assigned to the data warehouse project to handle all queries from analysts and external toolsNote that this structure may result in a lot of concurrent queries, so watch out for per-project limitations. This structure works best for flare-rate customers with lifted concurrency limits. Department data lakes and department data martsHere, we combine the previous approaches and create a data lake or storage project for each department. Additionally, each department might have their own datamart project where analysts can run queries.How it works:Department data engineers are granted BQ Data Editor and BQ Job User roles for their department’s data lake projectDepartment data analysts are granted BQ Viewer roles for their department’s data lake projectDepartment data analysts are granted BQ Data Editor and BQ Job User roles for their department’s data mart projectAuthorized views and authorized user defined functions can be leveraged to give data analysts access to data in projects where they themselves don’t have accessThis is especially useful for when:Each business unit wants to be billed individually both for data storage and computeDifferent business units access their data in their own tools or directly in the consoleYou need to avoid too many concurrent queries running in the same projectIt’s easier to manage raw data access at the project / department levelNow you should be well on your way to beginning to architect your BigQuery Data Warehouse! Be sure to keep an eye out for more in this series by following me on LinkedIn and Twitter!Related ArticleSpring forward with BigQuery user-friendly SQLThe newest set of user-friendly SQL features in BigQuery are designed to enable you to load and query more data with greater precision, a…Read Article
Quelle: Google Cloud Platform
Published by